這篇文章是多系列部落格的第一部分,重點介紹如何使用純原生 PyTorch 加速生成式 AI 模型。我們很高興能分享大量新發布的 PyTorch 效能功能,以及這些功能如何結合使用的實際示例,以展示我們能將 PyTorch 原生效能推向多遠。
正如PyTorch 開發者大會 2023上宣佈的,PyTorch 團隊重寫了 Meta 的 Segment Anything (“SAM”) 模型,使程式碼比原始實現快 8 倍,且未損失準確性,所有這些都使用了原生 PyTorch 最佳化。我們利用了大量新的 PyTorch 功能:
- Torch.compile:一個用於 PyTorch 模型的編譯器
- GPU 量化:透過降低精度操作來加速模型
- 縮放點積注意力 (SDPA):記憶體高效的注意力實現
- 半結構化 (2:4) 稀疏性:一種 GPU 最佳化的稀疏記憶體格式
- 巢狀張量:將不同大小的非均勻資料(如不同大小的影像)批次處理成單個張量。
- 帶 Triton 的自定義運算子:使用 Triton Python DSL 編寫 GPU 操作,並透過自定義運算子註冊輕鬆將其整合到 PyTorch 的各種元件中。
我們鼓勵讀者從我們在 Github 上的 SAM 實現複製貼上程式碼,並在 Github 上向我們提問。
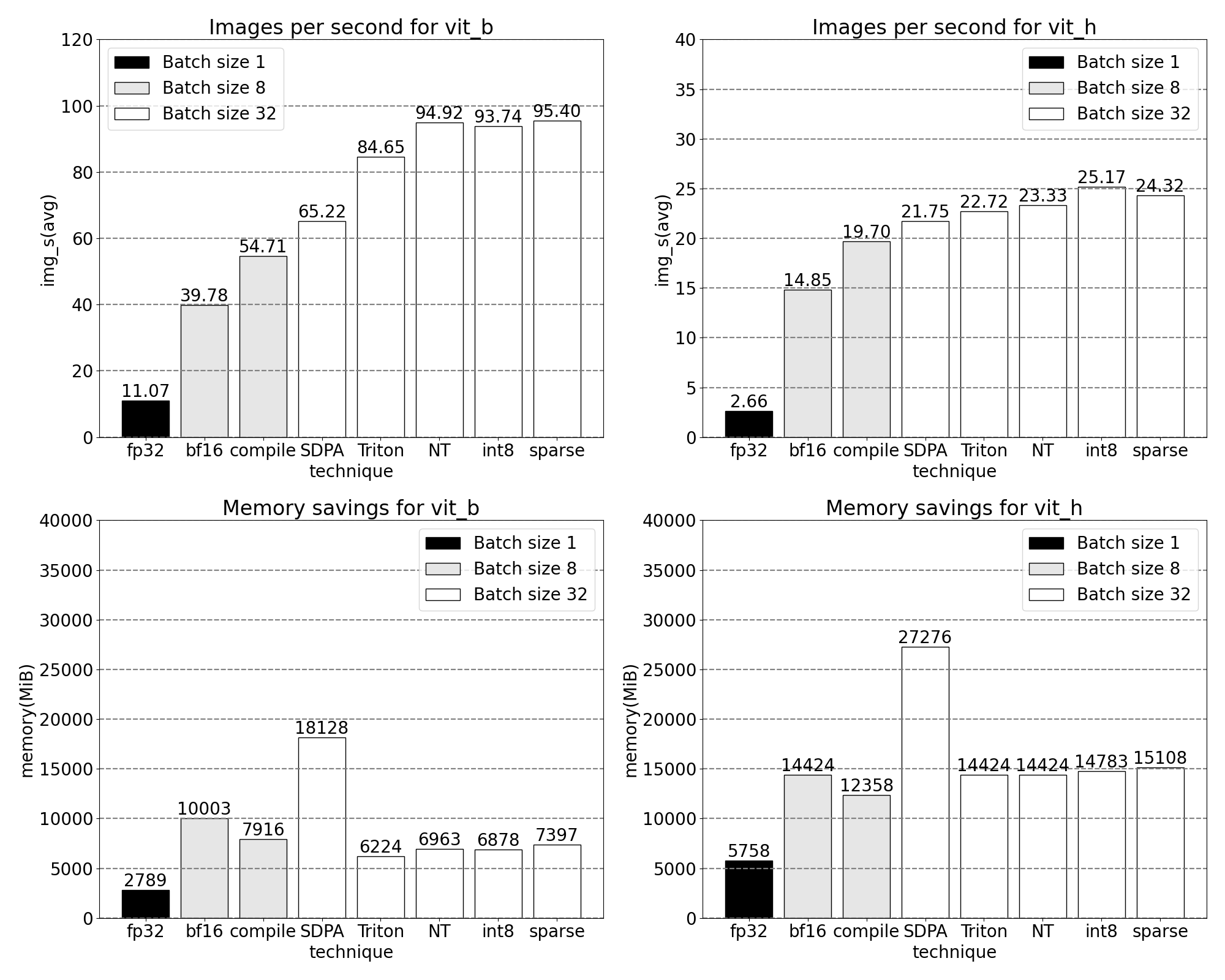
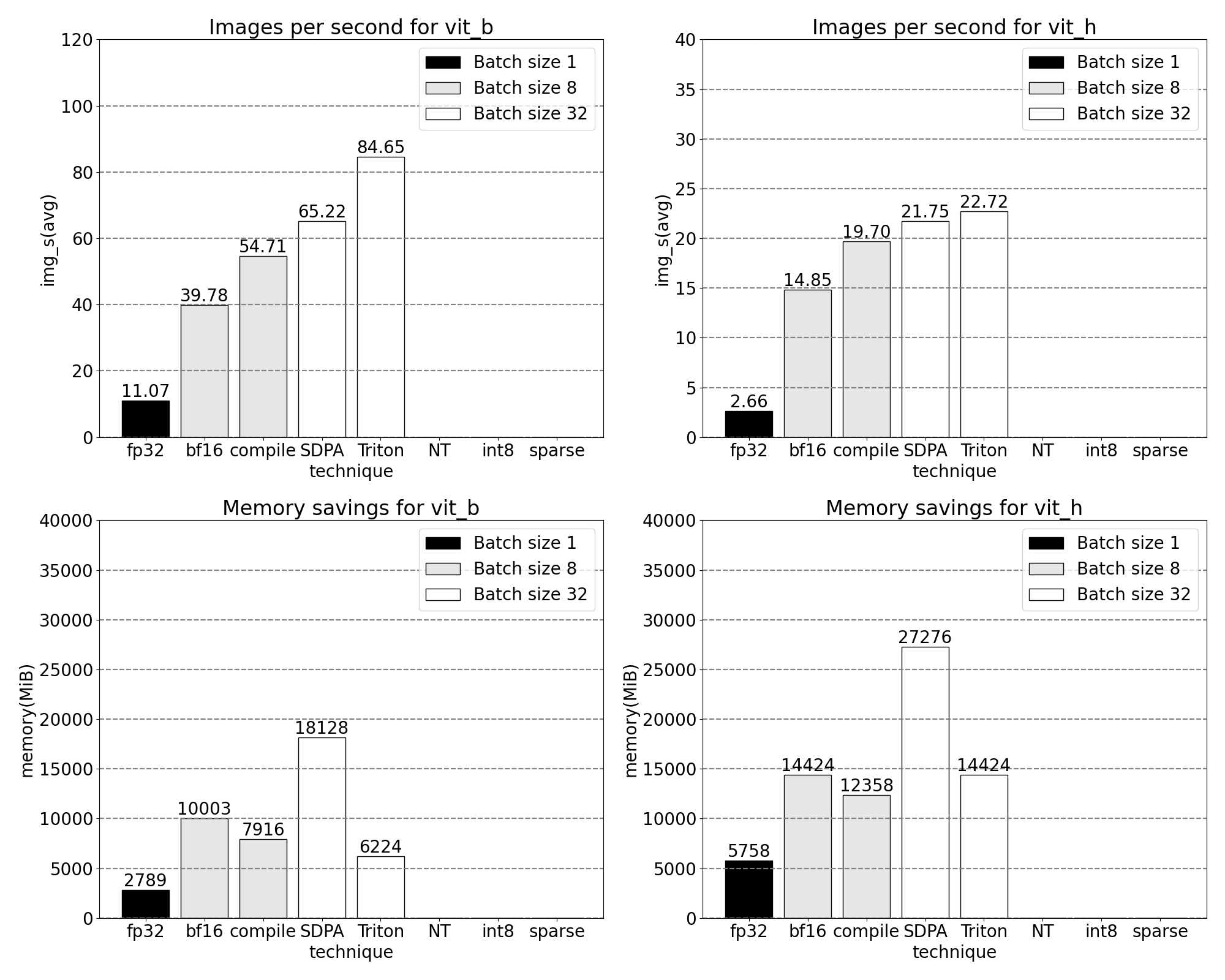
透過我們新發布的 PyTorch 原生功能,吞吐量增加,記憶體開銷減少的快速一瞥。基準測試在 p4d.24xlarge 例項(8x A100)上執行。
SegmentAnything 模型
SAM 是一個用於生成可提示影像掩碼的零樣本視覺模型。

SAM 架構[在其論文中描述]包含多個基於 Transformer 架構的提示和影像編碼器。其中,我們測量了最小和最大的視覺 transformer 主幹網的效能:ViT-B 和ViT-H。為簡單起見,我們僅顯示 ViT-B 模型的跟蹤。
最佳化
下面我們講述最佳化 SAM 的故事:分析、識別瓶頸,並將解決這些問題的新功能構建到 PyTorch 中。在此過程中,我們展示了新的 PyTorch 功能:torch.compile、SDPA、Triton 核心、巢狀張量和半結構化稀疏性。以下部分相互漸進式地構建,最終形成我們的 SAM-fast,現已在Github 上提供。我們使用完全 PyTorch 原生工具,透過真實的核心和記憶體跟蹤來激勵每個功能,並使用Perfetto UI 視覺化這些跟蹤。
