Amazon Ads 使用 PyTorch、TorchServe 和 AWS Inferentia 將推理成本降低 71%,並實現規模擴充套件。
Amazon Ads 幫助公司透過在亞馬遜商城內外(包括網站、應用程式和流媒體電視內容)展示廣告,在超過 15 個國家/地區建立品牌並與購物者建立聯絡。各種規模的企業和品牌,包括註冊賣家、供應商、圖書供應商、Kindle 直接出版 (KDP) 作者、應用程式開發商和代理商,都可以上傳自己的廣告創意,其中包括圖片、影片、音訊以及在亞馬遜上銷售的產品。

為了促進準確、安全和愉快的購物體驗,這些廣告必須遵守內容準則。例如,廣告不能閃爍,產品必須在適當的背景下展示,圖片和文字應適合普通受眾。為了幫助確保廣告符合所需的政策和標準,我們需要開發可擴充套件的機制和工具。
作為解決方案,我們使用機器學習 (ML) 模型來發現可能需要修改的廣告。在過去十年中,隨著深度神經網路的蓬勃發展,我們的資料科學團隊開始探索更通用的深度學習 (DL) 方法,這些方法能夠以最少的人工干預處理文字、影像、音訊或影片。為此,我們使用 PyTorch 構建了計算機視覺 (CV) 和自然語言處理 (NLP) 模型,以自動標記可能不符合要求的廣告。PyTorch 直觀、靈活且使用者友好,使我們無縫過渡到使用 DL 模型。在基於 AWS Inferentia 的 Amazon EC2 Inf1 例項上部署這些新模型,而不是在基於 GPU 的例項上部署,使相同工作負載的推理延遲降低了 30%,推理成本降低了 71%。
向深度學習的過渡
我們的機器學習系統將經典模型與詞嵌入配對,以評估廣告文字。但隨著我們的需求不斷演變,提交量持續增長,我們需要一種足夠靈活的方法來與我們的業務一起擴充套件。此外,我們的模型必須快速,並在毫秒內提供廣告,以提供最佳的客戶體驗。
在過去十年中,深度學習在許多領域都變得非常流行,包括自然語言、視覺和音訊。由於深度神經網路透過許多層傳輸資料集——逐步提取更高層次的特徵——它們可以做出比經典機器學習模型更細微的推斷。例如,深度學習模型不僅可以檢測被禁止的語言,還可以拒絕釋出虛假宣告的廣告。
此外,深度學習技術是可遷移的——為一項任務訓練的模型可以適應執行相關任務。例如,預訓練的神經網路可以最佳化以檢測影像中的物體,然後進行微調以識別不允許在廣告中顯示的特定物體。
深度神經網路可以自動化傳統機器學習中兩個最耗時的步驟:特徵工程和資料標註。與需要探索性資料分析和手工設計特徵的傳統監督學習方法不同,深度神經網路直接從資料中學習相關特徵。深度學習模型還可以分析非結構化資料,如文字和影像,而無需進行機器學習中必需的預處理。深度神經網路可以有效地隨著更多資料進行擴充套件,並且在涉及大型資料集的應用程式中表現尤其出色。
