這篇博文是多系列部落格的第二部分,重點介紹如何使用純原生 PyTorch 加速生成式 AI 模型。我們很高興能分享大量新發布的 PyTorch 效能功能,並提供實際示例,以展示我們能將 PyTorch 原生效能推向多遠。在第一部分中,我們展示瞭如何僅使用純原生 PyTorch 將Segment Anything 加速 8 倍以上。在本篇部落格中,我們將專注於 LLM 最佳化。
在過去一年中,生成式 AI 用例的受歡迎程度爆炸式增長。文字生成是一個特別受歡迎的領域,在開源專案(如llama.cpp、vLLM 和MLC-LLM)中湧現出大量創新。
雖然這些專案效能強大,但它們通常會在易用性方面做出權衡,例如需要將模型轉換為特定格式或構建和釋出新的依賴項。這引出了一個問題:我們僅使用純原生 PyTorch,能多快地執行 Transformer 推理?
正如我們在最近的PyTorch 開發者大會上宣佈的那樣,PyTorch 團隊從頭開始編寫了一個 LLM,其速度比基線快近 10 倍,且沒有精度損失,所有這些都使用了原生 PyTorch 最佳化。我們利用了廣泛的最佳化,包括
- Torch.compile:用於 PyTorch 模型的編譯器
- GPU 量化:透過降低精度操作來加速模型
- 推測解碼:使用小型“草稿”模型預測大型“目標”模型的輸出來加速 LLM
- 張量並行:透過在多個裝置上執行模型來加速模型。
更好的是,我們可以在不到 1000 行原生 PyTorch 程式碼中完成。
如果這足以讓您直接投入程式碼,請在https://github.com/pytorch-labs/gpt-fast檢視!

注意:所有這些基準測試都將重點關注延遲(即批次大小=1)。除非另有說明,所有基準測試均在 A100-80GB 上執行,功耗限制為 330W。
起點 (25.5 tok/s)
讓我們從一個極其基本和簡單的實現開始。
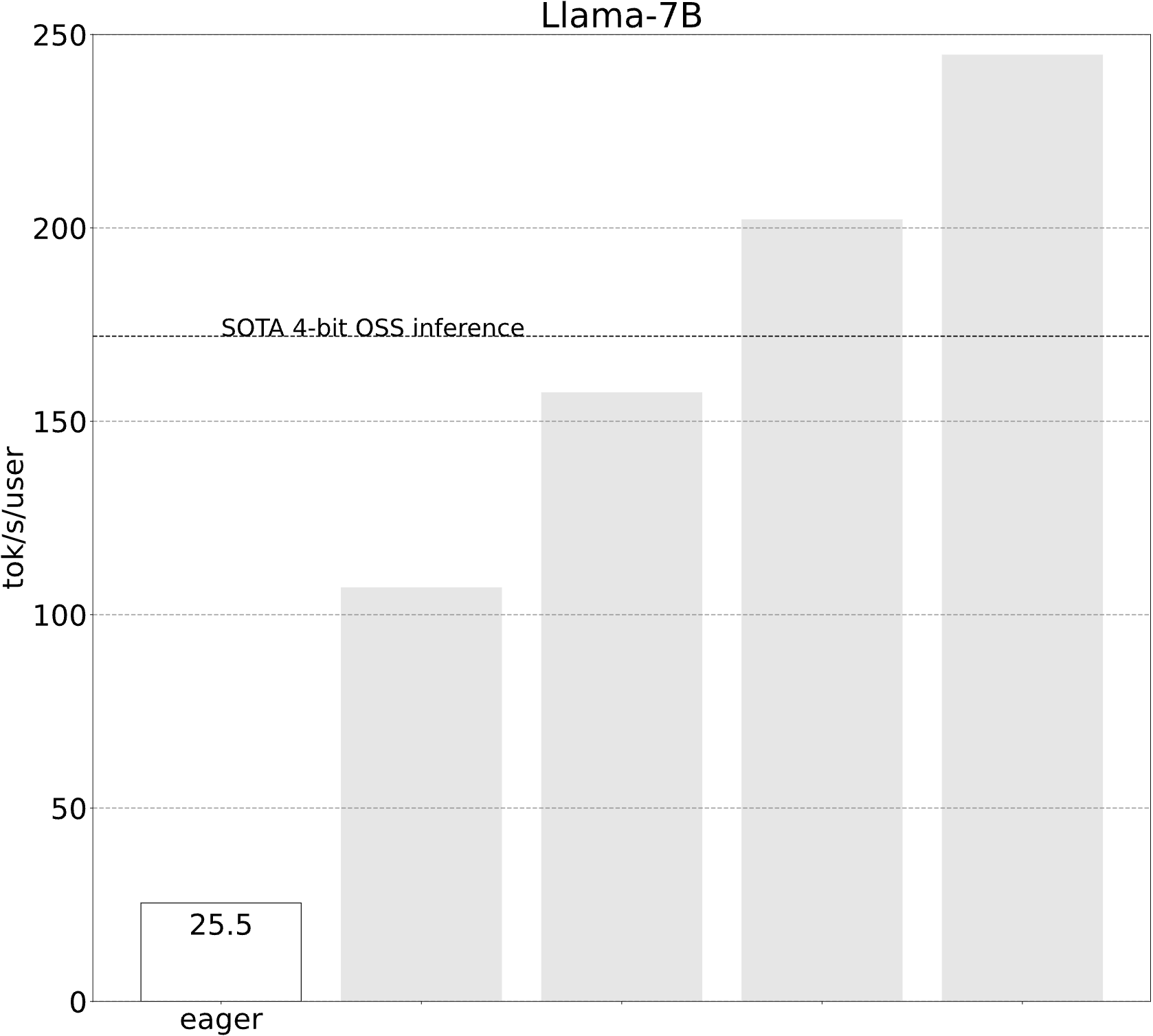
遺憾的是,這表現不佳。但為什麼呢?檢視追蹤會揭示答案——它嚴重受到 CPU 開銷的限制!這意味著我們的 CPU 無法足夠快地告訴 GPU 該做什麼,以致 GPU 無法充分利用。

想象一下 GPU 是一個擁有巨大計算能力的超級工廠。然後,想象一下 CPU 是一些信使,在 GPU 之間來回傳遞指令。請記住,在大型深度學習系統中,GPU 負責完成 100% 的工作!在這樣的系統中,CPU 的唯一作用是告訴 GPU 它應該做什麼工作。

因此,CPU 跑過去告訴 GPU 執行一個“加法”,但是當 CPU 能夠給 GPU 另一塊工作時,GPU 早已完成了前一塊工作。
儘管 GPU 需要執行數千次計算,而 CPU 只需進行協調工作,但這卻出奇地常見!造成這種情況的原因有很多,從 CPU 可能正在執行一些單執行緒 Python 到如今 GPU 速度驚人。
無論原因如何,我們現在都處於 開銷受限狀態。那麼,我們能做什麼呢?一、我們可以用 C++ 重寫我們的實現,甚至完全放棄框架並編寫原始 CUDA。或者……我們可以一次性向 GPU 傳送更多工作。

透過一次性發送大量工作,我們可以讓 GPU 保持忙碌!儘管在訓練期間,這可能只需增加批次大小即可實現,但在推理期間我們該怎麼做呢?
