最近,Llama 2 釋出並引起了機器學習社群的廣泛關注。Amazon EC2 Inf2 例項,由 AWS Inferentia2 提供支援,現已支援 Llama 2 模型的訓練和推理。在這篇文章中,我們將展示如何使用最新的 AWS Neuron SDK 版本在 Amazon EC2 Inf2 例項上實現 Llama-2 模型的低延遲和高成本效益推理。我們首先介紹如何建立、編譯和部署 Llama-2 模型,並解釋 AWS Neuron SDK 引入的最佳化技術,以實現低成本下的高效能。然後,我們將展示我們的基準測試結果。最後,我們將展示如何透過 Amazon SageMaker 使用 TorchServe 在 Inf2 例項上部署 Llama-2 模型。
什麼是 Llama 2
Llama 2 是一種自迴歸語言模型,它使用最佳化的 Transformer 架構。Llama 2 旨在用於英語的商業和研究用途。它有多種大小——70 億、130 億和 700 億引數——以及預訓練和微調版本。據 Meta 稱,微調版本使用監督微調 (SFT) 和帶有人類反饋的強化學習 (RLHF) 來與人類對有用性和安全性的偏好保持一致。Llama 2 在來自公開來源的 2 萬億個 token 資料上進行了預訓練。微調模型旨在用於助手式聊天,而預訓練模型可以適應各種自然語言生成任務。無論開發人員使用哪個版本的模型,Meta 的負責任使用指南都可以協助指導可能需要進行的額外微調,以透過適當的安全緩解措施來定製和最佳化模型。
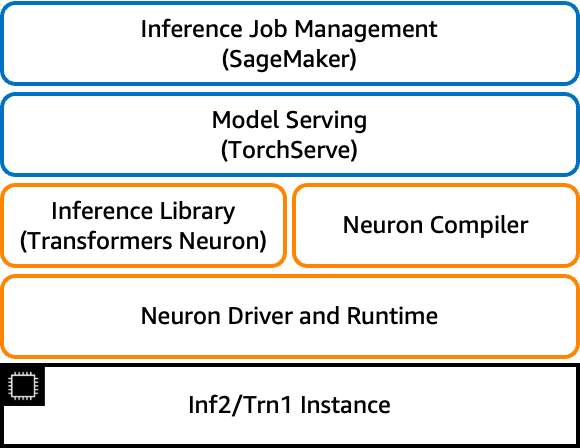
Amazon EC2 Inf2 例項概覽
Amazon EC2 Inf2 例項,採用 Inferentia2,提供 3 倍更高的計算能力,4 倍更多的加速器記憶體,從而實現高達 4 倍的吞吐量,以及高達 10 倍的低延遲,與第一代 Inf1 例項相比。
大型語言模型 (LLM) 推理是一種記憶體密集型工作負載,效能隨加速器記憶體頻寬的增加而提高。Inf2 例項是 Amazon EC2 中唯一針對推理最佳化的例項,可提供高速加速器互連 (NeuronLink),從而實現高效能大型 LLM 模型部署和高成本效益的分散式推理。您現在可以在 Inf2 例項上跨多個加速器高效且經濟地部署數十億引數的 LLM。
