
理論上,“注意力”是你所需要的一切。然而在實踐中,我們還需要像 FlashAttention 這樣經過最佳化的注意力實現。
儘管這些融合的注意力實現大大提高了效能並支援了長上下文,但這種效率的提高也伴隨著靈活性的損失。你不能再透過編寫幾個 PyTorch 運算子來嘗試新的注意力變體了——你通常需要編寫一個新的自定義核心!這對於機器學習研究人員來說,就像是一種“軟體彩票”——如果你的注意力變體不適合現有的最佳化核心之一,你就註定會遭遇慢速執行時和 CUDA 記憶體溢位。
注意力變體的一些例子包括:因果注意力、相對位置編碼、Alibi、滑動視窗注意力、PrefixLM、文件掩碼/樣本打包/鋸齒形張量、Tanh 軟限幅、分頁注意力等。更糟糕的是,人們通常希望將這些變體組合起來!滑動視窗注意力 + 文件掩碼 + 因果注意力 + 上下文並行?或者分頁注意力 + 滑動視窗 + Tanh 軟限幅又如何?
下面左圖展示了當今世界的現狀——掩碼、偏置和設定的某些組合具有現有的核心實現。但各種選項導致了指數級的設定,因此總體而言,我們最終獲得了相當零星的支援。更糟糕的是,研究人員提出的新注意力變體將獲得*零*支援。
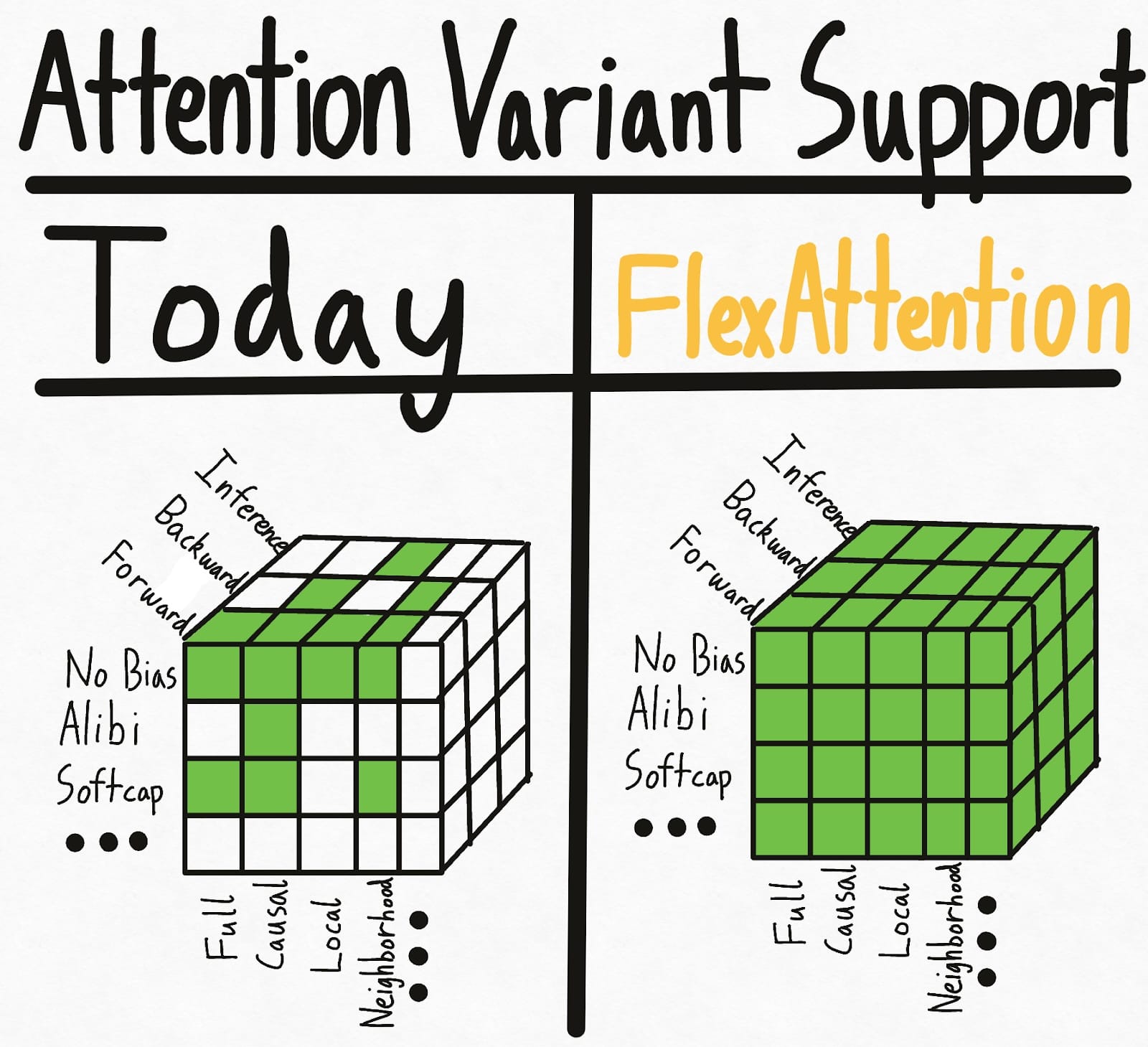
為了徹底解決這個超立方體問題,我們引入了**FlexAttention**,一個全新的 PyTorch API。
- 我們提供了一個靈活的 API,允許用幾行地道的 PyTorch 程式碼實現許多注意力變體(包括到目前為止部落格文章中提到的所有變體)。
- 我們透過 `torch.compile` 將其轉換為融合的 FlashAttention 核心,生成一個不例項化任何額外記憶體且效能與手寫核心相當的 FlashAttention 核心。
- 我們還利用 PyTorch 的自動求導機制自動生成反向傳播。
- 最後,我們還可以利用注意力掩碼中的稀疏性,從而相對於標準注意力實現獲得顯著改進。
有了 FlexAttention,我們希望嘗試新的注意力變體將只受限於你的想象力。
你可以在 Attention Gym 找到許多 FlexAttention 示例:https://github.com/pytorch-labs/attention-gym。如果你有任何很酷的應用,歡迎提交示例!
附註:我們還發現這個 API 非常令人興奮,因為它以一種有趣的方式利用了許多現有 PyTorch 基礎設施——更多內容將在最後介紹。
FlexAttention
這是經典的注意力方程
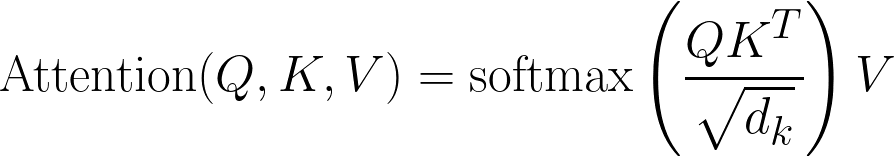
以程式碼形式
Q, K, V: Tensor[batch_size, num_heads, sequence_length, head_dim]
score: Tensor[batch_size, num_heads, sequence_length, sequence_length] = (Q @ K) / sqrt(head_dim)
probabilities = softmax(score, dim=-1)
output: Tensor[batch_size, num_heads, sequence_length, head_dim] = probabilities @ V
FlexAttention 允許使用者定義函式 `score_mod:`

以程式碼形式
Q, K, V: Tensor[batch_size, num_heads, sequence_length, head_dim]
score: Tensor[batch_size, num_heads, sequence_length, sequence_length] = (Q @ K) / sqrt(head_dim)
modified_scores: Tensor[batch_size, num_heads, sequence_length, sequence_length] = score_mod(score)
probabilities = softmax(modified_scores, dim=-1)
output: Tensor[batch_size, num_heads, sequence_length, head_dim] = probabilities @ V
這個函式允許你在 softmax 之前*修改*注意力分數。令人驚訝的是,這對於絕大多數注意力變體來說已經足夠了(示例如下)!
