要點速覽
NJT(巢狀不規則張量)將 DRAMA 模型的推理效率提升了 1.7 倍-2.3 倍,使其在基於 LLM 的編碼器類別中更具生產就緒性,尤其是在處理可變長度序列時。
引言和背景
基於大型語言模型 (LLM) 的編碼器最近的進展顯示出可喜的成果,許多模型在評估排行榜上名列前茅。然而,挑戰在於將這些複雜的模型投入生產,這通常需要大量的計算資源和基礎設施。
為了解決最佳化 LLaMA 編碼器的挑戰,我們選擇探索 DRAMA,這是一種利用裁剪 LLaMA 主幹的密集檢索模型。DRAMA 模型在各種版本(包括基礎版(0.1B)、大型版(0.3B)和 1B 版)中總體表現良好。具體而言,DRAMA-base 以其在英語和多語言檢索任務中的出色表現脫穎而出,儘管其尺寸緊湊,只有 0.1B 非嵌入引數。其質量使其成為客戶的一個有吸引力的選擇。然而,與其實現相關的高成本阻礙了其廣泛採用。為了解決這一挑戰,我們探索使用巢狀張量進一步最佳化模型,使其成為生產環境的可行解決方案。
透過利用巢狀張量,我們觀察到DRAMA模型的推理效率大幅提高,效率提升了 1.7 到 2.3 倍。這一突破對於在實際應用中部署基於 LLM 的編碼器具有重要意義。
什麼是 NJT
torchtune 中的樣本打包、TensorFlow 中的不規則張量、ModernBert 中的去填充以及Pytorch 中的巢狀張量都解決了可變長度序列資料的挑戰,但方法不同。雖然所有方法都旨在簡化序列建模,但它們的抽象和效能影響因框架和用例而異。
PyTorch 的巢狀張量是 Python 張量的一個子類,它透過高效的打包內部表示提供了一個統一的介面來處理不規則形狀的資料。
PyTorch 中有兩種型別的巢狀張量,透過它們的構造佈局來區分:`torch.strided` 或 `torch.jagged`。建議使用 Jagged 佈局的巢狀張量 (NJT),這也是本部落格關注的重點。值得注意的是,由於完全用 Python 實現,NJT 會產生一定的即時開銷,在較小的輸入尺寸上更為明顯。建議在可能的情況下編譯 NJT,以消除此開銷並從運算子融合中獲得性能提升。
NJT 張量可以透過將張量列表傳遞給 `torch.nested.nested_tensor` 並帶有 `layout=torch.jagged` 引數來建立。這將輸入複製到打包的、連續的記憶體塊中。NJT 目前支援單個不規則維度。
當模型部署通常對具有不同長度的大批次序列執行推理時,巢狀張量會從中受益。鑑於這種查詢模式,使用常規張量進行推理需要批次中的所有序列都填充到相同的長度,當批次由許多短序列和一個長序列組成時,這尤其浪費。相比之下,巢狀張量透過原生支援對不同序列長度的批次進行操作,從而避免在這些額外的填充標記上浪費計算。
密集與不規則
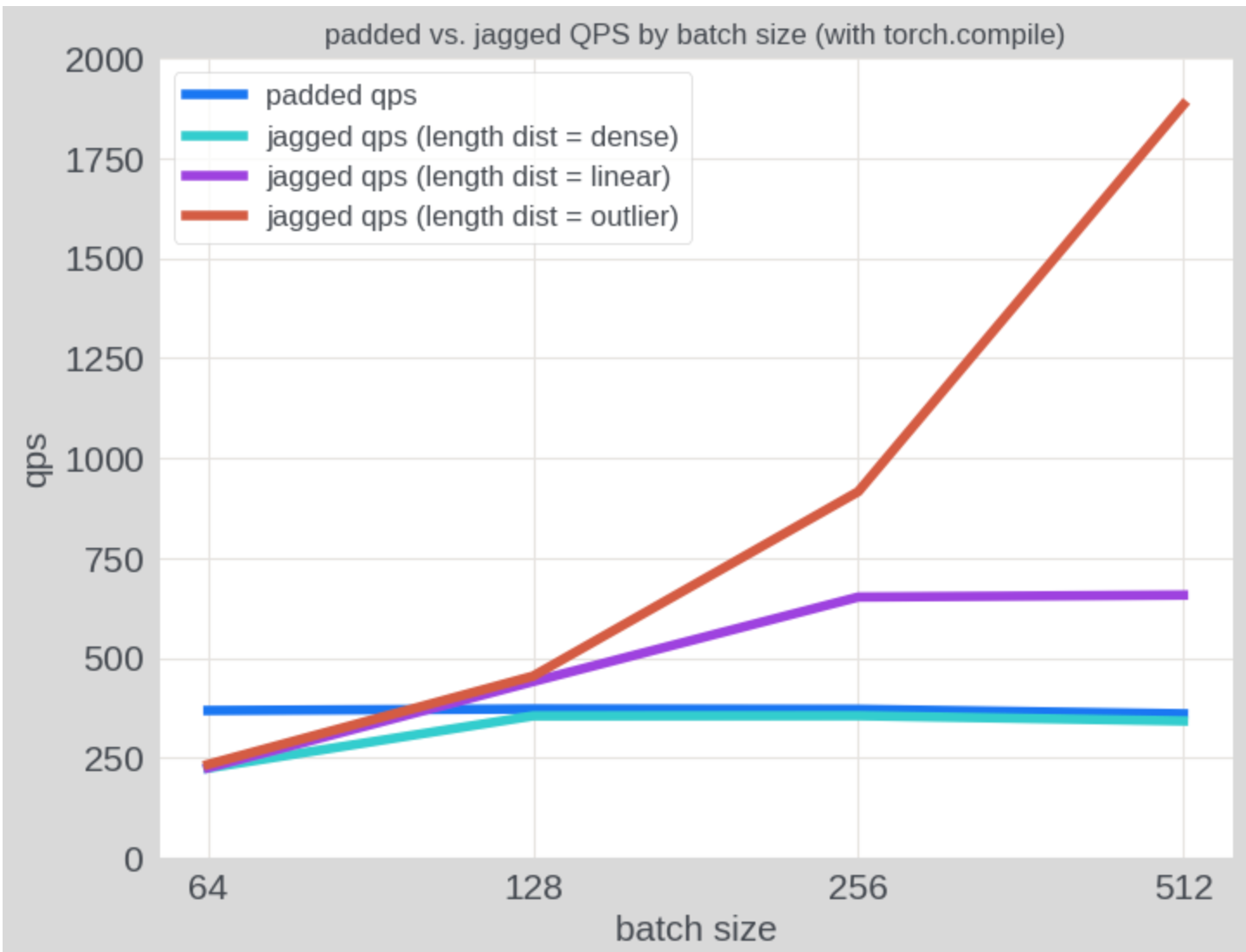
正如預期的那樣,與填充張量相比,NJT 在具有不均勻序列長度的輸入上表現出顯著更高的吞吐量。在下圖中,我們使用各種序列長度模式的合成數據評估了 QPS:(1) “密集”批次,其中每個序列的長度為 256;(2) “線性”批次,其中批次中的序列長度從 1 線性增加到 256;以及 (3) “異常值”批次,其中一個序列的長度為 256,其餘序列的長度為 1。在使用填充張量時,所有三種情況的推理成本保持不變,而使用 NJT 時,推理成本隨著批次稀疏性的增加而降低。在“線性”分佈上,NJT 的效能優於填充張量約 1.85 倍。
實現
為了將 NJT 應用於 LLaMa 模型,需要進行以下程式碼修改。主要集中在兩個關鍵元件:轉換和注意力。
轉換
將 token id 轉換為不規則 token id,並將 attention mask 設定為 none,因為不需要 mask,因為沒有填充。
jagged_input_ids = torch.nested.nested_tensor( tokenizer_output.input_ids, layout=torch.jagged ) attention_mask = None
LlamaSdpaAttention
- Llama 3 引入了分組查詢注意力 (GQA),其特點是注意力頭多於鍵值頭(
