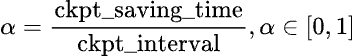隨著訓練作業規模的擴大,搶佔、崩潰或基礎設施不穩定等故障的可能性也隨之增加。這可能導致訓練效率低下,並延遲上市時間。在如此大的規模下,高效的分散式檢查點至關重要,它能減輕故障的負面影響,並最佳化整體訓練效率(訓練吞吐量)。
訓練不良吞吐量 (Training badput) 是指作業總持續時間中訓練未取得進展的百分比。我們可以使用中斷平均時間 (MTBI) 而不是總持續時間來計算訓練不良吞吐量,這樣推導適用於任何訓練持續時間。要計算檢查點不良吞吐量的百分比,我們將在 MTBI 間隔內因檢查點而損失的訓練時間除以 MTBI,以確定檢查點不良吞吐量的百分比。下面我們將正式定義檢查點不良吞吐量及其影響因素:

圖1:檢查點不良吞吐量的正式定義
上述公式分解為三個組成部分
- 載入:從中斷中恢復時從儲存載入檢查點所需的時間
- 儲存開銷:儲存檢查點對訓練造成的開銷
- 計算損失:從最近的檢查點恢復時損失的計算時間
最近由 PyTorch DistributedCheckpoint (DCP) 新增的功能,包括基於程序的非同步檢查點、儲存計劃快取和區域性檢查點等,改善了檢查點儲存開銷,進而縮短了檢查點儲存時間。檢查點不良吞吐量的進一步最小化取決於檢查點間隔。不頻繁的檢查點會導致檢查點之間存在更大的間隔,從而在必須恢復到上一個檢查點時增加可能丟失的訓練進度量。然而,由於檢查點會引入儲存開銷,因此過於頻繁地儲存檢查點會顯著擾亂訓練效能。最佳頻率可以透過數值計算確定,具體公式請參閱附錄。以下是對檢查點頻率及其對訓練不良吞吐量影響的直觀理解。
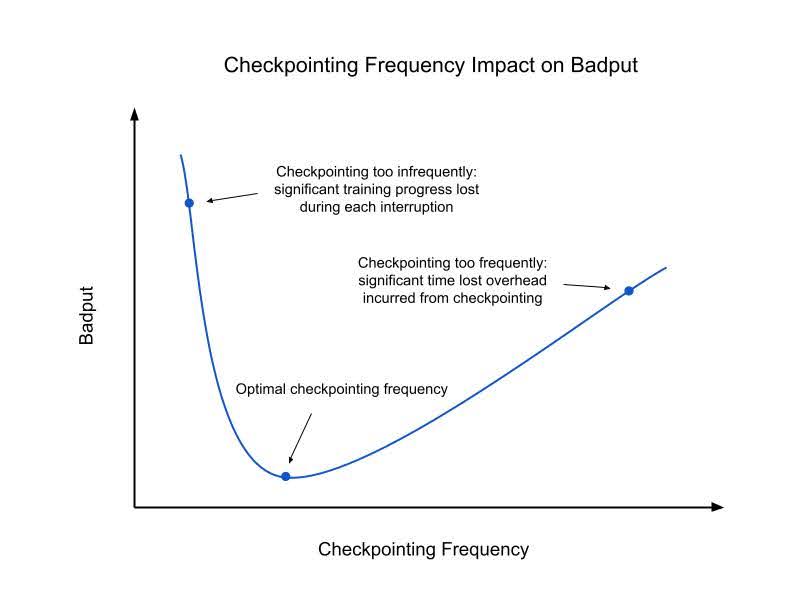
圖2:檢查點頻率對不良吞吐量的影響
過去,訓練工作負載依賴永續性儲存(例如:NFS、Lustre GCS)進行檢查點的寫入和讀取。在大規模場景下,處理永續性儲存會引入額外的延遲,這不幸地限制了檢查點儲存的速率。Google 和 PyTorch 最近合作開發了一種使用 DCP 的本地檢查點解決方案,可以頻繁地將檢查點儲存到本地儲存。正如我們稍後將展示的,本地檢查點克服了傳統設定的限制,並提高了訓練吞吐量。
最小化儲存開銷