具體來說,`score_mod` 的預期簽名有些獨特。
def score_mod(score: f32[], b: i32[], h: i32[], q_idx: i32[], kv_idx: i32[])
return score # noop - standard attention
換句話說,`score` 是一個標量 PyTorch 張量,表示查詢 token 和鍵 token 的點積。其餘引數告訴您當前正在計算的是*哪個*點積——`b`(批次中的當前元素)、`h`(當前頭)、`q_idx`(查詢中的位置)、`kv_idx`(鍵/值張量中的位置)。
要應用此函式,我們可以將其實現為
for b in range(batch_size):
for h in range(num_heads):
for q_idx in range(sequence_length):
for kv_idx in range(sequence_length):
modified_scores[b, h, q_idx, kv_idx] = score_mod(scores[b, h, q_idx, kv_idx], b, h, q_idx, kv_idx)
當然,這不是 FlexAttention 在底層實現的。透過利用 `torch.compile`,我們自動將您的函式轉換為一個*融合的* FlexAttention 核心——保證有效,否則退款!
這個 API 最終表現出驚人的表現力。讓我們看一些例子。
分數修改示例
完全注意力
首先,我們來實現“完全注意力”,即標準的雙向注意力。在這種情況下,`score_mod` 是一個無操作——它接收分數作為輸入,然後原樣返回。
def noop(score, b, h, q_idx, kv_idx):
return score
並端到端使用它(包括前向*和*後向)
from torch.nn.attention.flex_attention import flex_attention
flex_attention(query, key, value, score_mod=noop).sum().backward()
相對位置編碼
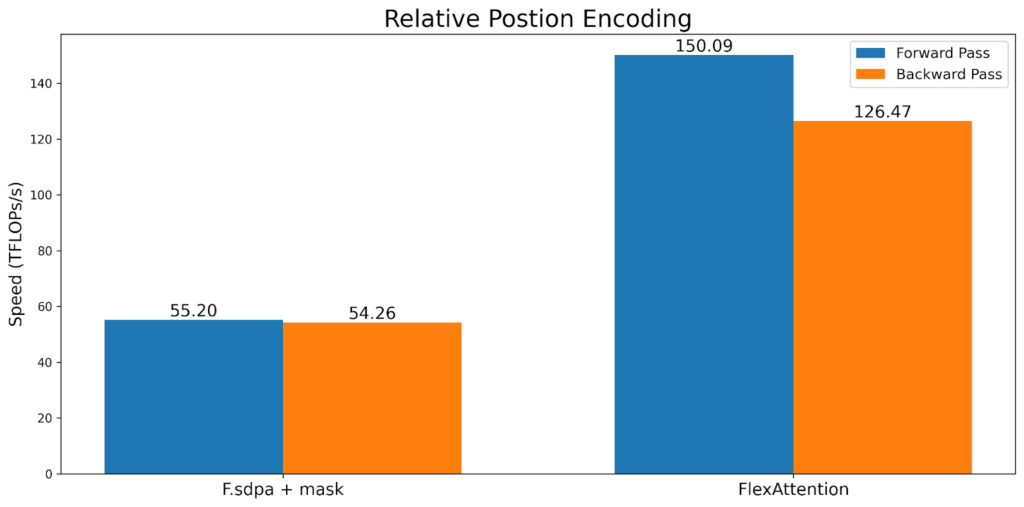
一種常見的注意力變體是“相對位置編碼”。相對位置編碼不是在查詢和鍵中編碼絕對距離,而是根據查詢和鍵之間的“距離”調整分數。
def relative_positional(score, b, h, q_idx, kv_idx):
return score + (q_idx - kv_idx)
請注意,與典型的實現不同,這*不需要*例項化 SxS 張量。相反,FlexAttention 在核心內部“即時”計算偏差值,從而顯著改善記憶體和效能。
ALiBi 偏差
來源:Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
ALiBi 在 Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation 中被引入,並聲稱在推理時具有對長度外推有益的特性。值得注意的是,MosaicML 指出 “缺乏核心支援” 是他們最終從 ALiBi 轉向旋轉嵌入的主要原因。
Alibi 與相對位置編碼相似,只有一個例外——它有一個通常預先計算的每個頭因子。
alibi_bias = generate_alibi_bias() # [num_heads]
def alibi(score, b, h, q_idx, kv_idx):
bias = alibi_bias[h] * (kv_idx - q_idx)
return score + bias
這展示了 `torch.compile` 提供的一個有趣的靈活性——我們可以從 `alibi_bias` 載入,即使它*沒有作為輸入明確傳遞*!生成的 Triton 核心將計算從 `alibi_bias` 張量中進行的正確載入並進行融合。請注意,即使您重新生成 `alibi_bias`,我們也不需要重新編譯。
軟限幅
軟限幅是 Gemma2 和 Grok-1 中使用的一種技術,可防止 logits 過度增長。在 FlexAttention 中,它看起來像這樣
softcap = 20
def soft_cap(score, b, h, q_idx, kv_idx):
score = score / softcap
score = torch.tanh(score)
score = score * softcap
return score
請注意,我們還會自動從前向傳播生成反向傳播。此外,儘管此實現從語義上是正確的,但出於效能原因,在這種情況下我們可能希望使用 tanh 近似。有關更多詳細資訊,請參閱 attention-gym。
因果掩碼
儘管雙向注意力是最簡單的,但最初的*《Attention is All You Need》*論文和絕大多數 LLM 都採用解碼器專用設定中的注意力,其中每個 token 只能關注其之前的 token。人們通常將其視為下三角掩碼,但使用 `score_mod` API,它可以表示為
def causal_mask(score, b, h, q_idx, kv_idx):
return torch.where(q_idx >= kv_idx, score, -float("inf"))
基本上,如果查詢 token 在鍵 token “之後”,我們就保留分數。否則,我們透過將其設定為 -inf 來將其遮蔽掉,從而確保它不會參與 softmax 計算。
然而,掩碼與其他修改相比是特殊的——如果某個東西被遮蔽掉了,我們就可以完全跳過它的計算!在這種情況下,因果掩碼大約有 50% 的稀疏性,因此不利用稀疏性會導致 2 倍的減速。儘管這個 `score_mod` 足以*正確地*實現因果掩碼,但要獲得稀疏性帶來的效能優勢需要另一個概念——`mask_mod`。
掩碼模組
為了利用掩碼的稀疏性,我們需要做更多的工作。具體來說,透過將 `mask_mod` 傳遞給 `create_block_mask`,我們可以建立一個 `BlockMask`。然後 FlexAttention 可以使用 `BlockMask` 來利用稀疏性!
