PyTorch 2.0 編譯的挑戰
自 PyTorch 2.0 (PT2) 及其強大的新編譯基礎設施釋出以來,研究人員和工程師們受益於模型執行速度和執行時效率的顯著提高。然而,這些收益也伴隨著代價:初始編譯可能會成為一個顯著的瓶頸,特別是對於像 Meta 內部用於推薦的大型複雜模型而言。
瞭解編譯瓶頸
PT2 引入了一個編譯步驟,在執行之前將 Python 模型程式碼轉換為高效能機器程式碼。
雖然結果是更快的訓練和推理,但編譯非常大型的模型可能需要長達一個小時或更長時間,尤其是在冷啟動時,對於我們一些具有 Transformer 之外複雜模型架構的內部推薦模型而言。
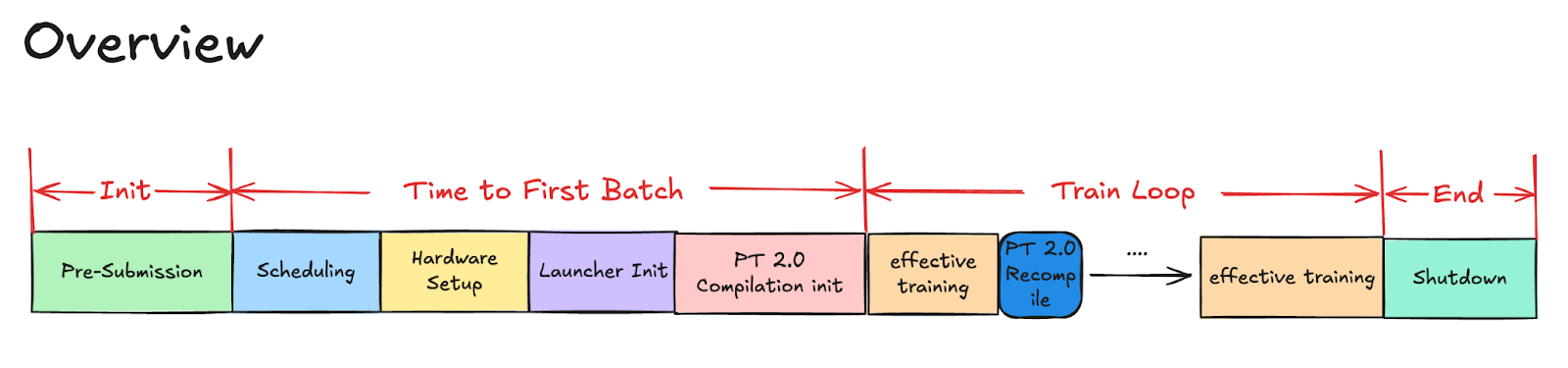
圖 1. 訓練概述
2024 年末,我們啟動了一項重點計劃,旨在分解和縮短我們最大的基礎模型之一的 PT2 編譯時間。我們首先執行一項全面的、長時間的編譯任務,對 PT2 編譯過程進行詳細分析。
Tlparse
Tlparse 解析結構化的 Torch 跟蹤日誌並輸出分析資料的 HTML 檔案。這使我們能夠識別編譯各個階段的瓶頸。
使用設定了 TORCH_TRACE 環境變數的 PyTorch 執行
TORCH_TRACE=/tmp/my_traced_log_dir example.py
|
將輸入饋送到 tlparse
