主要收穫
- PyTorch 和 vLLM 已有機整合,以加速尖端生成式 AI 應用,例如推理、訓練後和代理系統。
- 預填充/解碼解耦是一項關鍵技術,可在大規模下同時提高生成式 AI 推理的延遲和吞吐量效率。
- 預填充/解碼解耦已在 Meta 內部推理堆疊中啟用,服務於大規模 Meta 流量。透過 Meta 和 vLLM 團隊的協作努力,Meta vLLM 解耦實現已證明其效能優於 Meta 內部 LLM 推理堆疊。
- Meta 的最佳化和可靠性增強正在向上遊 vLLM 社群貢獻。
在我們之前的文章《PyTorch + vLLM》中,我們分享了 vLLM 加入 PyTorch 基金會的激動人心的訊息,並強調了 PyTorch 和 vLLM 之間的一些整合成就以及計劃中的舉措。其中一個關鍵舉措是用於推理的大規模預填充-解碼 (P/D) 解耦,旨在提高 Meta LLM 產品的吞吐量,同時滿足延遲預算。在過去的兩個月中,Meta 工程師投入了大量精力來實現與 vLLM 的內部 P/D 解耦整合,從而在 TTFT (首次生成令牌時間) 和 TTIT (迭代生成令牌時間) 指標方面,與 Meta 現有的內部 LLM 推理堆疊相比,效能有所提高。vLLM 與 llm-d 和 dynamo 有原生整合。在 Meta 內部,我們開發了抽象層,可以加速 KV 傳輸到我們的服務叢集拓撲和設定。本文將重點介紹 Meta 對 vLLM 的定製以及與上游 vLLM 的整合。
解耦預填充/解碼
在 LLM 推理中,第一個令牌依賴於使用者提供的輸入提示令牌,所有後續令牌以自迴歸方式一次生成一個令牌。我們將第一個令牌的生成稱為“預填充”,將剩餘令牌的生成稱為“解碼”。