在典型的檢查點工作流程中,當檢查點資料從 GPU 傳輸到 CPU 再傳輸到儲存時,GPU 會處於空閒狀態,只有在資料儲存後訓練才會恢復。非同步檢查點透過將資料儲存過程解除安裝到 CPU 執行緒,顯著減少了 GPU 阻塞時間。只有 GPU 解除安裝步驟仍然是同步的。這允許基於 GPU 的訓練同時進行,而檢查點資料則上傳到儲存。它主要用於中間檢查點或容錯檢查點,因為它比同步方法更快地釋放 GPU。訓練立即恢復,極大地提高了同步檢查點上的訓練吞吐量。欲瞭解更多詳細資訊,請參閱這篇 文章。
GIL 競爭導致 GPU 利用率下降
Python 中的全域性直譯器鎖 (GIL) 是一種機制,它阻止多個原生執行緒同時執行 Python 位元組碼。這種鎖主要是因為 CPython 的記憶體管理不是執行緒安全的,因此是必需的。
DCP 當前使用後臺執行緒進行元資料收集和上傳到儲存,儘管是非同步的,但它與訓練器執行緒爭奪 GIL。這顯著影響了 GPU 利用率並增加了端到端上傳延遲。對於大規模檢查點,CPU 並行處理的開銷對 GPU 訓練速度產生了抑制作用,因為 CPU 也透過 GPU 核心啟動來驅動訓練過程。
請參閱我們實驗中的下圖,它展示了基於執行緒的非同步檢查點對 GPU 利用率和訓練 QPS 的影響。
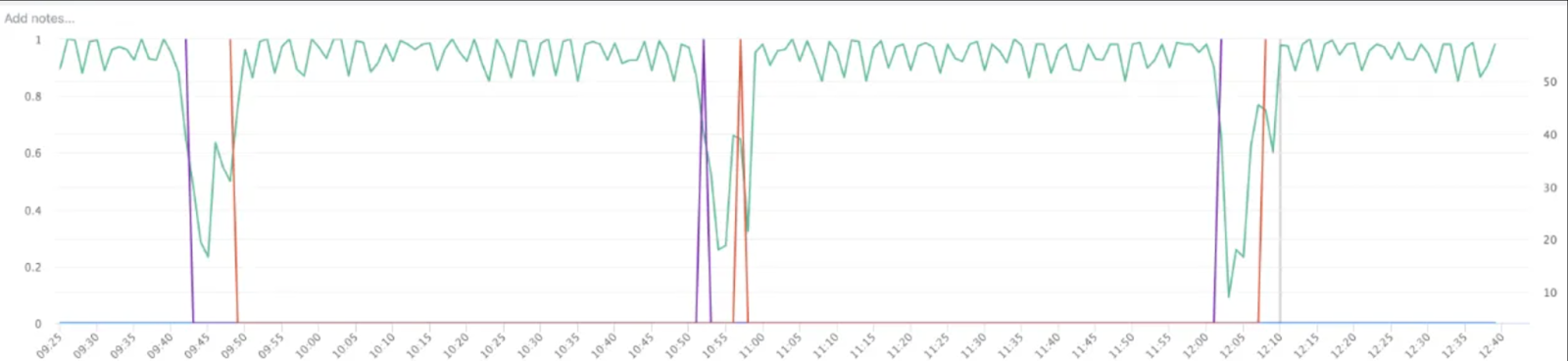
以下是 GIL 競爭導致檢查點儲存緩慢和訓練 QPS 降低的更詳細檢視
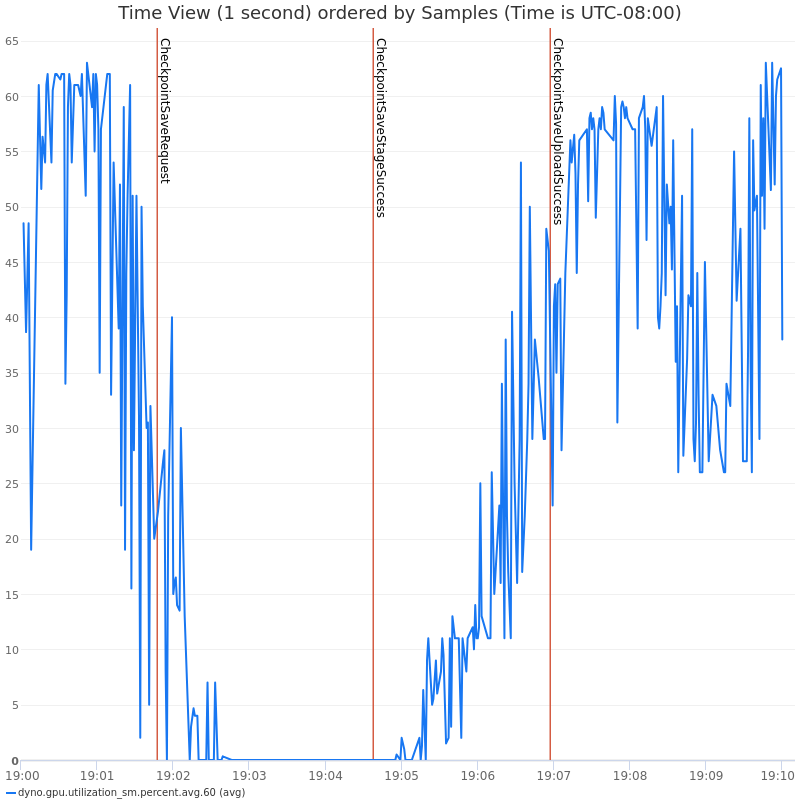
圖3和圖4:使用執行緒的非同步檢查點對 GPU 利用率和訓練 QPS 的影響
檢查點暫存成本
在非同步檢查點過程中,GPU 記憶體會解除安裝到 CPU 記憶體,這一步稱為暫存。這會引入與記憶體分配和解除分配相關的開銷,包括記憶體碎片、頁面錯誤和記憶體同步。透過解決這些開銷,可以減少檢查點上花費的總阻塞時間,從而提高整體訓練吞吐量。

圖5:暫存步驟概述
集體通訊成本
DCP 出於各種原因(資料去重、檢查點的全域性元資料、重新分片和分散式異常處理)執行了多個集合操作。集合操作成本高昂,因為它們需要網路 I/O 和大型 Python 物件的序列化/反序列化,這些物件透過 GPU 網路傳送。隨著作業規模的增加,這些集合操作變得極其昂貴,導致顯著更高的端到端延遲和集合操作超時的可能性。
