今天,我們很高興地宣佈 PyTorch 引入了一項新的高階 CUDA 功能——CUDA 圖。現代深度學習框架具有複雜的軟體堆疊,每次向 GPU 提交操作都會產生顯著的開銷。當深度學習工作負載為提高效能而強力擴充套件到多個 GPU 時,每個 GPU 操作所需的時間會減少到幾微秒,在這種情況下,框架高昂的工作提交延遲通常會導致 GPU 利用率低下。隨著 GPU 速度的加快以及工作負載擴充套件到更多裝置,工作負載因這些啟動引起的停頓而受損的可能性會增加。為了克服這些效能開銷,NVIDIA 工程師與 PyTorch 開發人員合作,在 PyTorch 中原生啟用 CUDA 圖執行。此設計對於擴充套件 NVIDIA 的 MLPerf 工作負載(在 PyTorch 中實現)至關重要,使其能夠擴充套件到 4000 多個 GPU,從而實現破紀錄的效能。

PyTorch 中對 CUDA 圖的支援只是 NVIDIA 和 Facebook 工程師長期合作的又一個例子。torch.cuda.amp,例如,使用半精度進行訓練,同時保持單精度實現的網路精度,並儘可能自動利用 Tensor Core。AMP 僅需幾行程式碼更改即可提供比 FP32 高達 3 倍的效能。同樣,NVIDIA 的Megatron-LM使用 PyTorch 在多達 3072 個 GPU 上進行了訓練。在 PyTorch 中,擴充套件 GPU 訓練的最有效方法之一是使用torch.nn.parallel.DistributedDataParallel與 NVIDIA Collective Communications Library (NCCL) 後端結合使用。
CUDA 圖
CUDA 圖於 CUDA 10 首次亮相,它允許將一系列 CUDA 核心定義和封裝為一個單元,即一個操作圖,而不是一系列單獨啟動的操作。它提供了一種透過單個 CPU 操作啟動多個 GPU 操作的機制,從而減少了啟動開銷。
CUDA 圖的優勢可以透過圖 1 中的簡單示例進行演示。在頂部,CPU 逐個啟動一系列短核心。CPU 啟動開銷在核心之間造成了顯著的間隔。如果我們將這一系列核心替換為 CUDA 圖,最初我們需要花費一些額外的時間來構建圖並在第一次一次性啟動整個圖,但後續執行將非常快,因為核心之間幾乎沒有間隔。當相同的操作序列重複多次時,例如在許多訓練步驟中,這種差異會更加明顯。在這種情況下,構建和啟動圖的初始成本將在整個訓練迭代次數中攤銷。有關該主題的更全面的介紹,請參閱我們的部落格CUDA 圖入門和 GTC 演講輕鬆實現 CUDA 圖。

圖 1. 使用 CUDA 圖的優勢
NCCL 對 CUDA 圖的支援
前面提到的減少啟動開銷的優勢也延伸到 NCCL 核心啟動。NCCL 支援基於 GPU 的集體通訊和 P2P 通訊。藉助NCCL 對 CUDA 圖的支援,我們可以消除 NCCL 核心啟動開銷。
此外,由於各種 CPU 負載和作業系統因素,核心啟動時間可能不可預測。這種時間偏差可能對 NCCL 集體操作的效能有害。藉助 CUDA 圖,核心被捆綁在一起,從而使分散式工作負載中各等級的效能保持一致。這在大型叢集中特別有用,因為即使單個緩慢的節點也可能降低整個叢集級別的效能。
對於分散式多 GPU 工作負載,NCCL 用於集體通訊。如果我們檢視利用資料並行性訓練神經網路,如果沒有 NCCL 對 CUDA 圖的支援,我們將需要為前向/後向傳播和 NCCL AllReduce 分別啟動。相比之下,藉助 NCCL 對 CUDA 圖的支援,我們可以透過將前向/後向傳播和 NCCL AllReduce 全部捆綁到單個圖啟動中來減少啟動開銷。

圖 2. 觀察典型的神經網路,所有 NCCL AllReduce 的核心啟動都可以打包成一個圖以減少開銷啟動時間。
PyTorch CUDA 圖
從 PyTorch v1.10 開始,CUDA 圖功能作為一組 Beta API 提供。
API 概述
PyTorch 支援使用流捕獲構建 CUDA 圖,它將 CUDA 流置於捕獲模式。發給捕獲流的 CUDA 工作實際上不會在 GPU 上執行。相反,工作會被記錄在一個圖中。捕獲後,可以啟動該圖以根據需要執行 GPU 工作任意多次。每次重放都以相同的引數執行相同的核心。對於指標引數,這意味著使用相同的記憶體地址。透過在每次重放之前用新資料(例如,來自新批次)填充輸入記憶體,您可以對新資料重新執行相同的工作。
重放圖犧牲了典型即時執行的動態靈活性,以換取大大降低的 CPU 開銷。圖的引數和核心是固定的,因此圖重放跳過了所有引數設定和核心排程層,包括 Python、C++ 和 CUDA 驅動程式開銷。在底層,重放透過單個呼叫cudaGraphLaunch將整個圖的工作提交給 GPU。重放中的核心在 GPU 上執行速度也略快,但消除 CPU 開銷是主要優勢。
如果您的網路全部或部分是圖安全的(通常這意味著靜態形狀和靜態控制流,但請參閱其他限制),並且您懷疑其執行時至少在某種程度上受到 CPU 限制,那麼您應該嘗試使用 CUDA 圖。
API 示例
PyTorch 透過原始的torch.cuda.CUDAGraph類和兩個便利包裝器torch.cuda.graph和torch.cuda.make_graphed_callables暴露圖。
torch.cuda.graph是一個簡單、多功能的上下文管理器,可在其上下文中捕獲 CUDA 工作。在捕獲之前,透過執行幾次即時迭代來預熱要捕獲的工作負載。預熱必須在側流上進行。由於圖在每次重放中都從相同的記憶體地址讀取和寫入,因此您必須在捕獲期間維護對儲存輸入和輸出資料的張量的長期引用。要在新輸入資料上執行圖,請將新資料複製到捕獲的輸入張量中,重放圖,然後從捕獲的輸出張量中讀取新輸出。
如果整個網路捕獲安全,則可以捕獲並重放整個網路,如以下示例所示。
N, D_in, H, D_out = 640, 4096, 2048, 1024