雖然執行的都是基本相同的操作集,但預填充和解碼錶現出截然不同的特性。一些顯著的特性是
- 預填充
- 計算密集型
- 令牌長度和批次大小限制延遲
- 每個請求發生一次
- 解碼
- 記憶體密集型
- 批次大小限制效率
- 在整體延遲中占主導地位
預填充/解碼解耦旨在將預填充和解碼解耦到單獨的主機中,其中解碼主機將請求重定向到預填充主機以進行第一個令牌生成,並自行處理剩餘部分。我們打算獨立擴充套件預填充和解碼推理,從而實現更高效的資源利用,並提高延遲和吞吐量。
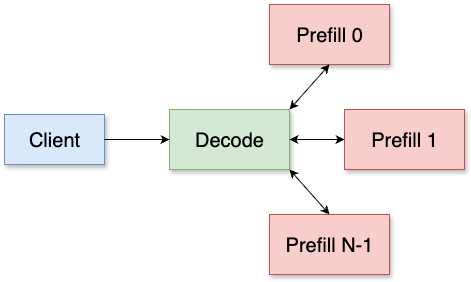
vLLM 整合概述
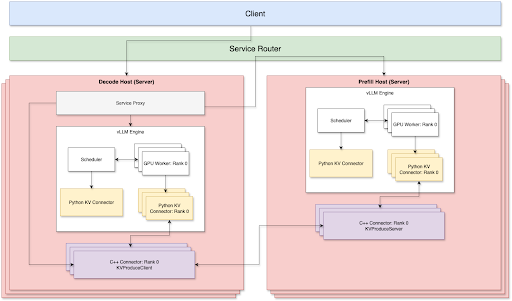
目前,預填充和解碼兩側都支援 TP + Disagg。為了透過 TCP 網路實現最佳的 P/D 解耦服務,有 3 個關鍵元件
- 代理庫
- Python KV 聯結器
- C++ 解碼 KV 聯結器和預填充 KV 聯結器,透過 TCP 連線
我們透過路由器層處理路由,該層負責負載均衡並透過 P2P 方式連線預填充節點和解碼節點,以減少網路開銷。預填充節點和解碼節點可以根據自己的工作負載獨立擴充套件或縮減。因此,在生產環境中執行時,我們不需要手動維護預填充:解碼比率。
元件
服務代理
服務代理連線到解碼伺服器。它將請求轉發到遠端預填充主機,並協調解碼和預填充 KV 聯結器之間的 KV 快取傳輸。我們使用 Meta 的內部服務路由器解決方案,根據伺服器工作負載和快取命中率在所有預填充主機之間進行負載均衡。