快取計劃
為了容錯,作業期間會進行多次檢查點。DCP 明確分離了規劃和儲存 I/O 階段。在大多數情況下,只有狀態字典在檢查點儲存嘗試之間發生變化,而計劃保持一致。這允許計劃快取,僅在第一次儲存時產生成本,並在後續嘗試中分攤。這顯著減少了總體開銷,因為在同步期間只有更新的計劃透過集合操作傳送。
快取元資料
由於集合開銷,生成檢查點的全域性元資料成本很高。為了緩解這個問題,只要計劃保持不變,檢查點元資料就可以與儲存計劃一起快取,並在多次儲存嘗試中重複使用。
基於程序的檢查點
DCP 目前使用後臺執行緒進行元資料收集和上傳到儲存。儘管這些昂貴的步驟是非同步完成的,但它導致與訓練器執行緒爭奪 GIL。這導致 GPU 利用率 (QPS) 顯著下降,並且也大大增加了端到端上傳延遲。圖6 如下所示,基於程序的非同步檢查點如何有效減少與訓練器的 GIL 競爭。這與圖3和圖4 形成對比,其中基於執行緒的非同步檢查點由於 GIL 競爭而導致訓練速度變慢。
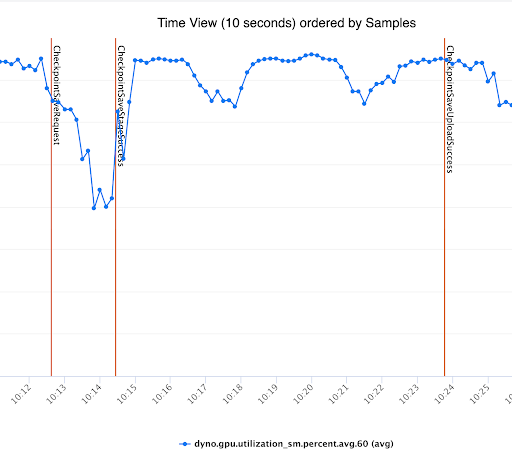
圖6:使用基於程序的非同步檢查點解決 GIL 競爭問題
固定記憶體暫存
我們的內部實驗表明,透過利用固定共享記憶體張量,可以加快將張量暫存到 CPU 或共享記憶體的速度,這有可能顯著改善非同步檢查點的阻塞時間。您可以此處和此處閱讀更多關於此策略的資訊。
基本思想是,由於 GPU 的某些機制,資料預設透過固定(不可分頁)記憶體傳輸到可分頁記憶體,這可以透過將某些位元組地址範圍指定為固定來最佳化,從而允許直接從 GPU 複製到共享記憶體。透過這種方法,我們看到暫存時間(GPU 阻塞時間)提高了 2 倍,顯著有助於提高訓練吞吐量,並允許更積極的檢查點間隔。
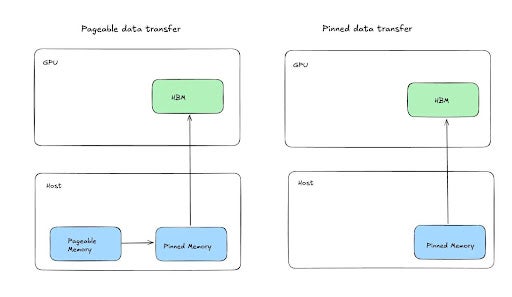
圖7:演示固定記憶體暫存
叢集本地檢查點
本地檢查點是指使用本地儲存(SSD、RAMDisk 等)儲存和載入檢查點,這意味著每個節點都將從其本地儲存而不是全域性持久化儲存中儲存和載入。本地檢查點的優點顯而易見,但由於大規模訓練作業中補救措施的複雜性,最佳利用它們可能很困難。