我們選擇 PyTorch 來開發我們的模型,因為它幫助我們最大限度地提高了系統的效能。藉助 PyTorch,我們可以更好地服務客戶,同時利用 Python 最直觀的概念。PyTorch 的程式設計是面向物件的:它將處理函式與其修改的資料分組。因此,我們的程式碼庫是模組化的,我們可以在不同的應用程式中重用程式碼片段。此外,PyTorch 的急切模式允許迴圈和控制結構,因此可以在模型中進行更復雜的操作。急切模式使我們能夠輕鬆地對模型進行原型設計和迭代,並且我們可以使用各種資料結構。這種靈活性有助於我們快速更新模型以滿足不斷變化的業務需求。
“在此之前,我們嘗試了其他‘Pythonic’框架,但 PyTorch 在這裡顯然是我們的贏家。”應用科學家 Yashal Kanungo 說。“使用 PyTorch 很容易,因為它的結構感覺像是 Python 原生程式設計,資料科學家對此非常熟悉。”
訓練管道
如今,我們完全在 PyTorch 中構建文字模型。為了節省時間和金錢,我們通常透過對預訓練的 NLP 模型進行微調以進行語言分析來跳過訓練的早期階段。如果我們需要一個新模型來評估影像或影片,我們首先瀏覽 PyTorch 的 torchvision 庫,該庫提供用於影像和影片分類、目標檢測、例項分割和姿態估計的預訓練選項。對於專業任務,我們從頭開始構建自定義模型。PyTorch 非常適合此任務,因為急切模式和使用者友好的前端使其易於嘗試不同的架構。
要了解如何在 PyTorch 中微調神經網路,請前往 本教程。
在開始訓練之前,我們會最佳化模型的超引數,即定義網路架構(例如,隱藏層數量)和訓練機制(例如,學習率和批次大小)的變數。選擇適當的超引數值至關重要,因為它們將影響模型的訓練行為。我們在此步驟中依賴於 AWS ML 平臺 SageMaker 中的貝葉斯搜尋功能。貝葉斯搜尋將超引數調優視為迴歸問題:它提出可能產生最佳結果的超引數組合,並執行訓練作業以測試這些值。每次試驗後,迴歸演算法都會確定下一組要測試的超引數值,並且效能會逐步提高。
我們使用 SageMaker Notebooks 對模型進行原型設計和迭代。急切模式透過為每個訓練批次構建一個新的計算圖來幫助我們快速原型化模型;操作序列可以在每次迭代中更改,以適應不同的資料結構或與中間結果保持一致。這使我們能夠在訓練期間調整網路而無需從頭開始。這些動態圖對於基於可變序列長度的遞迴計算特別有價值,例如使用 NLP 分析的廣告中的單詞、句子和段落。
當模型架構最終確定後,我們會在 SageMaker 上部署訓練作業。PyTorch 透過同時執行多個訓練作業來幫助我們更快地開發大型模型。PyTorch 的 分散式資料並行 (DDP) 模組將單個模型複製到 SageMaker 中多個互連的機器上,並且所有程序同時對各自獨特的資料集部分執行前向傳播。在反向傳播期間,該模組會平均所有程序的梯度,因此每個區域性模型都使用相同的引數值進行更新。