進入 torch.compile。
第一步:透過 torch.compile 和靜態 kv-cache 減少 CPU 開銷 (107.0 tok/s)
Torch.compile 允許我們將更大的區域捕獲到一個編譯區域中,特別是在執行 `mode="reduce-overhead"` 時,它在減少 CPU 開銷方面非常有效。在這裡,我們還指定 `fullgraph=True`,這驗證了模型中沒有“圖中斷”(即 torch.compile 無法編譯的部分)。換句話說,它確保 torch.compile 正在充分發揮其潛力。
要應用它,我們只需用它包裝一個函式(或模組)即可。
torch.compile(decode_one_token, mode="reduce-overhead", fullgraph=True)
然而,這裡有一些細微之處,使得人們很難透過將 torch.compile 應用於文字生成來獲得顯著的效能提升。
第一個障礙是 kv-cache。kv-cache 是一種推理時最佳化,它快取為先前 token 計算的啟用(有關更深入的解釋,請參見此處)。然而,隨著我們生成更多 token,kv-cache 的“邏輯長度”會增長。這帶來兩個問題。一是每次 cache 增長時重新分配(和複製!)kv-cache 都很昂貴。另一個是這種動態性使得減少開銷更加困難,因為我們無法再利用 cudagraphs 等方法。
為了解決這個問題,我們使用了一個“靜態”kv-cache,這意味著我們靜態分配 kv-cache 的最大大小,然後在計算的注意力部分掩蓋未使用的值。

第二個障礙是預填充階段。Transformer 文字生成最好被視為一個兩階段過程:1. 預填充,其中處理整個提示,2. 解碼,其中自迴歸地生成每個 token。
儘管一旦 kv-cache 變為靜態,解碼就可以完全靜態化,但由於提示長度可變,預填充階段仍然需要更多的動態性。因此,我們實際上需要使用不同的編譯策略來編譯這兩個階段。

雖然這些細節有些棘手,但實際實現一點也不難(請參見 gpt-fast)!效能提升是巨大的。
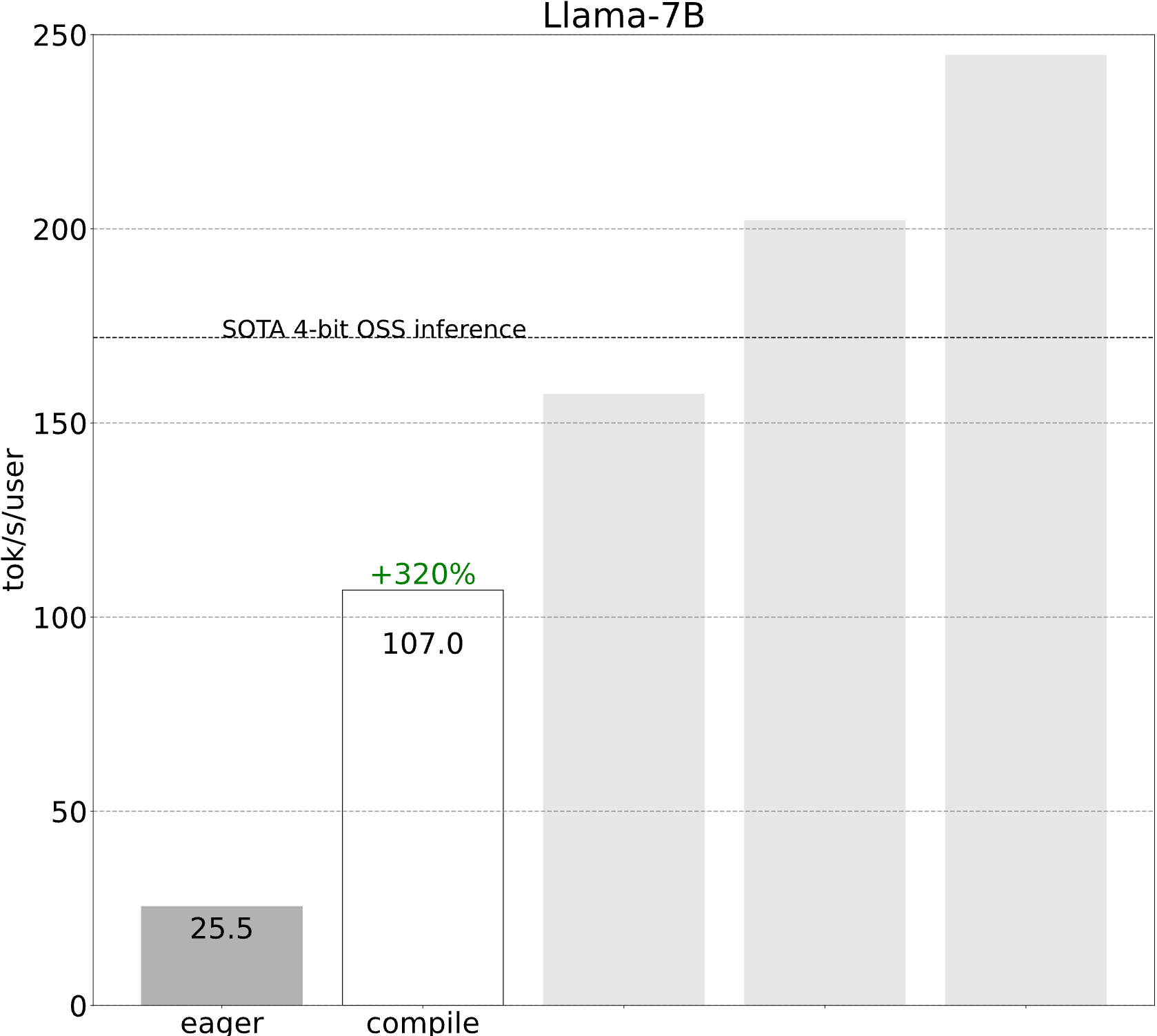
突然之間,我們的效能提高了 4 倍以上!當工作負載受開銷限制時,這種效能提升通常很常見。
旁註:torch.compile 如何提供幫助?
值得仔細分析 torch.compile 究竟是如何提高效能的。有兩個主要因素導致 torch.compile 的效能提升。
第一個因素,如上所述,是開銷減少。Torch.compile 能夠透過各種最佳化來減少開銷,其中最有效的一種叫做CUDAGraphs。雖然 torch.compile 在設定“reduce-overhead”時會自動為您應用此功能,從而省去了您手動在沒有 torch.compile 的情況下進行此操作所需的額外工作和程式碼。
然而,第二個因素是 torch.compile 只是生成了更快的核心。在上面的解碼基準測試中,torch.compile 實際上從頭開始生成了每一個核心,包括矩陣乘法和注意力!更酷的是,這些核心實際上比內建的替代方案(CuBLAS 和 FlashAttention2)更快!
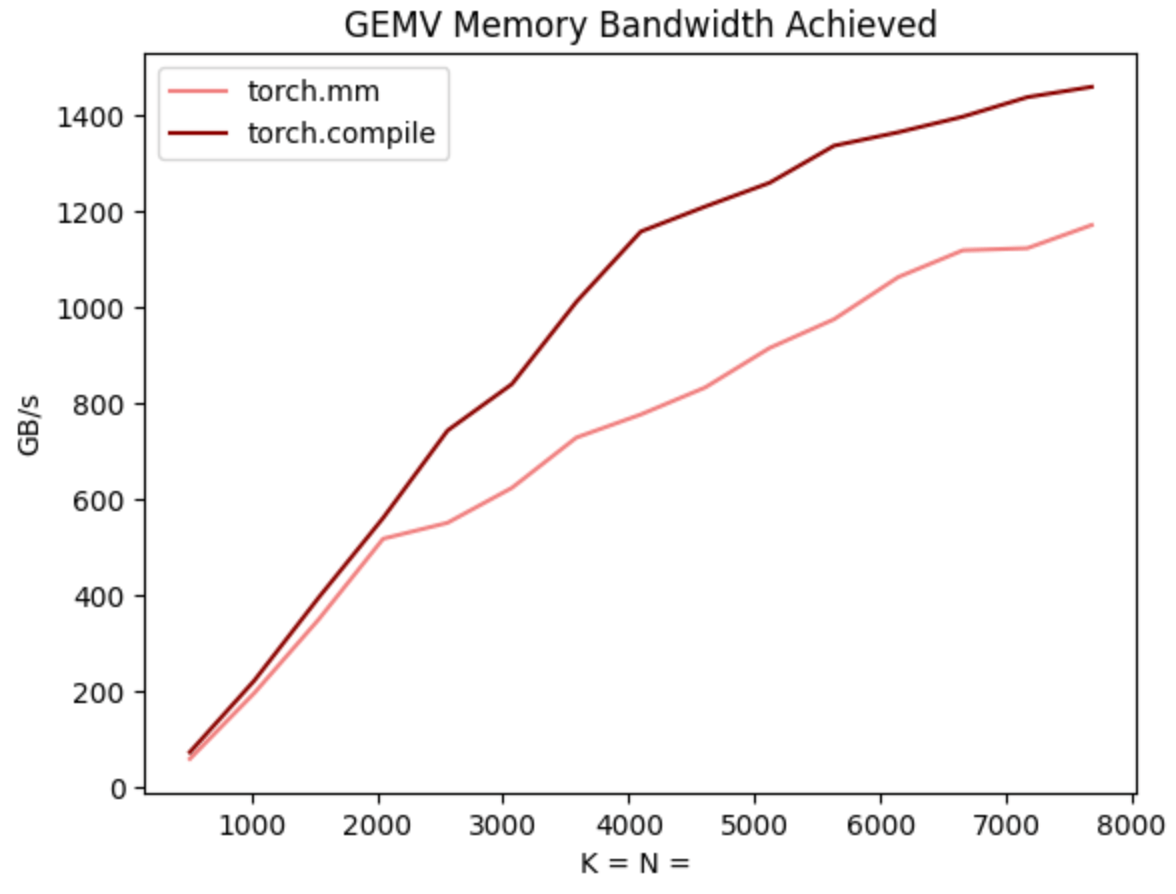
這對於許多人來說可能聽起來難以置信,考慮到編寫高效的矩陣乘法/注意力核心是多麼困難,以及在 CuBLAS 和 FlashAttention 上投入了多少人力。然而,這裡的關鍵在於,Transformer 解碼具有非常不尋常的計算特性。特別是,由於 KV-cache,對於 BS=1,Transformer 中的每一次矩陣乘法實際上都是矩陣向量乘法。
這意味著計算完全受 記憶體頻寬限制,因此,在編譯器自動生成的範圍內。事實上,當我們對照 CuBLAS 對 torch.compile 的矩陣向量乘法進行基準測試時,我們發現 torch.compile 的核心實際上要快得多!