- 服務代理首先將傳入請求轉發到選定的預填充主機,同時建立多個流通道,透過底層的 Meta C++ 聯結器從同一預填充主機獲取 KV 快取。
- 獲取的遠端 KV 快取將首先複製到臨時 GPU 緩衝區,等待 vLLM KV 聯結器稍後將其注入到適當的 KV 塊中。
vLLM Python KV 聯結器
我們基於 vLLM v1 KV 聯結器介面 實現了一個非同步 KV 聯結器解決方案。KV 聯結器將與主模型執行流並行進行 KV 快取傳輸操作,並確保雙方的 GPU 操作沒有衝突。透過這樣做,我們實現了更快的 TTIT/TTFT;最佳化細節可以在下面部分找到。
- 在預填充端
- Python KV 聯結器將在每個層完成注意力計算後,為給定請求將 KV 快取儲存到臨時 CPU 緩衝區,並且此類儲存操作將透過底層的 Meta C++ 聯結器進行。透過這樣做,我們確保主流模型執行不會被阻塞。
- KV 快取儲存完成後,它將立即流式傳輸到遠端解碼主機。
- 在解碼端
- 獲取遠端 KV 快取並將其複製到臨時 GPU 緩衝區後,Python KV 聯結器將開始將遠端 KV 快取注入到 vLLM 分配的本地 KV 快取塊中。這也透過底層的 Meta C++ 聯結器在其獨立的 C++ 執行緒和 CUDA 流中進行。
- KV 注入完成後,Python KV 聯結器將把請求釋放回 vLLM 排程器,並且該請求將在下一次迭代中安排執行。
- 錯誤處理
- 我們還實現了一個通用的垃圾收集器,用於清理從遠端獲取的空閒 KV 快取緩衝區,以避免 CUDA OOM 問題。這涵蓋了以下邊緣情況:
- 被搶佔的請求、取消/中止的請求,這些請求可能已完成遠端獲取但本地注入已中止。