模型部署管道
當我們在生產環境中部署模型時,我們希望在不影響預測準確性的前提下降低推理成本。PyTorch 的一些功能和 AWS 服務幫助我們解決了這一挑戰。
動態圖的靈活性豐富了訓練,但在部署中我們希望最大限度地提高效能和可移植性。在 PyTorch 中開發 NLP 模型的一個優點是,它們可以透過 TorchScript(一個專門用於 ML 應用程式的 Python 子集)開箱即用地被追蹤到靜態操作序列。Torchscript 將 PyTorch 模型轉換為更高效、對生產更友好的中間表示 (IR) 圖,該圖易於編譯。我們透過模型執行一個示例輸入,TorchScript 記錄了前向傳播期間執行的操作。生成的 IR 圖可以在高效能環境中執行,包括 C++ 和其他多執行緒無 Python 環境,並且諸如運算子融合等最佳化可以加快執行時速度。
Neuron SDK 和 AWS Inferentia 支援的計算
我們將模型部署在由 AWS Inferentia 提供支援的 Amazon EC2 Inf1 例項上,Inferentia 是亞馬遜首款旨在加速深度學習推理工作負載的 ML 晶片。與基於 Amazon EC2 GPU 的例項相比,Inferentia 已證明可將推理成本降低多達 70%。我們使用 AWS Neuron SDK(與 Inferentia 配合使用的一套軟體工具)來編譯和最佳化我們的模型,以便在 EC2 Inf1 例項上部署。
以下程式碼片段展示瞭如何使用 Neuron 編譯 Hugging Face BERT 模型。與 torch.jit.trace() 類似,neuron.trace() 在前向傳播期間記錄模型在示例輸入上的操作,以構建靜態 IR 圖。
import torch
from transformers import BertModel, BertTokenizer
import torch.neuron
tokenizer = BertTokenizer.from_pretrained("path to saved vocab")
model = BertModel.from_pretrained("path to the saved model", returned_dict=False)
inputs = tokenizer ("sample input", return_tensor="pt")
neuron_model = torch.neuron.trace(model,
example_inputs = (inputs['input_ids'], inputs['attention_mask']),
verbose = 1)
output = neuron_model(*(inputs['input_ids'], inputs['attention_mask']))