步驟 2:透過 int8 僅權重量化緩解記憶體頻寬瓶頸 (157.4 tok/s)
那麼,既然我們已經看到應用 torch.compile 帶來了巨大的加速,是否有可能做得更好呢?思考這個問題的一種方法是計算我們與理論峰值有多接近。在這種情況下,最大的瓶頸是將權重從 GPU 全域性記憶體載入到暫存器的成本。換句話說,每次前向傳播都需要我們“觸控”GPU 上的每個引數。那麼,我們理論上能多快地“觸控”模型中的每個引數呢?
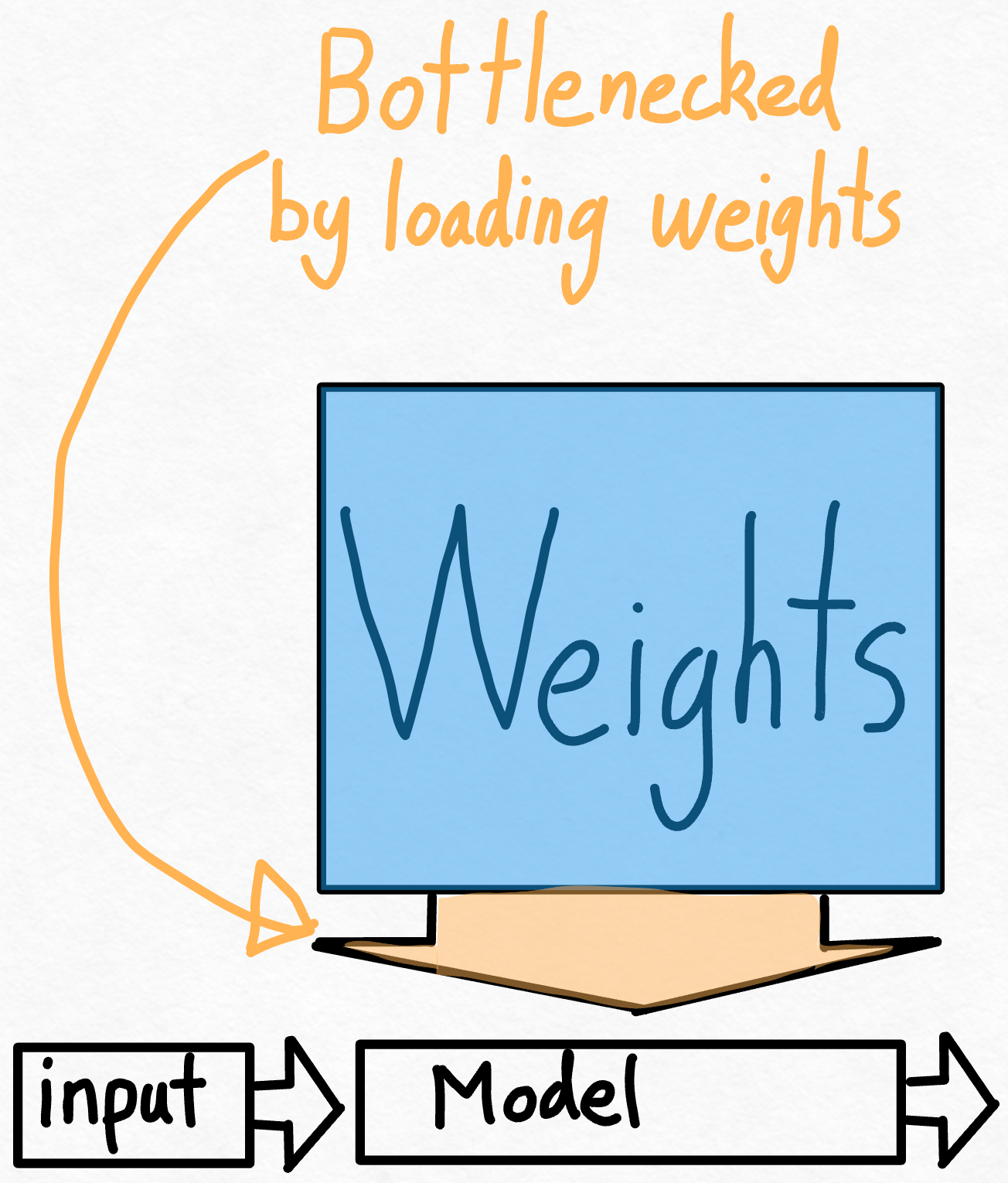
為了衡量這一點,我們可以使用 模型頻寬利用率 (MBU)。 這衡量了我們在推理期間能夠使用的記憶體頻寬的百分比。
計算起來很簡單。我們只需將模型的總大小(引數數量 * 每個引數的位元組數)乘以我們每秒可以執行的推理次數。然後,我們將此結果除以 GPU 的峰值頻寬即可得到 MBU。

例如,在上述案例中,我們有一個 7B 引數模型。每個引數以 fp16 儲存(每個引數 2 位元組),我們實現了 107 token/s。最後,我們的 A100-80GB 具有理論上 2 TB/s 的記憶體頻寬。
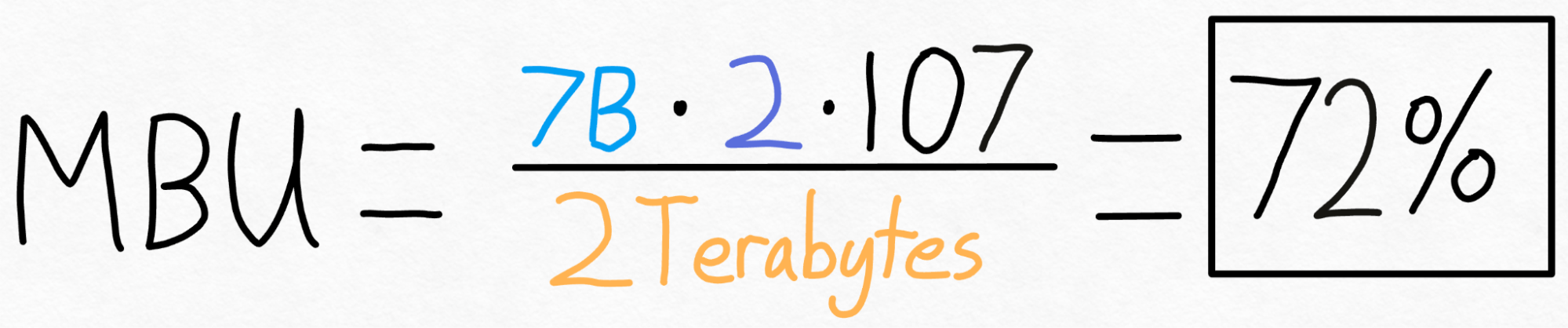
把所有這些加起來,我們得到 **72% MBU!** 這相當不錯了,考慮到即使只是複製記憶體也很難突破 85%。
但是……這確實意味著我們已經非常接近理論極限了,而且我們顯然受限於從記憶體載入權重。無論我們做什麼——如果不以某種方式改變問題陳述,我們可能只能再擠出 10% 的效能。
讓我們再看看上面的方程。我們無法真正改變模型中的引數數量。我們無法真正改變 GPU 的記憶體頻寬(嗯,除非支付更多費用)。但是,我們 可以 改變每個引數的儲存位元組數!