基線
我們的 SAM 基線是 Facebook Research 的未修改模型,使用 float32 資料型別和批次大小為 1。經過一些初始預熱後,我們可以使用PyTorch Profiler 檢視核心跟蹤。
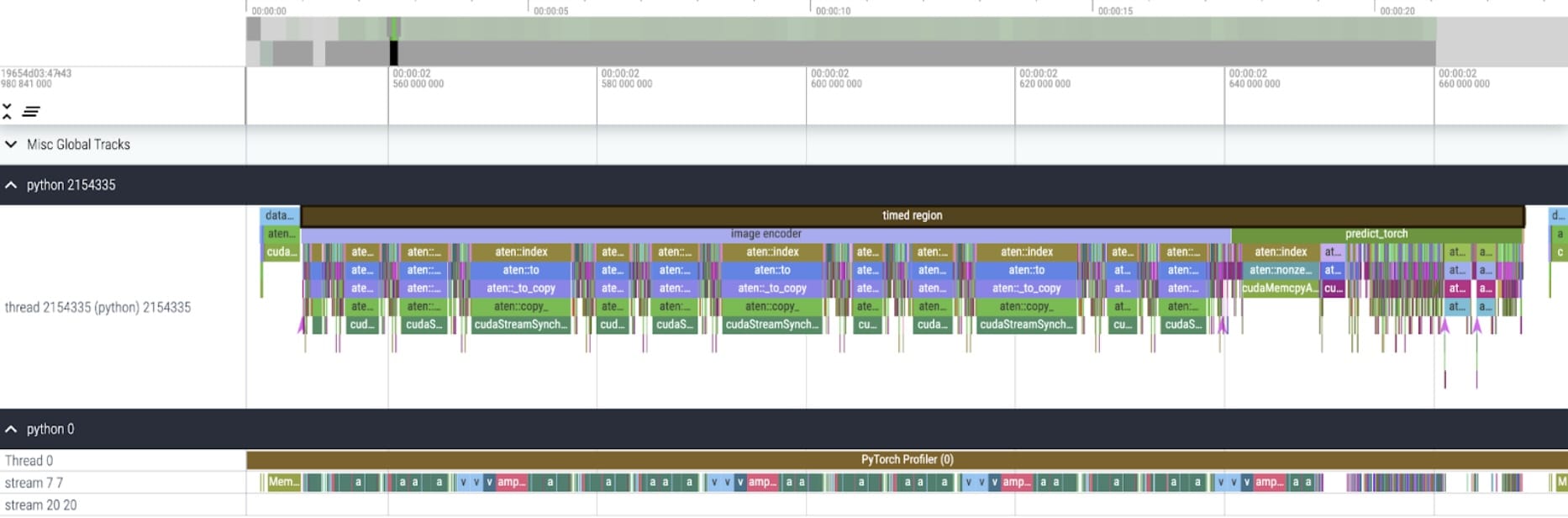
我們注意到兩個有待最佳化的領域。
首先是長時間呼叫 aten::index,這是張量索引操作(例如,[])導致的底層呼叫。雖然 aten::index 實際花費的 GPU 時間相對較低。aten::index 啟動了兩個核心,並且在兩者之間發生了阻塞的 cudaStreamSynchronize。這意味著 CPU 正在等待 GPU 完成處理,直到它啟動第二個核心。為了最佳化 SAM,我們應該致力於消除導致空閒時間的阻塞性 GPU 同步。
其次是 GPU 在矩陣乘法上花費了大量時間(上圖 stream 7 7 上的深綠色)。這在 Transformer 中很常見。如果我們能減少 GPU 在矩陣乘法上花費的時間,我們可以顯著加速 SAM。
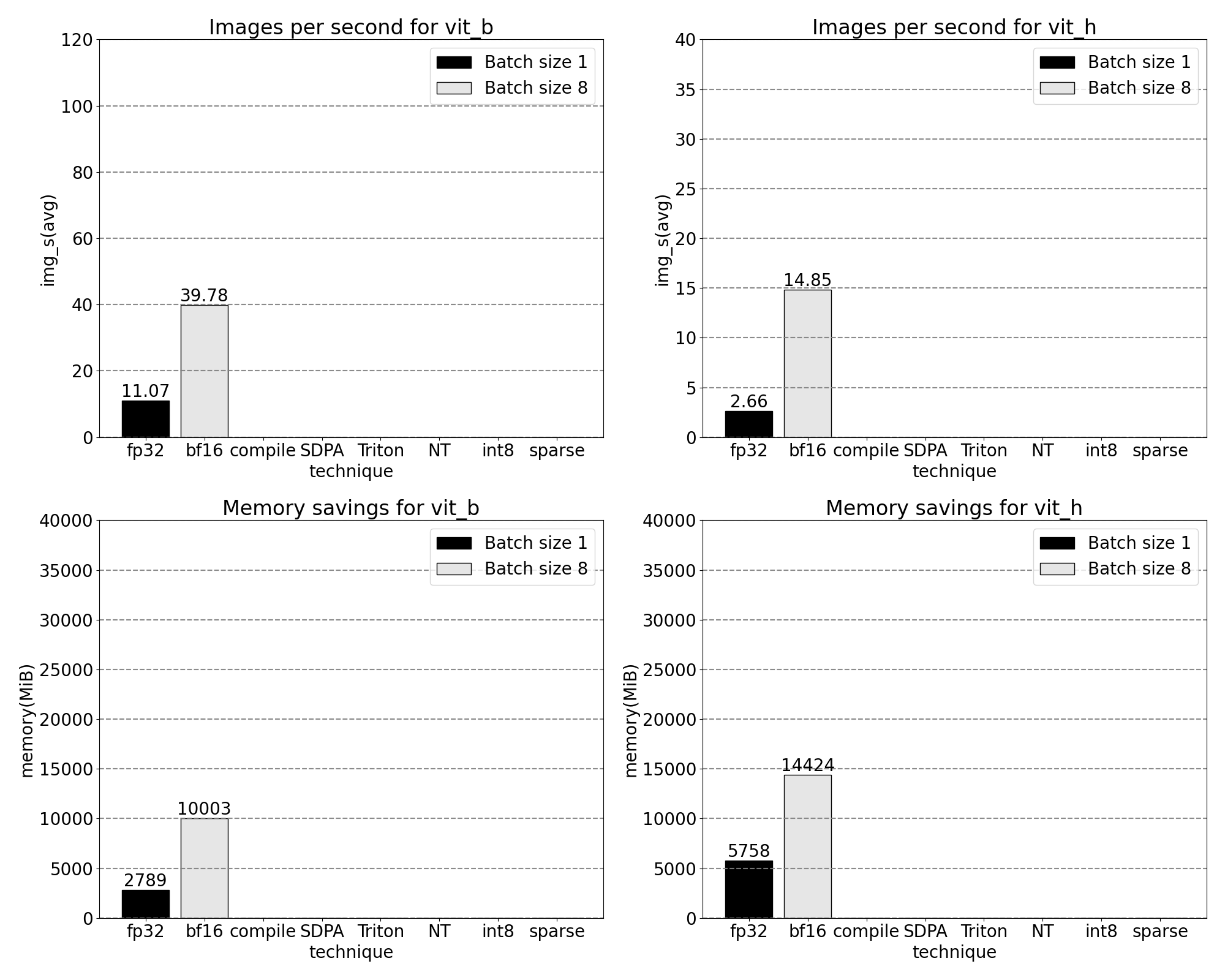
我們可以測量開箱即用 SAM 的吞吐量(img/s)和記憶體開銷(GiB),以建立基線。
Bfloat16 半精度(+GPU 同步和批處理)
為了解決矩陣乘法時間較短的第一個問題,我們可以轉向bfloat16。Bfloat16 是一種常用的半精度型別。透過降低每個引數和啟用的精度,我們可以在計算中節省大量時間和記憶體。在降低引數精度的同時,驗證端到端模型準確性至關重要。

此處顯示了一個將填充資料型別替換為半精度 bfloat16 的示例。程式碼在此。
除了簡單地設定 model.to(torch.bfloat16) 之外,我們還必須更改一些假定預設資料型別的小地方。
現在,為了消除 GPU 同步,我們需要審計導致它們的各種操作。我們可以透過在 GPU 跟蹤中搜索對 cudaStreamSynchronize 的呼叫來找到這些程式碼片段。實際上,我們找到了兩個可以重寫為無同步的位置。


