在這篇文章中,我們介紹了一個最佳化的 Triton BF16 分組 GEMM 核心,用於在專家混合 (MoE) 模型(例如 DeepSeekv3)上執行訓練和推理。
分組 GEMM 在一次核心呼叫中對輸入張量的多個切片(組)應用獨立的 GEMM。在基線 PyTorch 實現中,這些 GEMM 將在組的 for 迴圈中執行,每次迭代啟動一個核心。
我們的核心在 DeepSeekv3 訓練中,與手動 PyTorch 迴圈實現相比,在 NVIDIA H100 GPU 上實現了高達 2.62 倍的加速。我們討論了所利用的 Triton 核心最佳化技術,並展示了端到端的結果。
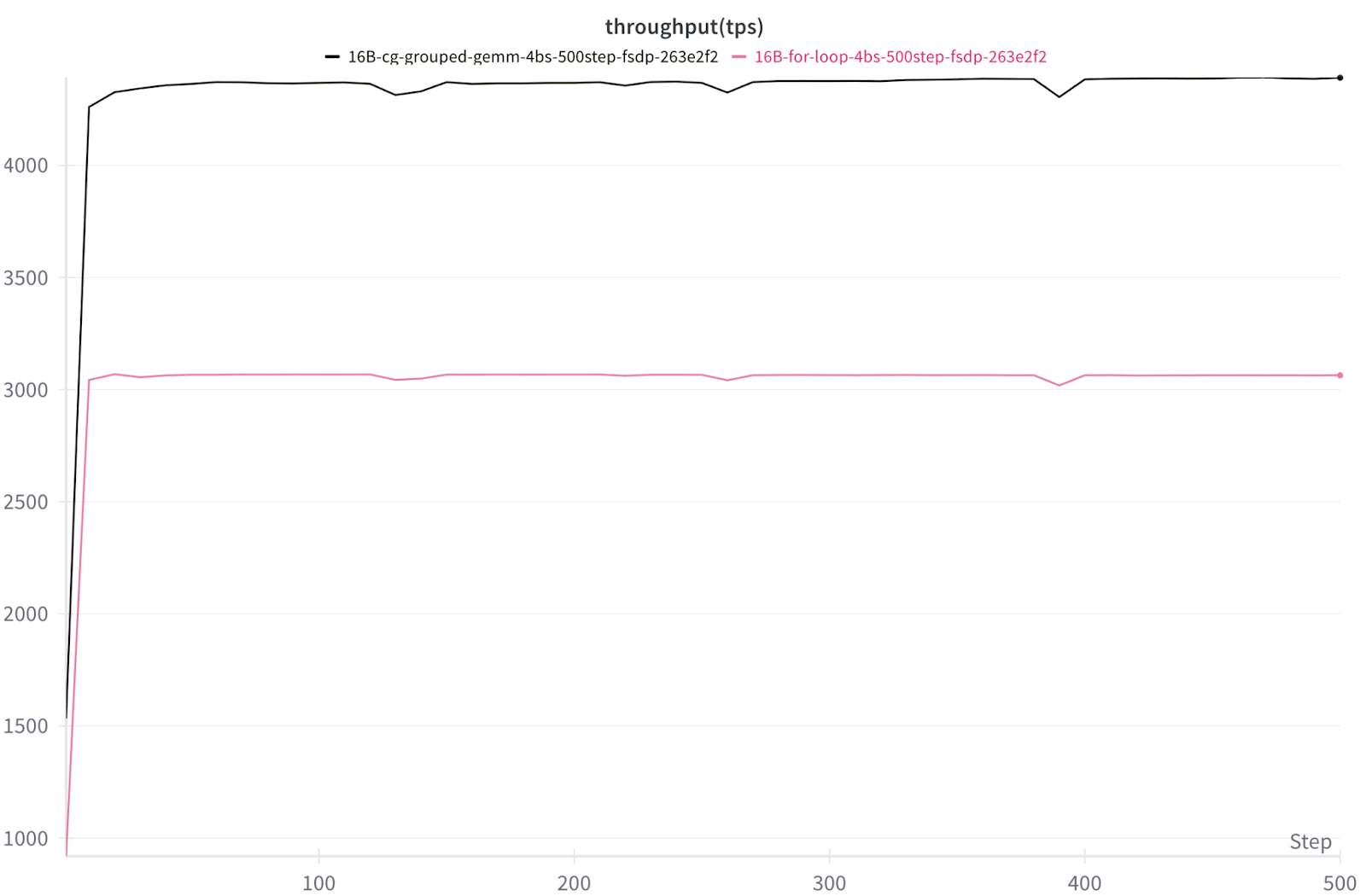
使用 FSDP2 的 8x NVIDIA H100 上 16B DeepSeekv3 TPS 吞吐量
Triton 核心分組 GEMM 與 PyTorch 手動迴圈分組 GEMM(1.42 倍-2.62 倍加速)
背景
GEMM(通用矩陣乘法)是 LLM 工作負載中的基本原語。當輸入啟用矩陣乘以權重矩陣時,就執行了 GEMM。在現代基於深度學習的架構中,GEMM 佔據了 FLOP 計數的主導地位,因此它們的效率通常決定了端到端模型的速度。
在專家混合 (MoE) 模型中,令牌被動態路由到不同的專家,從而導致許多獨立的 GEMM。分組 GEMM 在一次核心啟動中執行多個較小的 GEMM。我們不是將每個專家或層視為一個獨立的 GEMM,而是將它們批次處理,這減少了啟動開銷並提高了 GPU 利用率。