因此,我們來到了下一個技術——int8 量化。這裡的想法很簡單。如果從記憶體載入權重是我們的主要瓶頸,為什麼我們不把權重做得更小呢?
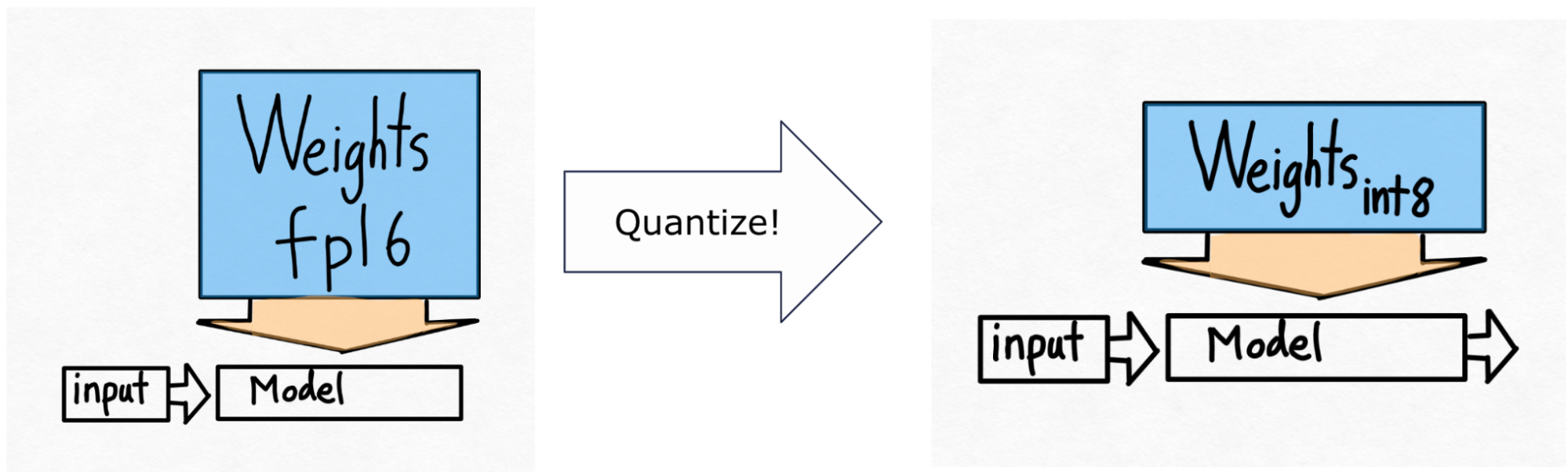
請注意,這 僅 對權重進行量化——計算本身仍然以 bf16 完成。這使得這種形式的量化易於應用,並且幾乎不會導致精度下降。
此外,torch.compile 還可以輕鬆生成用於 int8 量化的高效程式碼。讓我們再次看看上面的基準測試,這次包含了 int8 僅權重 量化。

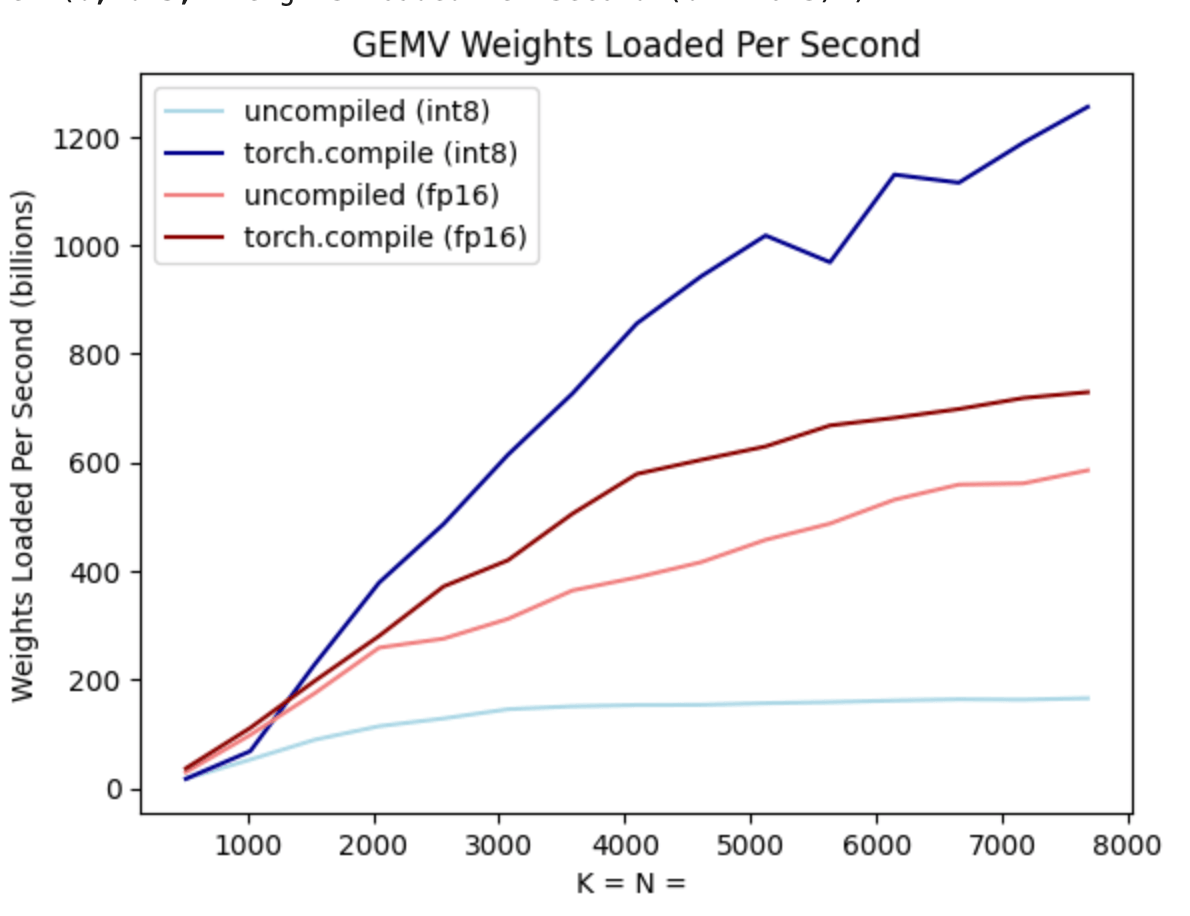
正如你從深藍色線(torch.compile + int8)中看到的,使用 torch.compile + int8 僅權重 量化時,效能有了顯著提升!此外,淺藍色線(無 torch.compile + int8)實際上比 fp16 效能差得多!這是因為為了利用 int8 量化的效能優勢,我們需要融合核心。這展示了 torch.compile 的一個優點——這些核心可以為使用者自動生成!
將 int8 量化應用於我們的模型,我們看到了 50% 的效能提升,使我們達到 157.4 tokens/s!