model = torch.nn.Sequential(torch.nn.Linear(D_in, H),
torch.nn.Dropout(p=0.2),
torch.nn.Linear(H, D_out),
torch.nn.Dropout(p=0.1)).cuda()
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
# Placeholders used for capture
static_input = torch.randn(N, D_in, device='cuda')
static_target = torch.randn(N, D_out, device='cuda')
# warmup
# Uses static_input and static_target here for convenience,
# but in a real setting, because the warmup includes optimizer.step()
# you must use a few batches of real data.
s = torch.cuda.Stream()
s.wait_stream(torch.cuda.current_stream())
with torch.cuda.stream(s):
for i in range(3):
optimizer.zero_grad(set_to_none=True)
y_pred = model(static_input)
loss = loss_fn(y_pred, static_target)
loss.backward()
optimizer.step()
torch.cuda.current_stream().wait_stream(s)
# capture
g = torch.cuda.CUDAGraph()
# Sets grads to None before capture, so backward() will create
# .grad attributes with allocations from the graph's private pool
optimizer.zero_grad(set_to_none=True)
with torch.cuda.graph(g):
static_y_pred = model(static_input)
static_loss = loss_fn(static_y_pred, static_target)
static_loss.backward()
optimizer.step()
real_inputs = [torch.rand_like(static_input) for _ in range(10)]
real_targets = [torch.rand_like(static_target) for _ in range(10)]
for data, target in zip(real_inputs, real_targets):
# Fills the graph's input memory with new data to compute on
static_input.copy_(data)
static_target.copy_(target)
# replay() includes forward, backward, and step.
# You don't even need to call optimizer.zero_grad() between iterations
# because the captured backward refills static .grad tensors in place.
g.replay()
# Params have been updated. static_y_pred, static_loss, and .grad
# attributes hold values from computing on this iteration's data.
如果您的網路中的某些部分不安全無法捕獲(例如,由於動態控制流、動態形狀、CPU 同步或必要的 CPU 端邏輯),您可以即時執行不安全的部分,並使用torch.cuda.make_graphed_callables僅對捕獲安全的部分進行圖化。接下來將演示這一點。
make_graphed_callables接受可呼叫物件(函式或nn.Module)並返回圖化版本。預設情況下,由make_graphed_callables返回的可呼叫物件是自動求導感知的,可以在訓練迴圈中直接替代您傳入的函式或nn.Module。make_graphed_callables內部建立CUDAGraph物件,執行預熱迭代,並根據需要維護靜態輸入和輸出。因此(與torch.cuda.graph不同),您不需要手動處理這些。
在以下示例中,依賴資料的動態控制流意味著網路無法端到端捕獲,但make_graphed_callables() 讓我們無論如何都可以捕獲並執行圖安全的部分作為圖
N, D_in, H, D_out = 640, 4096, 2048, 1024
module1 = torch.nn.Linear(D_in, H).cuda()
module2 = torch.nn.Linear(H, D_out).cuda()
module3 = torch.nn.Linear(H, D_out).cuda()
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.SGD(chain(module1.parameters(),
module2.parameters(),
module3.parameters()),
lr=0.1)