圖 1. 具有 3 個專家的 GEMM 問題示例
為了說明這一點,我們可以想象一個玩具場景,我們有 3 個專家權重,以及數量不等的令牌被路由到每個專家,因此啟用的大小不同。我們可以將這 3 個不同大小的矩陣乘法構建成一個分組 GEMM 問題,這使我們能夠在一個核心啟動中計算輸出矩陣 C1、C2 和 C3。
最佳化 1:持久化核心設計
Nvidia GPU 具有流式多處理器單元 (SM),其中包含專門的硬體單元來執行載入、儲存和計算操作。SM 利用率是核心效能的關鍵。因此,在使用 Triton 程式語言實現並行演算法(如分組矩陣乘法)時,一個關鍵的考慮因素是 SM 之間工作分解。
在樸素的工作劃分中,每個工作塊都會啟動一個新的執行緒塊 (CTA)。相比之下,持久化核心使 CTA“保持活動”並動態地向它們提供新的工作塊,直到整個 GEMM 完成。這避免了啟動開銷,提高了快取重用,並減少了排程不平衡,這可能導致稱為波量化的效應。波量化是一種低效率,當輸出塊的數量不能被 GPU SM 的數量均勻整除時發生,從而導致低利用率。這篇 Colfax 文章深入探討了該主題。
我們透過在分組 GEMM 核心中應用持久化核心策略來構建這個想法。在 MoE 模型的訓練和預填充工作負載中,矩陣乘法問題大小很大。因此,在樸素的工作分解中,需要排程大量的執行緒塊來計算輸出矩陣,這將導致多波工作。相反,透過我們的持久化核心設計,我們可以透過在 Triton 核心中進行兩個關鍵更改來在單波工作中計算整個矩陣乘法,如下面程式碼片段中討論的那樣。