Inferentia2 支援 FP32、TF32、BF16、FP16、UINT8 和新的可配置 FP8 (cFP8) 資料型別。AWS Neuron 可以接受高精度 FP32 和 FP16 模型,並將其自動轉換為低精度資料型別,同時最佳化準確性和效能。自動轉換透過消除對低精度再訓練的需求,並使用更小的資料型別實現更高效能的推理,從而縮短了上市時間。
為了靈活且可擴充套件地部署不斷發展的深度學習模型,Inf2 例項具有硬體最佳化和軟體支援,可用於動態輸入形狀以及透過標準 PyTorch 自定義運算子程式設計介面用 C++ 編寫的自定義運算子。
Transformers Neuron (transformers-neuronx)
Transformers Neuron 是一個軟體包,使 PyTorch 使用者能夠部署效能最佳化的 LLM 推理。它具有使用 XLA 高階運算子 (HLO) 實現的 Transformer 模型最佳化版本,這使得張量可以在多個 NeuronCore 之間進行分片(即張量並行),並實現了效能最佳化,例如用於 Neuron 硬體的並行上下文編碼和 KV 快取。Llama 2 的 XLA HLO 原始碼可以在這裡找到。
Llama 2 透過 LlamaForSampling 類在 Transformers Neuron 中得到支援。Transformers Neuron 為 Hugging Face 模型提供了無縫的使用者體驗,可在 Inf2 例項上提供最佳化的推理。更多詳細資訊可在 Transforms Neuron Developer Guide 中找到。在下一節中,我們將解釋如何使用 Transformers Neuron 部署 Llama-2 13B 模型。此示例也適用於其他基於 Llama 的模型。
使用 Transformers Neuron 進行 Llama 2 模型推理
建立模型、編譯和部署
我們在這裡有三個簡單的步驟來在 Inf2 例項上建立、編譯和部署模型。
- 建立一個 CPU 模型,使用此指令碼或以下程式碼片段序列化並將檢查點儲存在本地目錄中。
from transformers import AutoModelForCausalLM