tlparse /tmp/my_traced_log_dir -o tl_out/ |
結果將日誌組織成幾個易於理解的部分,突出顯示每次分析重新啟動的時間、任何圖中斷等。它還提供跟蹤檔案,幫助您詳細分析執行和效能。
如果您需要更多資訊來執行 Tlpase,可以參考這些步驟。
示例結果:
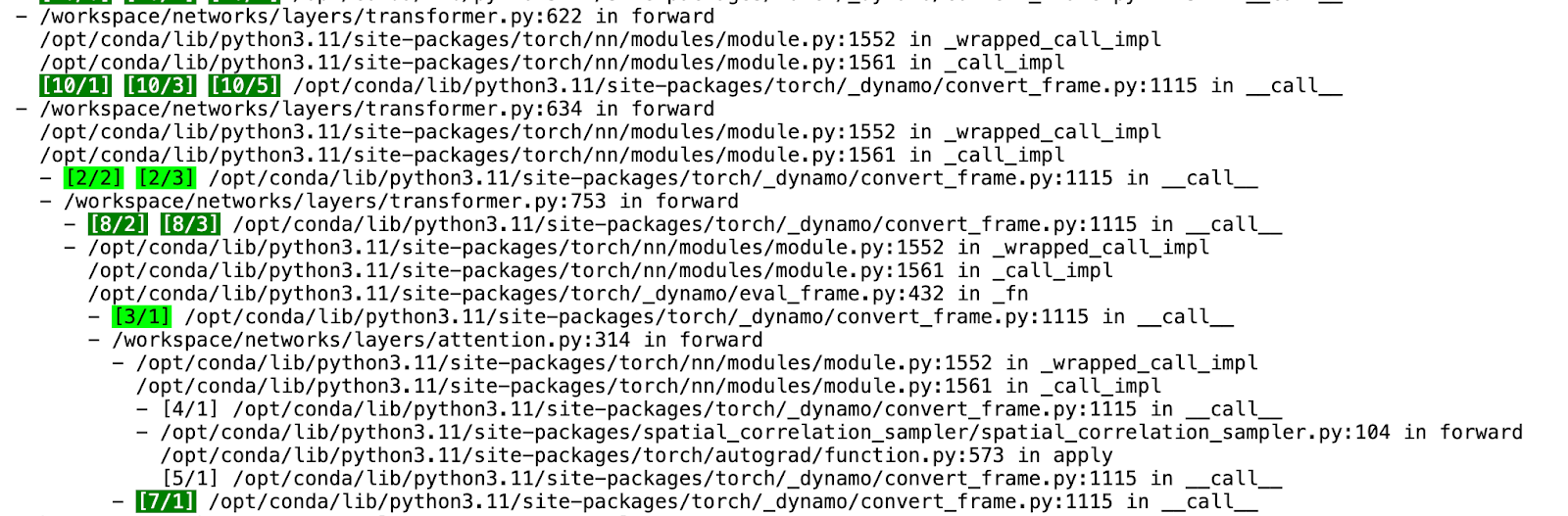
圖 2. PT2 編譯 HTML
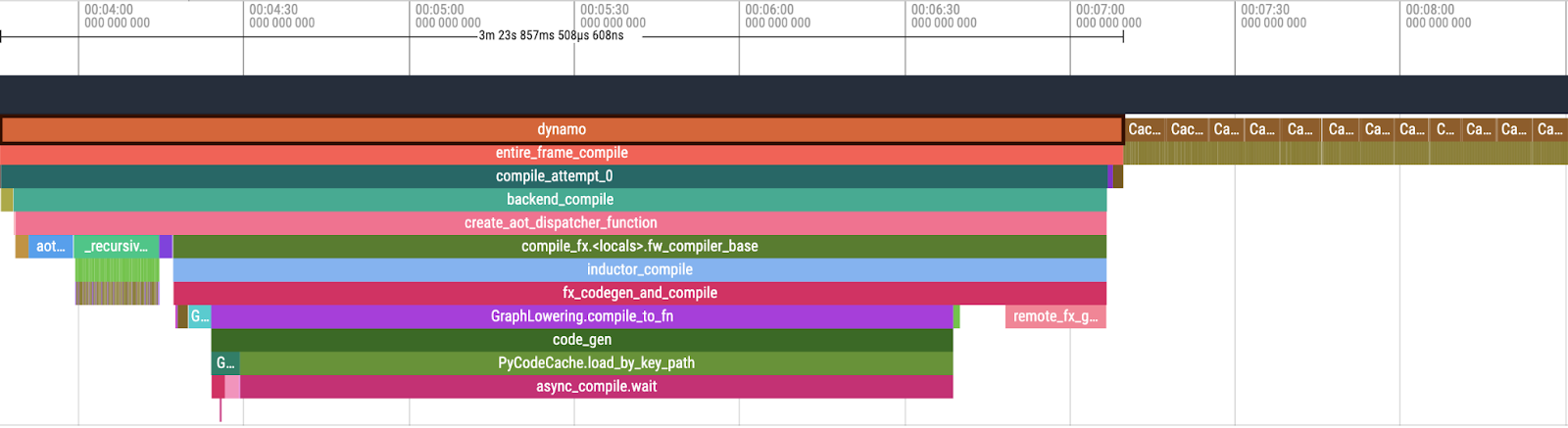
圖 3. Perfetto UI 中 PT2 編譯概述
在檢查 Tlparse 的輸出時,我們關注 PT2 編譯堆疊的以下關鍵元件:
- Dynamo:負責動態圖轉換和最佳化的初始階段。
- AOTInductor (AOTDispatch):將 PyTorch 的自動梯度引擎過載為跟蹤自動微分,以生成提前反向跟蹤。
- TorchInductor:一種深度學習編譯器,可為多個加速器和後端生成快速程式碼。對於 NVIDIA 和 AMD GPU,它使用OpenAI Triton 作為關鍵構建塊。
在此分析之後,我們系統地解決了每個瓶頸區域,並進行了有針對性的改進,以減少整體編譯時間。
| 階段 | 時間(獨佔,秒) |
| 總計 | 1825.58 |
| Dynamo | 100.64 (5.5%) |
| AOTDispatch | 248.03 (13.5%) |