mask_mod 的簽名與 score_mod 非常相似——只是沒有 score。特別是
# returns True if this position should participate in the computation
mask_mod(b, h, q_idx, kv_idx) => bool
請注意,`score_mod` 比 `mask_mod` 嚴格來說*更具*表現力。然而,對於掩碼,建議使用 `mask_mod` 和 `create_block_mask`,因為它效能更高。請參閱 FAQ 瞭解為什麼 `score_mod` 和 `mask_mod` 是分開的。
現在,讓我們看看如何使用 `mask_mod` 實現因果掩碼。
因果掩碼
from torch.nn.attention.flex_attention import create_block_mask
def causal(b, h, q_idx, kv_idx):
return q_idx >= kv_idx
# Because the sparsity pattern is independent of batch and heads, we'll set them to None (which broadcasts them)
block_mask = create_block_mask(causal, B=None, H=None, Q_LEN=1024, KV_LEN=1024)
# In this case, we don't need a score_mod, so we won't pass any in.
# However, score_mod can still be combined with block_mask if you need the additional flexibility.
flex_attention(query, key, value, block_mask=block_mask)
請注意,`create_block_mask` 是一個**相對昂貴的操作!** 儘管 FlexAttention 在它改變時不需要重新編譯,但如果您不小心快取它,它可能會導致顯著的減速(請檢視 FAQ 以獲取最佳實踐建議)。
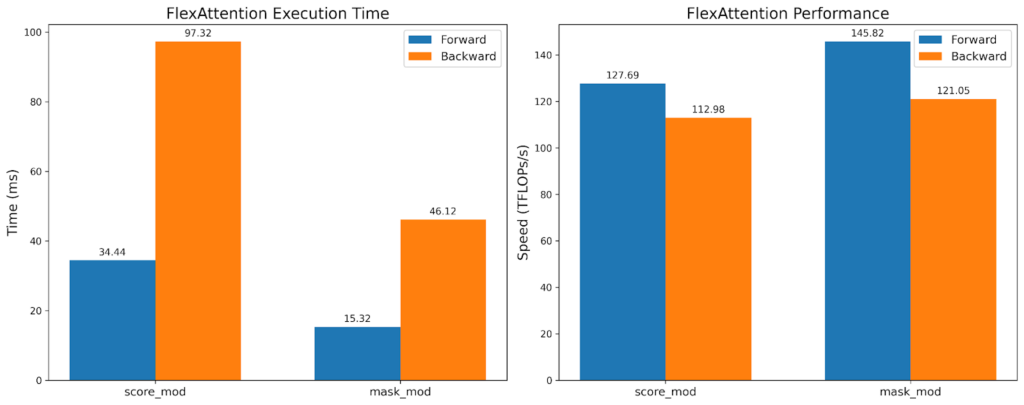
雖然 TFlops 大致相同,但 mask_mod 版本的執行時間快了 2 倍!這表明我們可以利用 BlockMask 提供的稀疏性,而*不*損失硬體效率。
滑動視窗 + 因果
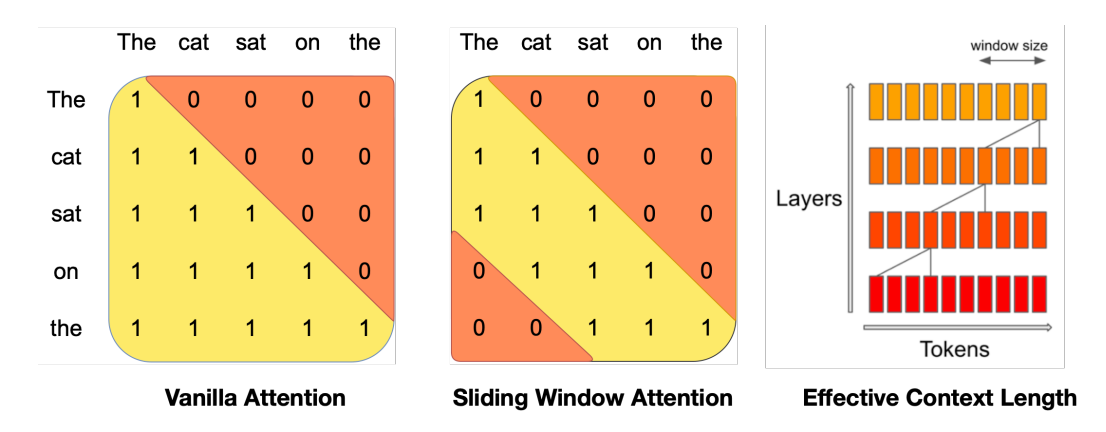
來源:Mistral 7B
由 Mistral 推廣,滑動視窗注意力(也稱為區域性注意力)利用了最近的 token 最有用的直覺。特別是,它允許查詢 token 只關注例如最近的 1024 個 token。這通常與因果注意力一起使用。
SLIDING_WINDOW = 1024
def sliding_window_causal(b, h, q_idx, kv_idx):
causal_mask = q_idx >= kv_idx
window_mask = q_idx - kv_idx <= SLIDING_WINDOW
return causal_mask & window_mask
# If you want to be cute...
from torch.nn.attention import and_masks
def sliding_window(b, h, q_idx, kv_idx)
return q_idx - kv_idx <= SLIDING_WINDOW
sliding_window_causal = and_masks(causal_mask, sliding_window)
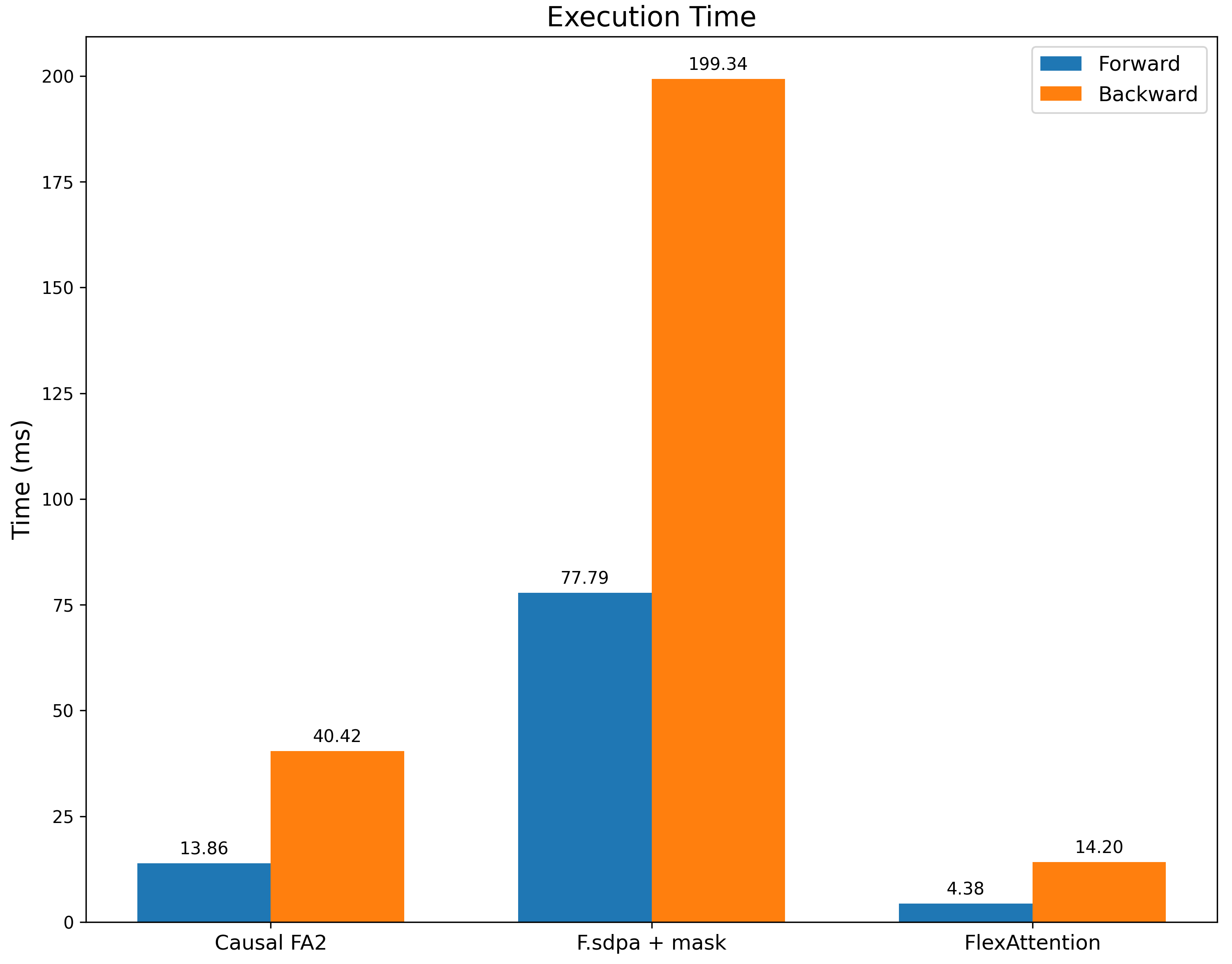
我們將其與帶有滑動視窗掩碼的 `F.scaled_dot_product_attention` 以及帶有因果掩碼的 FA2(作為效能參考點)進行基準測試。我們不僅比 `F.scaled_dot_product_attention` 快得多,我們*也*比帶有因果掩碼的 FA2 快得多,因為這個掩碼具有顯著更多的稀疏性。
PrefixLM
來源:PaliGemma: A versatile 3B VLM for transfer
在《探索統一文字到文字轉換器的遷移學習極限》中提出的 T5 架構描述了一種注意力變體,它在“字首”上執行完全雙向注意力,在其餘部分執行因果注意力。我們再次組合兩個掩碼函式來完成此操作,一個用於因果掩碼,另一個基於字首長度。
prefix_length: [B]
def prefix_mask(b, h, q_idx, kv_idx):
return kv_idx <= prefix_length[b]
prefix_lm_causal = or_masks(prefix_mask, causal_mask)
# In this case, our mask is different per sequence so we set B equal to our batch size
block_mask = create_block_mask(prefix_lm_causal, B=B, H=None, S, S)
就像 `score_mod` 一樣,`mask_mod` 允許我們引用未明確作為函式輸入的額外張量!然而,對於 prefixLM,稀疏模式是*每個輸入*都會改變。這意味著對於每個新的輸入批次,我們都需要重新計算 `BlockMask`。一種常見的模式是在模型開頭呼叫 `create_block_mask` 並將該 `block_mask` 重用於模型中的所有注意力呼叫。請參閱*重新計算 BlockMasks 與重新編譯*。
然而,作為回報,我們不僅能夠為 prefixLM 提供高效的注意力核心,我們還能夠利用輸入中存在的任意稀疏性!FlexAttention 將根據 BlockMask 資料動態調整其效能,而*無需*重新編譯核心。
文件掩碼/鋸齒序列
另一種常見的注意力變體是文件掩碼/鋸齒序列。想象一下您有許多長度不等的序列。您想將它們一起訓練,但不幸的是,大多數運算子只接受矩形張量。
透過 `BlockMask`,我們也可以在 FlexAttention 中高效地支援它!