在訓練作業中,中斷通常發生在單個節點級別。節點可能因各種原因而失敗,這可能導致其本地狀態對工作負載的其餘部分不可訪問。為了快速恢復,訓練作業通常會預留備用容量,可用作替代。因此,主動訓練的節點集是動態的。此主動集的變化需要調整最佳化的網路拓撲,這可能進一步影響每個節點需要訓練的狀態。與訓練狀態始終可用的持久化儲存不同,當依賴本地儲存時,活動節點集的變化會導致一部分節點缺少所需的訓練狀態。
為了防止這些情況,工作負載通常會依賴某種形式的狀態複製和備份到持久化儲存。雖然始終保持一定頻率的備份到持久化儲存很重要,但本地檢查點引入的優勢促使人們尋求能夠處理狀態複製的複雜解決方案。
狀態可以透過啟用資料並行或在檢查點儲存期間複製,其中每個節點的狀態作為備份與另一個節點共享。在儲存時複製狀態會引入額外的延遲,因為每個節點都需要儲存自己的狀態和另一個節點的狀態。在檢查點載入時,兩種方法都需要在節點之間傳輸狀態的功能以及理解需要進行哪些傳輸的邏輯。
Google 與 PyTorch 合作,最近釋出了一個基於 DCP 的本地檢查點解決方案。當前的解決方案利用了資料並行性,並在載入期間處理複製邏輯。未來的工作還將實現在儲存期間的複製。此本地檢查點解決方案可在 Google Cloud 的容錯庫中找到,並已整合到多個經過吞吐量最佳化的訓練方案中。
檢查點最佳化對吞吐量的影響
讓我們利用檢查點不良吞吐量的公式,將所有這些最佳化重新置於訓練吞吐量的視角。為了計算不良吞吐量,我們測量了檢查點造成的開銷、儲存檢查點的總時間以及載入檢查點的時間。以下結果是在 54 臺Google Cloud A3Ultra VM(432 塊 NVIDIA H200 SXM GPU)上使用 Llama 3 405B 獲得的。
| 使用 GCS 作為持久儲存的基線非同步檢查點 | 上一欄 + DCP 計劃 + 元資料快取 | 上一欄 + 基於專用程序的檢查點 + 固定記憶體 | 上一欄 + 本地檢查點 | |
| 檢查點開銷(不包括第一個檢查點) | 18.5秒 | 5.5秒 | 1.5秒 | 2.3秒 |
| 儲存檢查點的總時間(不包括第一個檢查點) | 約126秒 | 約135秒 | 約135秒 | 約47秒 |
| 載入檢查點的時間 | 94秒 | 94秒 | 94秒 | 80秒 |