from transformers_neuronx.module import save_pretrained_split
model_cpu = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-13b-hf", low_cpu_mem_usage=True)
model_dir = "./llama-2-13b-split"
save_pretrained_split(model_cpu, model_dir)
- 使用以下方法從儲存序列化檢查點的本地目錄載入和編譯模型。要載入 Llama 2 模型,我們使用 Transformers Neuron 中的
LlamaForSampling。請注意,環境變數NEURON_RT_NUM_CORES指定了執行時要使用的 NeuronCore 數量,它應該與為模型指定的張量並行 (TP) 度匹配。此外,NEURON_CC_FLAGS可在僅解碼器 LLM 模型上啟用編譯器最佳化。
from transformers_neuronx.llama.model import LlamaForSampling
os.environ['NEURON_RT_NUM_CORES'] = '24'
os.environ['NEURON_CC_FLAGS'] = '--model-type=transformer'
model = LlamaForSampling.from_pretrained(
model_dir,
batch_size=1,
tp_degree=24,
amp='bf16',
n_positions=16,
context_length_estimate=[8]
)
現在,讓我們編譯模型並使用一行 API 將模型權重載入到裝置記憶體中。
model.to_neuron()
- 最後,讓我們在編譯後的模型上執行推理。請注意,
sample函式的輸入和輸出都是 token 序列。
inputs = torch.tensor([[1, 16644, 31844, 312, 31876, 31836, 260, 3067, 2228, 31844]])
seq_len = 16
outputs = model.sample(inputs, seq_len, top_k=1)