- 首先,我們將所有序列展平為單個序列,包含 sum(序列長度) 個 token。
- 然後,我們計算每個 token 所屬的 document_id。
- 最後,在我們的 `mask_mod` 中,我們簡單地判斷查詢和鍵值 token 是否屬於同一個文件!
# The document that each token belongs to.
# e.g. [0, 0, 0, 1, 1, 2, 2, 2, 2, 2, 2] corresponds to sequence lengths 3, 2, and 6.
document_id: [SEQ_LEN]
def document_masking(b, h, q_idx, kv_idx):
return document_id[q_idx] == document_id[kv_idx]
就這樣!在這種情況下,我們看到我們最終得到一個塊對角掩碼。
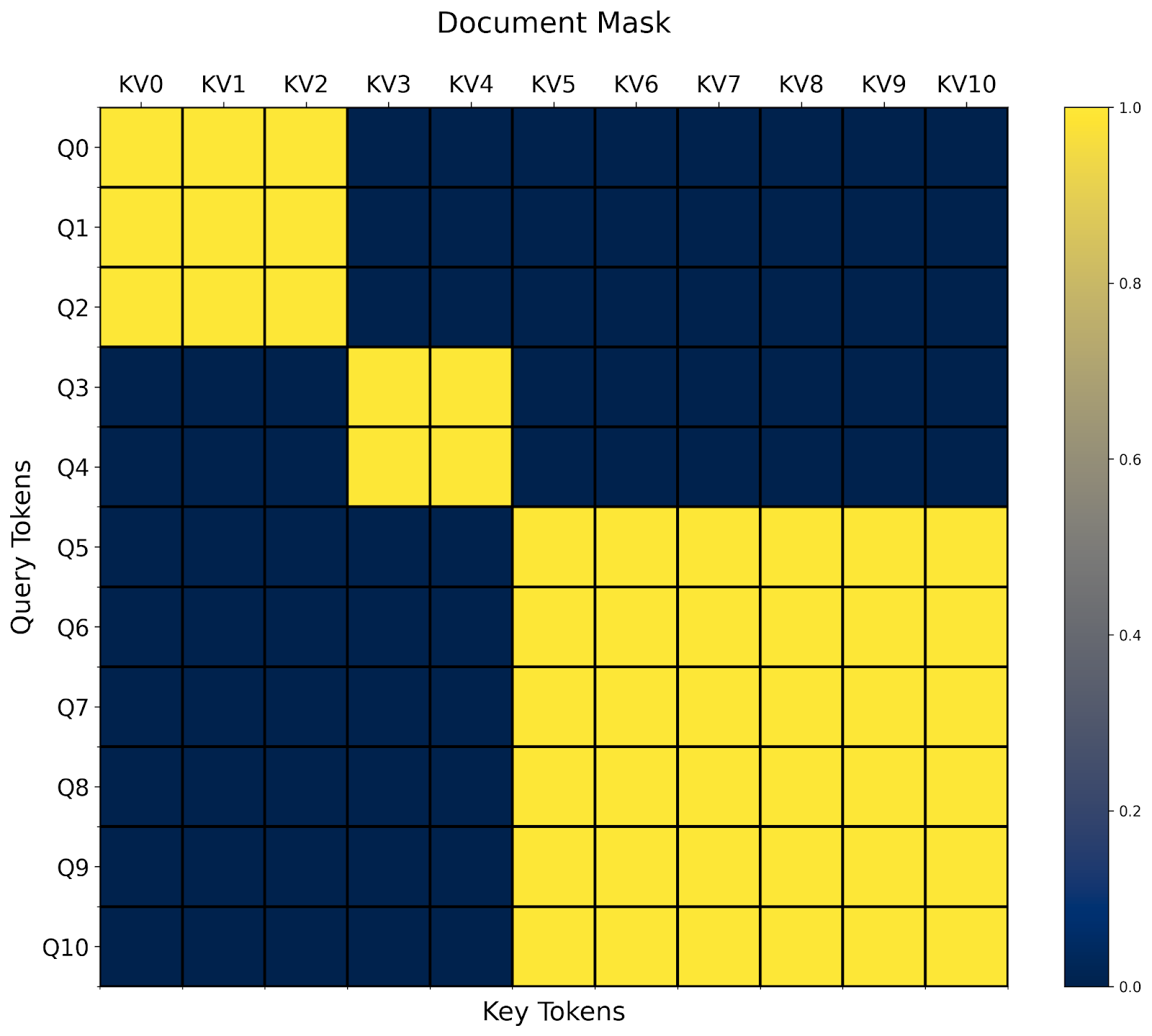
文件掩碼的一個有趣之處在於,很容易看出它如何與任意其他掩碼組合。例如,我們已經在上一節中定義了 `prefixlm_mask`。現在我們還需要定義一個 `prefixlm_document_mask` 函式嗎?
