TLDR:使用 MXFP8 訓練加速 1.22 倍 – 1.28 倍,與 BF16 相比收斂性相當。
我們最近與一個 Crusoe B200 叢集合作,該叢集擁有 1856 個 GPU,首次體驗到使用新的 MX-FP8 資料型別與 TorchAO 的實現和 TorchTitan(Llama3-70B,HSDP2,上下文並行=2)帶來的訓練速度提升。 這項工作與我們之前在 Crusoe H200s 上的大規模訓練在精神上相似。
我們的測試表明,即使在全部 1856 個 GPU 規模下,與 BF16 訓練相比,損失曲線等效且加速了 1.22 倍到 1.28 倍。
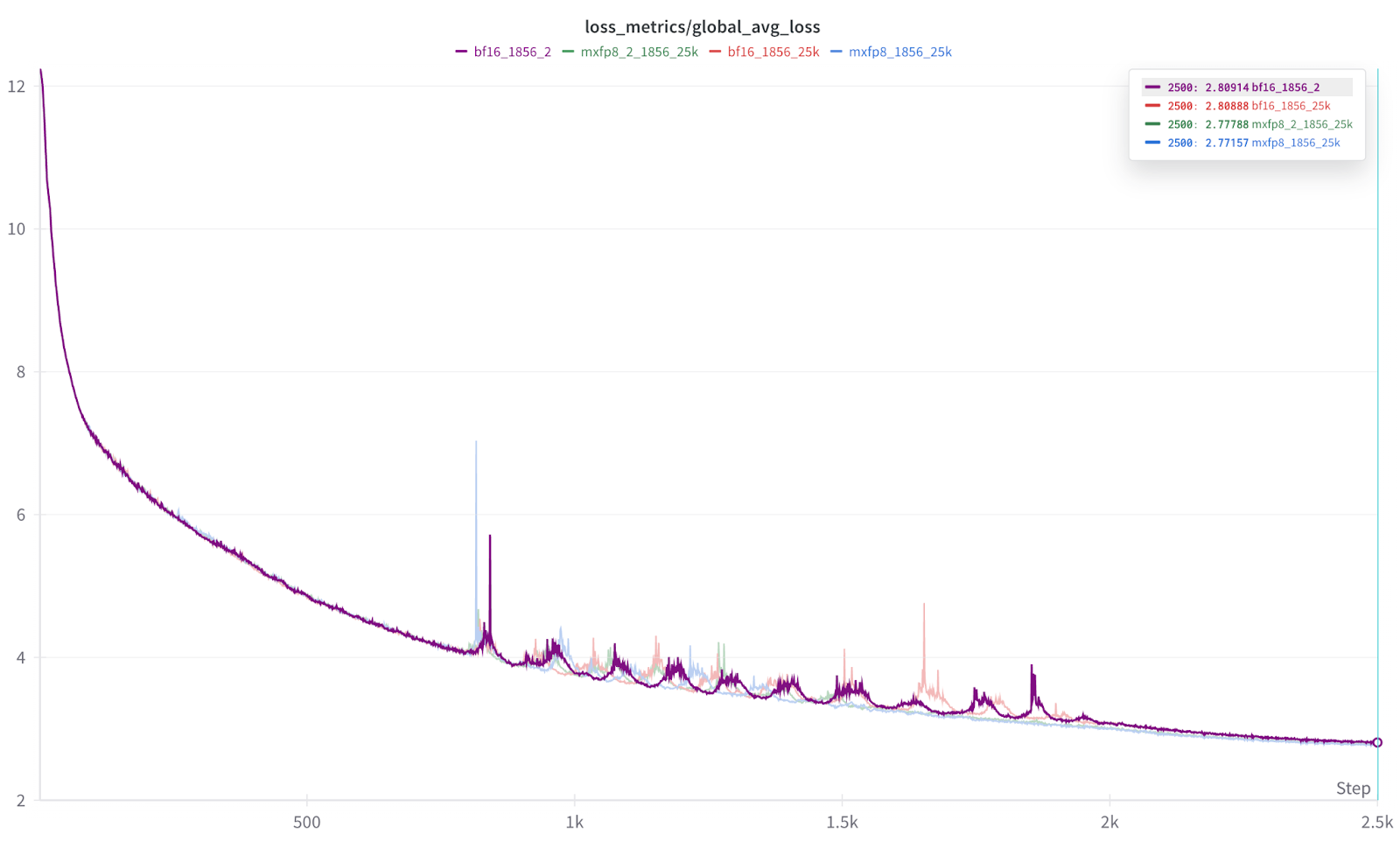
- 請注意,這些結果是使用早期 [v0.10,2025 年 4 月] 版本的 TorchAO 獲得的,並且相關核心一直在改進,因此如果再次執行,將產生更快的結果。
值得注意的是,當從 4 個節點擴充套件到 188 個節點時,我們觀察到的效能差異僅約為 5%,總世界規模增加了 47 倍。