具體來說,我們看到在 SAM 的影像編碼器中,有變數充當座標縮放器,q_coords 和 k_coords。這些變數都在 CPU 上分配和處理。然而,一旦這些變數用於在 rel_pos_resized 中進行索引,索引操作會自動將這些變數移動到 GPU。這種複製會導致我們上面觀察到的 GPU 同步。我們注意到 SAM 的提示編碼器中對索引的第二次呼叫:我們可以使用 torch.where 重寫它,如上所示。
核心跟蹤
應用這些更改後,我們開始看到各個核心呼叫之間存在顯著的時間。這通常在批次大小較小(此處為 1)時觀察到,這是由於啟動核心的 GPU 開銷。為了更仔細地檢視實際最佳化區域,我們可以開始以批次大小為 8 對 SAM 推理進行分析。
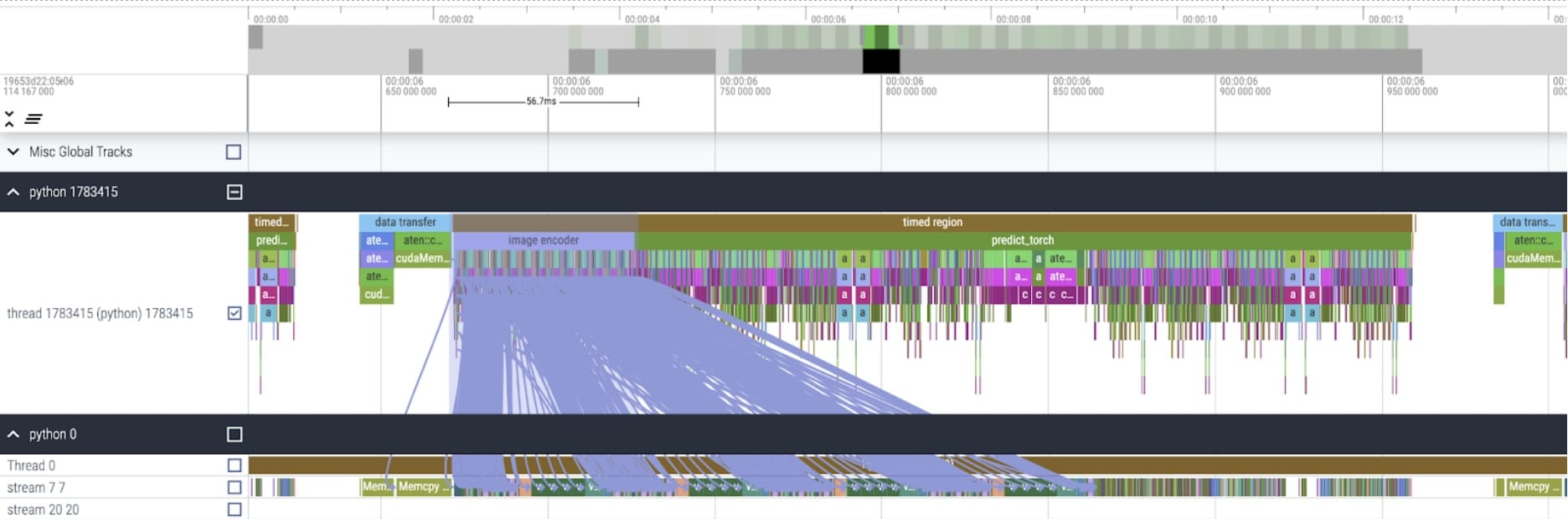
檢視每個核心花費的時間,我們發現 SAM 的 GPU 時間大部分花在元素級核心和 softmax 操作上。透過這些,我們現在看到矩陣乘法的相對開銷變得小得多。
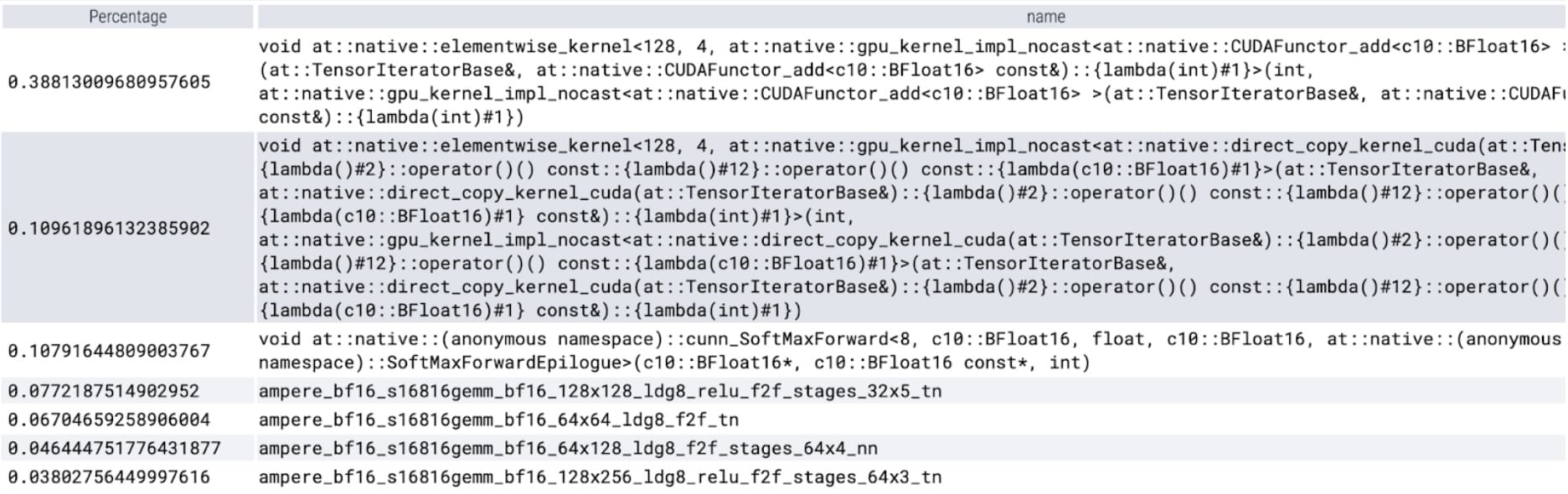
綜合 GPU 同步和 bfloat16 最佳化,我們現在已將 SAM 效能提升了多達 3 倍。
Torch.compile(+圖中斷和 CUDA 圖)
當觀察到大量小操作(例如上面分析的元素級核心)時,轉向編譯器來融合操作可以帶來顯著的好處。PyTorch 最近釋出的 torch.compile 在以下方面做得很好:
- 將一系列操作(如 nn.LayerNorm 或 nn.GELU)融合到一個被呼叫的單個 GPU 核心中,並且
- 尾聲:融合緊隨矩陣乘法核心的操作,以減少 GPU 核心呼叫的數量。
透過這些最佳化,我們減少了 GPU 全域性記憶體往返的次數,從而加速了推理。我們現在可以在 SAM 的影像編碼器上嘗試 torch.compile。為了最大化效能,我們使用了一些高階編譯技術,例如:
- 使用 torch.compile 的 max-autotune 模式可以啟用CUDA 圖和帶有自定義尾聲的特定形狀核心。
- 透過設定 TORCH_LOGS=”graph_breaks,recompiles”,我們可以手動驗證我們沒有遇到圖中斷或重新編譯。
- 用零填充編碼器輸入影像的批次,確保編譯器接受靜態形狀,從而能夠始終使用帶有自定義尾聲的特定形狀最佳化核心,而無需重新編譯。
predictor.model.image_encoder = \