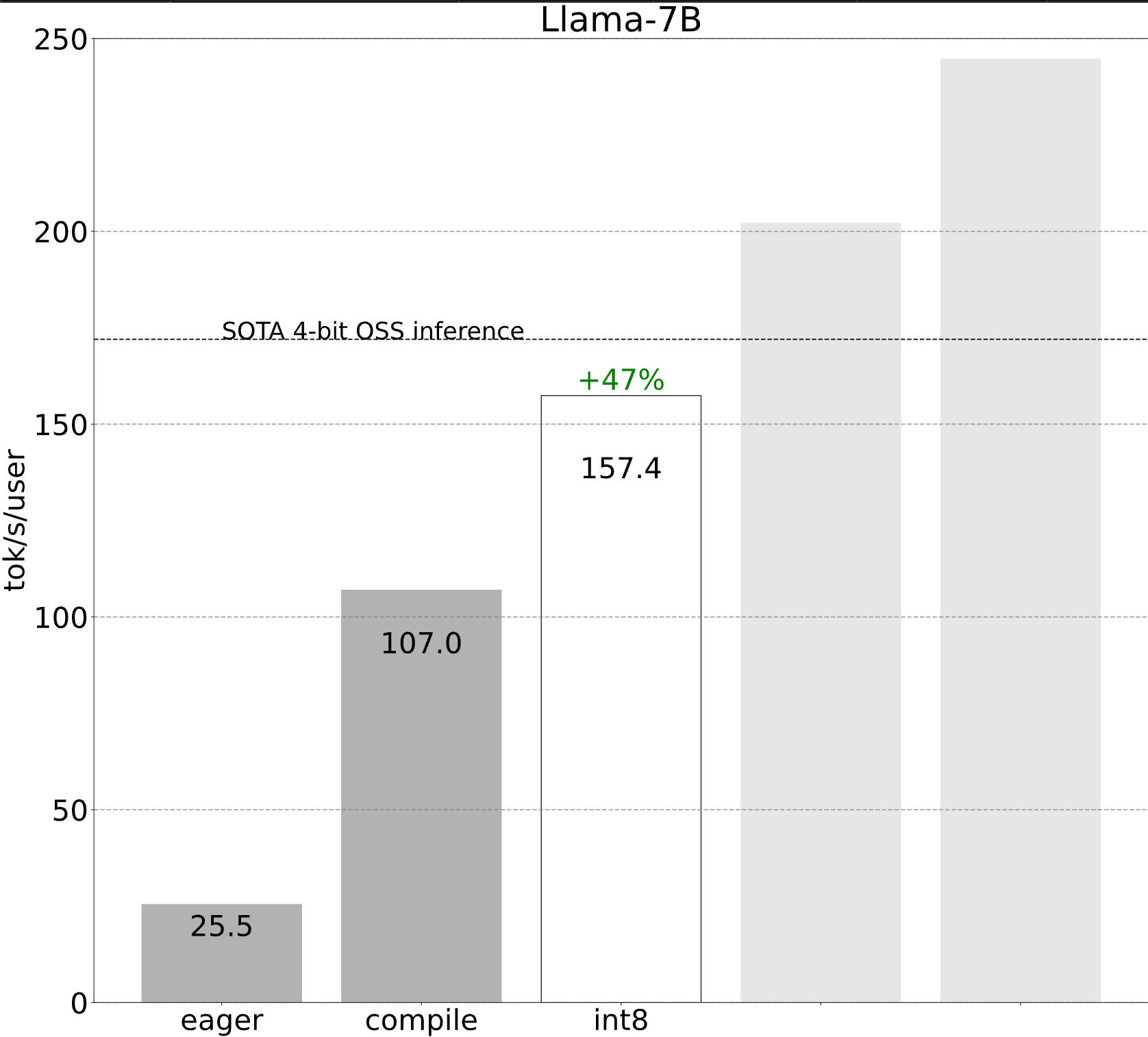
第三步:利用推測解碼重新構建問題 (202.1 tok/s)
即使在使用量化等技術之後,我們仍然面臨另一個問題。為了生成 100 個 token,我們必須載入 100 次權重。
即使權重經過量化,我們仍然必須一遍又一遍地載入權重,每生成一個 token 就載入一次!有沒有辦法解決這個問題?
乍一看,答案似乎是否定的——我們的自迴歸生成存在嚴格的序列依賴。然而,事實證明,透過利用推測解碼,我們能夠打破這種嚴格的序列依賴並獲得加速!
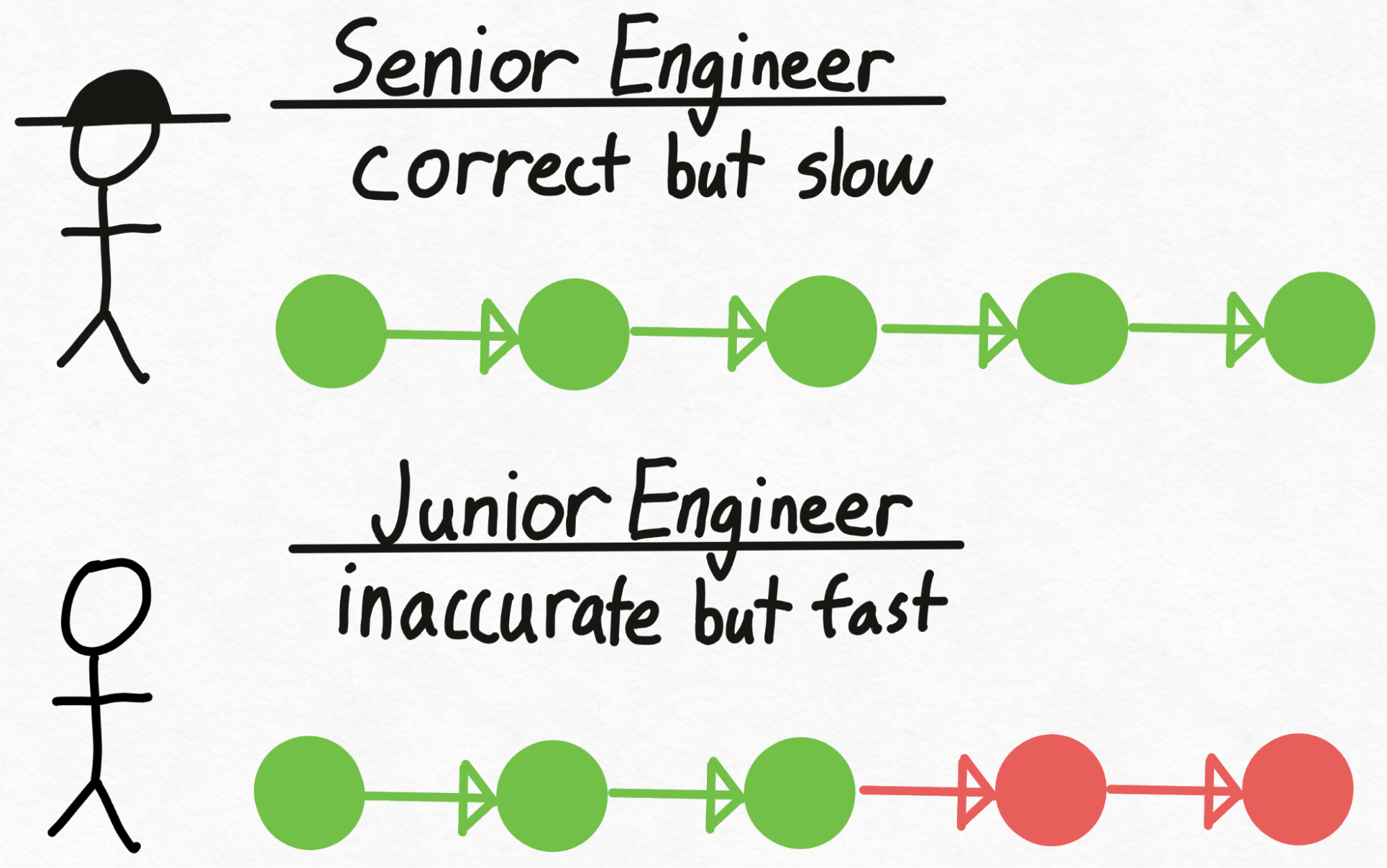
想象一下,你有一位高階工程師(名叫 Verity),他能做出正確的技術決策,但編寫程式碼相當慢。然而,你還有一位初級工程師(名叫 Drake),他並不總是能做出正確的技術決策,但他編寫程式碼的速度比 Verity 快得多(也更便宜!)。我們如何利用 Drake(初級工程師)更快地編寫程式碼,同時確保我們仍然做出正確的技術決策?