- 我們還實現了一個通用的垃圾收集器,用於清理從遠端獲取的空閒 KV 快取緩衝區,以避免 CUDA OOM 問題。這涵蓋了以下邊緣情況:
Meta C++ 聯結器
由於 KV 傳輸操作具有繁重的 IO,我們選擇使用 C++ 實現它們,這樣我們可以更好地並行化資料傳輸並微調執行緒模型。所有實際的 KV 傳輸操作,例如透過網路流式傳輸、本地 H2D/D2H、KV 注入/提取,都在它們自己的 C++ 執行緒中進行,並使用單獨的 CUDA 流。
預填充 C++ 聯結器
在每個層完成模型注意力計算後,KV 快取被解除安裝到 DRAM 上的 C++ 聯結器。然後,它將 KV 快取流式傳輸回解碼主機,用於特定的請求和層。
解碼 C++ 聯結器
它從代理層接收請求及其路由的預填充主機地址,然後建立多個流通道以獲取遠端 KV 快取。它將獲取的 KV 快取緩衝在 DRAM 上,並非同步將其注入到預分配的 GPU KV 快取塊中。
最佳化
加速網路傳輸
- 多網絡卡支援: 多個前端網絡卡 (NIC) 連線到最近的 GPU,優化了解碼和預填充 KV 聯結器之間的連線。
- 多流 KV 快取傳輸: 單個 TCP 流無法飽和網路頻寬。為了最大限度地提高網路吞吐量,KV 快取被切片並使用多個流並行傳輸。
最佳化服務效能
- 粘性路由: 在預填充轉發中,來自同一會話的請求始終定向到同一預填充主機。這顯著提高了多輪用例的字首快取命中率。
- 負載均衡: 我們利用 Meta 的內部服務路由器根據每個主機的利用率有效地在各種預填充主機之間分配工作負載。這與粘性路由相結合,使得字首快取命中率達到 40%-50%,同時將 HBM 利用率保持在 90%。
微調 vLLM