首先,我們將核心網格設定為等於 H100 GPU 上的 SM 數量,即 132。
grid = (NUM_SMS, 1, 1) (Host Code)
接下來,我們將外部 for 迴圈結構更改為
for tile_id in tl.range(start_pid, num_tiles, NUM_SMS) (Device Code)
我們為每個 SM 啟動一個 Triton 程式,因此所有 Triton 程式都適合單個波中,沒有程式在佇列中等待。在核心內部,每個程式迴圈遍歷其分配的工作塊,獲取新工作直到所有工作塊都計算完畢。這種設計使 Triton 程式在 SM 上保持活動狀態,消除了重複啟動,並使 GEMM 成為一個連續的工作波。
最佳化 2:分組啟動順序
核心速度的一個重要考慮因素是快取效能。在 Triton 中,程式設計師控制輸出塊的計算順序,因此我們可以在核心級別最佳化 L2 快取效能。我們嘗試了線性塊排序(行主序)和分組啟動排序排程。為了說明這兩種方法之間的差異,我們可以檢查以下玩具矩陣乘法示例,其中 A 和 B 是輸入矩陣,C 是輸出矩陣。
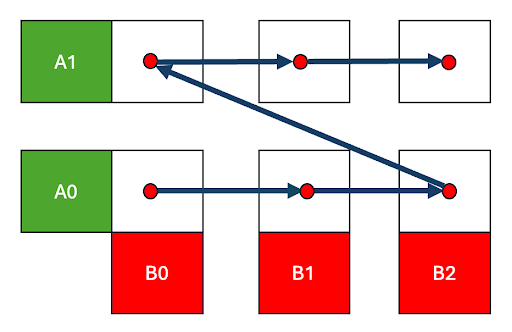
圖 2. 行主序排程