自動型別轉換和重新校準
在底層,Neuron 透過將模型自動轉換為較小的資料型別來最佳化其效能。預設情況下,大多數應用程式以 32 位單精度浮點 (FP32) 數字格式表示神經網路值。將模型自動轉換為 16 位格式(半精度浮點 (FP16) 或 Brain 浮點 (BF16))可減少模型的記憶體佔用和執行時間。在我們的案例中,我們決定使用 FP16 來最佳化效能,同時保持高精度。
在某些情況下,自動型別轉換到較小的資料型別可能會導致模型預測略有不同。為了確保模型的準確性不受影響,Neuron 會比較 FP16 和 FP32 模型的效能指標和預測。當自動型別轉換降低模型準確性時,我們可以告訴 Neuron 編譯器只將權重和某些資料輸入轉換為 FP16,而將其餘的中間結果保留在 FP32 中。此外,我們通常會使用訓練資料執行幾次迭代,以重新校準我們自動型別轉換的模型。這個過程比原始訓練強度要小得多。
部署
為了分析多媒體廣告,我們執行一組深度學習模型。所有上傳到亞馬遜的廣告都會透過專門的模型進行執行,這些模型評估其中包含的每種型別的內容:影像、影片和音訊、標題、文字、背景,甚至語法、詞法和可能不當的語言。我們從這些模型接收到的訊號表明廣告是否符合我們的標準。
部署和監控多個模型非常複雜,因此我們依賴於 TorchServe,它是 SageMaker 預設的 PyTorch 模型服務庫。TorchServe 由 Facebook 的 PyTorch 團隊和 AWS 聯合開發,旨在簡化從原型設計到生產的過渡,它幫助我們大規模部署訓練好的 PyTorch 模型,而無需編寫自定義程式碼。它提供了一組安全的 REST API,用於推理、管理、指標和解釋。憑藉多模型服務、模型版本控制、整合支援和自動批處理等功能,TorchServe 非常適合支援我們龐大的工作負載。您可以在這篇 部落格文章 中閱讀更多關於使用 Amazon SageMaker 原生 TorchServe 整合在 SageMaker 上部署您的 Pytorch 模型的資訊。
在某些用例中,我們利用 PyTorch 的面向物件程式設計正規化,將多個深度學習模型封裝到一個父物件中——一個 PyTorch nn.Module——並將其作為單個整合進行服務。在其他情況下,我們使用 TorchServe 在獨立的 SageMaker 端點上服務單個模型,這些端點執行在 AWS Inf1 例項上。
自定義處理程式
我們特別欣賞 TorchServe 允許我們將模型初始化、預處理、推理和後處理程式碼嵌入到單個 Python 指令碼 handler.py 中,該指令碼位於伺服器上。這個指令碼——處理程式——預處理來自廣告的未標記資料,透過我們的模型執行這些資料,並將產生的推理結果傳遞給下游系統。TorchServe 提供了幾個預設處理程式,用於載入權重和架構,並準備模型以在特定裝置上執行。我們可以將所有其他必需的工件(例如詞彙檔案或標籤對映)與模型捆綁在一個存檔檔案中。