Transformers Neuron 中的推理最佳化
張量並行
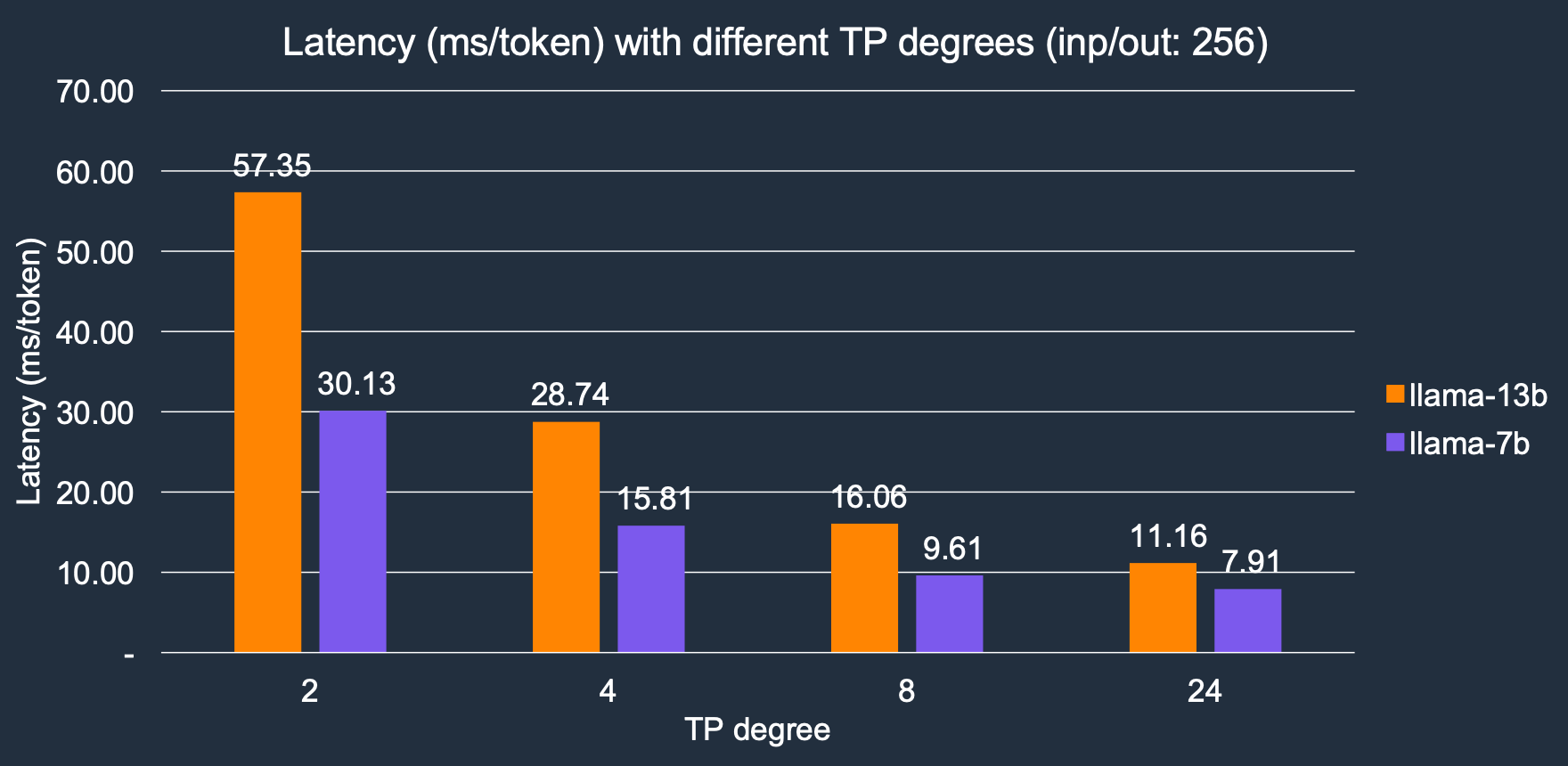
Transformer Neuron 在多個 NeuronCore 之間實現並行張量操作。我們將用於推理的核心數量表示為 TP 度。TP 度越大,記憶體頻寬越高,從而導致延遲越低,因為 LLM token 生成是一個記憶體 I/O 密集型工作負載。隨著 TP 度的增加,推理延遲顯著降低,我們的結果顯示,TP 度從 2 增加到 24,整體速度提高了約 4 倍。對於 Llama-2 7B 模型,延遲從 2 個核心的 30.1 毫秒/token 降低到 24 個核心的 7.9 毫秒/token;類似地,對於 Llama-2 13B 模型,它從 57.3 毫秒/token 降低到 11.1 毫秒/token。
並行上下文編碼
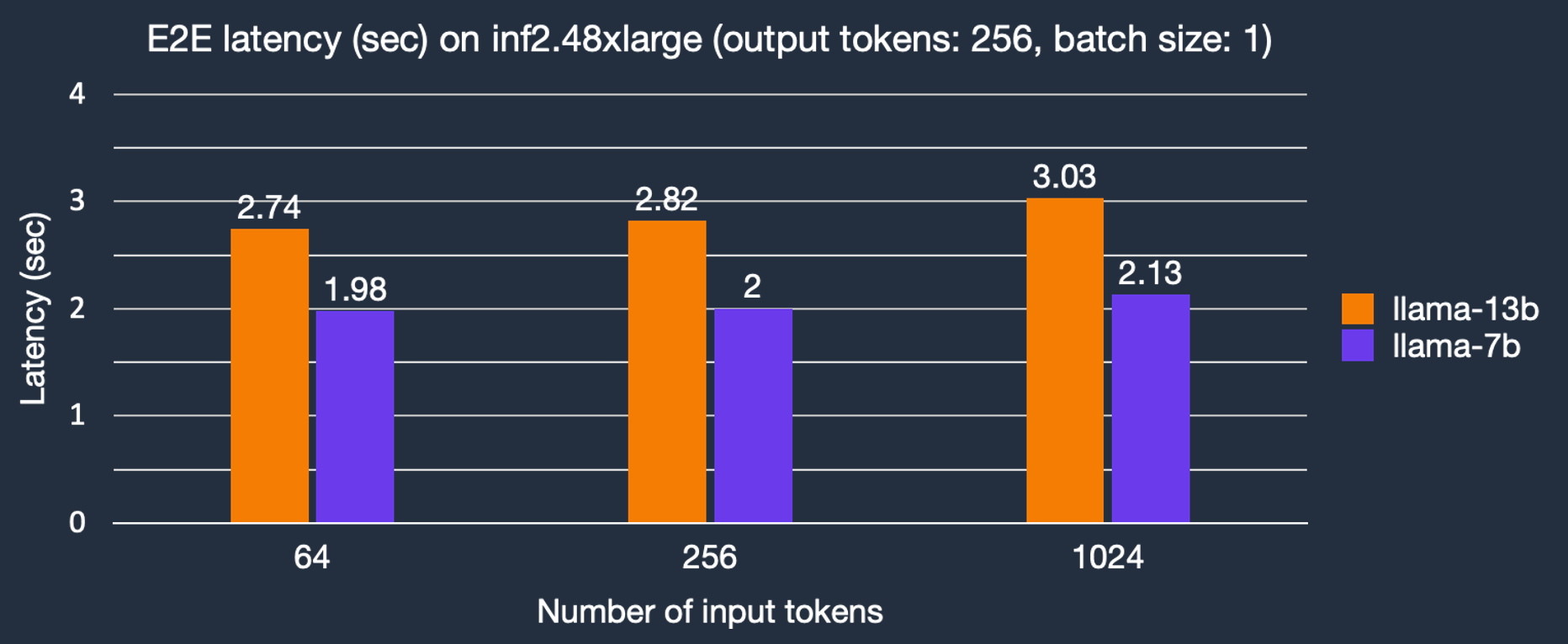
在 Transformer 架構中,token 以稱為自迴歸取樣(autoregressive sampling)的順序過程生成,而輸入提示 token 可以透過並行上下文編碼並行處理。這可以顯著減少在透過自迴歸取樣生成 token 之前輸入提示上下文編碼的延遲。預設情況下,引數 context_length_estimate 將設定為一系列 2 的冪次方數字,旨在涵蓋各種上下文長度。根據用例,它可以設定為自定義數字。這可以在使用 LlamaForSampling.from_pretrained 建立 Llama 2 模型時完成。我們描述了輸入 token 長度對端到端 (E2E) 延遲的影響。如圖所示,得益於並行上下文編碼,Llama-2 7B 模型的文字生成延遲僅隨更大輸入提示而略有增加。
KV 快取
自注意力塊使用 KV 向量執行自注意力操作。KV 向量是使用 token 嵌入和 KV 權重計算的,因此與 token 相關聯。在樸素實現中,對於每個生成的 token,都會重新計算整個 KV 快取,但這會降低效能。因此,Transformers Neuron 庫會重複使用先前計算的 KV 向量,以避免不必要的計算,這被稱為 KV 快取,以減少自迴歸取樣階段的延遲。
基準測試結果