- 更大的塊大小: 雖然 vLLM 建議每個 KV 快取塊 16 個令牌,但我們發現,在 CPU 和 GPU 之間傳輸這些較小的塊會由於 KV 快取注入和提取期間大量的微小核心啟動而產生大量的開銷。因此,我們採用了更大的塊大小(例如,128、256)以提高解耦效能,並進行了必要的核心端調整。
- 停用解碼字首快取: 解碼主機從 KV 聯結器載入 KV 快取,使得字首雜湊計算成為排程器的不必要開銷。在解碼端停用它可以幫助穩定 TTIT(令牌間時間)。
改進 TTFT(首次生成令牌時間)
- 早期首次令牌返回: 代理層從預填充層接收響應,並立即將第一個令牌返回給客戶端。同時,引擎解碼第二個令牌。我們還重用了預填充的令牌化提示,消除了解碼端的額外令牌化步驟。這確保了 P/D 解耦解決方案的 TTFT 儘可能接近預填充主機的 TTFT。
增強 TTIT(迭代生成令牌時間)
- 僅使用基本型別: 我們觀察到,在 vLLM 排程器和工作器之間傳輸資料時,Python 的原生 pickle dump 序列化張量所需的時間是序列化整數列表的三倍。這通常會導致隨機排程器程序掛起,對 TTIT 產生負面影響。最好避免在 KVConnectorMetadata 和 SchedulerOutput 中建立張量或複雜物件。
- 非同步 KV 載入: 我們將 KV 載入操作與 vLLM 模型解碼步驟並行化。這可以防止等待遠端 KV 的請求阻塞已經在生成新輸出令牌的請求。
- 最大化 GPU 操作重疊: 由於 KV 傳輸操作主要是複製/IO 操作,而主流模型前向執行是計算密集型的,我們成功地將 KV 傳輸操作在其自己的 CUDA 流中與主模型前向執行完全重疊。這導致 KV 傳輸不會產生額外的延遲開銷。