在輸出 C 矩陣的行主序遍歷中,我們快速地遍歷 B 矩陣和 C(0,0) -> C(0,1) -> C(0,2) 的列,然後移動到下一行 C(1,0)。這意味著 B 塊只有在遍歷完 C 的整行之後才會被重新訪問,屆時資料可能已經被逐出。
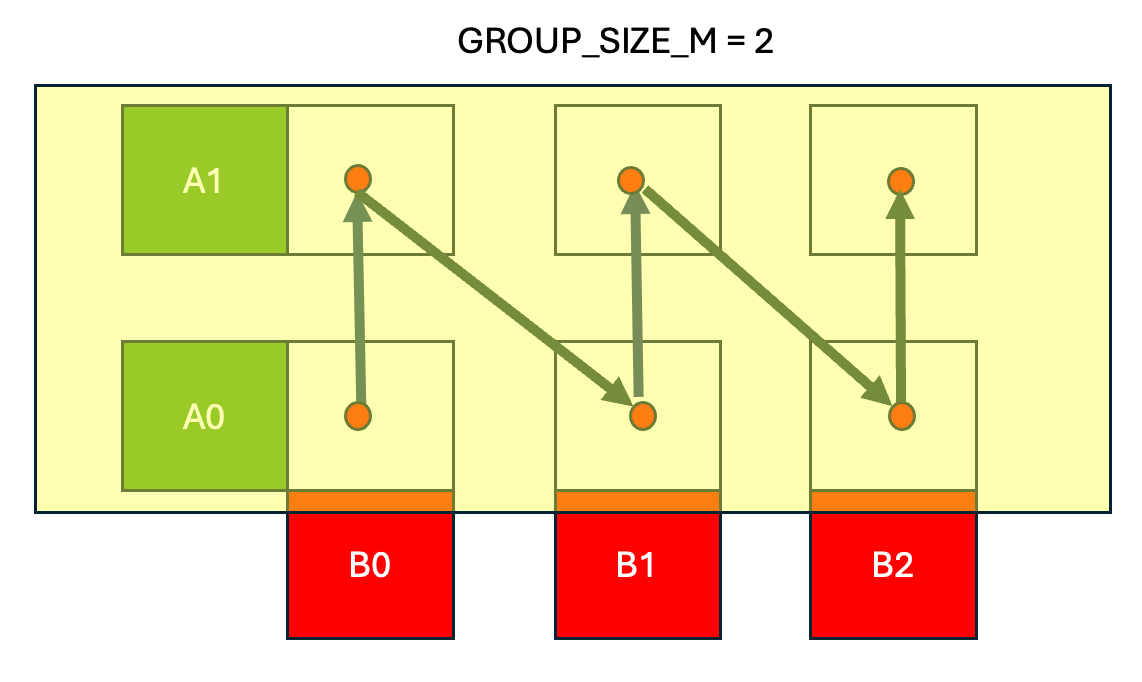
圖 3. 分組啟動排程,組大小 = 2
在 分組啟動排程中,我們保持 A 矩陣中的一行帶(圖 3 中為 2)在快取中,並按列主序遍歷輸出 C 矩陣,計算 C(0,0) -> C(1,0) ->…-> C(GROUP_SIZE_M, 0),然後移動到下一列並計算 C(0,1) -> C(1,1) 等。
最終結果是,分組啟動排程提高了 A 和 B 矩陣的快取效能。連續的 Triton 程式 (CTA) 快速連續地重用相同的 B 塊,同時將 A 行帶保留在快取中。
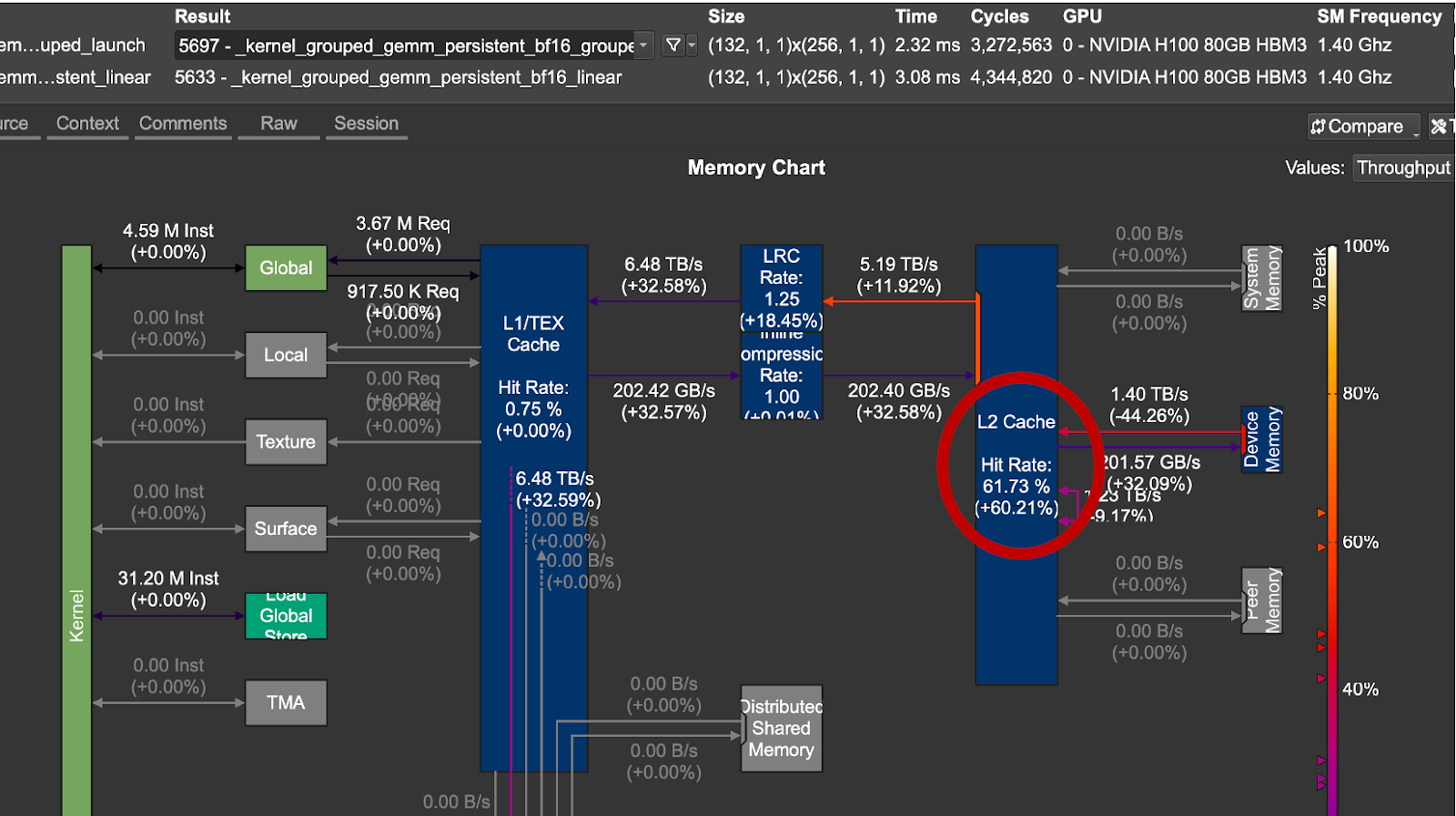
圖 4. 分組啟動順序與線性啟動順序的 L2 快取增益
num_groups, m, k, n = 8, 4096, 2048, 7168
對於我們測試的問題大小,分組啟動順序在資料重用和延遲方面表現更好。從上圖 4 中,我們注意到最佳化的排程實現了 1.33 倍 的加速和 +60% 的 L2 快取命中率。
在我們的分組 GEMM 核心中使用分組啟動排程的主要好處是它強制執行時間區域性性,如上圖所示。這是透過重新排序程式的啟動順序來實現的,以便以允許更好地重用輸入啟用和專家權重的順序計算 GEMM 問題的塊,從而提高 L2 快取命中率,增加算術強度,從而減少核心延遲。