我們對 Llama-2 7B 和 13B 模型在不同條件下(即輸出 token 數量、例項型別)的延遲和成本進行了基準測試。除非另有說明,我們使用資料型別 'bf16' 和批處理大小 1,因為這是即時應用(如聊天機器人和程式碼助手)的常見配置。
延遲
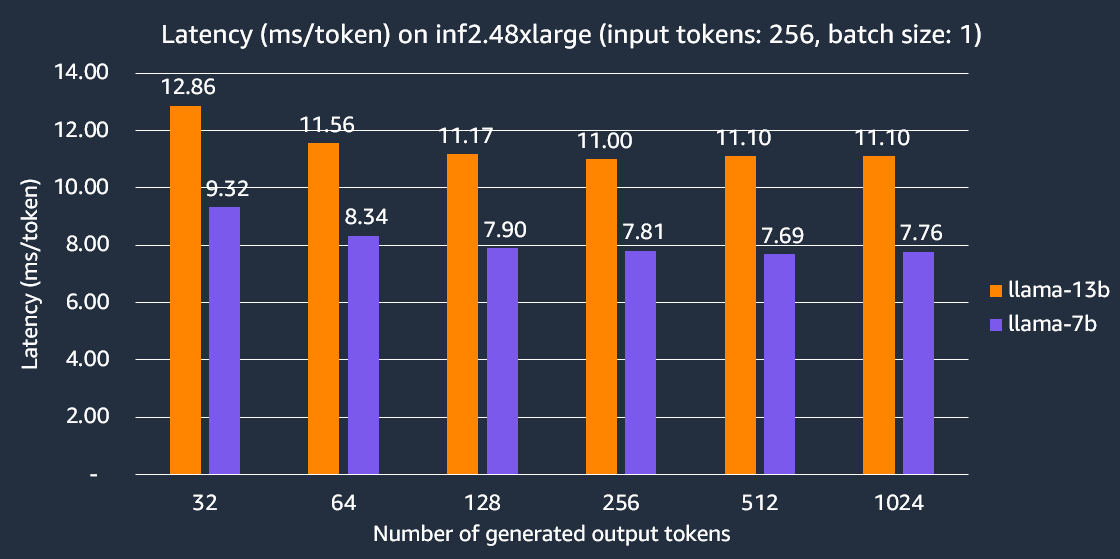
以下圖表顯示了在 inf2.48xlarge 例項上使用 TP 度為 24 的每個 token 延遲。這裡,每個輸出 token 的延遲計算為端到端延遲除以輸出 token 的數量。我們的實驗表明,Llama-2 7B 生成 256 個 token 的端到端延遲比其他可比較的推理最佳化型 EC2 例項快 2 倍。
吞吐量
現在我們展示 inf2.48xlarge 例項可以為 Llama-2 7B 和 13B 模型每秒生成的 token 數量。在 TP 度為 24 的情況下,充分利用所有 24 個 NeuronCore,Llama-2 7B 和 13B 模型分別可以達到 130 token/秒和 90 token/秒。
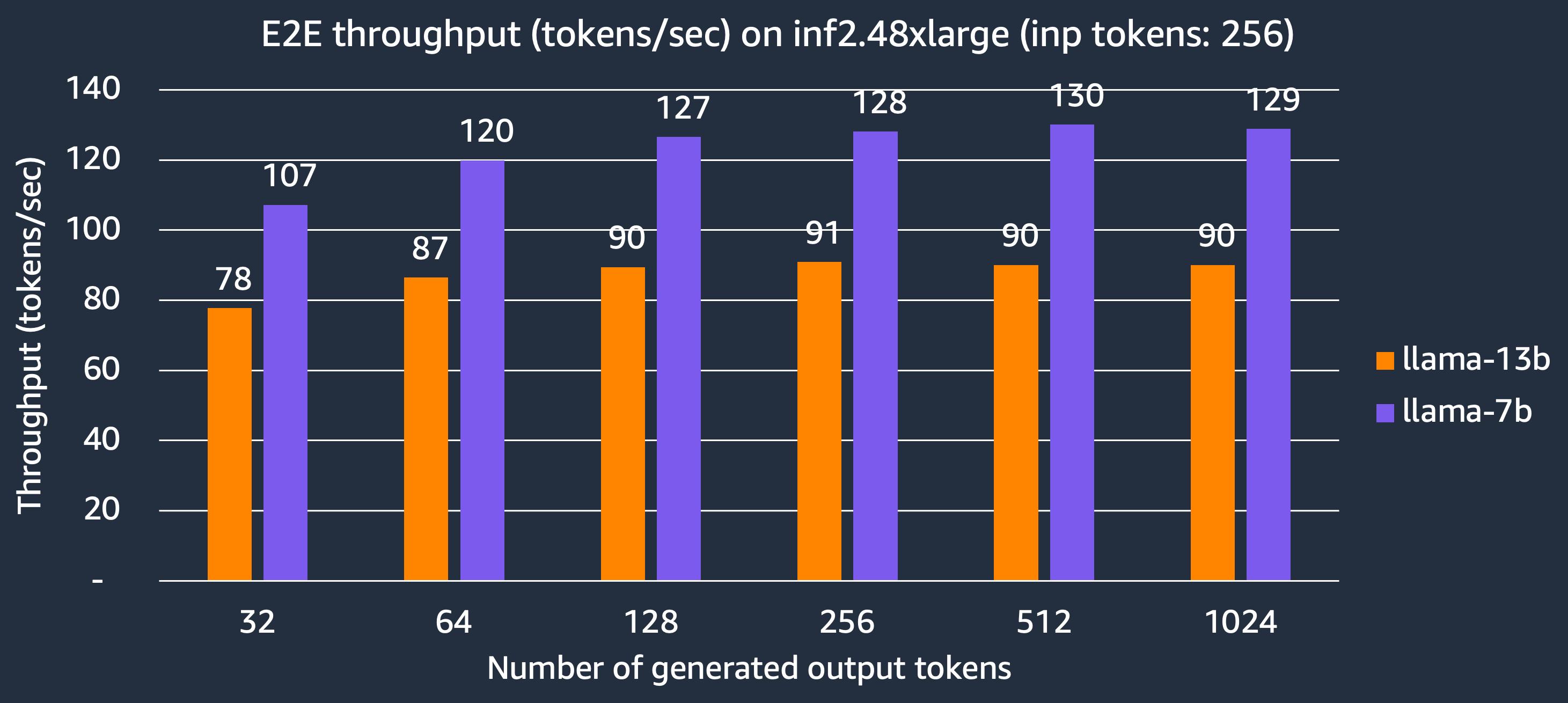
成本
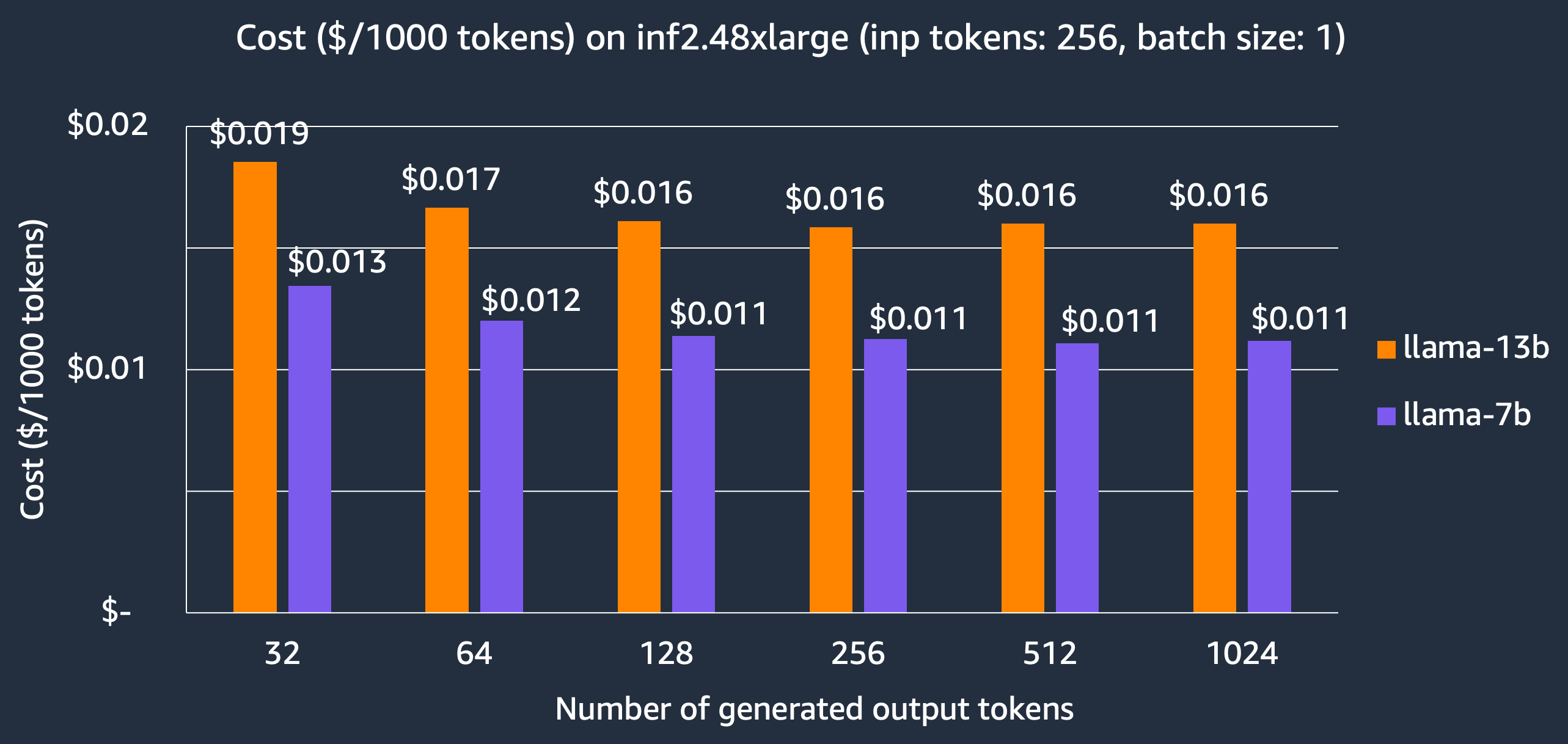
對於延遲優先的應用程式,我們展示了在 inf2.48xlarge 例項上託管 Llama-2 模型的成本,7B 和 13B 模型每 1000 個 token 的成本分別為 $0.011 和 $0.016,比其他可比較的推理最佳化型 EC2 例項節省了 3 倍的成本。請注意,我們報告的成本基於 3 年預留例項價格,這是客戶用於大型生產部署的價格。
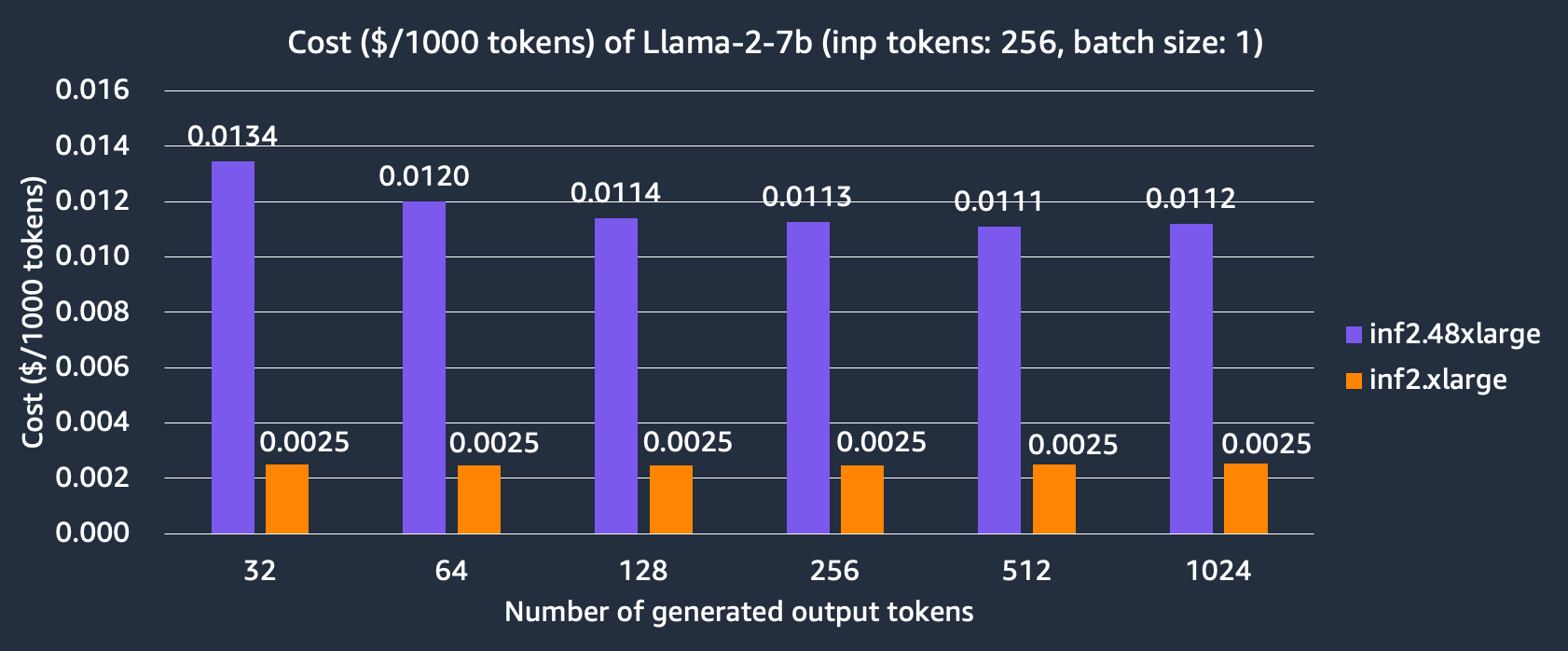
我們還比較了在 inf2.xlarge 和 inf2.48xlarge 例項上託管 Llama-2 7B 模型的成本。我們可以看到 inf2.xlarge 比 inf2.48xlarge 便宜 4 倍以上,但代價是由於 TP 度較小而導致延遲更長。例如,在 inf2.48xlarge 上模型生成 256 個輸出 token(輸入 256 個 token)需要 7.9 毫秒,而在 Inf2.xlarge 上需要 30.1 毫秒。