torch.compile(predictor.model.image_encoder, mode=use_compile)
核心跟蹤
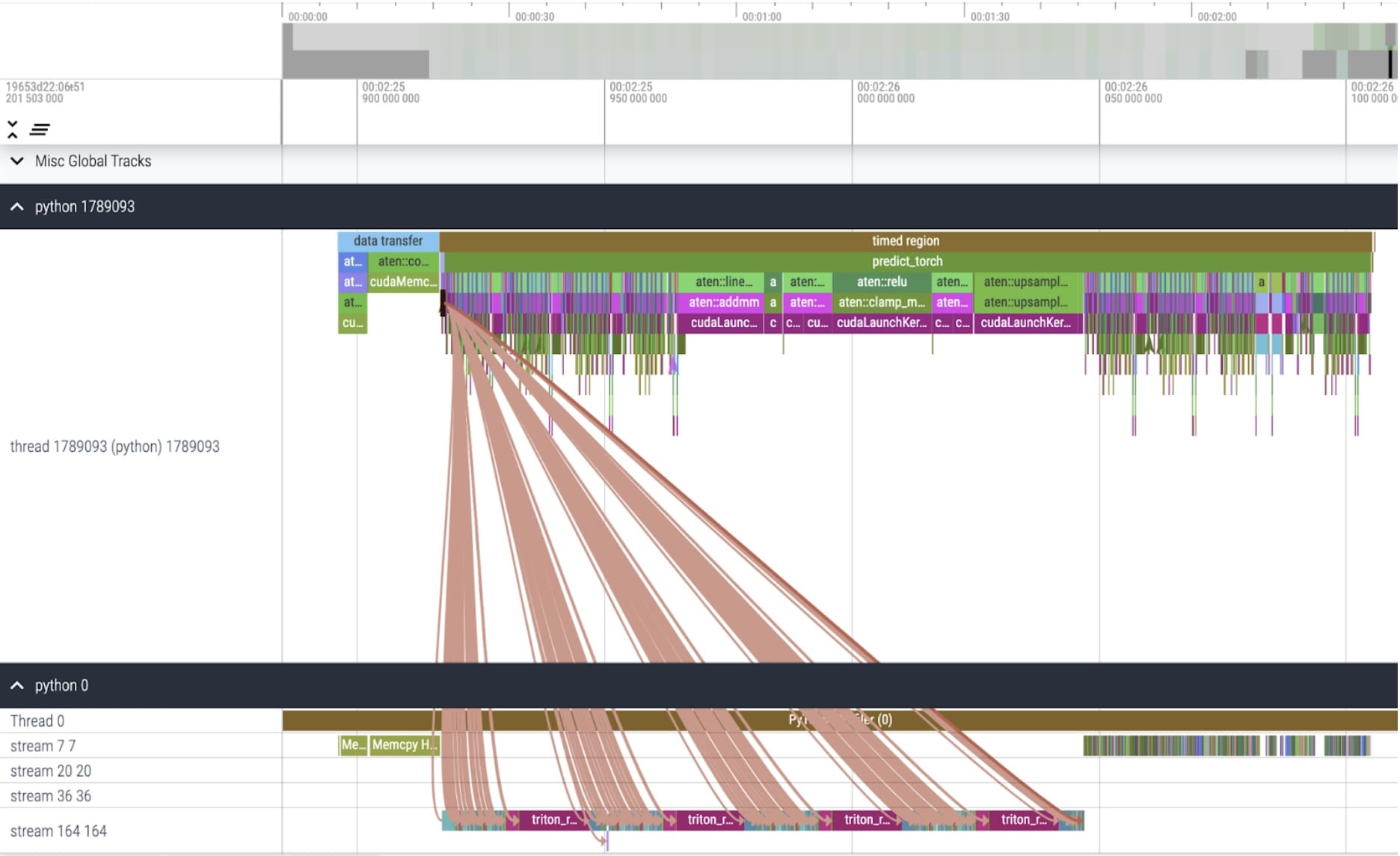
torch.compile 工作得非常好。我們啟動了一個 CUDA 圖,它在計時區域內佔據了 GPU 時間的很大一部分。讓我們再次執行我們的配置檔案,看看 GPU 時間花在特定核心上的百分比。
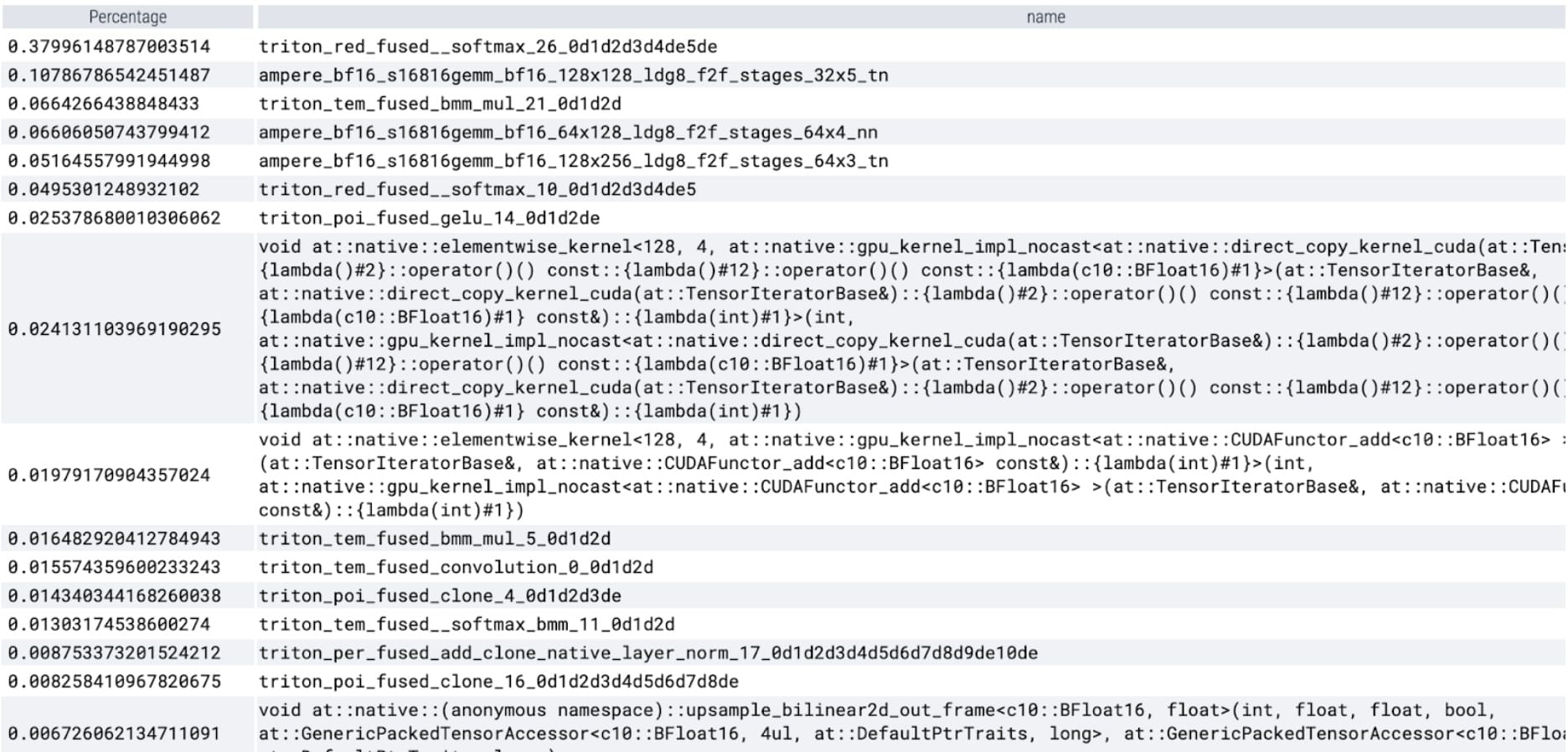
我們現在看到 softmax 佔據了大部分時間,其次是各種 GEMM 變體。總而言之,我們觀察到批次大小為 8 及以上更改的以下測量結果。
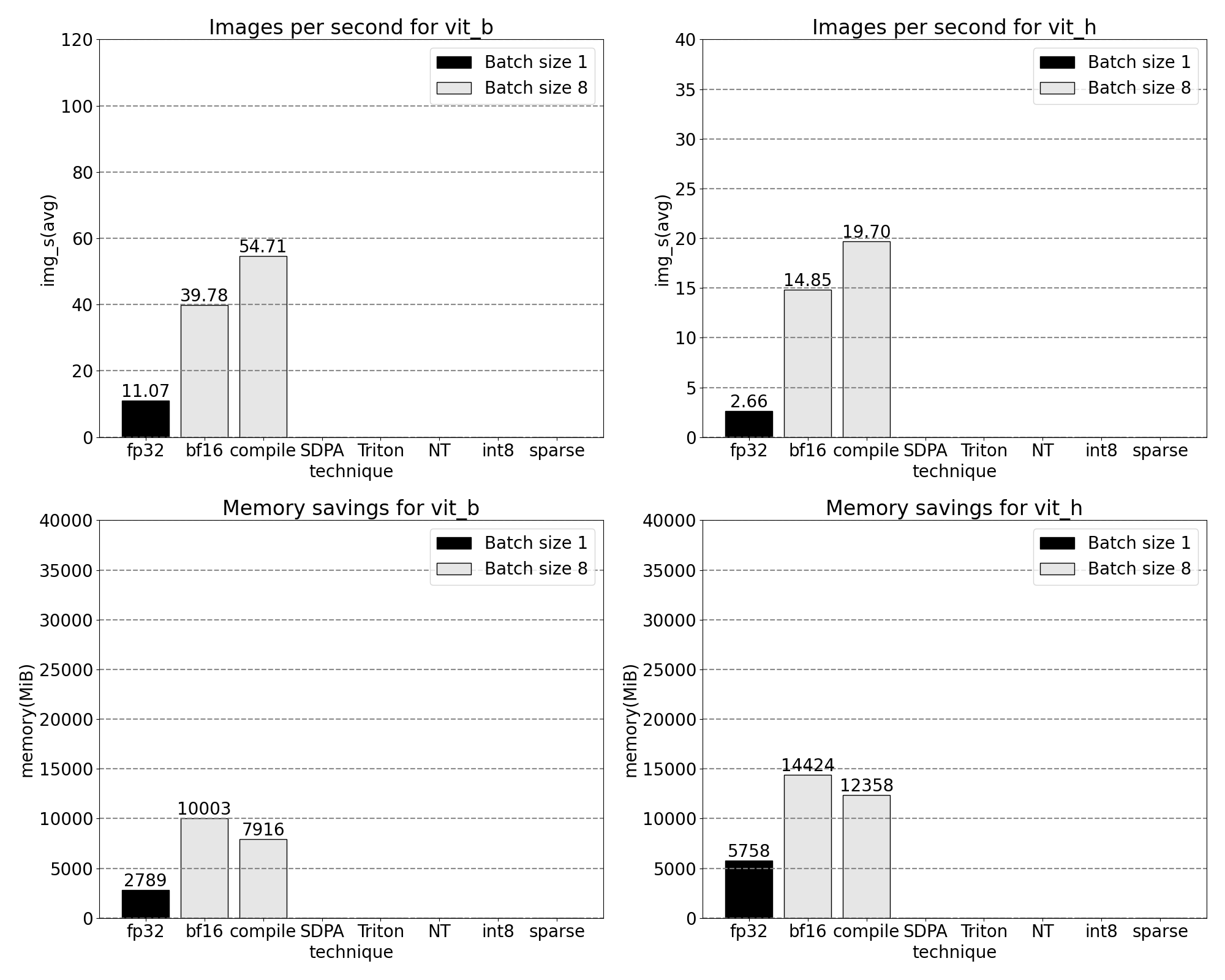
SDPA:scaled_dot_product_attention
接下來,我們可以解決 Transformer 效能開銷最常見的領域之一:注意力機制。樸素的注意力實現與序列長度在時間上和記憶體上呈二次方增長。PyTorch 的scaled_dot_product_attention 操作基於 Flash Attention、FlashAttentionV2 和 xFormer 的記憶體高效注意力 的原理構建,可以顯著加速 GPU 注意力。結合 torch.compile,此操作允許我們表達和融合 MultiheadAttention 變體中的常見模式。經過一小組更改,我們可以使模型適應使用 scaled_dot_product_attention。
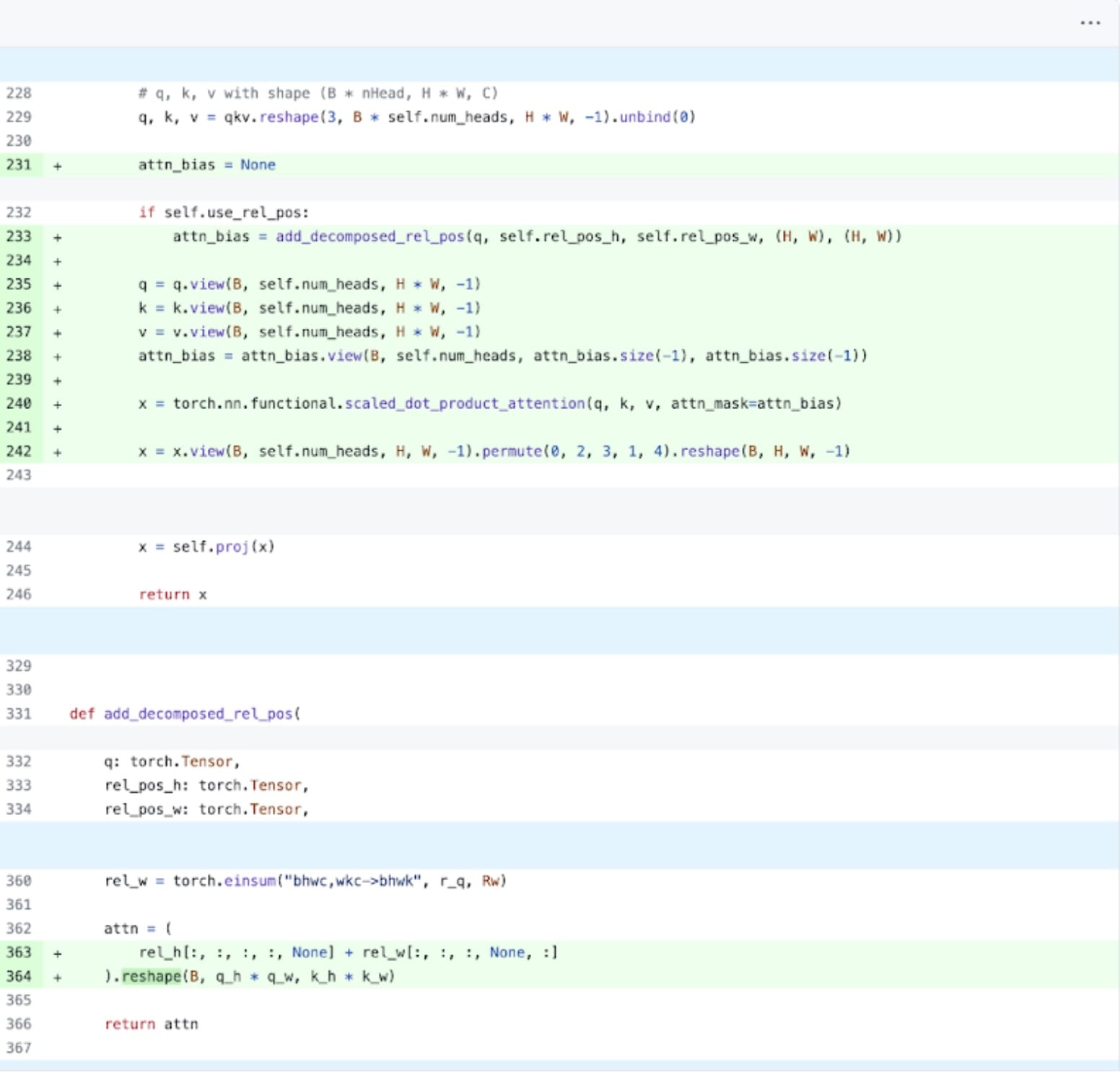
PyTorch 原生注意力實現,程式碼在此處檢視。
核心跟蹤
我們現在可以看到,特別是記憶體高效的注意力核心在 GPU 上佔用了大量的計算時間。
使用 PyTorch 原生的 scaled_dot_product_attention,我們可以顯著增加批次大小。我們現在觀察到批次大小為 32 及以上更改的以下測量結果。
Triton:用於融合相對位置編碼的自定義 SDPA
暫時離開推理吞吐量,我們開始分析 SAM 的整體記憶體。在影像編碼器中,我們發現記憶體分配出現顯著峰值。
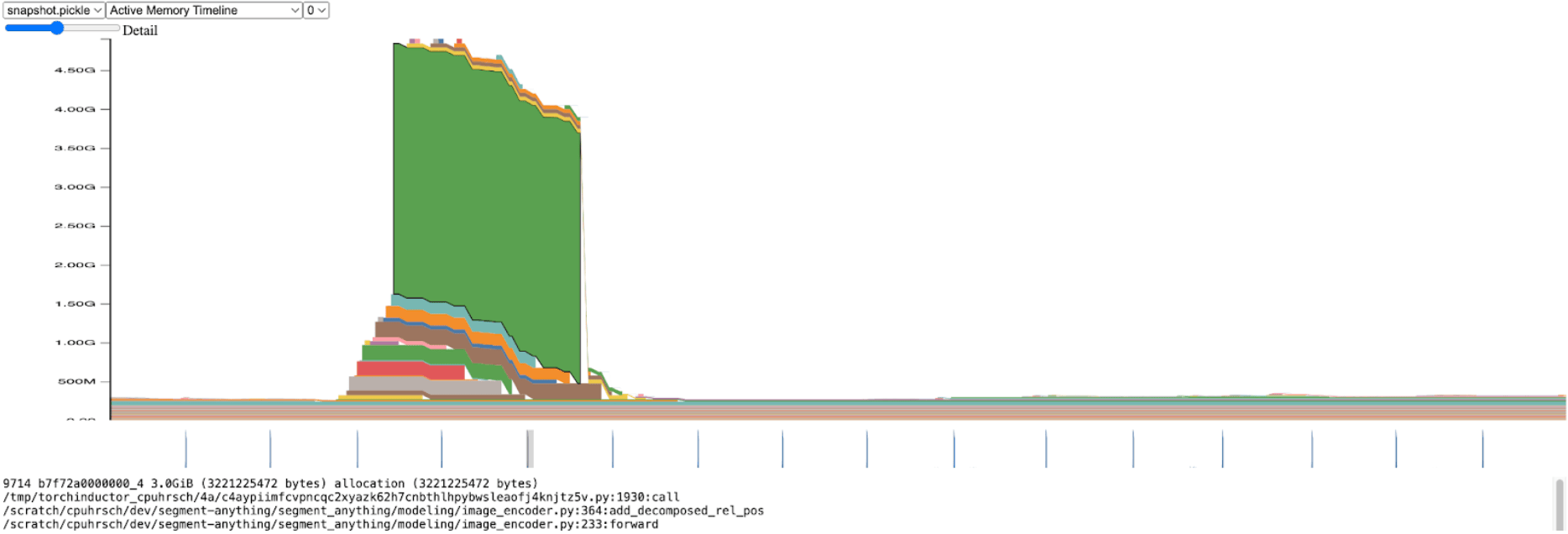
放大來看,我們看到此分配發生在 add_decomposed_rel_pos 中,在以下行:

這裡的 `attn` 變數是兩個較小張量的和:形狀為 (B, q_h, q_w, k_h, 1) 的 `rel_h` 和形狀為 (B, q_h, q_w, 1, k_w) 的 `rel_w`。
注意力偏置大小超過 3.0GiB 時,記憶體高效注意力核心(透過 SDPA 使用)需要很長時間也就不足為奇了。如果我們不分配這個巨大的 `attn` 張量,而是將兩個較小的 `rel_h` 和 `rel_w` 張量執行緒化到 SDPA 中,並且只在需要時構造 `attn`,我們預計會獲得顯著的效能提升。
不幸的是,這不是一個簡單的修改;SDPA 核心是高度最佳化的,並且是用 CUDA 編寫的。我們可以轉向 Triton,其易於理解和使用的FlashAttention 實現教程。經過大量的深入研究並與 xFormer 的 Daniel Haziza 密切合作,我們發現了一種輸入形狀的情況,在這種情況下,實現核心的融合版本相對簡單。這些詳細資訊已新增到儲存庫中。令人驚訝的是,對於推理情況,這可以在 350 行程式碼內完成。
這是一個很好的例子,說明如何使用 Triton 程式碼輕鬆地擴充套件 PyTorch,增加新的核心。
核心跟蹤
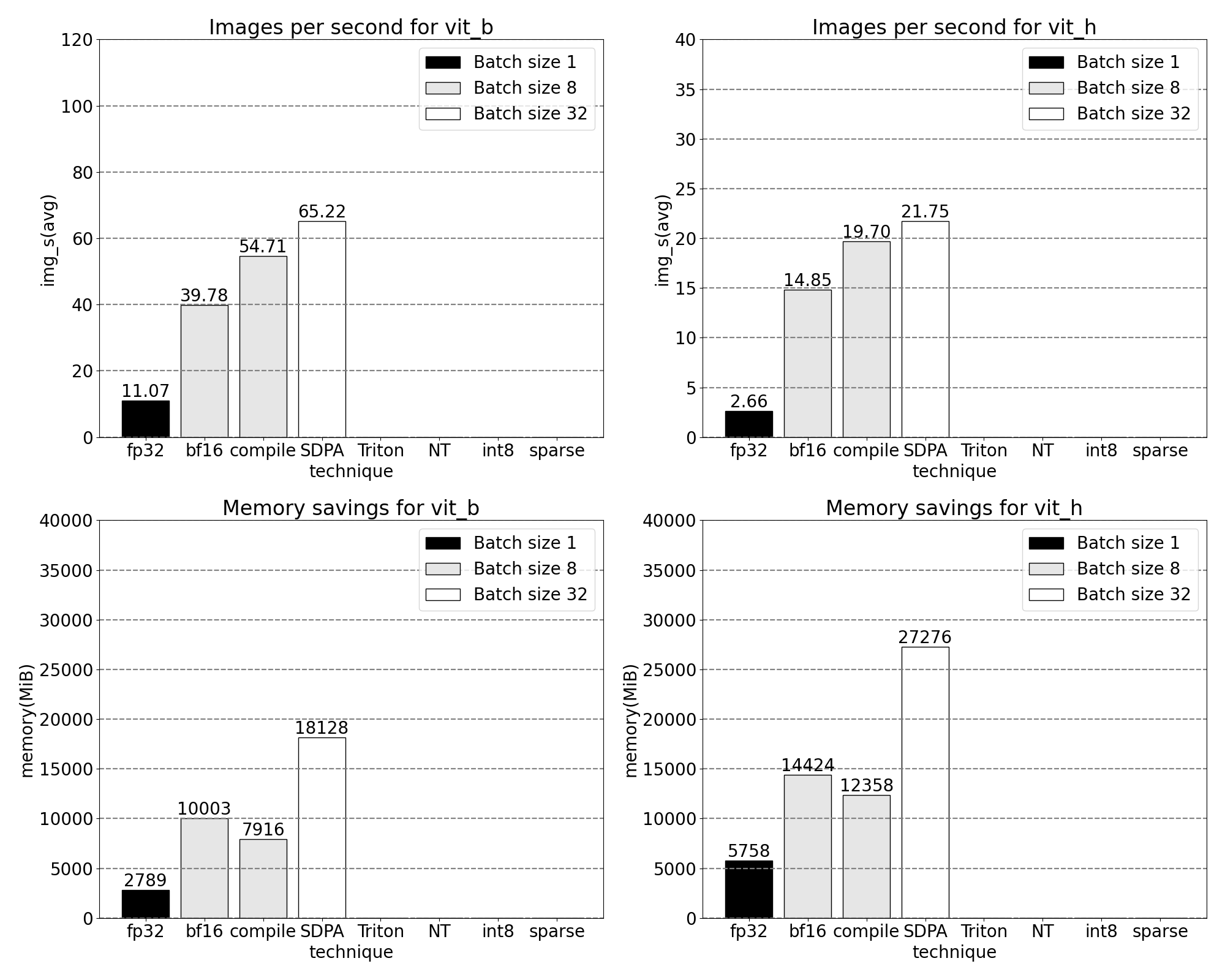
透過我們自定義的位置 Triton 核心,我們觀察到批次大小為 32 時的以下測量結果。
NT:NestedTensor 和批次 predict_torch
我們已經在影像編碼器上花費了大量時間。這是有道理的,因為它佔據了大部分計算時間。然而,到目前為止,它已經得到了很好的最佳化,而最耗時的操作需要大量的額外投資才能改進。
我們對掩碼預測流水線有了一個有趣的發現:對於每個影像,都有一個相關的 `size`、`coords` 和 `fg_labels` 張量。這些張量中的每一個都具有不同的批次大小。每個影像本身也具有不同的大小。這種資料表示類似於不規則陣列。藉助 PyTorch 最近釋出的NestedTensor,我們可以修改資料流水線,將 `coords` 和 `fg_labels` 張量批次處理成一個 NestedTensor。這可以為影像編碼器之後的提示編碼器和掩碼解碼器帶來顯著的效能優勢。呼叫
torch.nested.nested_tensor(data, dtype=dtype, layout=torch.jagged)
核心跟蹤