最佳化 3:專家權重張量記憶體加速器 (TMA) 利用率
NVIDIA Hopper GPU 上的 TMA 單元是用於張量載入/儲存操作的專用硬體單元。在我們的核心設計中利用 TMA 單元的好處是,當資料從全域性記憶體移動到共享記憶體時,它可以釋放 SM 資源,例如暫存器和 CUDA 核心。要了解有關 Triton 中 TMA 用法的更多資訊,請參閱我們之前關於此主題的深入探討。
然而,由於該核心的特殊用例,存在一個注意事項。通常,包含張量元資料的 TMA 描述符是在主機上建立的,然後傳遞給核心。
對於 MoE 模型,需要修改方法,因為所選專家是預先未知的。相反,它在執行時確定,從而建立對專家權重矩陣的資料依賴訪問。這種型別的訪問在 Triton 中是可能的,方法是根據所選專家索引動態建立本地 TMA 描述符。我們將在下面的程式碼中演示如何為所選專家在裝置上構建 TMA 2D 描述符,以及如何使用它來發出 TMA 載入。
首先,我們在主機上預分配一塊 GPU 記憶體,即工作區
workspace = torch.empty( NUM_SMS * desc_helper.tma_size, #Host Code device=x.device, dtype=torch.uint8)
我們保留的記憶體大小等於單個 TMA 描述符的大小(以位元組為單位),desc_helper.tma_size,乘以我們正在啟動的持久化 Triton 程式的數量,NUM_SMs。這確保了每個 Triton 程式都有空間來寫入自己的 TMA 描述符。