# Sample inputs used for capture
# requires_grad state of sample inputs must match
# requires_grad state of real inputs each callable will see.
x = torch.randn(N, D_in, device='cuda')
h = torch.randn(N, H, device='cuda', requires_grad=True)
module1 = torch.cuda.make_graphed_callables(module1, (x,))
module2 = torch.cuda.make_graphed_callables(module2, (h,))
module3 = torch.cuda.make_graphed_callables(module3, (h,))
real_inputs = [torch.rand_like(x) for _ in range(10)]
real_targets = [torch.randn(N, D_out, device="cuda") for _ in range(10)]
for data, target in zip(real_inputs, real_targets):
optimizer.zero_grad(set_to_none=True)
tmp = module1(data) # forward ops run as a graph
if tmp.sum().item() > 0:
tmp = module2(tmp) # forward ops run as a graph
else:
tmp = module3(tmp) # forward ops run as a graph
loss = loss_fn(tmp, target)
# module2's or module3's (whichever was chosen) backward ops,
# as well as module1's backward ops, run as graphs
loss.backward()
optimizer.step()
示例用例
MLPerf v1.0 訓練工作負載
PyTorch CUDA 圖功能在將 NVIDIA 的 MLPerf 訓練 v1.0 工作負載(在 PyTorch 中實現)擴充套件到 4000 多個 GPU 方面發揮了重要作用,在所有方面都創造了新紀錄。我們將在下面展示兩個 MLPerf 工作負載,其中使用 CUDA 圖獲得了最顯著的增益,速度提升高達約 1.7 倍。
| GPU 數量 | CUDA 圖帶來的加速比 | |
|---|---|---|
| Mask R-CNN | 272 | 1.70倍 |
| BERT | 4096 | 1.12倍 |
表 1. PyTorch CUDA 圖對 MLPerf 訓練 v1.0 效能的提升。
Mask R-CNN