| TorchInductor | 1238.50 (67.8%)
大部分是 async_compile.wait (843.95) |
| CachingAutotuner.benchmark_all_configs | 238.00 (13.0%) |
| 剩餘 (inductor) | 0.41 (0%) |
縮短 PT2 編譯時間的關鍵重點領域
根據對基線編譯作業的分析,我們確定了幾個關鍵領域,以期縮短整體編譯時間,尤其是對於冷啟動:
- 識別並最佳化最耗時的區域,以最大程度地減少編譯次數。
- 增強async_compile.wait 過程,以加速 Triton 編譯。
- 有效修剪Triton 自動調優配置,特別是使用者定義的核心配置,以減少編譯時間和基準測試時間。
- 提高整體PT2 快取效能並提高下游作業的快取命中率。
技術深入探討
在過去一年中,我們與 Meta 的多個團隊合作,開發並實施了幾項旨在減少 PT2 編譯時間的新技術。以下是我們應用於基礎模型的關鍵技術概述。
1. 透過 Triton 編譯實現最大並行度
此最佳化包括兩項關鍵改進:避免在父程序中進行 Triton 編譯,以及透過在工作程序中呼叫 Triton 並使用未來快取來更早地啟動 Triton 編譯,以增加編譯過程的並行度。
具體而言,我們的並行編譯工作器現在編譯 Triton 核心並將編譯結果直接傳遞給父程序,消除了父程序中冗餘編譯的需要。這增強了並行性並減少了整體編譯時間。
2. 動態形狀標記
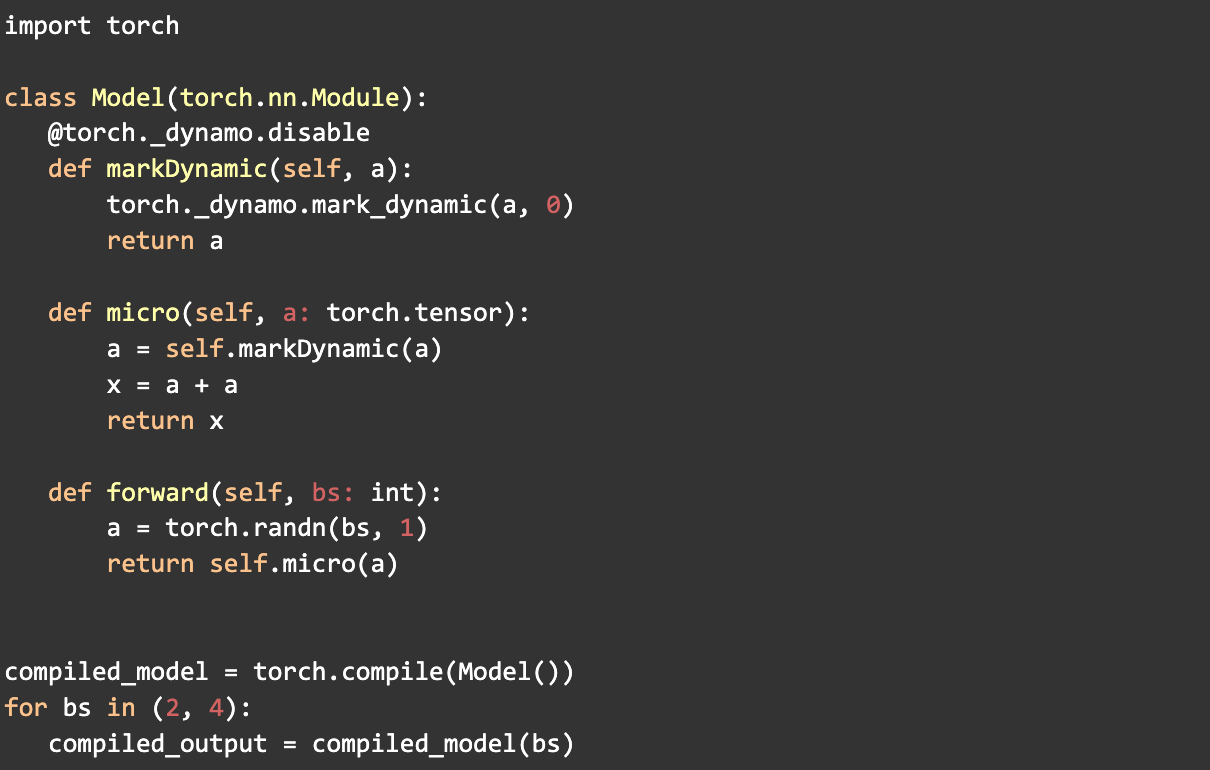
- mark_dynamic
使用 PyTorch 的mark_dynamic API 有助於在編譯前識別動態形狀。由於許多重新編譯發生在編譯期間張量形狀發生變化時,將這些形狀標記為動態可以顯著減少重新編譯的次數。這反過來又提高了整體 PT2 編譯時間。
此過程涉及將張量標記為動態並單獨處理專門化。最初,確定專門化以及如何最好地將它們標記為動態具有挑戰性,需要大量的實驗並且證明非常複雜。
在此過程中,我們開發了工具和技術來簡化 mark_dynamic 的使用,包括在 tlparse 中增強了動態資訊日誌記錄。
例子
- TORCH_COMPILE_DYNAMIC_SOURCES
動態源白名單 (TORCH_COMPILE_DYNAMIC_SOURCES) 的引入,透過提供一種簡單友好的方式來標記引數為動態而無需修改底層程式碼,改善了引數動態形狀的處理。此功能還支援將整數標記為動態,並允許使用正則表示式來包含更廣泛的引數,從而增強了靈活性並縮短了編譯時間。
例子

3. 自動調優配置剪枝
我們發現,應用於基礎模型的使用者核心和使用者定義配置的數量顯著影響 PT2 編譯。