首先,Drake 經歷編寫程式碼的勞動密集型過程,在此過程中做出技術決策。接下來,我們將程式碼交給 Verity 稽核。

在審查程式碼時,Verity 可能會決定 Drake 做出的前 3 個技術決策是正確的,但最後 2 個需要重做。於是,Drake 回去,拋棄了他最後 2 個決策,並從那裡重新開始編碼。
值得注意的是,儘管 Verity(高階工程師)只看了一次程式碼,但我們能夠生成 3 塊經過驗證的程式碼,與她自己編寫的程式碼完全相同!因此,假設 Verity 稽核程式碼的速度比她自己編寫這 3 塊程式碼所需的時間要快,那麼這種方法就會勝出。
在 transformer 推理的背景下,Verity 將由我們希望獲得其輸出的較大模型扮演,稱為 驗證器模型。同樣,Drake 將由一個比大模型生成文字快得多的較小模型扮演,稱為 草稿模型。因此,我們將使用草稿模型生成 8 個 token,然後使用驗證器模型並行處理所有這八個 token,丟棄不匹配的 token。
如上所述,推測解碼的一個關鍵特性是 它不會改變輸出的質量。只要使用草稿模型生成 token + 驗證 token 所花費的時間少於生成這些 token 所需的時間,我們就會領先。
在原生 PyTorch 中實現這一切的好處之一是,這項技術實際上非常容易實現!這是整個實現,大約 50 行原生 PyTorch 程式碼。

雖然推測解碼保證了我們在數學上與常規生成結果相同,但它的執行時效能確實會因生成的文字以及草稿模型和驗證器模型的對齊程度而異。例如,執行 CodeLlama-34B + CodeLlama-7B 時,我們能夠將生成程式碼的 tokens/s 提高 2 倍。另一方面,當使用 Llama-7B + TinyLlama-1B 時,我們只能將 tokens/s 提高約 1.3 倍。
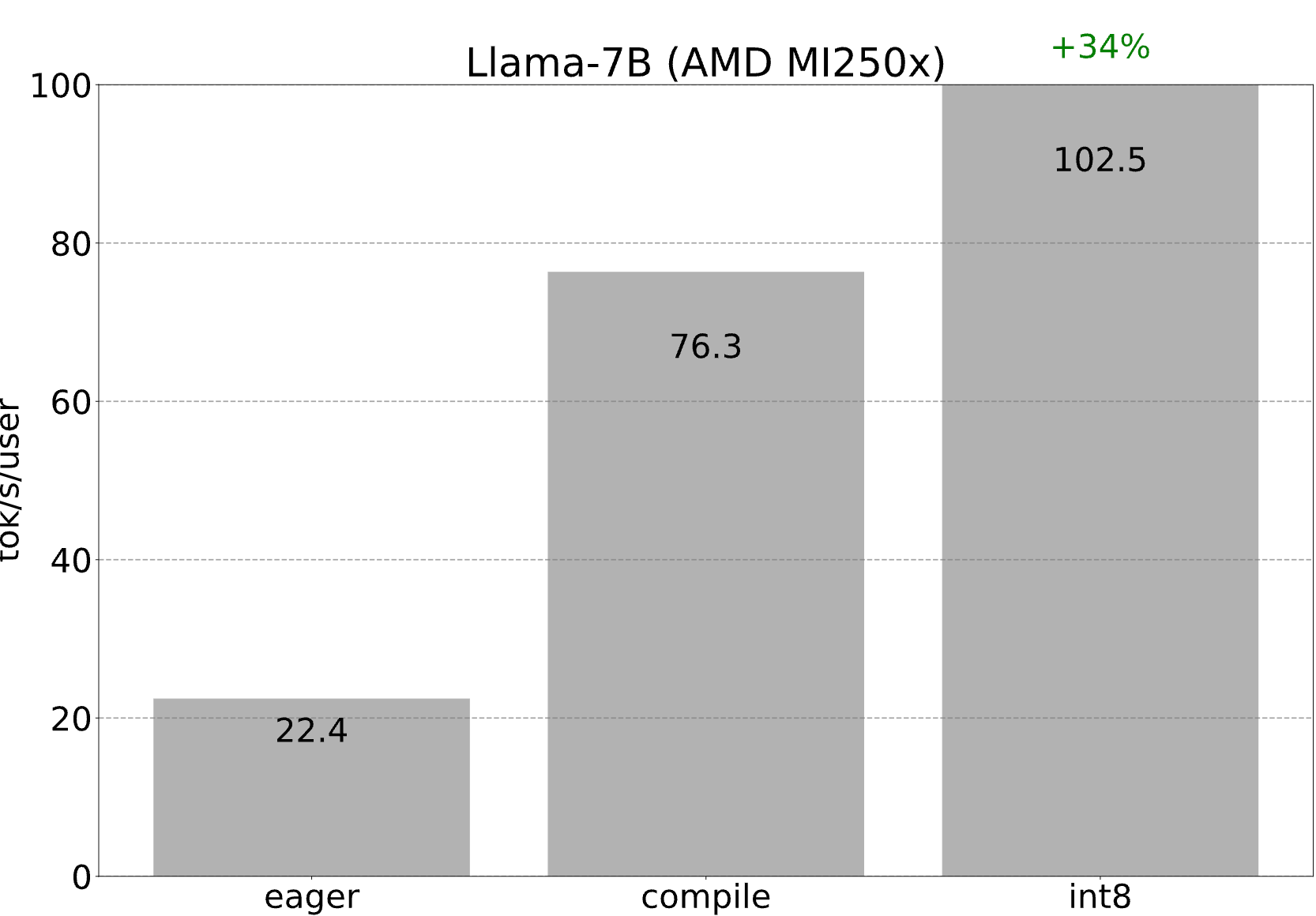
旁註:在 AMD 上執行此功能
如上所述,解碼中的每個核心都由 torch.compile 從頭開始生成,並轉換為 OpenAI Triton。由於 AMD 有一個torch.compile 後端(以及一個 Triton 後端),我們只需經歷上述所有最佳化……但在 AMD GPU 上!透過 int8 量化,我們能夠在一個 MI250x 的一個 GCD(即一半)上達到 102.5 tokens/s!
第四步:透過 int4 量化和 GPTQ 進一步減小權重大小 (202.1 tok/s)
當然,如果將權重從 16 位減小到 8 位可以透過減少需要載入的位元組數來提高速度,那麼將權重減小到 4 位將導致更大的速度提升!