深度學習框架使用 GPU 加速計算,但仍有大量程式碼在 CPU 核心上執行。CPU 核心處理張量形狀等元資料,以準備啟動 GPU 核心所需的引數。處理元資料是固定成本,而 GPU 完成的計算工作的成本與批處理大小正相關。對於大批處理大小,CPU 開銷佔總執行時間成本的百分比可以忽略不計,但對於小批處理大小,CPU 開銷可能大於 GPU 執行時間。發生這種情況時,GPU 在核心呼叫之間處於空閒狀態。這個問題可以在圖 3 的 NSight 時間軸圖中識別。下圖顯示了 Mask R-CNN 的“骨幹”部分,每個 GPU 的批處理大小為 1,在圖化之前。綠色部分顯示 CPU 負載,藍色部分顯示 GPU 負載。在此配置檔案中,我們看到 CPU 負載達到 100%,而 GPU 大部分時間處於空閒狀態,GPU 核心之間存在大量空白區域。

圖 3:Mask R-CNN 的 NSight 時間線圖
當張量形狀是靜態的時,CUDA 圖可以自動消除 CPU 開銷。在第一步中捕獲所有核心呼叫的完整圖,在後續步驟中,整個圖透過單個操作啟動,從而消除所有 CPU 開銷,如圖 4 所示。

圖 4:CUDA 圖最佳化
透過圖化,我們看到 GPU 核心緊密打包,GPU 利用率保持較高。圖化部分現在在 6 毫秒內執行,而不是 31 毫秒,速度提升了 5 倍。我們沒有對整個模型進行圖化,主要只是 resnet 骨幹網路,這導致整體速度提升了約 1.7 倍。為了擴大圖的範圍,我們對軟體堆疊進行了一些更改,以消除一些 CPU-GPU 同步點。在 MLPerf v1.0 中,這項工作包括將 torch.randperm 函式的實現更改為使用 CUB 而不是 Thrust,因為後者是一個同步的 C++ 模板庫。這些改進可在最新的 NGC 容器中獲得。
BERT
同樣,透過圖形捕獲模型,我們消除了 CPU 開銷以及伴隨的同步開銷。CUDA 圖實現使我們最大規模的 BERT 配置效能提升了 1.12 倍。為了最大化 CUDA 圖的優勢,重要的是要儘可能擴大圖的範圍。為此,我們修改了模型指令碼以在執行過程中移除 CPU-GPU 同步,以便可以完整捕獲模型圖。此外,我們還確保執行期間圖範圍內的張量大小是靜態的。例如,在 BERT 中,只有總標記的特定子集對損失函式有貢獻,這由預生成的掩碼張量決定。從該掩碼中提取有效標記的索引,並使用這些索引收集對損失有貢獻的標記,會生成一個具有動態形狀的張量,即在迭代之間形狀不恆定。為了確保張量大小是靜態的,我們沒有在損失計算中使用動態形狀張量,而是使用了靜態形狀張量,其中使用掩碼來指示哪些元素有效。因此,所有張量形狀都是靜態的。動態形狀還需要 CPU-GPU 同步,因為它必須涉及框架在 CPU 端的記憶體管理。對於僅靜態形狀,不需要 CPU-GPU 同步。這在圖 5 中顯示。

圖 5. 透過使用固定大小的張量和布林掩碼,如文中所述,我們能夠消除動態大小張量所需的 CPU 同步
NVIDIA 深度學習示例集合中的 CUDA 圖
單 GPU 用例也可以從使用 CUDA 圖中受益。對於啟動許多具有小批次的短核心的工作負載尤其如此。一個很好的例子是推薦系統的訓練和推理。下面我們展示了 NVIDIA 深度學習示例集合中深度學習推薦模型 (DLRM) 實現的初步基準測試結果。為此工作負載使用 CUDA 圖為訓練和推理都提供了顯著的加速。當使用非常小的批次大小時,效果尤其明顯,因為 CPU 開銷更加突出。
CUDA 圖正在積極整合到其他 PyTorch NGC 模型指令碼和 NVIDIA Github 深度學習示例中。敬請關注更多關於如何使用它的示例。
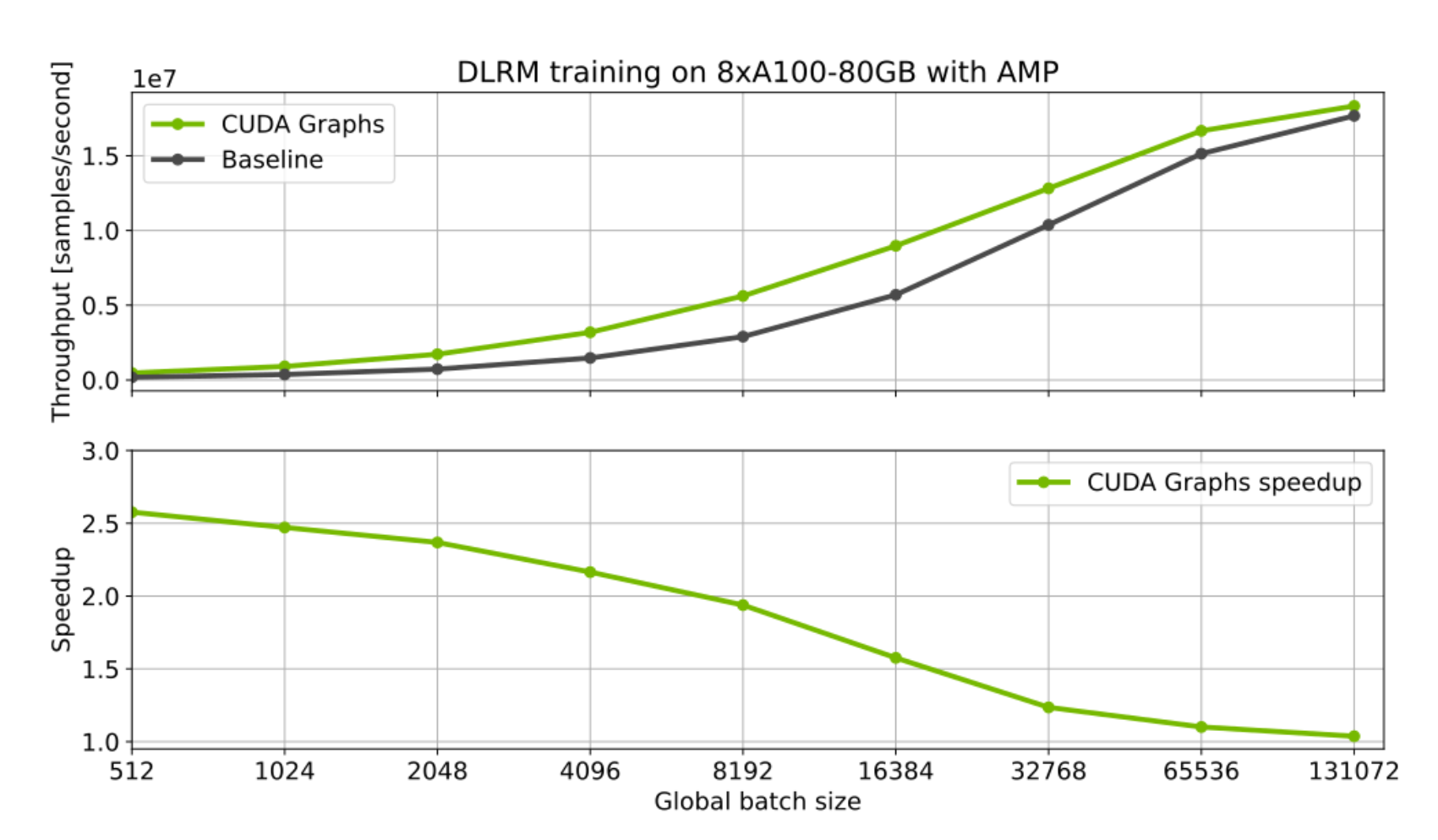

圖 6:DLRM 模型的 CUDA 圖最佳化。