使用 TorchServe 在 EC2 Inf2 例項上提供 Llama2
現在,我們轉向模型部署。在本節中,我們將向您展示如何透過 SageMaker 使用 TorchServe 部署 Llama-2 13B 模型。TorchServe 是 PyTorch 推薦的模型伺服器,預裝在 AWS PyTorch 深度學習容器 (DLC) 中。
本節描述了使用 TorchServe 所需的準備工作,特別是如何配置 model_config.yaml 和 inf2_handler.py,以及如何生成模型工件和預編譯模型以用於後續模型部署。提前準備模型工件可以避免模型部署期間的模型編譯,從而縮短模型載入時間。
模型配置 model-config.yaml
handler 和 micro_batching 部分中定義的引數用於自定義處理程式 inf2_handler.py。有關 model_config.yaml 的更多詳細資訊,請參見 此處。TorchServe 微批處理是一種並行預處理和後處理批次推理請求的機制。當後端穩定接收傳入資料時,透過更好地利用可用加速器,它可以實現更高的吞吐量,更多詳細資訊請參見 此處。對於 Inf2 上的模型推理,micro_batch_size、amp、tp_degree 和 max_length 分別指定批處理大小、資料型別、張量並行度以及最大序列長度。
# TorchServe Frontend Parameters
minWorkers: 1
maxWorkers: 1
maxBatchDelay: 100
responseTimeout: 10800
batchSize: 16
# TorchServe Backend Custom Handler Parameters
handler:
model_checkpoint_dir: "llama-2-13b-split"
amp: "bf16"
tp_degree: 12
max_length: 100
micro_batching:
# Used by batch_size in function LlamaForSampling.from_pretrained
micro_batch_size: 1
parallelism:
preprocess: 2
inference: 1