背景 – 透過縮放精度實現 Float8 進展
我們之前使用過各種 Float8 實現,其縮放精度水平不斷提高。縮放因子範圍從 張量級(即整個張量一個縮放因子)到 行級(即每行一個縮放因子),現在到 MX 樣式(即每 32 個元素一個縮放因子)。
在此基礎上,DeepSeek 推廣了一種更細粒度的 Float8 實現,其中輸入(A 矩陣)以 1×128 縮放進行量化,權重(B 矩陣)以 128×128 塊級縮放。
大約在同一時間,TorchAO 釋出了 Float8 行級,其中每行都有一個單一的縮放因子。我們之前在 Crusoe H200 叢集上測試了這一點,展示了損失收斂。
這就引出了目前最細粒度的縮放,MXFP8。
最初由微軟開創, MX 已成為 OCP 標準。對於 Nvidia Blackwell 上的 MXFP8,我們有硬體支援的 mxfp8,其中張量的 32 個元素(1×32)塊使用一個縮放因子進行量化。
直觀地看,1×32 的縮放應該比 1×128 等提供更高的精度,而且透過 Blackwell,我們可以要求硬體進行量化,條件是 K % 32 == 0(基本上,張量必須能被 32 整除,這樣我們就不會遇到填充要求)。
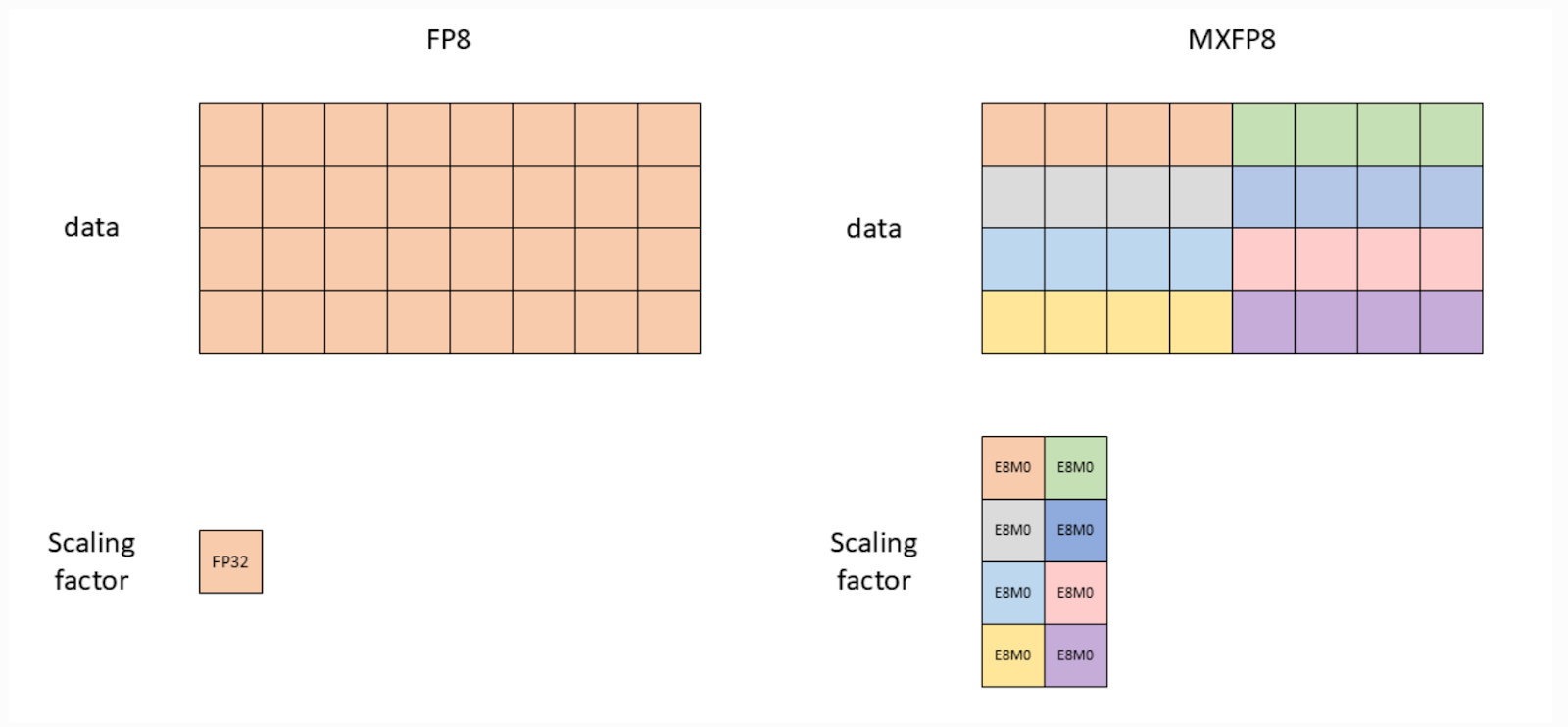
圖 1:Float8 張量級(左)與 MXFP8(右)的視覺比較(圖片來源:NVIDIA 文件)
另一個變化是縮放因子精度從 FP32 變為 E8M0(實際上是 2 的冪次縮放)

圖 2:縮放因子 dtype 比較(圖片來源:NVIDIA 文件)
MXFP8 訓練加速結果:
接下來,我們可以回顧與 BF16 執行 TorchTitan(Llama3-70B 模型大小、HSDP2 和上下文並行=2)相比的加速情況。
我們看到加速範圍從 1504 GPU 規模下的 1.22 倍到 32 GPU 規模下的 1.285 倍
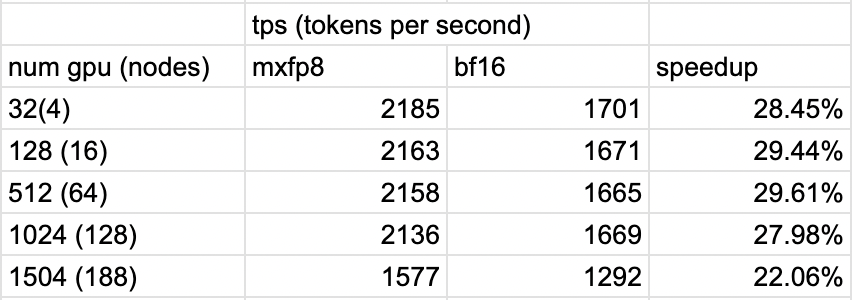
圖 3:MXFP8 在不同 GPU 規模下訓練的加速效果
MXFP8 收斂結果:
更重要的是,在 1856 規模下,我們還看到損失曲線的收斂性幾乎相同(MXFP8 略佔優勢)
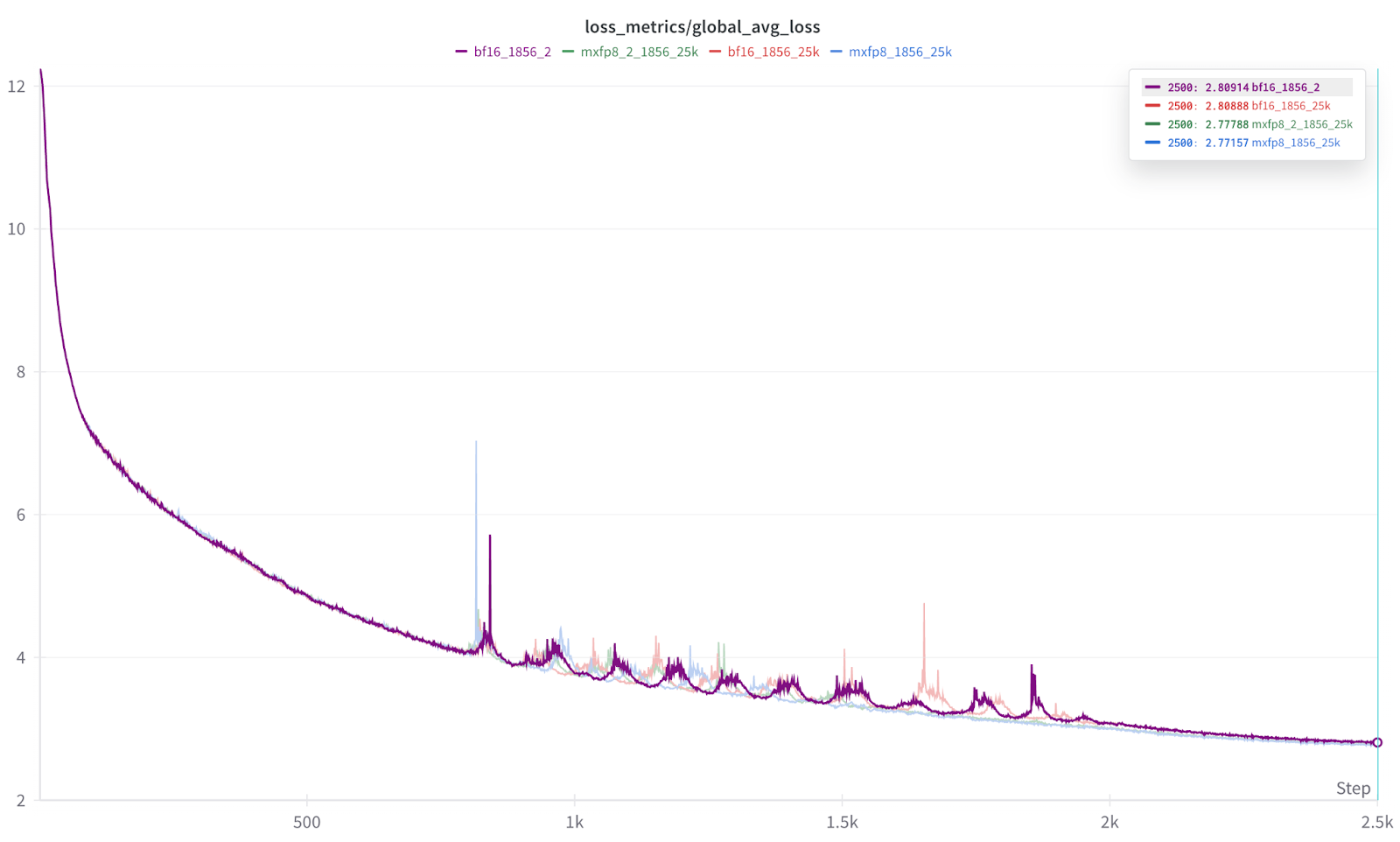
圖 4:多次訓練執行的損失曲線疊加
結果的放大圖。 每次執行重複 2 次,以幫助證明結果的一致性。
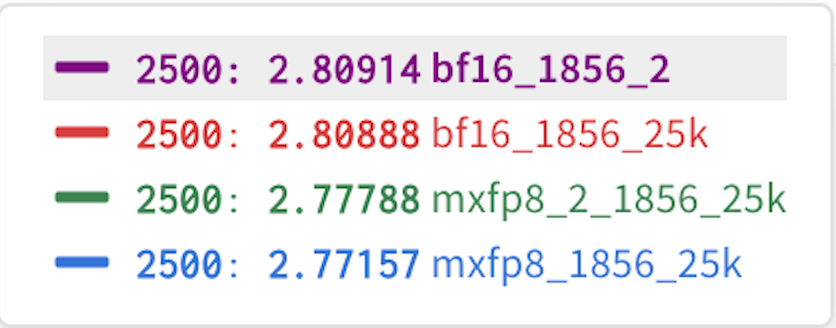
圖 5:每次 2500 次迭代執行的最終結果。
從圖 5 的結果可以看出,每種資料型別(BF16、MXFP8)的執行結果幾乎無法區分,而且我們還發現 MXFP8 的結果始終略微領先。 因此,在我們的初步測試中,我們發現 MXFP8 既提供了訓練加速,又提供了與 BF16 相同或略好的收斂性/準確性。
未來工作
這些大規模執行的目的是建立初始效能指標和損失收斂方面的數值等效性,將 TorchAO 的 MXFP8 與 BF16 進行比較。
我們已經改進了相關核心,例如
dim1
此外,我們計劃基於 Quartet 論文探索未來的 MXFP4 和 NVFP4 訓練。