在這些情況下,我們發現一種非常有用的模式是我們稱之為“更高級別修改”的方法。在這種情況下,我們可以採用現有的 `mask_mod` 並自動將其轉換為一個適用於鋸齒序列的 `mask_mod`!
def generate_doc_mask_mod(mask_mod, document_id):
# Get unique document IDs and their counts
_, counts = torch.unique_consecutive(document_id, return_counts=True)
# Create cumulative counts (offsets)
offsets = torch.cat([torch.tensor([0], device=document_id.device), counts.cumsum(0)[:-1]])
def doc_mask_wrapper(b, h, q_idx, kv_idx):
same_doc = document_id[q_idx] == document_id[kv_idx]
q_logical = q_idx - offsets[document_id[q_idx]]
kv_logical = kv_idx - offsets[document_id[kv_idx]]
inner_mask = mask_mod(b, h, q_logical, kv_logical)
return same_doc & inner_mask
return doc_mask_wrapper
例如,給定上面的 `prefix_lm_causal` 掩碼,我們可以將其轉換為一個適用於打包文件的掩碼,如下所示
prefix_length = torch.tensor(2, dtype=torch.int32, device="cuda")
def prefix_mask(b, h, q_idx, kv_idx):
return kv_idx < prefix_length
prefix_lm_causal = or_masks(prefix_mask, causal_mask)
doc_prefix_lm_causal_mask = generate_doc_mask_mod(prefix_lm_causal, document_id)
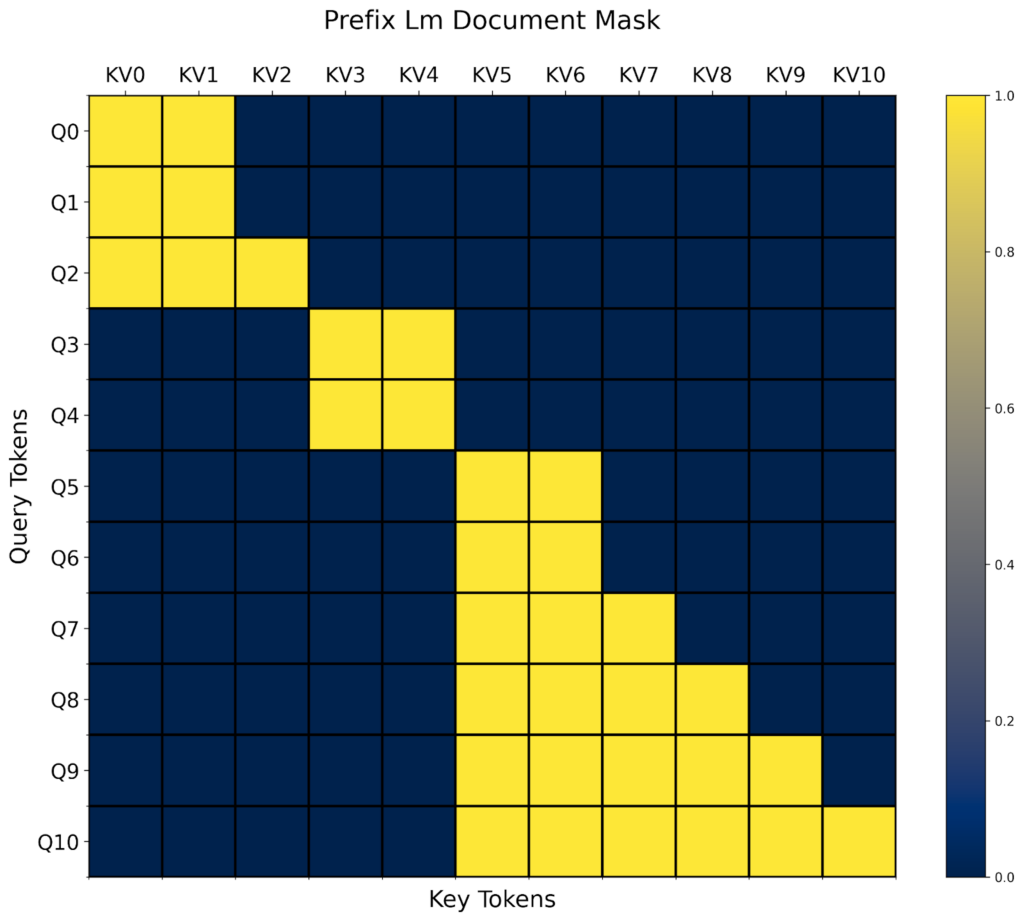
現在,這個掩碼是“塊-字首LM-對角線”形狀的。🙂
這就是我們所有的示例!注意力變體遠不止我們能列出的,所以請檢視Attention Gym以獲取更多示例。我們希望社群也能貢獻他們最喜歡的 FlexAttention 應用。
常見問題
問:FlexAttention 何時需要重新編譯?
由於 FlexAttention 利用 `torch.compile` 進行圖捕獲,它實際上可以在廣泛的場景中避免重新編譯。值得注意的是,即使捕獲的張量值發生變化,它也*不需要*重新編譯!
flex_attention = torch.compile(flex_attention)
def create_bias_mod(bias)
def bias_mod(score, b, h, q_idx, kv_idx):
return score + bias
return bias_mod
bias_mod1 = create_bias_mod(torch.tensor(0))
flex_attention(..., score_mod=bias_mod1) # Compiles the kernel here
bias_mod2 = create_bias_mod(torch.tensor(2))
flex_attention(..., score_mod=bias_mod2) # Doesn't need to recompile!
即使更改塊稀疏性也不需要重新編譯。但是,如果塊稀疏性發生變化,我們確實需要*重新計算* BlockMask。
問:我們應該何時重新計算 BlockMask?
每當塊稀疏性改變時,我們都需要重新計算 BlockMask。儘管計算 BlockMask 比重新編譯便宜得多(大約幾百微秒而不是幾秒),但您仍應注意不要過度重新計算 BlockMask。
以下是一些常見模式以及關於如何處理它們的建議。
掩碼從不改變(例如因果掩碼)
在這種情況下,您可以簡單地預先計算塊掩碼並全域性快取它,將其重用於所有注意力呼叫。
block_mask = create_block_mask(causal_mask, 1, 1, S,S)
causal_attention = functools.partial(flex_attention, block_mask=block_mask)
掩碼每批次都會變化(例如文件掩碼)
在這種情況下,我們建議在模型開始時計算 BlockMask,並將其貫穿模型——將 BlockMask 重用於所有層。
def forward(self, x, doc_mask):
# Compute block mask at beginning of forwards
block_mask = create_block_mask(doc_mask, None, None, S, S)
x = self.layer1(x, block_mask)
x = self.layer2(x, block_mask)
...
# amortize block mask construction cost across all layers
x = self.layer3(x, block_mask)
return x
掩碼每層變化(例如資料相關的稀疏性)
這是最困難的設定,因為我們無法在多次 FlexAttention 呼叫中攤銷塊掩碼計算。儘管 FlexAttention 肯定仍然可以在這種情況下受益,但 BlockMask 的實際好處取決於您的注意力掩碼的稀疏程度以及我們構建 BlockMask 的速度。這引出了…
問:我們如何更快地計算 BlockMask?
`create_block_mask` 不幸的是在記憶體和計算方面都相當昂貴,因為確定一個塊是否完全稀疏需要評估該塊中每個點的 `mask_mod`。有幾種方法可以解決這個問題
- 如果您的掩碼在批處理大小或頭部之間相同,請確保您在這些維度上進行廣播(即在 `create_block_mask` 中將它們設定為 `None`)。
- 編譯 `create_block_mask`。不幸的是,目前 `torch.compile` 由於一些不幸的限制,無法直接作用於 `create_block_mask`。但是,您可以設定 `_compile=True`,這將顯著降低峰值記憶體和執行時(在我們的測試中通常是一個數量級)。
- 為 BlockMask 編寫自定義建構函式。BlockMask 的元資料非常簡單(請參閱文件)。它本質上是兩個張量。a. `num_blocks`:為每個查詢塊計算的 KV 塊數。
b. `indices`:為每個查詢塊計算的 KV 塊的位置。例如,這是 `causal_mask` 的自定義 BlockMask 建構函式。
def create_causal_mask(S):
BLOCK_SIZE = 128
# The first query block computes one block, the second query block computes 2 blocks, etc.
num_blocks = torch.arange(S // BLOCK_SIZE, device="cuda") + 1
# Since we're always computing from the left to the right,
# we can use the indices [0, 1, 2, ...] for every query block.
indices = torch.arange(S // BLOCK_SIZE, device="cuda").expand(
S // BLOCK_SIZE, S // BLOCK_SIZE
)
num_blocks = num_blocks[None, None, :]
indices = indices[None, None, :]
return BlockMask(num_blocks, indices, BLOCK_SIZE=BLOCK_SIZE, mask_mod=causal_mask)
問:為什麼 `score_mod` 和 `mask_mod` 不同?難道 `mask_mod` 不僅僅是 `score_mod` 的一個特例嗎?