num_attention_heads > num_key_value_heads)。為了確保注意力過程中的相容性,repeat_kv函式發揮了關鍵作用——其主要任務是有效地在查詢頭之間複製鍵值頭。此操作將張量從(batch, num_key_value_heads, seqlen, head_dim) 重塑為 (batch, num_attention_heads, seqlen, head_dim)。
為了更好地處理不規則和密集張量格式,原始的repeat_kv函式已分為兩個專門的函式:
-
-
-
- repeat_dense_kv:用於密集張量,此函式與原始 repeat_kv 相同。
- repeat_jagged_kv:專為不規則張量設計,帶有
ragged_idx索引,增加了複雜性。此方法利用一系列轉置和展平操作。透過在展平之前臨時更改維度順序,然後轉置回來,它有效地解決了不規則張量帶來的獨特挑戰。
-
-
def repeat_jagged_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor: """ This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch, num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim) """
batch, num_key_value_heads, slen, head_dim = hidden_states.shape expand_shape = (batch, num_key_value_heads, -1, n_rep, head_dim) if n_rep == 1: return hidden_states hidden_states = ( hidden_states.unsqueeze(3) .expand(expand_shape) .transpose(1, 2) .flatten(2, 3) .transpose(1, 2) ) return hidden_states
def repeat_dense_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor: """ This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch, num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim) """ batch, num_key_value_heads, slen, head_dim = hidden_states.shape if n_rep == 1: return hidden_states hidden_states = hidden_states[:, :, None, :, :].expand( batch, num_key_value_heads, n_rep, slen, head_dim ) return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
2. 當將旋轉位置嵌入 (RoPE) 應用於查詢和鍵張量時,我們需要處理兩種不同的張量格式:不規則和密集。為了適應這一點,我們實現了兩個獨立的函式,每個函式都針對特定的張量型別量身定製。主函式apply_rotary_pos_emb()充當路由器,根據張量是否巢狀將輸入定向到_jagged_tensor_forward或
_dense_tensor_forward
對於不規則張量,該過程涉及三個關鍵步驟:首先,使用q.to_padded_tensor(0.0)將不規則張量轉換為密集張量;其次,在此密集表示上應用旋轉位置嵌入;最後,使用
_dense_to_jagged
def apply_rotary_pos_emb( q: torch.Tensor, k: torch.Tensor, cos: torch.Tensor, sin: torch.Tensor, unsqueeze_dim: int = 1, ) -> Tuple[torch.Tensor, torch.Tensor]: cos = cos.unsqueeze(unsqueeze_dim) sin = sin.unsqueeze(unsqueeze_dim) if q.is_nested and k.is_nested: if q.layout != torch.jagged: raise NotImplementedError(f"Unsupported layout: {q.layout}") if k.layout != torch.jagged: raise NotImplementedError(f"Unsupported layout: {k.layout}") return _jagged_tensor_forward(q, k, cos, sin) else: return _dense_tensor_forward(q, k, cos, sin)