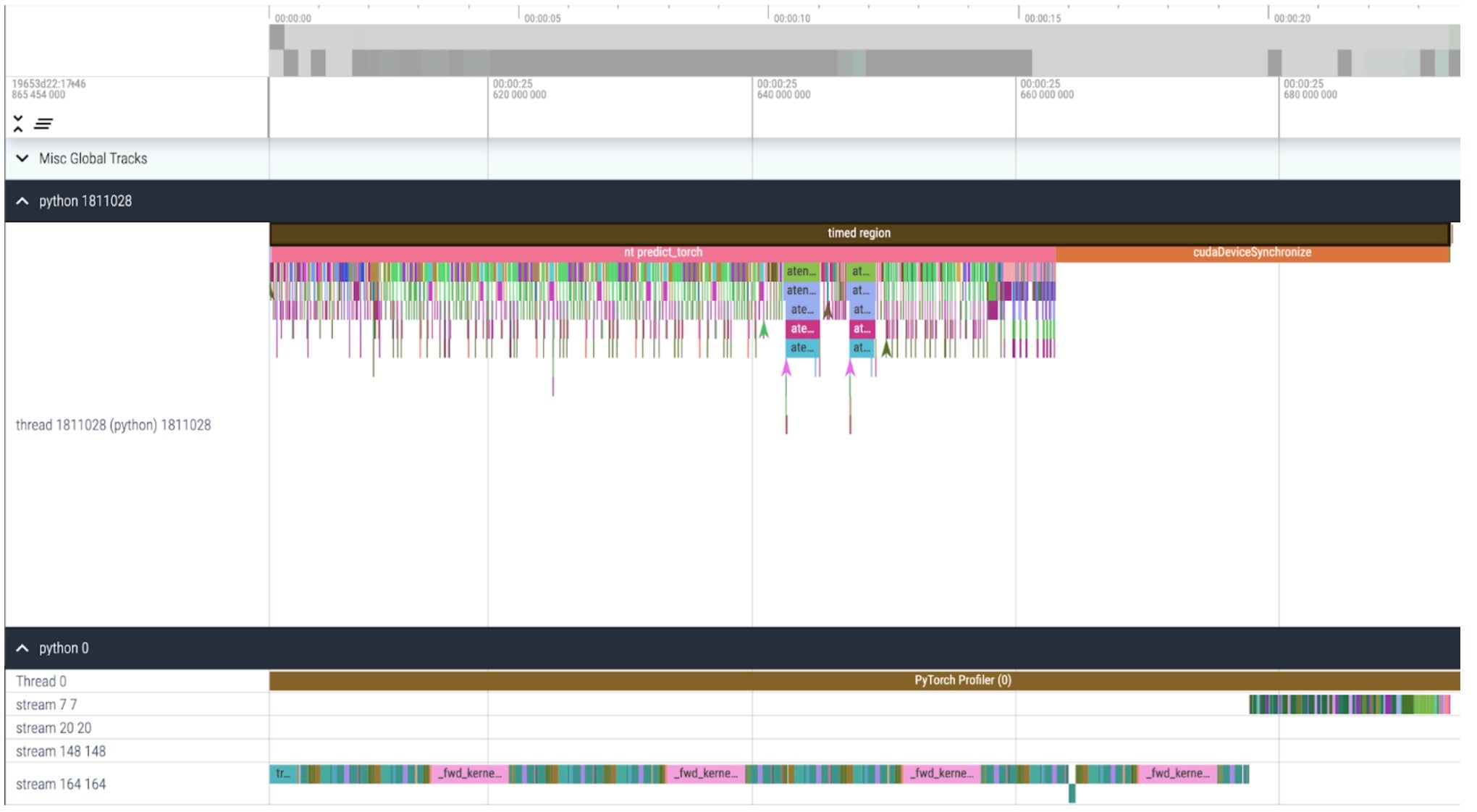

我們現在可以看到,CPU 啟動核心的速度比 GPU 處理核心的速度快得多,並且在我們的計時區域結束時,CPU 會長時間等待 GPU 完成處理(cudaDeviceSynchronize)。我們也不會在 GPU 上看到核心之間有任何空閒時間(空白)。
使用 Nested Tensor,我們觀察到批次大小為 32 及以上更改的以下測量結果。
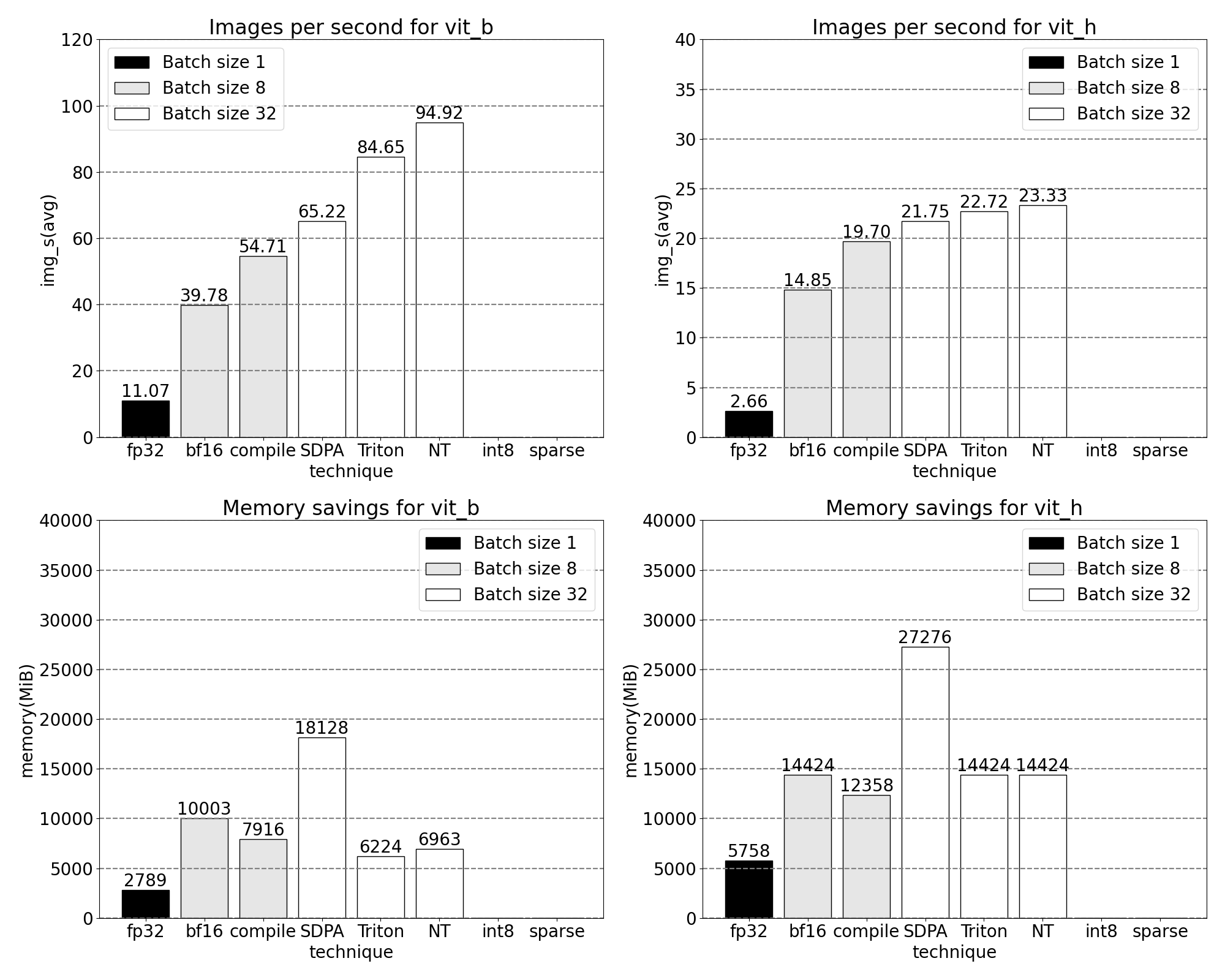
int8:量化和近似矩陣乘法
我們注意到在上面的跟蹤中,現在大量時間花費在 GEMM 核心中。我們已經最佳化到足以讓矩陣乘法在推理中佔用的時間超過縮放點積注意力。
在從 fp32 到 bfloat16 的早期學習基礎上,我們再進一步,透過 int8 量化模擬更低的精度。在量化方法中,我們專注於動態量化,其中模型觀察層可能輸入和權重的範圍,並細分可表達的 int8 範圍以均勻地“分散”觀察到的值。最終,每個浮點輸入都將被對映到 [-128, 127] 範圍內的單個整數。有關更多資訊,請參閱 PyTorch 的量化教程。
降低精度可以立即帶來峰值記憶體節省,但要實現推理加速,我們必須透過 SAM 的操作充分利用 int8。這需要構建一個高效的 int8@int8 矩陣乘法核心,以及從高精度到低精度(量化)以及從低精度到高精度(反量化)的轉換邏輯。利用 torch.compile 的強大功能,我們可以將這些量化和反量化例程編譯並融合到高效的單個核心和矩陣乘法的尾聲中。生成的實現相當短,不到 250 行程式碼。有關 API 和用法的更多資訊,請參閱pytorch-labs/ao。
雖然在推理時量化模型通常會導致一些精度迴歸,但 SAM 對低精度推理特別健壯,精度損失極小。新增量化後,我們現在觀察到 批次大小 32 及以上更改的以下測量結果。
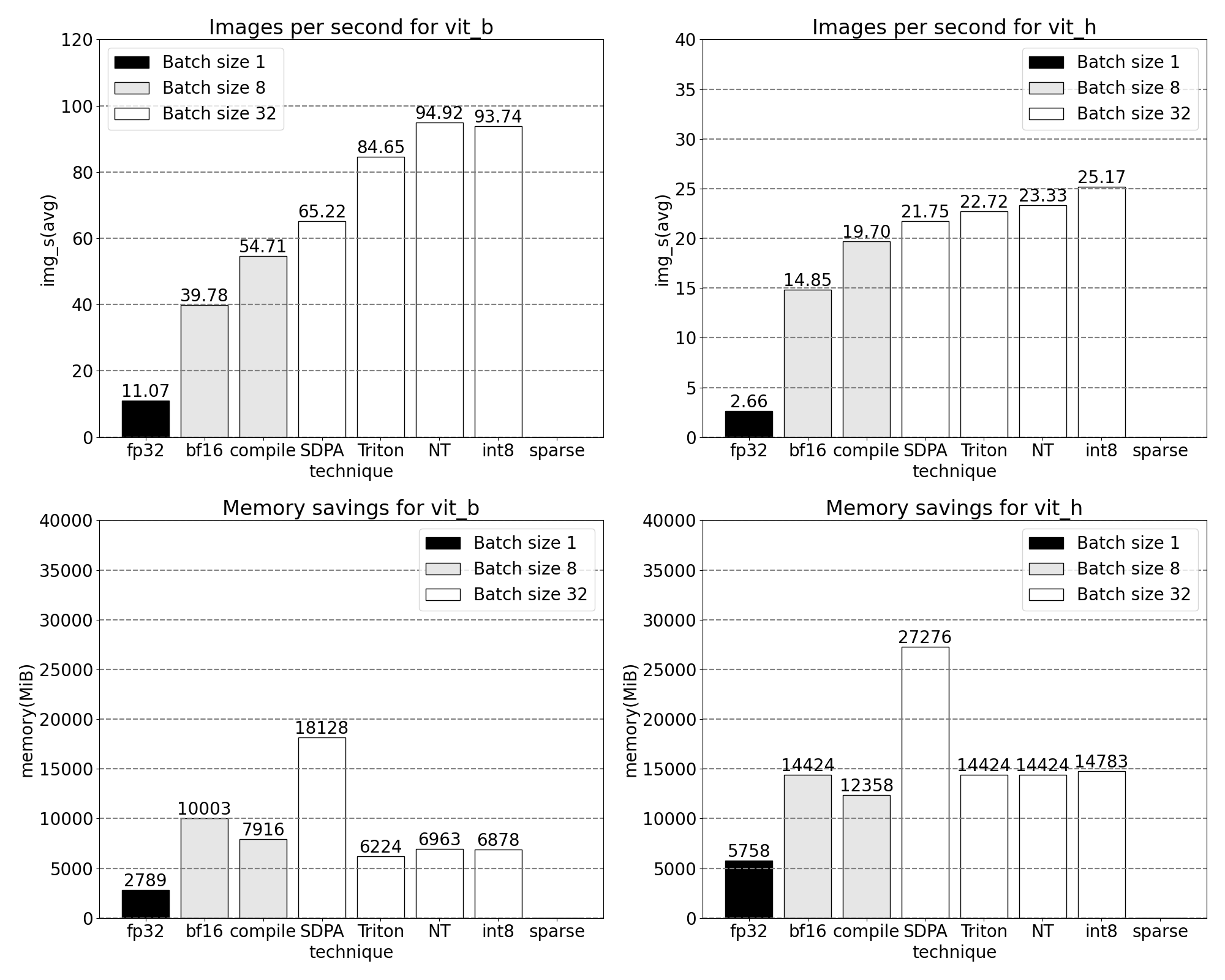
稀疏:半結構化 (2:4) 稀疏性
矩陣乘法仍然是我們的瓶頸。我們可以轉向模型加速策略,採用另一種經典的近似矩陣乘法方法:稀疏化。透過稀疏化我們的矩陣(即,將值置零),我們理論上可以使用更少的位元來儲存權重和啟用張量。我們決定將張量中哪些權重置零的過程稱為剪枝。剪枝背後的思想是,權重張量中的小權重對層(通常是權重與啟用的乘積)的淨輸出貢獻很小。剪除小權重可以潛在地減小模型大小,而不會顯著損失準確性。