expert_desc_ptr_tile = workspace + start_pid * TMA_SIZE tl.extra.cuda.experimental_device_tensormap_create2d( desc_ptr= expert_desc_ptr_tile, global_address=b_ptr + expert_idx*N*K + n_start*K, (Device Code) load_size=[BLOCK_SIZE_N, BLOCK_SIZE_K], global_size=[NUM_EXPERTS*N, K], element_ty=tl.bfloat16) tl.extra.cuda.experimental_tensormap_fenceproxy_acquire(expert_desc_ptr_tile) expert_weight = tl._experimental_descriptor_load( expert_desc_ptr_tile, [0, k_offset], [BLOCK_SIZE_N, BLOCK_SIZE_K], tl.bfloat16)
在 Triton 程式碼中,每個 Triton 程式首先在工作區中建立一個私有槽來放置專家描述符。接下來,我們透過傳遞專家元資料來建立一個指向路由專家塊的 2D 張量對映。然後,我們顯式呼叫一個代理柵欄,這是在兩個不同的代理(SM 和 TMA 引擎)之間同步記憶體操作所必需的。在我們的核心中,每當選擇一個新的 expert_idx 時,SM 都會將新的 TMA 描述符寫入全域性記憶體。柵欄保證在 TMA 引擎發出載入指令之前,新的 TMA 描述符是全域性可見的。這確保我們不會讀取陳舊/不正確的資料。
現在,由於 TMA 描述符是根據所選的 expert_idx 動態構建的,因此分組 GEMM 核心中的每個 Triton 程式都可以將其 TMA 載入定向到路由的專家權重。
微基準測試
我們將我們的 Hopper 最佳化核心與不包含我們討論的最佳化的基線 Triton 分組 GEMM 核心進行了基準測試,以隔離這些技術帶來的增益。
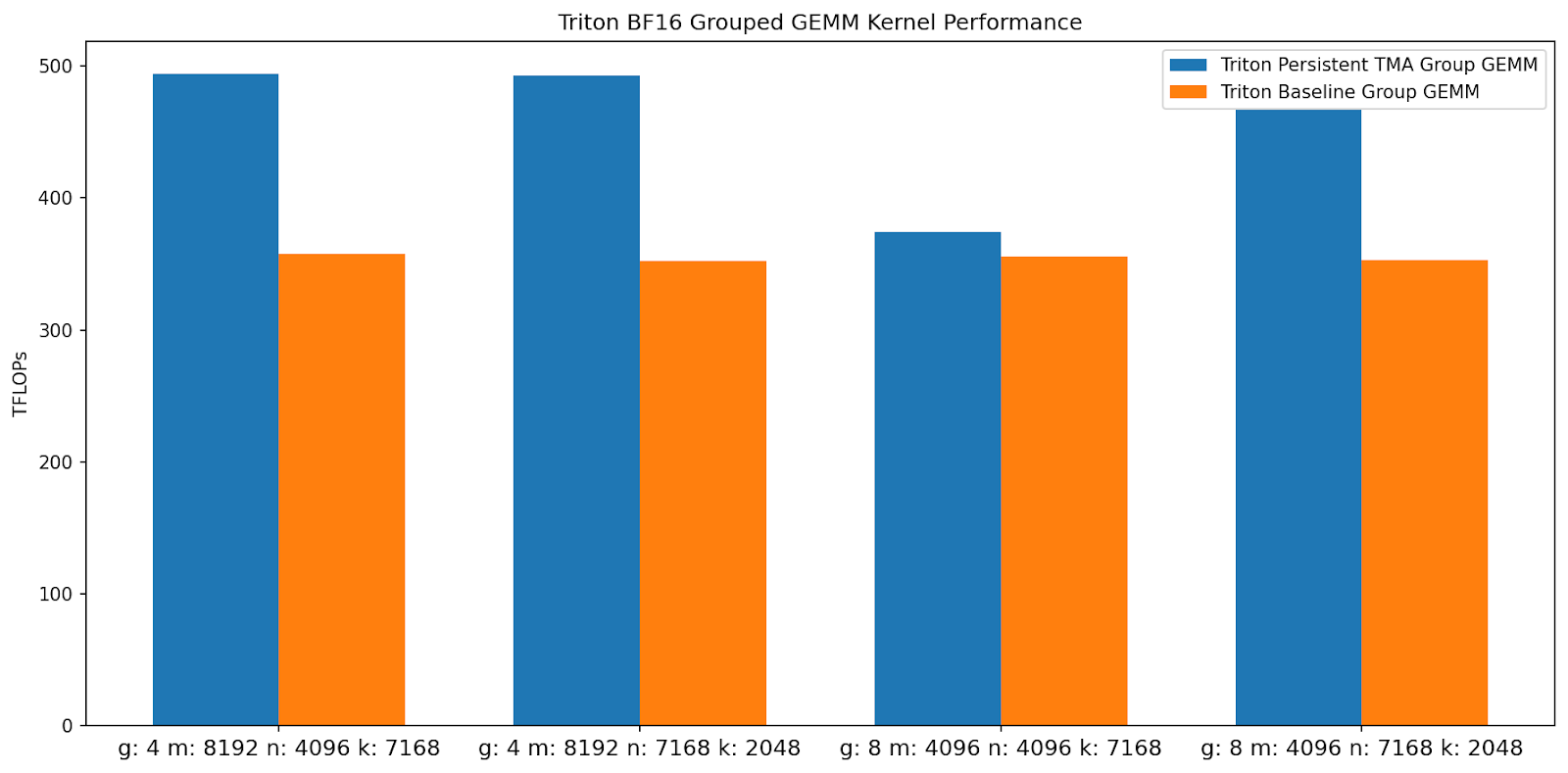
圖 5. Triton 分組 GEMM 核心 TFLOPs 比較(越高越好)
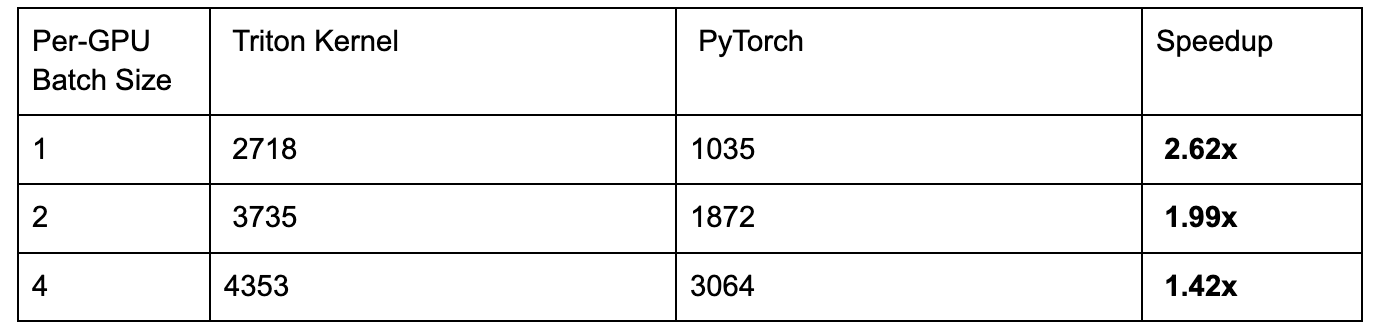
圖 6. 核心延遲比較及相對於基線 Triton 核心的加速
透過利用持久化核心設計、分組啟動塊排序和 Hopper TMA 單元,我們的核心比基線 Triton 核心實現了高達 1.50 倍 的加速。
端到端基準測試
我們將核心整合到 torchtitan 中,以建立一個端到端測試,其中我們使用 FSDP2 在 8xH100 上訓練 16B 引數的 DeepSeekv3 模型。不同批次大小的加速如下:

圖 7. 16B DeepSeekv3 E2E 每秒令牌數/GPU 吞吐量彙總
MoE 模型的引數與 FLOPs 比率遠高於密集模型,這一事實使得 FSDP2 對於訓練來說不是最優的,因為通訊大權重成本很高。相反,透過將不同的專家靜態放置在不同的 GPU 上並通訊啟用來並行化會更有益。在這種專家並行訓練中,每個 GPU 處理的令牌數量是動態變化的,這使得 Triton 核心的使用具有挑戰性,因為每個新的令牌計數可能需要核心重新編譯,具體取決於實現的細節。我們將對這種動態訓練工作負載的支援留待未來的工作。
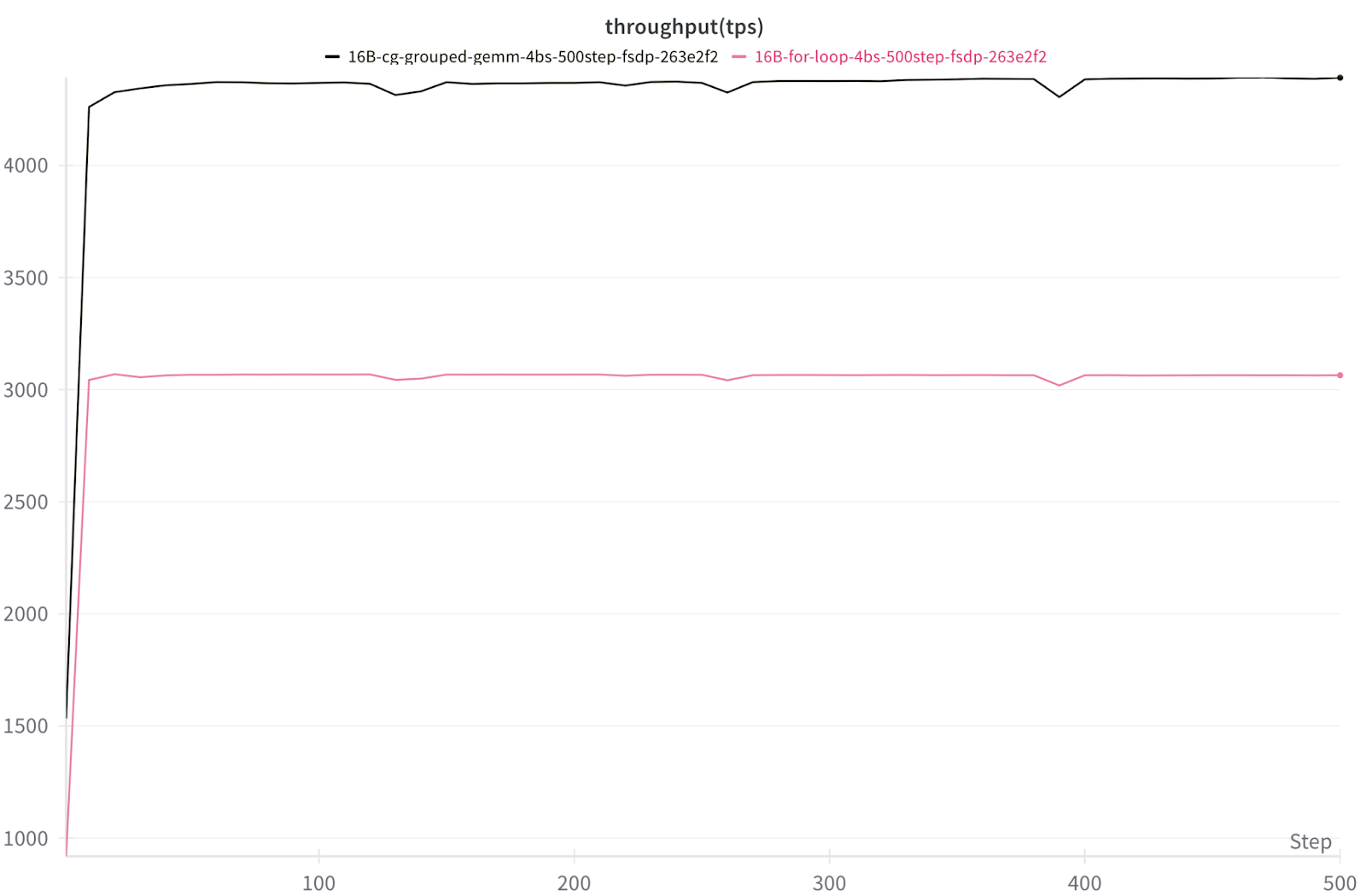
訓練 (torchtitan)
圖 8. 在 8x NVIDIA H100 上使用 FSDP2 訓練批次大小為 4 的 16B DeepSeekv3 的每秒令牌數/GPU

訓練 (torchtitan)
圖 9. 在 8x NVIDIA H100 上使用 FSDP2 訓練 16B DeepSeekv3 的 Triton 與 for 迴圈的損失曲線比較
結論
未來的工作,我們計劃將我們的核心整合到 vLLM(正在進行的 PR 在此處),並擴充套件此核心以支援前向和後向的 FP8。我們的核心可以從 torchtitan 在此處利用。 此外,我們還計劃試驗更低精度的datatypes,例如 MXFP4,這些 datatype 受到新一代 NVIDIA GPU(如 B200)的支援。