非常敏銳的問題,假想的觀眾!事實上,任何 `mask_mod` 都可以很容易地轉換為 `score_mod`(我們不建議在實踐中使用此函式!)
def mask_mod_as_score_mod(b, h, q_idx, kv_idx):
return torch.where(mask_mod(b, h, q_idx, kv_idx), score, -float("inf"))
那麼,如果 `score_mod` 可以實現 `mask_mod` 可以實現的所有功能,那麼 `mask_mod` 的意義何在?
一個直接的挑戰是:`score_mod` 需要實際的 `score` 值作為輸入,但在預計算 BlockMask 時,我們沒有實際的 `score` 值。我們或許可以透過傳入全零來偽造這些值,如果 `score_mod` 返回 `-inf`,那麼我們認為它被掩蓋了(事實上,我們最初就是這樣做的!)。
然而,存在兩個問題。首先,這是不嚴謹的——如果使用者的 `score_mod` 在輸入為 0 時返回 `-inf` 怎麼辦?或者如果使用者的 `score_mod` 用一個大的負值而不是 `-inf` 進行掩碼處理怎麼辦?我們似乎在試圖把圓釘子敲進方孔裡。然而,將 `mask_mod` 與 `score_mod` 分開還有一個更重要的原因——它從根本上更高效!
事實證明,對每個計算出的元素應用掩碼實際上非常昂貴——我們的基準測試顯示效能下降約 15-20%!因此,儘管我們可以透過跳過一半計算來顯著加速,但由於需要掩蓋每個元素,我們損失了相當一部分加速!
幸運的是,如果我們視覺化因果掩碼,我們會注意到絕大多數塊根本不需要“因果掩碼”——它們是完全計算的!只有對角線上的塊,部分計算和部分掩碼的塊,才需要應用掩碼。
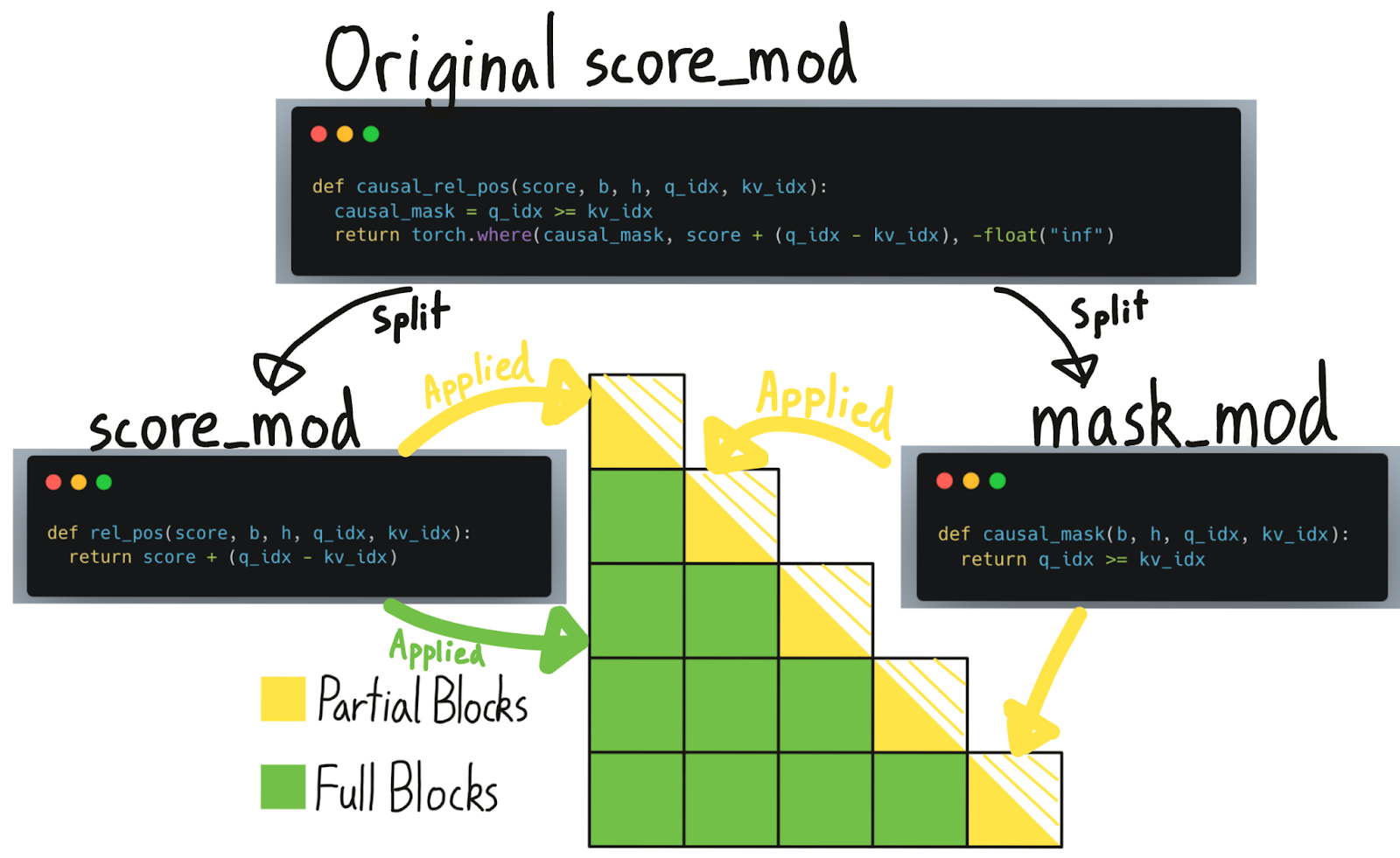
BlockMask 之前告訴我們哪些塊需要計算,哪些塊可以跳過。現在,我們進一步增強了這個資料結構,它還可以告訴我們哪些塊是“完全計算的”(即可以跳過掩碼)與“部分計算的”(即需要應用掩碼)。但請注意,儘管在“完全計算的”塊上可以跳過掩碼,但其他 `score_mod`(如相對位置嵌入)仍然需要應用。
給定一個 `score_mod`,我們無法可靠地判斷它的哪些部分是“掩碼”。因此,使用者必須將這些部分自己分成 `mask_mod`。
問:BlockMask 需要多少額外記憶體?