行動號召:PyTorch v1.10 中的 CUDA 圖
CUDA 圖可以為包含許多小型 GPU 核心並因此受 CPU 啟動開銷拖累的工作負載提供巨大的好處。這已在我們的 MLPerf 工作中得到證明,優化了 PyTorch 模型。許多這些最佳化,包括 CUDA 圖,已經或最終將整合到我們的 PyTorch NGC 模型指令碼集合和 NVIDIA Github 深度學習示例中。目前,請檢視我們的開源 MLPerf 訓練 v1.0 實現,它可以作為了解 CUDA 圖實際運作的良好起點。或者,在您自己的工作負載上嘗試 PyTorch CUDA 圖 API。
我們感謝許多 NVIDIA 和 Facebook 工程師的討論和建議:Karthik Mandakolathur US、Tomasz Grel、PLJoey Conway、Arslan Zulfiqar US
作者簡介
Vinh Nguyen 深度學習工程師,NVIDIA
Vinh 是一位深度學習工程師和資料科學家,已發表 50 多篇科學文章,引用次數超過 2500 次。在 NVIDIA,他的工作涵蓋廣泛的深度學習和人工智慧應用,包括語音、語言和視覺處理以及推薦系統。
Michael Carilli 高階開發者技術工程師,NVIDIA
Michael 曾在空軍研究實驗室工作,為現代並行架構最佳化 CFD 程式碼。他擁有加州大學聖巴巴拉分校計算物理學博士學位。作為 PyTorch 團隊的一員,他致力於使內部團隊、外部客戶和 PyTorch 社群使用者能夠更快、數值更穩定、更輕鬆地進行 GPU 訓練。
Sukru Burc Eryilmaz 開發架構高階架構師,NVIDIA
Sukru 獲得斯坦福大學博士學位和 Bilkent 大學學士學位。他目前致力於改進單節點規模和超級計算機規模的神經網路訓練的端到端效能。
Vartika Singh 深度學習框架和庫技術合作夥伴主管,NVIDIA
Vartika 曾領導團隊在雲和分散式計算、擴充套件和人工智慧的交匯點工作,影響了主要公司的設計和戰略。她目前與主要框架和編譯器組織以及 NVIDIA 內外的開發人員合作,幫助設計在 NVIDIA 硬體上高效、最佳化地工作。
Michelle Lin 產品實習生,NVIDIA
Michelle 目前在加州大學伯克利分校攻讀計算機科學與工商管理本科學位。她目前負責管理專案執行,例如進行市場調研和為 Magnum IO 建立營銷資產。
Natalia Gimelshein 應用研究科學家,Facebook
Natalia Gimelshein 曾在 NVIDIA 和 Facebook 致力於深度學習工作負載的 GPU 效能最佳化。她目前是 PyTorch 核心團隊成員,與合作伙伴合作無縫支援新的軟體和硬體功能。
Alban Desmaison 研究工程師,Facebook
Alban 學習工程學並獲得了機器學習和最佳化博士學位,在此期間他曾是 PyTorch 的 OSS 貢獻者,之後加入了 Facebook。他的主要職責是維護一些核心庫和功能(autograd、optim、nn),並致力於全面改進 PyTorch。
Edward Yang 研究工程師,Facebook
Edward 在麻省理工學院和斯坦福大學學習計算機科學,之後加入 Facebook。他是 PyTorch 核心團隊的一員,也是 PyTorch 的主要貢獻者之一。