因為 PT2 自動調優會自動對每個核心的許多可能的執行時配置進行基準測試,以找到最有效的配置,這在有許多核心和配置時可能非常耗時。
為了解決這個問題,我們開發了一個流程來識別最耗時的核心,並確定最佳的執行時配置以在程式碼庫中實現。這種方法顯著減少了編譯時間。
4. 提高快取命中率
配置檔案引導最佳化 (PGO) 會破壞快取,導致非確定性快取鍵,從而導致快取未命中並導致編譯時間過長。
無 PGO

有 PGO

為解決此問題,團隊實現了雜湊函式以生成一致的符號 ID 以進行穩定分配,並使用線性探測以避免符號衝突 (詳情)。
這一改變顯著提高了作業內部暖執行和使用遠端快取的不同作業的快取命中率。
5. 最佳化核心啟動
常規 Triton 核心由於需要在編譯時進行 C++ 程式碼生成而具有較高的啟動成本,並且在廣告模型上的快取命中率較低。StaticCudaLauncher 是 PyTorch 用於 Triton 生成的 CUDA 核心的新啟動器,我們將其用作所有 Triton 核心的預設啟動器。這使得冷啟動和熱啟動的編譯時間都更快。
6. 巨型快取
MegaCache 將多種 PT2 編譯快取型別整合在一起——包括 Inductor(核心 PT2 編譯器)、Triton bundler(用於 GPU 程式碼)、AOT Autograd(用於高效梯度計算)、Dynamo PGO(配置檔案引導最佳化)和自動調優設定等元件——形成一個可以輕鬆下載和共享的單一存檔。