不幸的是,當將權重減小到 4 位時,模型的準確性開始成為一個更大的問題。從我們初步評估來看,儘管使用 int8 僅權重 量化沒有明顯的精度下降,但使用 int4 僅權重 量化卻有。
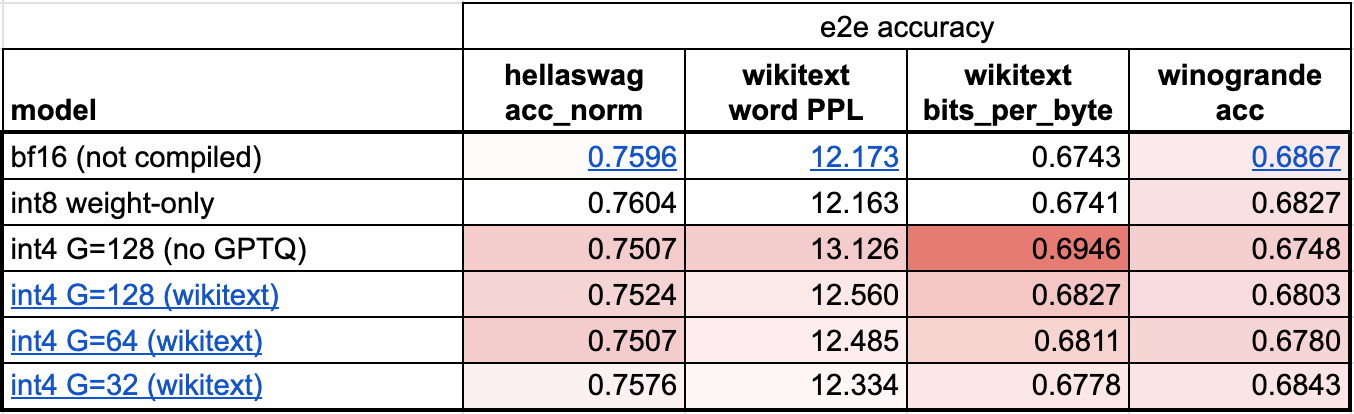
我們可以使用兩種主要技巧來限制 int4 量化的精度下降。
第一個是採用更細粒度的縮放因子。理解縮放因子的一種方法是,當我們有一個量化張量表示時,它介於浮點張量(每個值都有一個縮放因子)和整數張量(沒有值有縮放因子)之間。例如,在 int8 量化中,我們每行有一個縮放因子。然而,如果我們需要更高的精度,我們可以將其更改為“每 32 個元素一個縮放因子”。我們選擇 32 的組大小是為了最大程度地減少精度下降,這也是社群中的一個常見選擇。
另一個是使用比簡單地舍入權重更高階的量化策略。例如,像GPTQ這樣的方法利用示例資料來更準確地校準權重。在這種情況下,我們基於 PyTorch 最近釋出的torch.export在儲存庫中原型化了 GPTQ 的實現。
此外,我們需要將 int4 反量化與矩陣向量乘法融合的核心。在這種情況下,torch.compile 不幸無法從頭開始生成這些核心,因此我們利用了 PyTorch 中的一些手寫 CUDA 核心。
這些技術需要一些額外的工作,但將它們結合起來會帶來更好的效能!
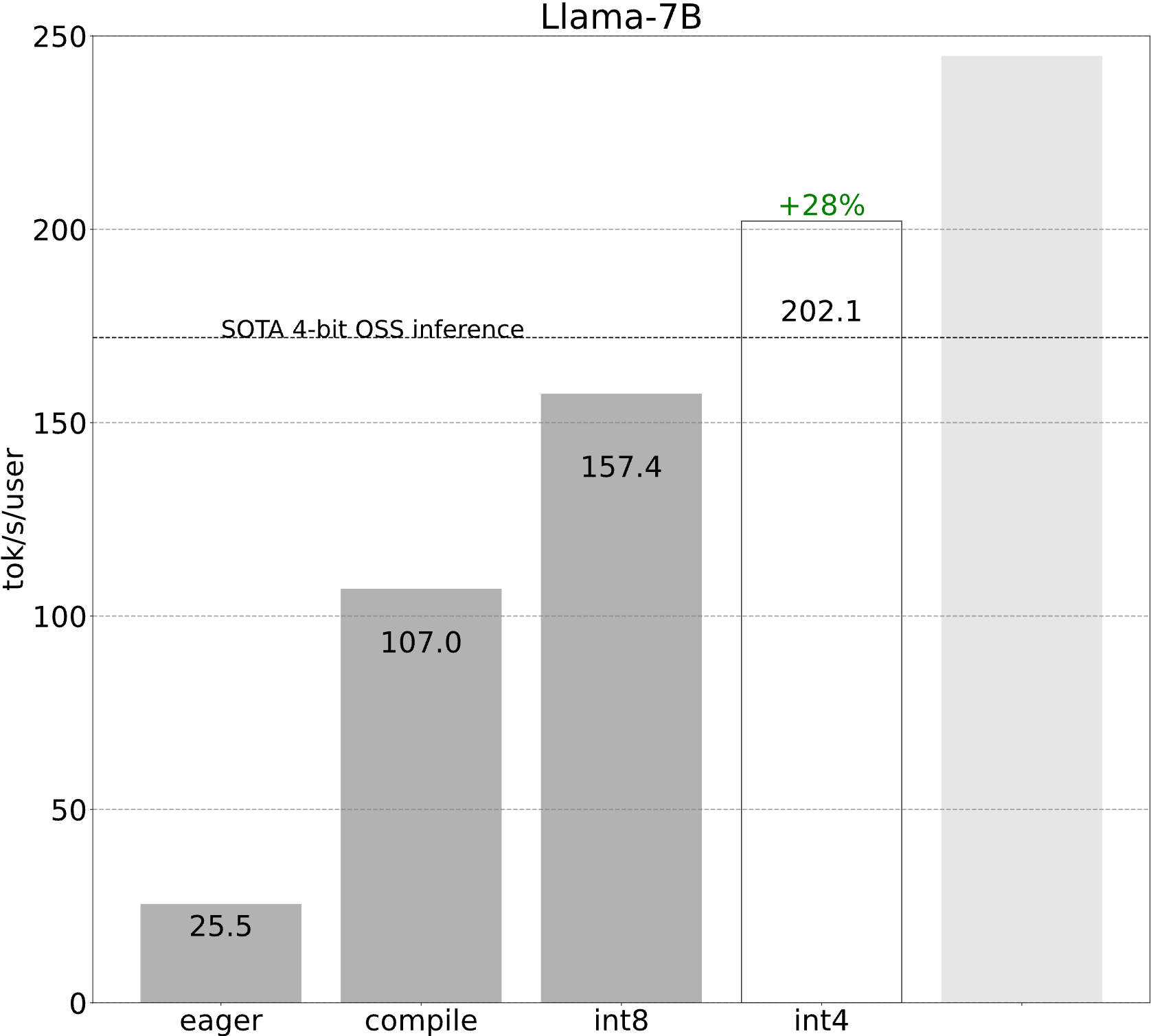
第五步:將所有技術結合起來 (244.7 tok/s)
最後,我們可以將所有技術結合起來,以實現更好的效能!
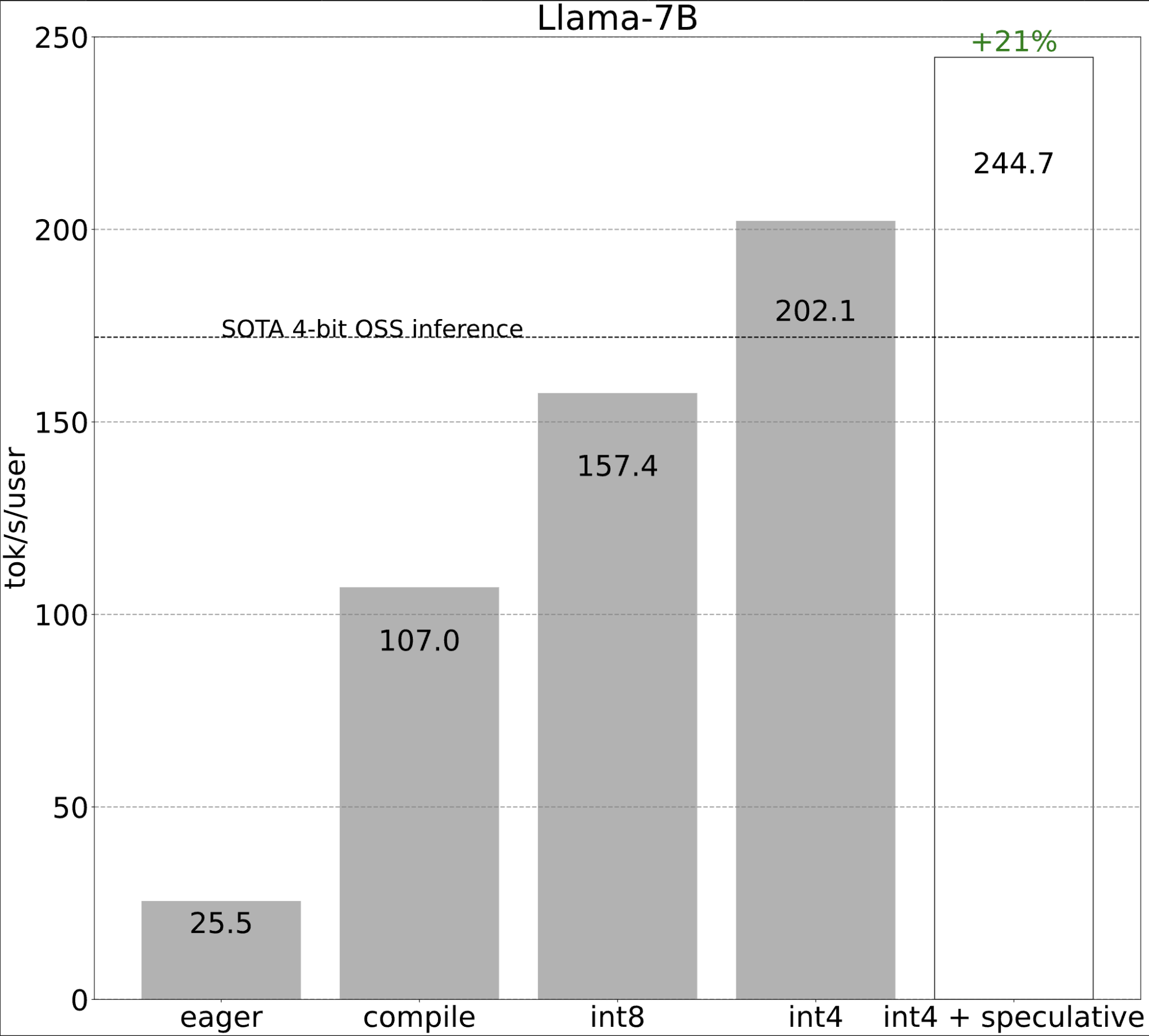
第六步:使用張量並行
到目前為止,我們一直將自己限制在單個 GPU 上最小化延遲。然而,在許多設定中,我們都可以訪問多個 GPU。這使我們能夠進一步改善延遲!