def _jagged_tensor_forward( q: torch.Tensor, k: torch.Tensor, cos: torch.Tensor, sin: torch.Tensor, ) -> Tuple[torch.Tensor, torch.Tensor]: q_dense = q.to_padded_tensor(0.0) k_dense = k.to_padded_tensor(0.0) q_dense_embed = (q_dense * cos) + (rotate_half(q_dense) * sin) k_dense_embed = (k_dense * cos) + (rotate_half(k_dense) * sin) q_jagged_embed = convert_dense_to_jagged(q, q_dense_embed) k_jagged_embed = convert_dense_to_jagged(k, k_dense_embed) return q_jagged_embed, k_jagged_embed def _dense_tensor_forward( q: torch.Tensor, k: torch.Tensor, cos: torch.Tensor, sin: torch.Tensor, ) -> Tuple[torch.Tensor, torch.Tensor]: q_embed = (q * cos) + (rotate_half(q) * sin) k_embed = (k * cos) + (rotate_half(k) * sin) return q_embed, k_embed def convert_dense_to_jagged(nested_q: torch.Tensor, q: torch.Tensor) -> torch.Tensor: padded_max_S = nested_q._get_max_seqlen()
total_L = nested_q._values.shape[nested_q._ragged_idx - 1] if padded_max_S is None: # use upper bound on max seqlen if it's not present padded_max_S = total_L # convert dense tensor -> jagged q = q.expand( [ x if i != nested_q._ragged_idx else padded_max_S for i, x in enumerate(q.shape) ] ) nested_result = nested_from_padded( q, offsets=nested_q._offsets, ragged_idx=nested_q._ragged_idx, sum_S=total_L, min_seqlen=nested_q._get_min_seqlen(), max_seqlen=padded_max_S, ) return nested_result
增加了帶有 NJT 的 Drama 模型實現:modeling_drama_nested.py
致謝
我們感謝 Xilun Chen 在程式碼審查中提供的有益反饋。並感謝 Don Husa、Jeffrey Wan、Joel Schlosser 和 Fernando Hernandez 對部落格的有益反饋。
結論
使用 NJT 的這項最佳化顯著提高了 DRAMA(基於 LLaMa 的編碼器)的效率,使其在實際部署中更具實用性。透過減少計算開銷,尤其是對於可變長度序列,這種方法為高效能基於 LLM 的編碼器在生產環境中的廣泛採用鋪平了道路。然而,NJT 在 PyTorch 中已是功能完備,目前沒有積極新增新功能,但歡迎社群貢獻。