當我們需要部署具有複雜初始化過程或源自第三方庫的模型時,我們會在 TorchServe 中設計自定義處理程式。這些處理程式允許我們載入來自任何庫的任何模型,並使用任何必需的程序。以下程式碼片段展示了一個簡單的處理程式,可以在任何 SageMaker 託管端點例項上服務 Hugging Face BERT 模型。
import torch
import torch.neuron
from ts.torch_handler.base_handler import BaseHandler
import transformers
from transformers import AutoModelForSequenceClassification,AutoTokenizer
class MyModelHandler(BaseHandler):
def initialize(self, context):
self.manifest = ctx.manifest
properties = ctx.system_properties
model_dir = properties.get("model_dir")
serialized_file = self.manifest["model"]["serializedFile"]
model_pt_path = os.path.join(model_dir, serialized_file)
self.tokenizer = AutoTokenizer.from_pretrained(
model_dir, do_lower_case=True
)
self.model = AutoModelForSequenceClassification.from_pretrained(
model_dir
)
def preprocess(self, data):
input_text = data.get("data")
if input_text is None:
input_text = data.get("body")
inputs = self.tokenizer.encode_plus(input_text, max_length=int(max_length), pad_to_max_length=True, add_special_tokens=True, return_tensors='pt')
return inputs
def inference(self,inputs):
predictions = self.model(**inputs)
return predictions
def postprocess(self, output):