透過整合這些元素,MegaCache 提供了以下改進:
- 最大程度地減少對遠端伺服器的重複請求
- 縮短模型設定時間
- 提高啟動和重試作業的可靠性,即使在分散式或雲環境中也是如此
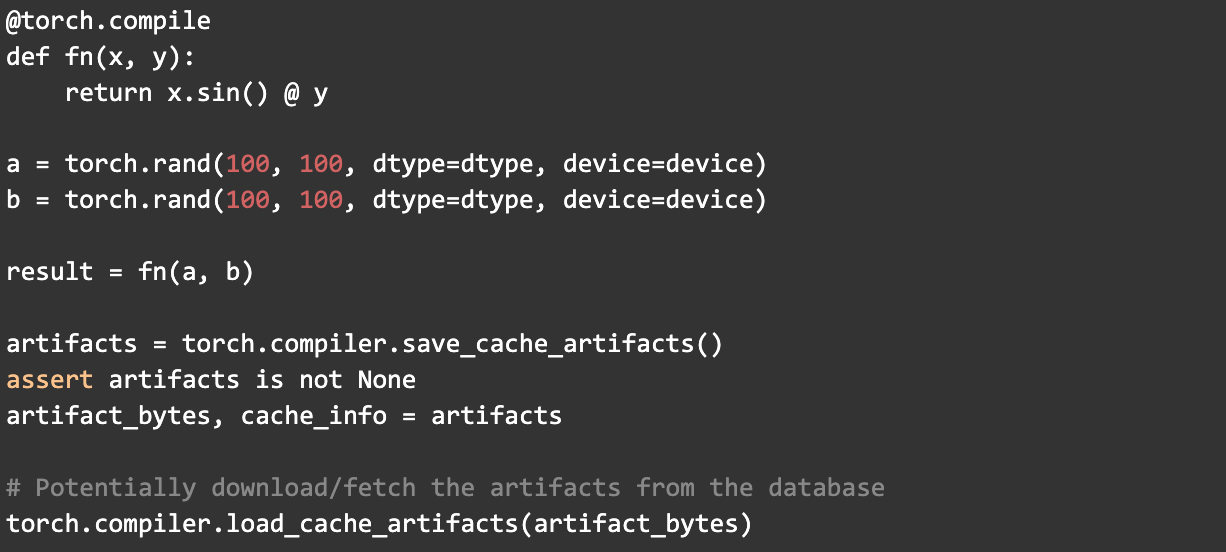
Mega-Cache 提供兩個編譯器 API
- torch.compiler.save_cache_artifacts()
- torch.compiler.load_cache_artifacts()
以此為例
成果與影響:編譯速度提高 80% 以上
得益於我們的最佳化工作,我們最大的基礎模型之一在離線訓練期間的編譯時間在過去一年中減少了 80% 以上,從大約 3000 秒縮短到不到 500 秒。
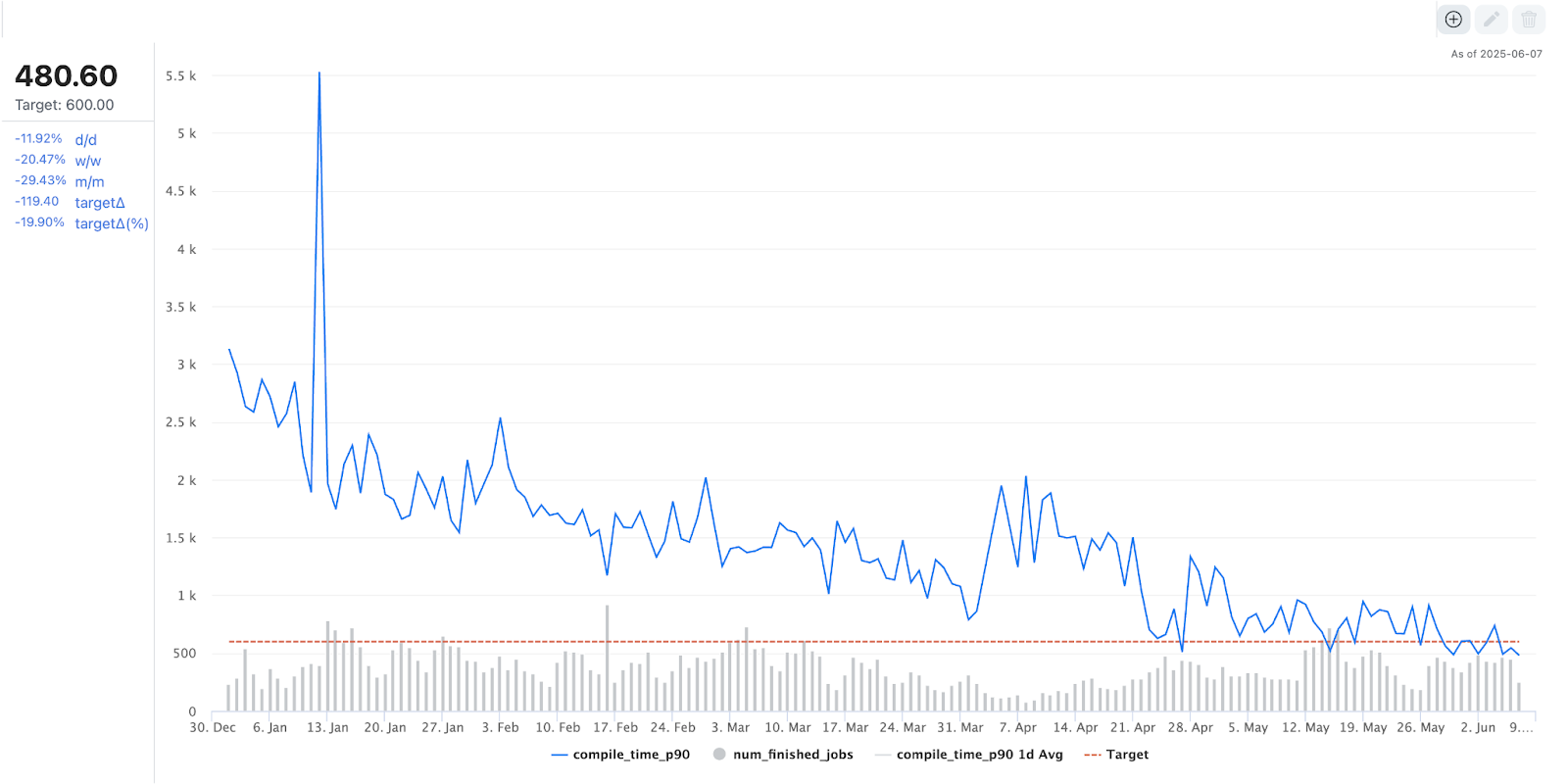
圖 4. PT2 編譯時間趨勢
結語
我們已將這些最佳化整合到 PT2 編譯器堆疊中,使其成為所有使用 PT2 編譯模型使用者的預設設定。我們通用的轉換方法旨在使 Meta 生態系統之外的各種模型受益,我們歡迎在現有工作的基礎上進行持續討論和改進。
致謝
非常感謝Max Leung、Musharaf Sultan、John Bocharov 和 Gregory Chanan 提供富有洞察力的支援和評審。