結果表明,DCP 最佳化顯著將檢查點開銷降至接近零。正如預期,本地檢查點顯著縮短了儲存和載入檢查點的時間。由於決定排除檢查點去重邏輯,本地檢查點時的檢查點開銷略高。這導致每個節點向儲存寫入更大的檔案。未來的工作旨在在使用本地檢查點時減少檢查點檔案大小。
根據上表中的測量結果,我們可以透過附錄中的推導來確定最佳檢查點頻率,並計算檢查點造成的總不良吞吐量。
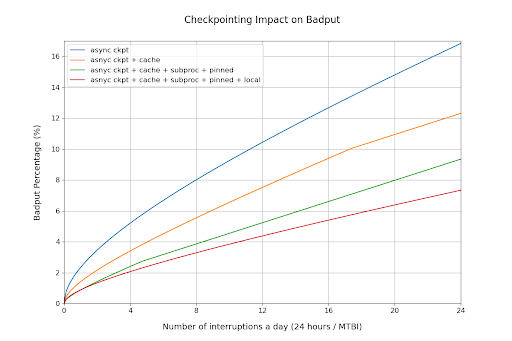
圖8:檢查點對不良吞吐量的影響
該圖顯示,隨著中斷變得更頻繁,每次檢查點最佳化對訓練吞吐量的影響也變得更顯著。在故障每小時發生一次的最極端情況下,這些檢查點最佳化可以將不良吞吐量降低9個百分點。
這些結果強調,最佳化的檢查點解決方案對於處理頻繁中斷的大規模訓練作業至關重要。
如何在 DCP 中啟用這些最佳化?
這些功能已作為 PyTorch 每夜構建的一部分提供,您可以直接在TorchTitan中測試 PyTorch 的非同步 DCP 檢查點。以下是啟用這些功能的說明:
- 基於程序的非同步檢查點:
- 在async_save API 中將async_checkpointer_type 設定為 AsyncCheckpointerType.PROCESS。(檔案:pytorch/torch/distributed/checkpoint/state_dict_saver.py)
- 儲存計劃快取:
- 在DefaultSavePlanner中將enable_plan_caching 標誌設定為 true。(檔案:pytorch/torch/distributed/checkpoint/default_planner.py)
- 啟用基於固定記憶體的暫存
- 在StagingOptions中建立暫存器,並將use_pinned_memory 標誌設定為 true。(檔案:https://github.com/pytorch/pytorch/blob/main/torch/distributed/checkpoint/staging.py)
- 在叢集本地檢查點中: https://github.com/AI-Hypercomputer/resiliency
附錄
採用檢查點不良吞吐量的公式,最佳檢查點間隔可以推導如下:

其中 定義為