- 避免 CPU 排程爭用: 我們不是同時排程所有層的 KV 注入(本質上是索引複製操作),這可能在模型前向透過期間導致核心排程爭用,而是按順序排程每層 KV 注入,與模型前向透過同步。
- 非阻塞複製操作: 所有複製(主機到裝置/裝置到主機)操作都以非阻塞方式執行。我們還解決了一個問題,即在預設 CUDA 流中執行的主模型前向透過意外地阻塞了來自非阻塞 CUDA 流的其他複製操作。
效能結果
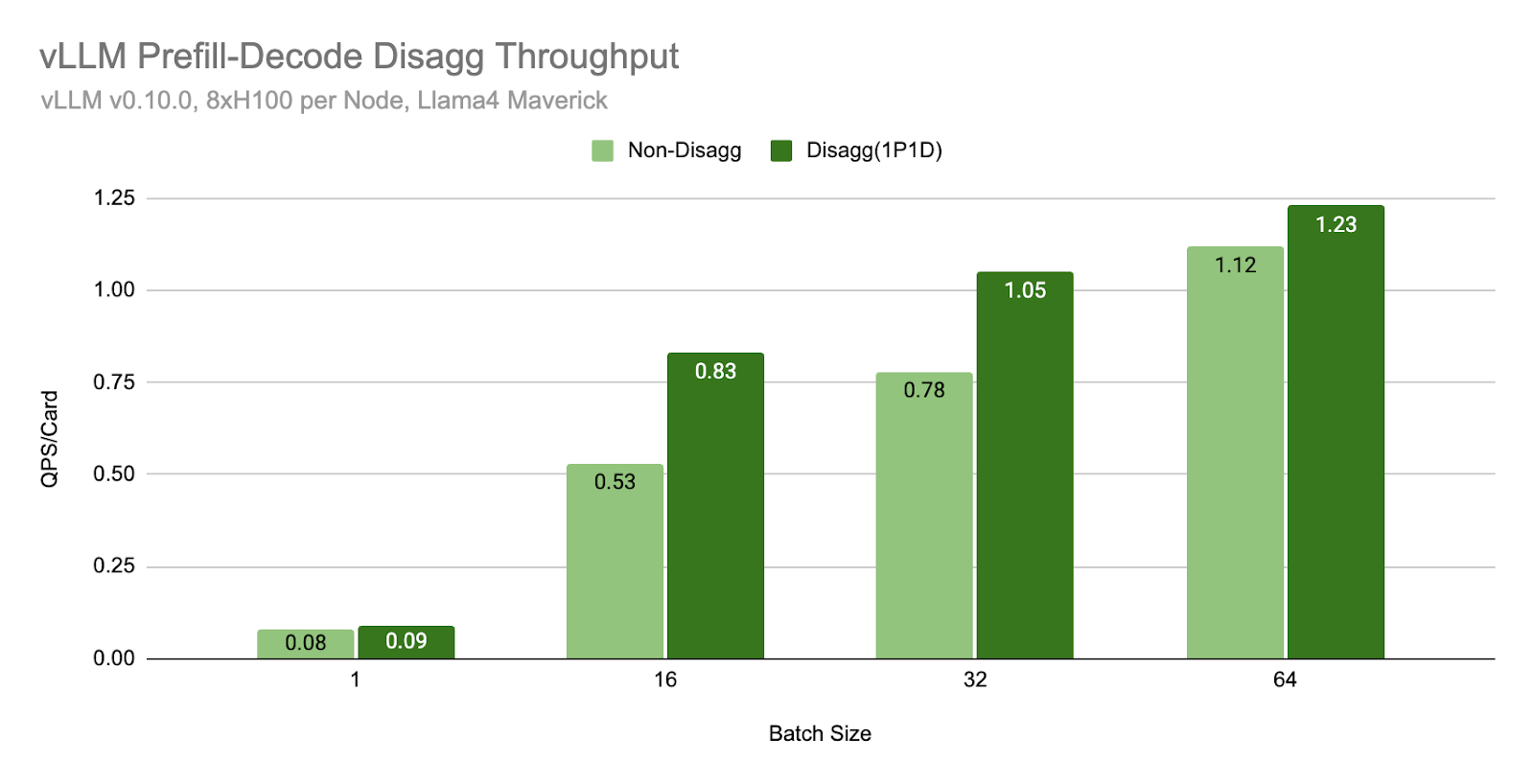
我們使用 Llama4 Maverick 在透過 TCP 網路連線的 H100 主機(每個主機 8xH100 卡)上進行了基準測試。評估使用的輸入長度為 2000,輸出長度為 150。
在相同的批次大小下,我們發現解耦 (1P1D) 可以提供更高的吞吐量
在相同的 QPS 工作負載下,我們發現解耦 (1P1D) 由於 TTIT 曲線更平滑,可以更好地控制整體延遲。
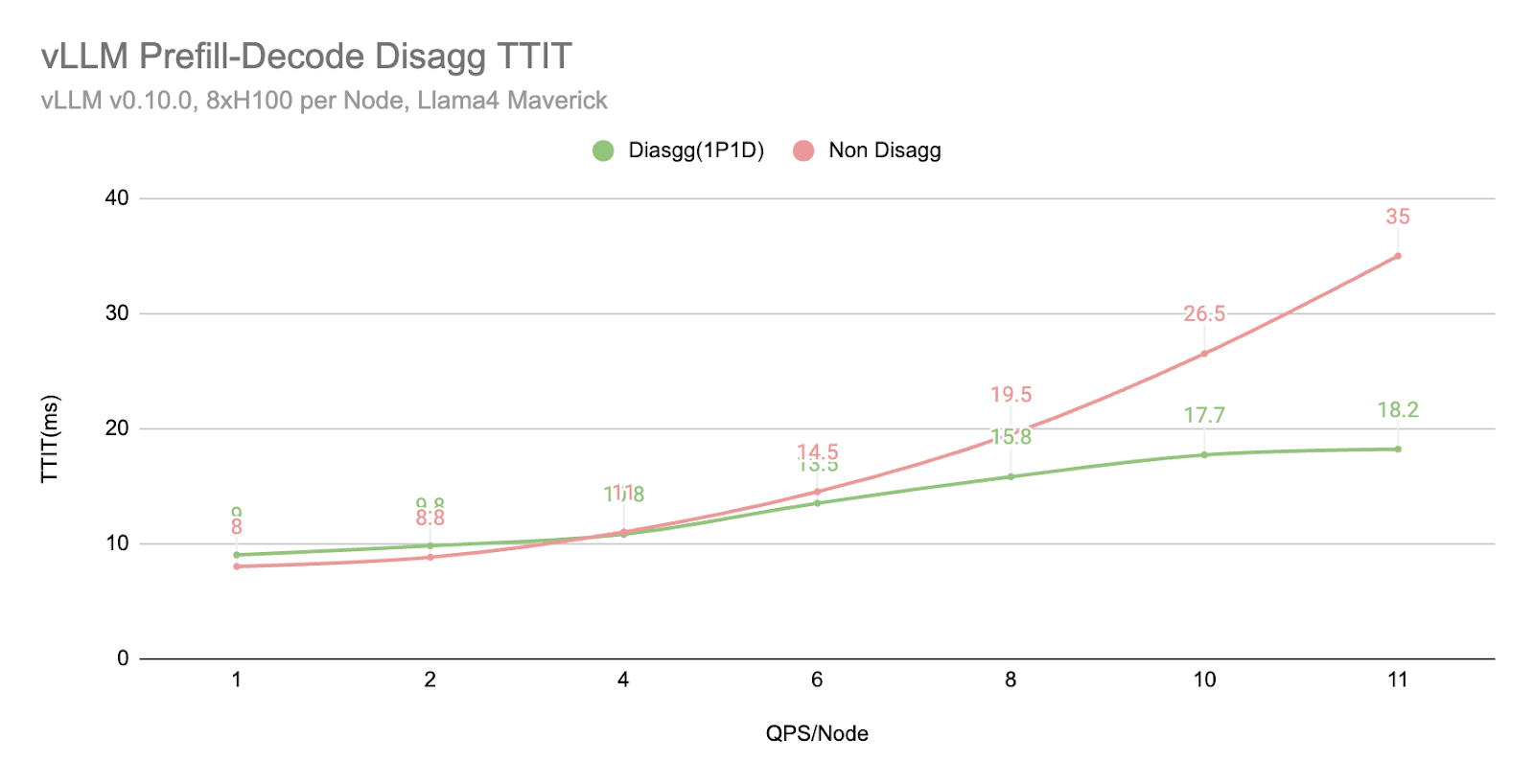
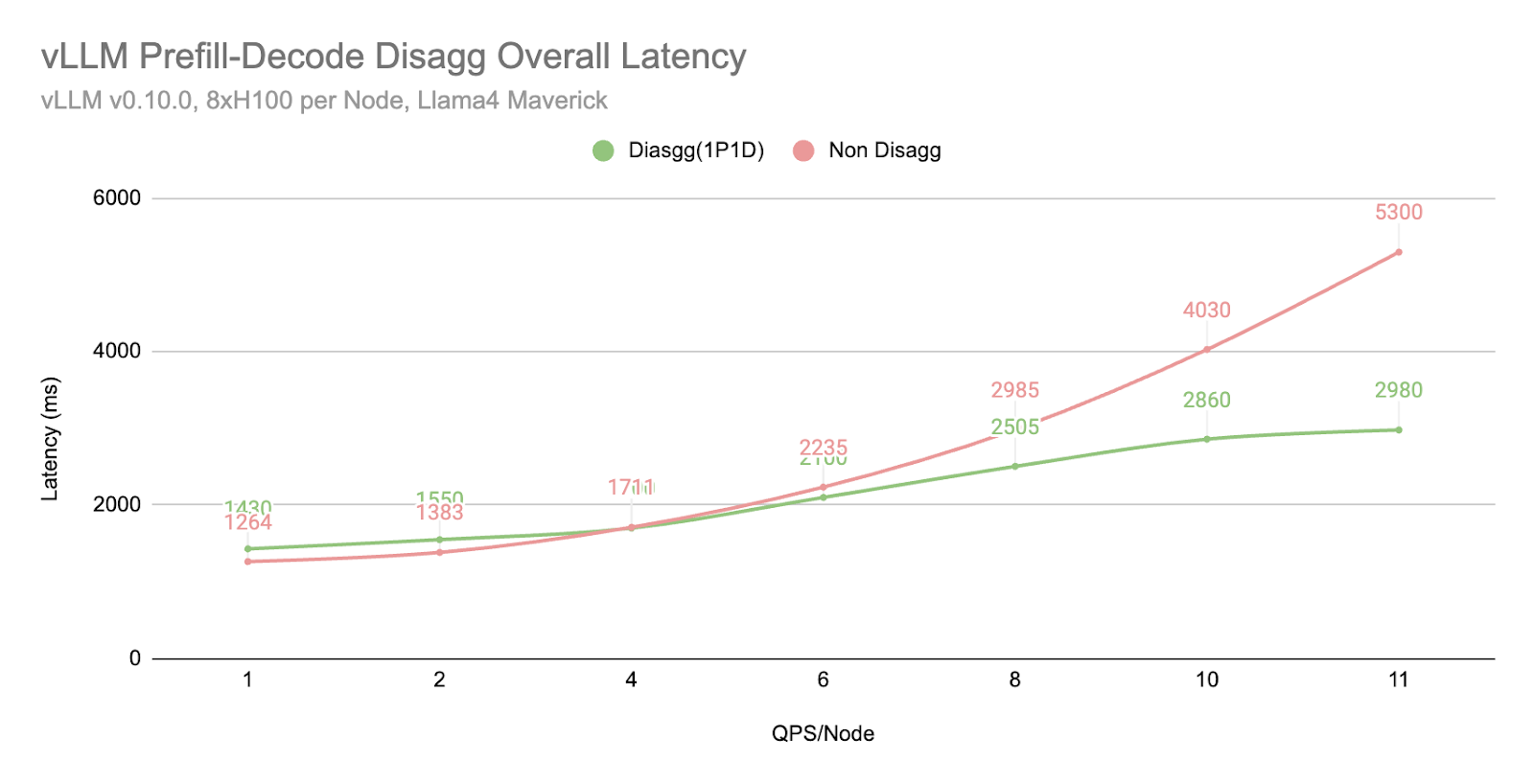
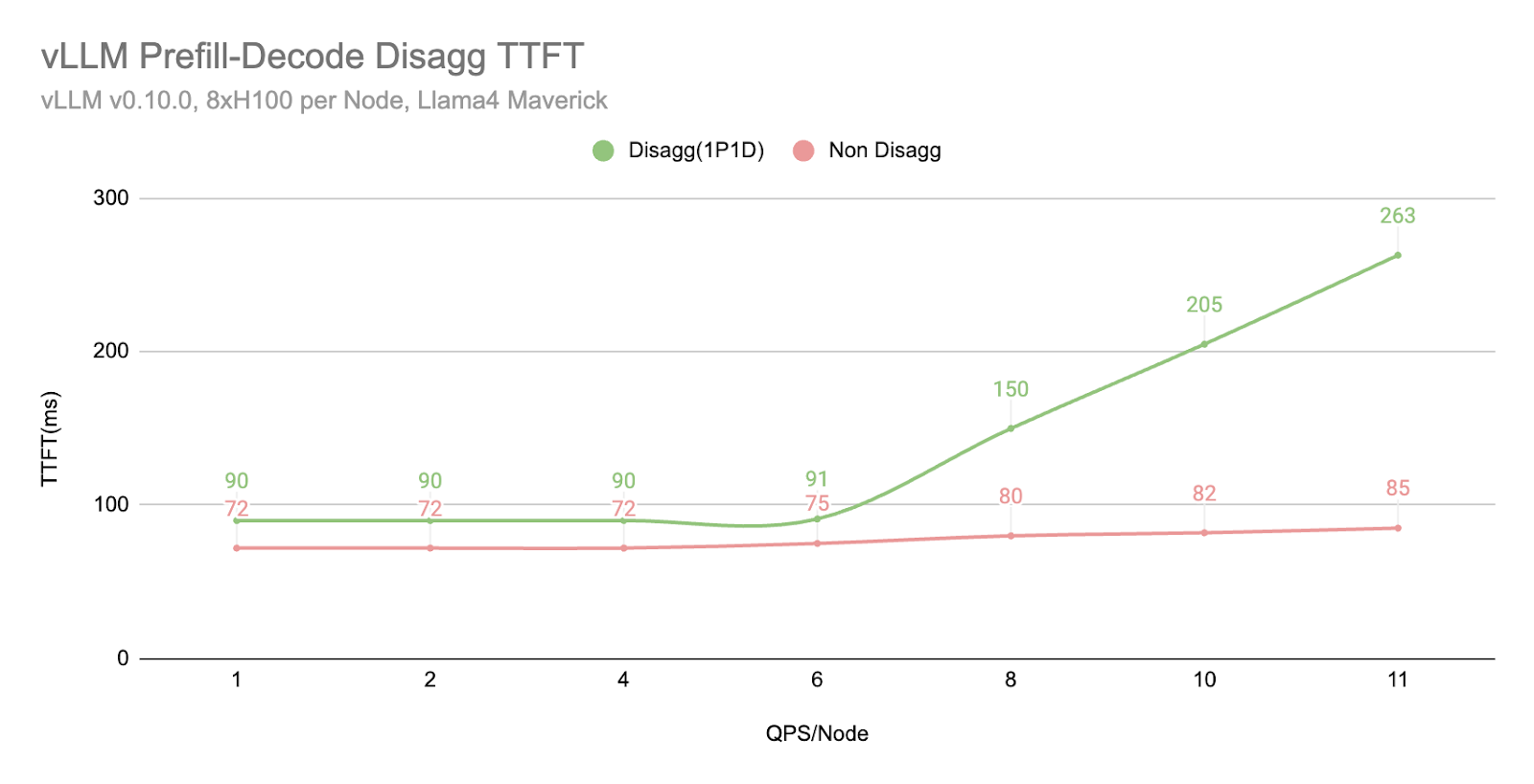
然而,我們也注意到,當工作負載變得非常大時,TTFT 會以更急劇的曲線回退,這可能由於多種原因(正如我們在下一節“更多探索”中提到的)
- 透過 TCP 連線,網路成為瓶頸。
- 1P1D 設定對預填充端施加了更大的工作負載壓力,因為我們的評估是在更多預填充密集型工作(2000 個輸入 vs 150 個輸出)上進行的。理想情況下,需要更高的預填充到解碼比率。
