概述
在執行視覺模型時,記憶體格式對效能有顯著影響,通常“通道優先”(Channels Last)由於更好的資料區域性性,從效能角度來看更為有利。
本部落格將介紹記憶體格式的基本概念,並演示在Intel® Xeon® 可擴充套件處理器上,使用“通道優先”在流行的PyTorch視覺模型上帶來的效能優勢。
記憶體格式介紹
記憶體格式是指資料表示形式,它描述了多維(nD)陣列如何儲存線上性(1D)記憶體地址空間中。記憶體格式的概念有兩個方面:
- 物理順序是指資料在物理記憶體中的儲存佈局。對於視覺模型,我們通常談論NCHW和NHWC。這些是物理記憶體佈局的描述,也分別稱為“通道優先”(Channels First)和“通道居後”(Channels Last)。
- 邏輯順序是描述張量形狀和步幅的約定。在PyTorch中,此約定為NCHW。無論物理順序如何,張量的形狀和步幅將始終以NCHW的順序描述。
圖1顯示了形狀為[1, 3, 4, 4]的張量在“通道優先”和“通道居後”記憶體格式下的物理記憶體佈局(通道分別表示為R、G、B)

圖1 “通道優先”和“通道居後”的物理記憶體佈局
記憶體格式傳播
PyTorch記憶體格式傳播的一般規則是保留輸入張量的記憶體格式。這意味著“通道優先”的輸入將生成“通道優先”的輸出,而“通道居後”的輸入將生成“通道居後”的輸出。
對於卷積層,PyTorch預設使用oneDNN(oneAPI深度神經網路庫)在Intel CPU上實現最佳效能。由於直接使用“通道優先”記憶體格式無法實現高度最佳化的效能,因此輸入和權重首先被轉換為分塊格式,然後進行計算。oneDNN可能會根據輸入形狀、資料型別和硬體架構選擇不同的分塊格式,以實現向量化和快取重用。分塊格式對PyTorch是不透明的,因此輸出需要轉換回“通道優先”格式。儘管分塊格式可以帶來最佳計算效能,但格式轉換可能會增加開銷,從而抵消效能提升。
另一方面,oneDNN針對“通道居後”記憶體格式進行了最佳化,可以直接使用它以獲得最佳效能,PyTorch將簡單地將記憶體檢視傳遞給oneDNN。這意味著節省了輸入和輸出張量的轉換。圖2顯示了PyTorch CPU上卷積的記憶體格式傳播行為(實線箭頭表示記憶體格式轉換,虛線箭頭表示記憶體檢視)
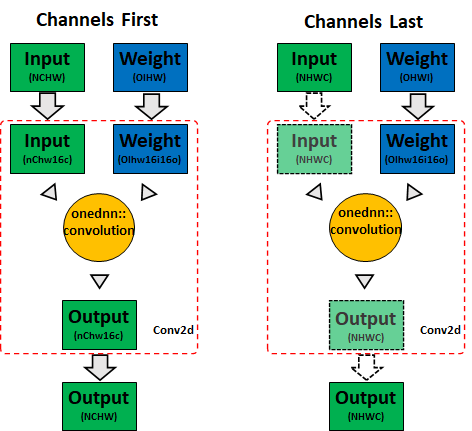
圖2 CPU卷積記憶體格式傳播
在PyTorch中,預設的記憶體格式是“通道優先”。如果某個特定運算子不支援“通道居後”,NHWC輸入將被視為不連續的NCHW,因此會回退到“通道優先”,這將在CPU上消耗之前的記憶體頻寬並導致次優效能。
因此,擴充套件“通道居後”支援的範圍對於獲得最佳效能至關重要。我們已經為CV領域常用運算子(推理和訓練均適用)實現了“通道居後”核,例如:
- 啟用函式(例如ReLU、PReLU等)
- 卷積(例如Conv2d)
- 歸一化(例如BatchNorm2d、GroupNorm等)
- 池化(例如AdaptiveAvgPool2d、MaxPool2d等)
- 混洗(例如ChannelShuffle、PixelShuffle)
詳情請參閱支援“通道居後”的運算子。
“通道居後”的本地級別最佳化
如上所述,PyTorch使用oneDNN在Intel CPU上實現卷積的最佳效能。其餘記憶體格式感知運算子在PyTorch本地級別進行最佳化,無需任何第三方庫支援。