postprocess: 2
自定義處理程式 inf2_handler.py
Torchserve 中的自定義處理程式是一個簡單的 Python 指令碼,可讓您將模型初始化、預處理、推理和後處理邏輯定義為函式。在這裡,我們建立了 Inf2 自定義處理程式。
- initialize 函式用於載入模型。在這裡,Neuron SDK 將首次編譯模型,並將預編譯的模型儲存在由
NEURONX_CACHE啟用並在NEURONX_DUMP_TO中指定的目錄中。第一次之後,後續執行將檢查是否已經有預編譯的模型工件。如果是,它將跳過模型編譯。一旦模型載入完成,我們便會啟動預熱推理請求,以便快取編譯版本。當使用 neuron 持久快取時,它可以顯著減少模型載入延遲,確保後續推理執行迅速。
os.environ["NEURONX_CACHE"] = "on"
os.environ["NEURONX_DUMP_TO"] = f"{model_dir}/neuron_cache"
TorchServe `TextIteratorStreamerBatch` 擴充套件了 Hugging Face transformers `BaseStreamer`,以支援當 `batchSize` 大於 1 時的響應流。
self.output_streamer = TextIteratorStreamerBatch(
self.tokenizer,
batch_size=self.handle.micro_batch_size,
skip_special_tokens=True,
)
- 推理函式呼叫
send_intermediate_predict_response以傳送流式響應。
for new_text in self.output_streamer:
logger.debug("send response stream")
send_intermediate_predict_response(
new_text[: len(micro_batch_req_id_map)],
micro_batch_req_id_map,
"Intermediate Prediction success",
200,
self.context,
)
打包模型工件