return output
批處理
硬體加速器針對並行性進行了最佳化,而批處理——在單個步驟中向模型饋送多個輸入——有助於飽和所有可用容量,通常會帶來更高的吞吐量。然而,過高的批處理大小可能會增加延遲,而吞吐量的改進卻很小。嘗試不同的批處理大小有助於我們找到模型和硬體加速器的最佳點。我們執行實驗來確定模型大小、負載大小和請求流量模式的最佳批處理大小。
Neuron 編譯器現在支援可變批處理大小。以前,跟蹤模型會硬編碼預定義的批處理大小,因此我們必須填充資料,這會浪費計算資源,降低吞吐量,並加劇延遲。Inferentia 經過最佳化,可最大限度地提高小批處理的吞吐量,透過減輕系統負載來降低延遲。
並行性
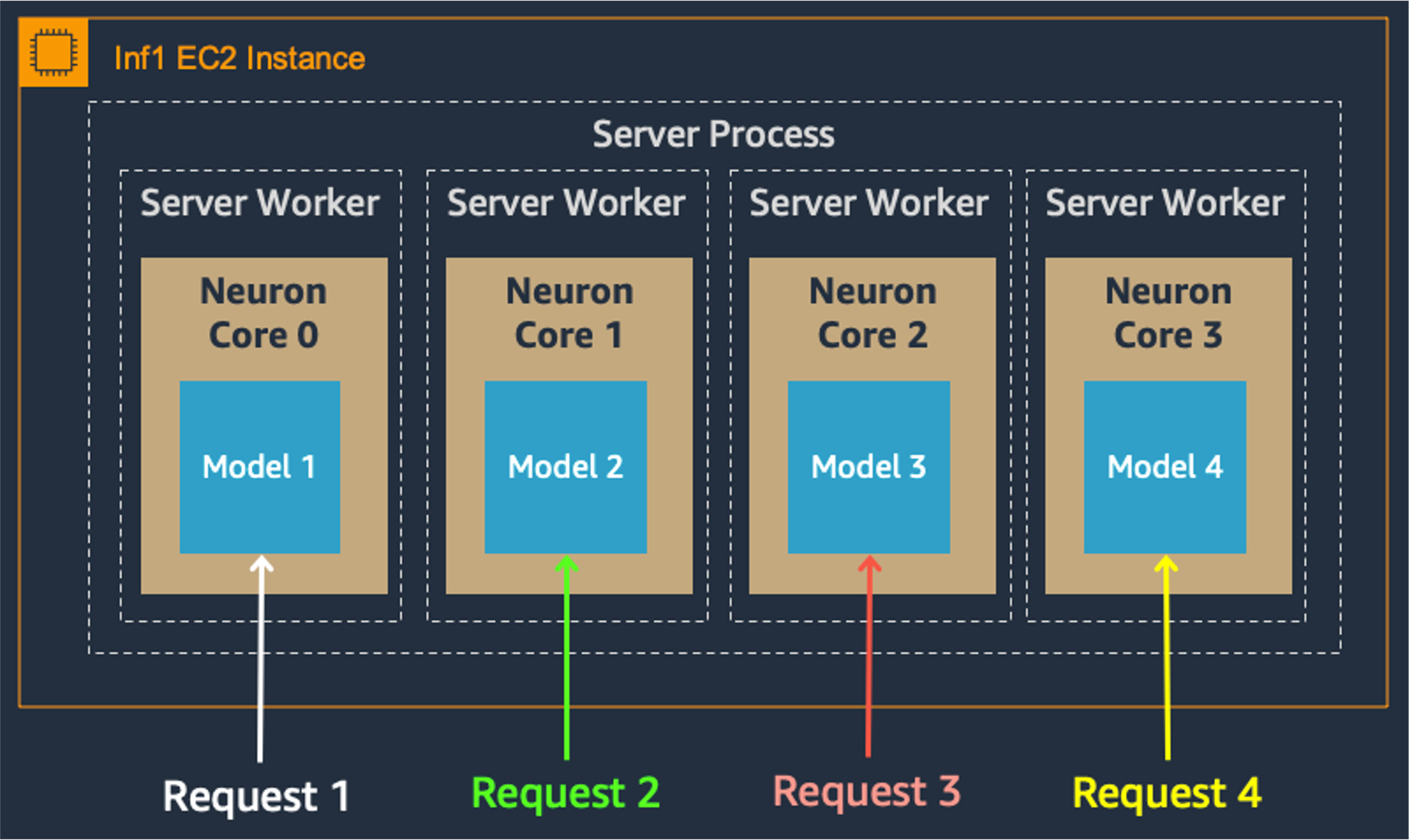
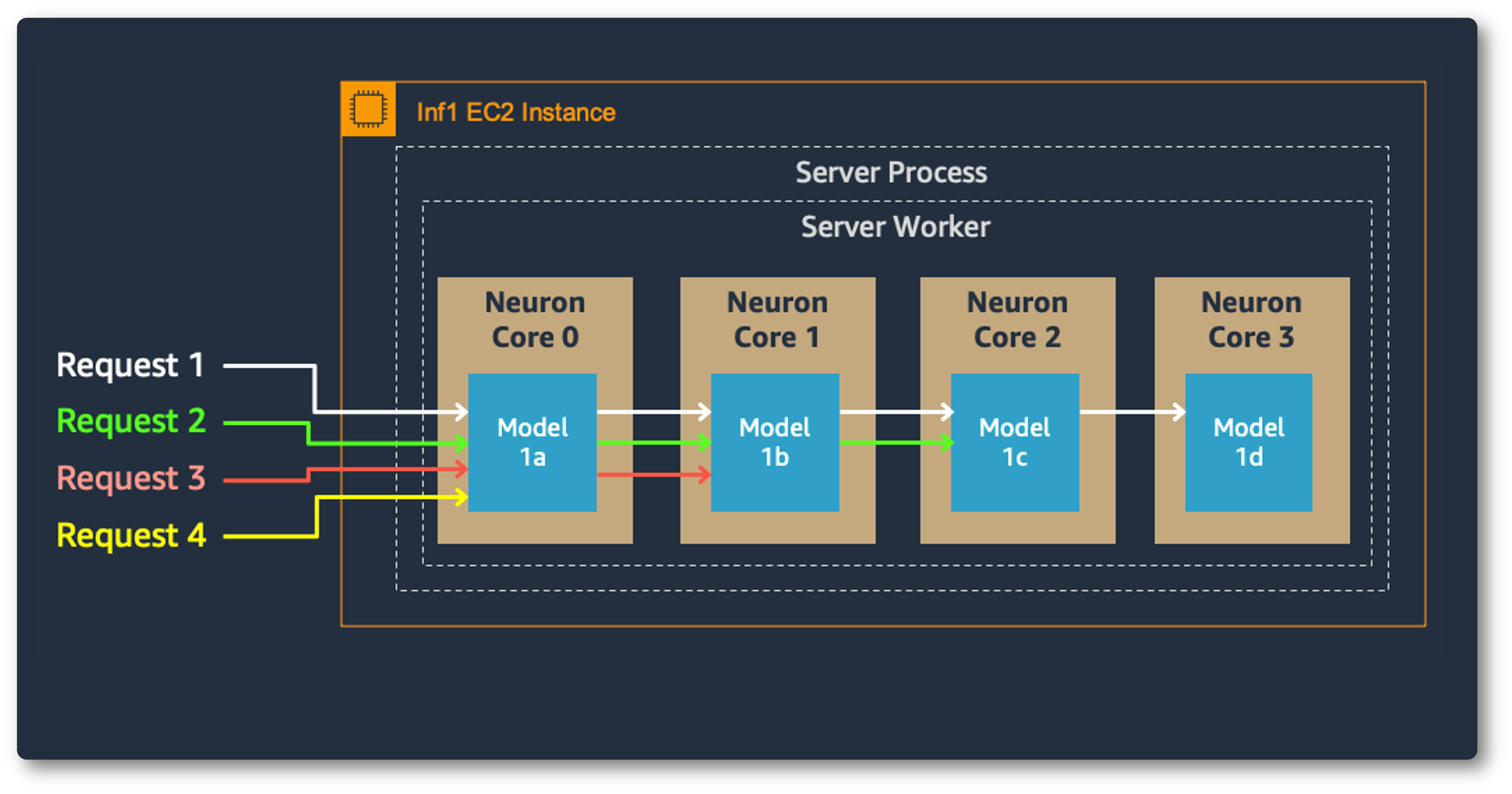
多核模型並行性也改善了吞吐量和延遲,這對於我們繁重的工作負載至關重要。每個 Inferentia 晶片包含四個 NeuronCore,它們可以同時執行單獨的模型,也可以形成管道來流式傳輸單個模型。在我們的用例中,資料並行配置以最低的成本提供最高的吞吐量,因為它擴充套件了併發處理請求。
資料並行
模型並行
監控
至關重要的是,我們必須監控生產環境中推理的準確性。最初做出良好預測的模型最終可能會在部署中退化,因為它們會暴露於更廣泛的資料中。這種現象稱為模型漂移,通常發生在輸入資料分佈或預測目標發生變化時。
我們使用 SageMaker Model Monitor 來跟蹤訓練資料和生產資料之間的一致性。當生產中的預測開始偏離訓練和驗證結果時,Model Monitor 會通知我們。得益於這一早期預警,我們可以在廣告商受到影響之前恢復準確性——必要時透過重新訓練模型。為了即時跟蹤效能,Model Monitor 還會向我們傳送有關預測質量的指標,例如準確率、F 值和預測類別的分佈。
為了確定我們的應用程式是否需要擴充套件,TorchServe 會定期記錄 CPU、記憶體和磁碟的資源利用率指標;它還會記錄收到的請求數量與已服務的請求數量。對於自定義指標,TorchServe 提供了一個 Metrics API。
令人欣喜的成果
我們的深度學習模型,使用 PyTorch 開發並部署在 Inferentia 上,加速了我們的廣告分析,同時降低了成本。從我們最初探索深度學習開始,用 PyTorch 程式設計就感覺很自然。其使用者友好的功能幫助我們從早期實驗到多模態整合的部署都順利進行。PyTorch 讓我們能夠快速原型設計和構建模型,這對於我們廣告服務的不斷發展和擴充套件至關重要。此外,PyTorch 與 Inferentia 和我們的 AWS ML 堆疊無縫協作。我們期待使用 PyTorch 構建更多用例,以便我們能夠繼續為客戶提供準確的即時結果。