- 快取友好的並行化方案:為所有記憶體格式感知運算子保持相同的並行化方案,這將有助於在將每個層的輸出傳遞給下一層時提高資料區域性性。
- 多架構向量化:通常,我們可以在“通道居後”記憶體格式的最內層維度進行向量化。每個向量化的CPU核將同時為AVX2和AVX512生成。
在貢獻“通道居後”核的同時,我們也盡力優化了“通道優先”對應的核。事實上,有些運算子在“通道優先”下無法實現最佳效能,例如卷積、池化等。
在“通道居後”上執行視覺模型
“通道居後”相關的API已在PyTorch記憶體格式教程中記錄。通常,我們可以透過以下方式將4D張量從“通道優先”轉換為“通道居後”:
# convert x to channels last
# suppose x’s shape is (N, C, H, W)
# then x’s stride will be (HWC, 1, WC, C)
x = x.to(memory_format=torch.channels_last)
要在“通道居後”記憶體格式上執行模型,只需將輸入和模型轉換為“通道居後”,即可開始執行。以下是一個最小示例,展示瞭如何在“通道居後”記憶體格式下執行帶TorchVision的ResNet50:
import torch
from torchvision.models import resnet50
N, C, H, W = 1, 3, 224, 224
x = torch.rand(N, C, H, W)
model = resnet50()
model.eval()
# convert input and model to channels last
x = x.to(memory_format=torch.channels_last)
model = model.to(memory_format=torch.channels_last)
model(x)
“通道居後”最佳化是在本地核心級別實現的,這意味著您可以將其他功能(如torch.fx和torch script)與“通道居後”一起應用。
效能提升
我們在Intel® Xeon® Platinum 8380 CPU @ 2.3 GHz上對TorchVision模型的推理效能進行了基準測試,每個插槽單例項(批處理大小=2 x 物理核心數)。結果顯示,“通道居後”比“通道優先”具有1.3倍到1.8倍的效能提升。
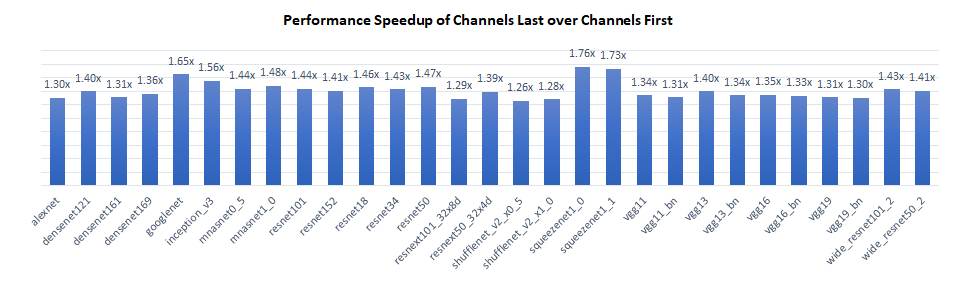
效能提升主要來自兩個方面:
- 對於卷積層,“通道居後”節省了啟用層到分塊格式的記憶體格式轉換,從而提高了整體計算效率。
- 對於池化和上取樣層,“通道居後”可以在最內層維度(例如“C”)使用向量化邏輯,而“通道優先”則不能。
對於不感知記憶體格式的層,“通道居後”和“通道優先”具有相同的效能。
結論與未來工作
在本部落格中,我們介紹了“通道居後”的基本概念,並演示了在CPU上使用“通道居後”在視覺模型上的效能優勢。目前的工作僅限於2D模型,我們將在不久的將來將最佳化工作擴充套件到3D模型!
致謝
本部落格中呈現的結果是Meta和Intel PyTorch團隊共同努力的成果。特別感謝Meta的Vitaly Fedyunin和Wei Wei,他們付出了寶貴的時間並提供了實質性幫助!我們共同為改善PyTorch CPU生態系統邁出了又一步。