BlockMask 元資料的大小為 `[BATCH_SIZE, NUM_HEADS, QUERY_LEN//BLOCK_SIZE, KV_LEN//BLOCK_SIZE]`。如果掩碼在批次或頭維度上相同,則可以在該維度上進行廣播以節省記憶體。
在預設的 `BLOCK_SIZE` 為 128 時,我們預計大多數用例的記憶體使用將可以忽略不計。例如,對於 100 萬的序列長度,BlockMask 只會使用 60MB 的額外記憶體。如果這是一個問題,您可以增加塊大小:`create_block_mask(..., BLOCK_SIZE=1024)`。例如,將 `BLOCK_SIZE` 增加到 1024 將導致此元資料下降到一兆位元組以下。
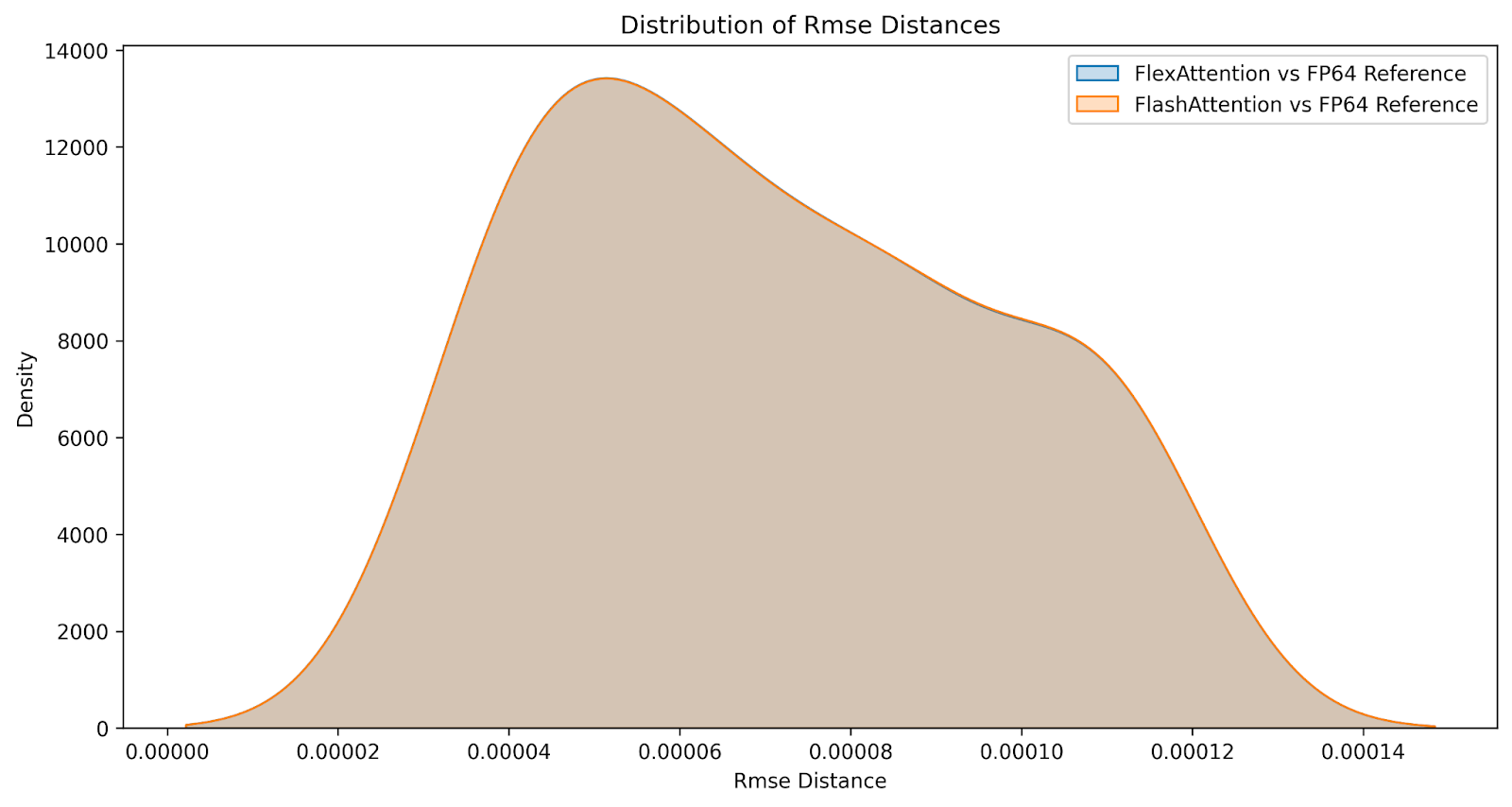
問:數值比較如何?
儘管結果並非位相同,但我們相信 FlexAttention 在數值上與 FlashAttention 一樣準確。我們在一系列因果和非因果注意力變體的輸入上比較了 FlashAttention 和 FlexAttention 的差異,生成了以下差異分佈。誤差幾乎相同。
效能
通常來說,FlexAttention 的效能幾乎與手寫的 Triton 核心相當,這並不奇怪,因為我們大量利用了手寫的 Triton 核心。然而,由於其通用性,我們確實會產生一小部分效能損失。例如,我們必須承擔一些額外的延遲來確定接下來要計算哪個塊。在某些情況下,我們提供了一些核心選項,它們可以在改變其行為的同時影響核心的效能。它們可以在這裡找到:效能旋鈕
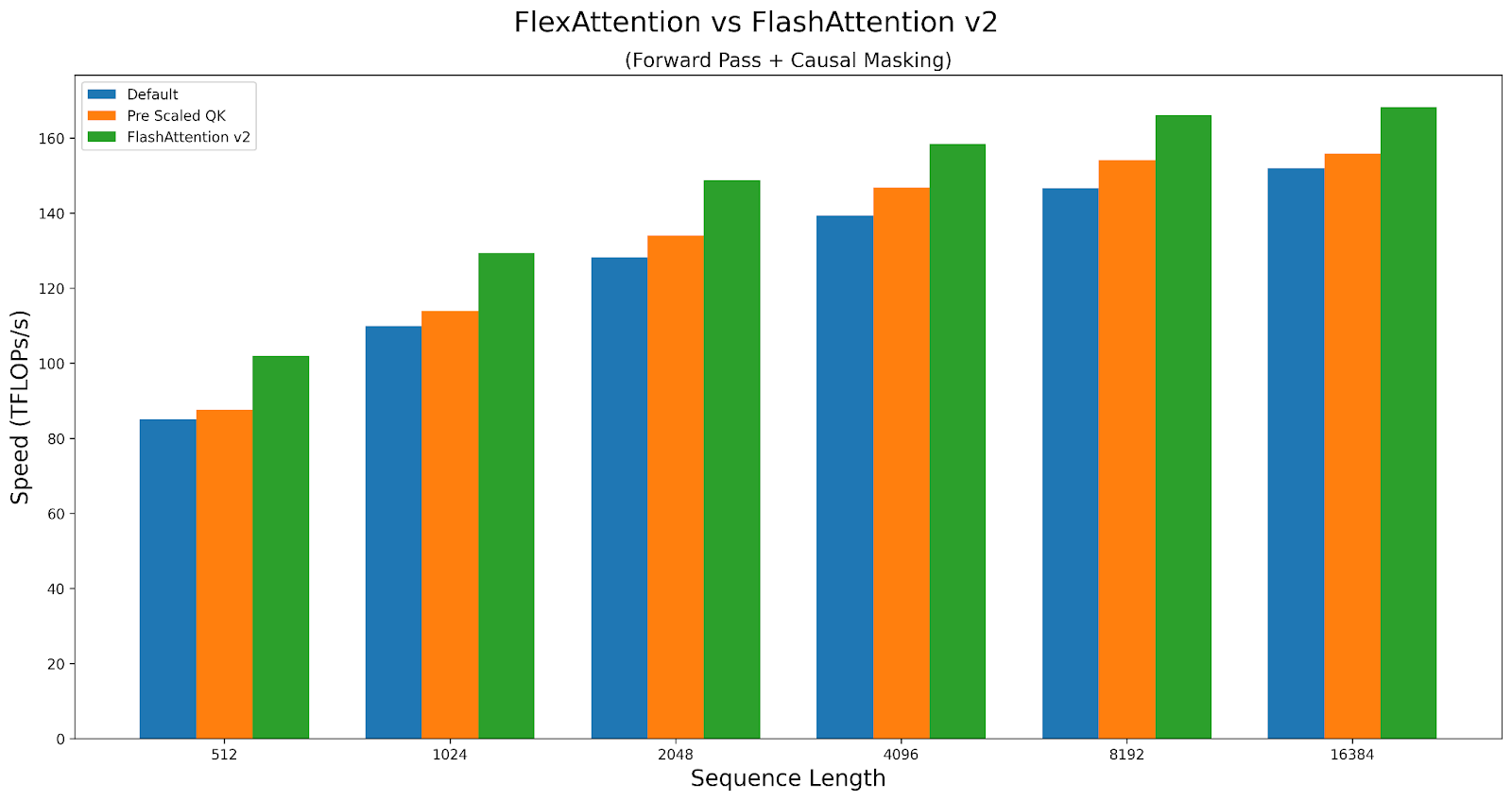
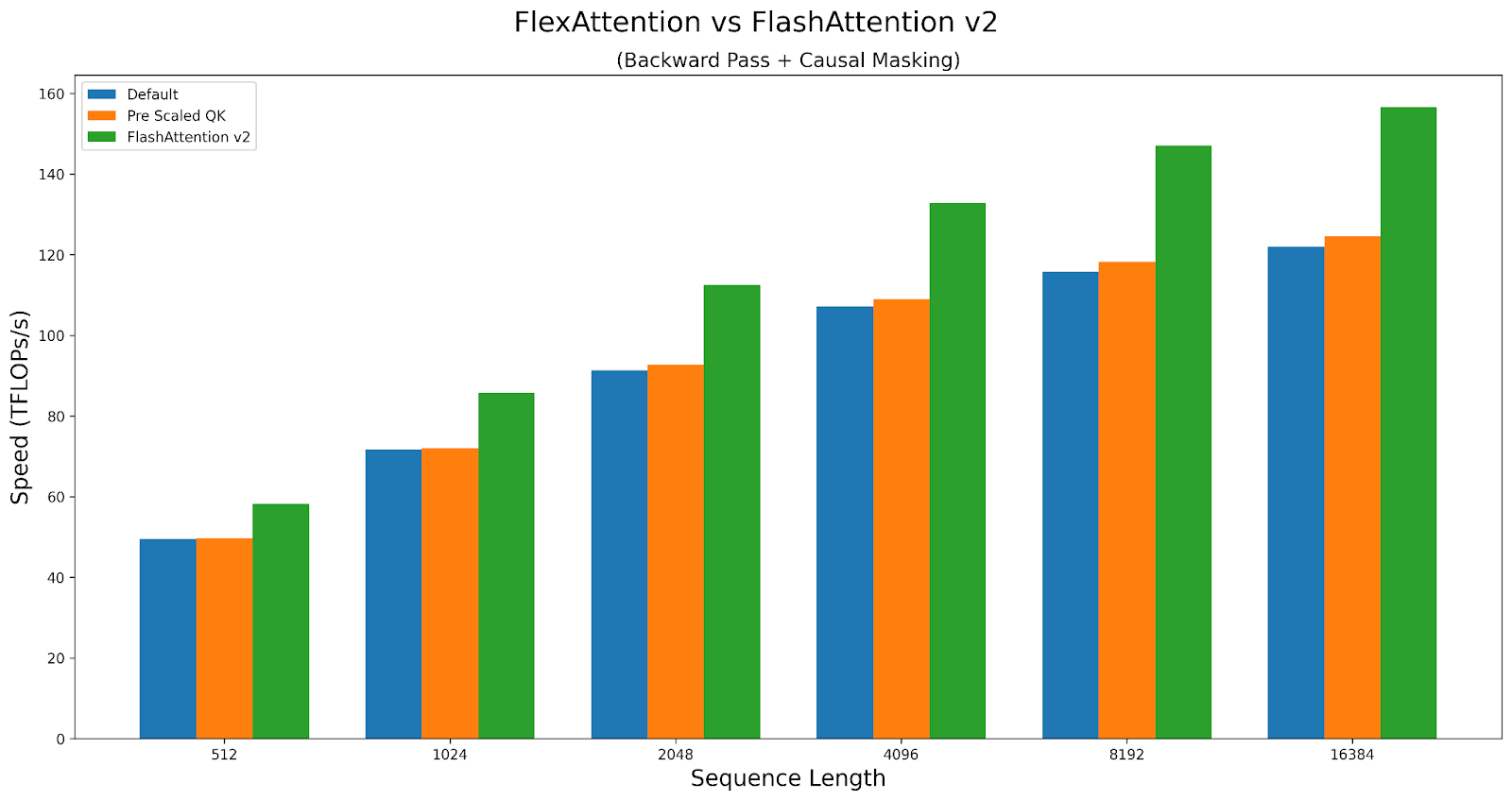
作為案例研究,讓我們探討這些旋鈕如何影響因果注意力的效能。我們將比較 A100 上 Triton 核心與 FlashAttentionv2 的效能。指令碼可以在此處找到。
FlexAttention 在前向傳播中實現了 FlashAttention2 90% 的效能,在反向傳播中實現了 85% 的效能。FlexAttention 目前正在使用一種確定性演算法,它比 FAv2 重新計算更多的中間結果,但我們計劃改進 FlexAttention 的反向傳播演算法,並希望彌合這一差距!
結論
我們希望您在使用 FlexAttention 時能像我們開發它時一樣快樂!在開發過程中,我們發現了比預期更多的此 API 應用。我們已經看到它將 torchtune 的樣本打包吞吐量提高了 71%,消除了研究人員需要花費一週多時間編寫自己的自定義 Triton 核心的需求,並提供了與自定義手寫注意力變體具有競爭力的效能。