剪枝方法多種多樣,從完全非結構化(貪婪地剪枝權重)到高度結構化(一次剪枝張量的大子元件)。方法的選擇並非易事。雖然非結構化剪枝在理論上對準確性的影響最小,但 GPU 在乘以大型密集矩陣時效率很高,在稀疏情況下可能會遭受顯著的效能下降。PyTorch 中支援的一種最新剪枝方法試圖在兩者之間取得平衡,稱為半結構化(或 2:4)稀疏性。這種稀疏儲存將原始張量顯著減少了 50%,同時產生了一個密集張量輸出,可以利用高效能的 2:4 GPU 核心。請看下圖以進行說明。
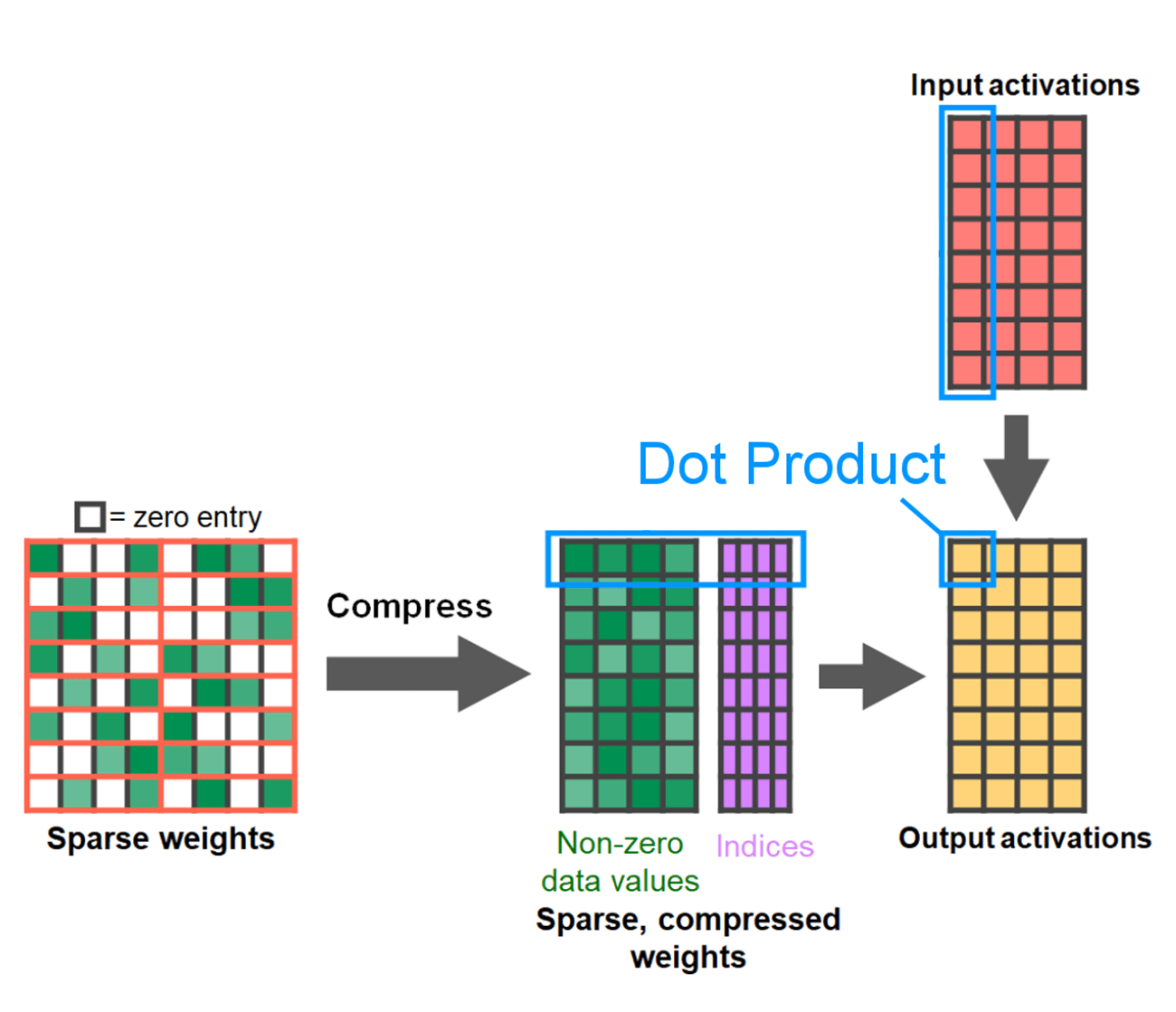
來自developer.nvidia.com/blog/exploiting-ampere-structured-sparsity-with-cusparselt
為了使用這種稀疏儲存格式和相關的快速核心,我們需要對權重進行剪枝,使其符合格式的約束。我們在 1x4 區域中選擇兩個最小的權重進行剪枝,測量效能與精度之間的權衡。將權重從其預設的 PyTorch(“跨步”)佈局更改為這種新的半結構化稀疏佈局很容易。要實現 apply_sparse(model),我們只需要 32 行 Python 程式碼。
import torch
from torch.sparse import to_sparse_semi_structured, SparseSemiStructuredTensor
# Sparsity helper functions
def apply_fake_sparsity(model):
"""
This function simulates 2:4 sparsity on all linear layers in a model.
It uses the torch.ao.pruning flow.
"""
# torch.ao.pruning flow
from torch.ao.pruning import WeightNormSparsifier
sparse_config = []
for name, mod in model.named_modules():
if isinstance(mod, torch.nn.Linear):
sparse_config.append({"tensor_fqn": f"{name}.weight"})