為了直觀地理解為什麼這能提高我們的延遲,讓我們看看 MBU 的前一個方程,特別是分母。在多個 GPU 上執行使我們能夠訪問更多的記憶體頻寬,從而獲得更高的潛在效能。
至於選擇哪種並行策略,請注意,為了減少單個示例的延遲,我們需要能夠同時跨多個裝置利用我們的記憶體頻寬。這意味著我們需要將一個 token 的處理分散到多個裝置上。換句話說,我們需要使用張量並行。
幸運的是,PyTorch 也提供了與 torch.compile 相容的張量並行低階工具。我們還在開發更高階的 API 來表達張量並行,敬請期待!
然而,即使沒有更高級別的 API,新增張量並行仍然非常容易。我們的實現僅需150 行程式碼,並且不需要任何模型更改。

我們仍然可以利用前面提到的所有最佳化,這些最佳化都可以繼續與張量並行組合。將這些結合起來,我們能夠以 55 tokens/s 的速度使用 int8 量化為 Llama-70B 提供服務!
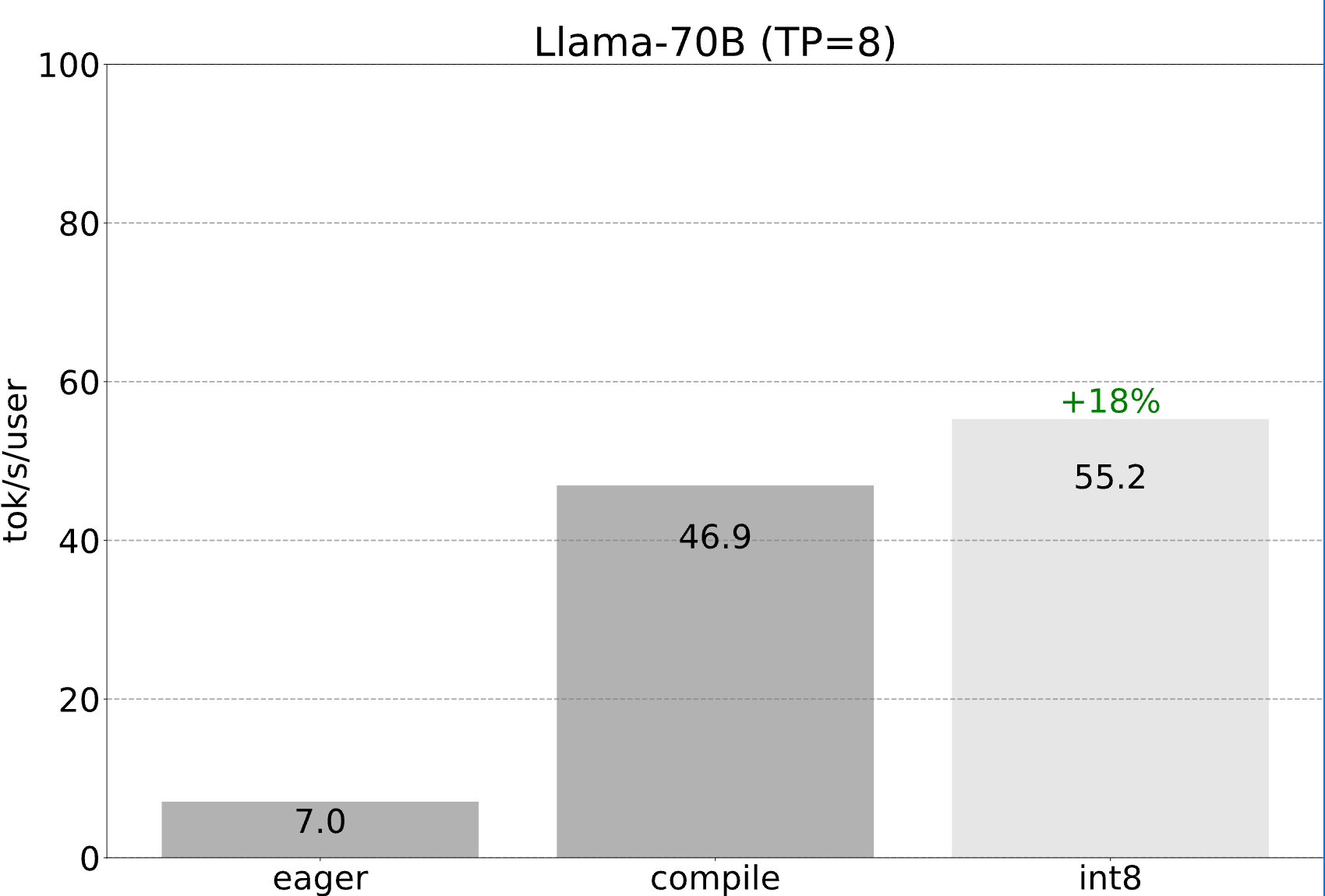
總結
讓我們看看我們能夠完成什麼。
- 簡潔性:忽略量化,model.py (244 LOC) + generate.py (371 LOC) + tp.py (151 LOC) 總共 766 LOC,實現了快速推理 + 推測解碼 + 張量並行。
- 效能:對於 Llama-7B,我們能夠使用編譯 + int4 量化 + 推測解碼達到 241 tok/s。對於 Llama-70B,我們還可以加入張量並行達到 80 tok/s。這些都接近或超越了 SOTA 效能資料!
PyTorch 始終提供簡潔性、易用性和靈活性。然而,藉助 torch.compile,我們還可以兼顧效能。
程式碼可以在這裡找到:https://github.com/pytorch-labs/gpt-fast。我們希望社群覺得它有用。我們這個倉庫的目標不是提供另一個供人們匯入的庫或框架。相反,我們鼓勵使用者複製貼上、分支和修改倉庫中的程式碼。
致謝
我們要感謝活躍的開源社群對擴充套件 LLM 的持續支援,其中包括
- Lightning AI 對 pytorch 和 flash attention、int8 量化以及 LoRA 微調工作的支援。
- GGML 推動了 LLM 在裝置上的快速推理
- Andrej Karpathy 率先提出了簡單、可解釋且快速的 LLM 實現
- MLC-LLM 推動了異構硬體上的 4 位量化效能