最後,讓 FlexAttention 的實現變得非常有趣的一點是,我們能夠以一種有趣的方式利用許多現有的 PyTorch 基礎設施。例如,TorchDynamo(torch.compile 的前端)的一個獨特之處在於,它*不*要求編譯函式中使用的張量作為輸入顯式傳入。這使我們能夠編譯文件掩碼等模組,這些模組需要訪問*全域性*變數,並且全域性變數需要更改!
bias = torch.randn(1024, 1024)
def score_mod(score, b, h, q_idx, kv_idx):
return score + bias[q_idx][kv_idx] # The bias tensor can change!
此外,`torch.compile` 是一種通用圖捕獲機制,這一事實也使其能夠支援更“高階”的轉換,例如將任何 `mask_mod` 轉換為適用於鋸齒張量的高階轉換。
我們還利用 TorchInductor(torch.compile 的後端)基礎設施來實現 Triton 模板。這不僅使得支援程式碼生成 FlexAttention 變得容易,而且還自動為我們提供了對動態形狀和 epilogue 融合(即在注意力末尾融合一個運算子)的支援!將來,我們計劃擴充套件此支援,以允許量化版本的注意力或像 RadixAttention 這樣的功能。
此外,我們還利用了高階操作、PyTorch 的自動求導來自動生成反向傳播,以及 vmap 來自動應用 `score_mod` 以建立 BlockMask。
當然,沒有 Triton 和 TorchInductor 生成 Triton 程式碼的能力,這個專案是不可能實現的。
我們期待在未來將我們在這裡使用的方法應用於更多的應用程式!
侷限性和未來工作
- FlexAttention 目前在 PyTorch 每夜釋出版中可用,我們計劃在 2.5.0 中將其作為原型功能釋出
- 我們在這裡沒有介紹如何將 FlexAttention 用於推理(或如何實現 PagedAttention)——我們將在以後的文章中介紹。
- 我們正在努力提高 FlexAttention 的效能,使其與 H100 GPU 上的 FlashAttention3 匹配。
- FlexAttention 要求所有序列長度都是 128 的倍數——這個問題很快就會解決。
- 我們計劃很快新增 GQA 支援——目前,您只需複製 kv 頭即可。
致謝
我們要強調一些啟發 FlexAttention 的前期工作(和人物)。
- Tri Dao 在 FlashAttention 方面的工作
- Francisco Massa 和 Xformers 團隊在 Triton 中實現的 BlockSparseAttention
- Jax 團隊在 SplashAttention 方面的工作
- Philippe Tillet 和 Keren Zhou 協助我們處理 Triton
- Ali Hassani 關於鄰域注意力的討論
- 所有抱怨注意力核心不支援他們最喜歡的注意力變體的人 🙂