sparsifier = WeightNormSparsifier(sparsity_level=1.0,
sparse_block_shape=(1,4),
zeros_per_block=2)
sparsifier.prepare(model, sparse_config)
sparsifier.step()
sparsifier.step()
sparsifier.squash_mask()
def apply_sparse(model):
apply_fake_sparsity(model)
for name, mod in model.named_modules():
if isinstance(mod, torch.nn.Linear):
mod.weight = torch.nn.Parameter(to_sparse_semi_structured(mod.weight))
透過 2:4 稀疏性,我們觀察到 SAM 在 vit_b 和批次大小為 32 時達到峰值效能。
總結
總結一下,我們很高興宣佈了迄今為止最快的 Segment Anything 實現。我們使用大量新發布的功能,用純 PyTorch 重寫了 Meta 的原始 SAM,且未損失準確性。
- Torch.compile PyTorch 的原生 JIT 編譯器,提供快速、自動化的 PyTorch 操作融合 [教程]
- GPU 量化 透過降低精度操作加速模型 [API]
- 縮放點積注意力 (SDPA) 一種新的、記憶體高效的注意力實現 [教程]
- 半結構化 (2:4) 稀疏性 使用更少的位元儲存權重和啟用來加速模型 [教程]
- 巢狀張量 高度最佳化的鋸齒狀陣列處理,適用於非均勻批次和影像大小 [教程]
- Triton 核心。自定義 GPU 操作,透過 Triton 輕鬆構建和最佳化。
有關如何重現此部落格文章中資料的更多詳細資訊,請檢視segment-anything-fast 的 experiments 資料夾。如果您遇到任何技術問題,請隨時與我們聯絡或提出問題。
在我們的下一篇文章中,我們很高興能分享我們 PyTorch 原生 LLM 類似的效能提升!
致謝
我們感謝 Meta 的xFormers團隊,包括 Daniel Haziza 和 Francisco Massa,他們編寫了 SDPA 核心並幫助我們設計了定製的一次性 Triton 核心。