更多探索
- 僅快取未命中 KV 傳輸
- 我們還原型化了僅快取未命中 KV 傳輸機制,在該機制中,我們僅從遠端獲取解碼端缺失的 KV 快取。例如,如果請求具有 40% 的字首快取命中率,我們將僅從預填充端獲取其餘 60% 的 KV 快取。根據早期觀察,當 QPS 很高時,它會產生更平滑的 TTFT/TTIT 曲線。
- 預填充的計算-通訊重疊
- 對於預填充,我們還探索了在自己的 CUDA 流中完成 KV 快取儲存的解決方案,這使其與模型前向透過並行執行。我們計劃進一步探索這個方向並調整相關的服務設定,以推動更好的 TTFT 限制。
- 解耦 + DP/EP
- 為了支援 Meta 的大規模 vLLM 服務,我們正在實現 P/D 解耦和大規模 DP/EP 的整合,旨在透過不同程度的負載均衡和網路原語最佳化來實現整體最佳吞吐量和延遲。
- RDMA 通訊支援
- 目前,我們依賴 Thrift 進行透過 TCP 的資料傳輸,這涉及大量的額外張量移動和網路堆疊開銷。透過利用 NVLink 和 RDMA 等先進的通訊連線,我們看到了進一步提高 TTFT 和 TTIT 效能的機會。
- 硬體特定最佳化
- 目前,我們正在將我們的解決方案生產化到 H100 硬體環境,並且我們計劃將硬體特定最佳化擴充套件到提供 GB200 的其他硬體環境。
當然,我們將繼續將所有這些功能貢獻到上游,以便社群可以在核心 vLLM 專案和 PyTorch 中利用所有這些功能。如果您希望以任何方式進行協作,請聯絡我們。
乾杯!
Meta & vLLM 團隊的 PyTorch 團隊