使用 torch-model-archiver 將所有模型工件打包到一個名為 llama-2-13b-neuronx-b1 的資料夾中。
torch-model-archiver --model-name llama-2-13b-neuronx-b1 --version 1.0 --handler inf2_handler.py -r requirements.txt --config-file model-config.yaml --archive-format no-archive
服務模型
export TS_INSTALL_PY_DEP_PER_MODEL="true"
torchserve --ncs --start --model-store model_store --models llama-2-13b-neuronx-b1
一旦日誌顯示“WORKER_MODEL_LOADED”,預編譯模型應儲存在 llama-2-13b-neuronx-b1/neuron_cache 資料夾中,該資料夾與 Neuron SDK 版本緊密相關。然後,將 llama-2-13b-neuronx-b1 資料夾上傳到您的 S3 儲存桶,以供產品部署中使用。本部落格中 Llama-2 13B 模型的工件可在 此處 找到,該工件與 TorchServe 模型庫中的 Neuron SDK 2.13.2 相關聯。
使用 TorchServe 在 SageMaker Inf2 例項上部署 Llama-2 13B 模型
在本節中,我們使用 PyTorch Neuronx 容器在 SageMaker 端點上部署 Llama-2 13B 模型,該端點使用 ml.inf2.24xlarge 託管例項,該例項具有 6 個 Inferentia2 加速器,與我們的模型配置 model_config.yaml 處理程式設定 tp_degree: 12 對應。鑑於我們已使用 torch-model-archiver 將所有模型工件打包到一個資料夾中並上傳到 S3 儲存桶,我們現在將使用 SageMaker Python SDK 建立一個 SageMaker 模型,並使用 部署未壓縮模型方法將其部署到 SageMaker 即時端點。以這種方式使用 SageMaker 部署的關鍵優勢是速度,您可以獲得一個功能齊全的生產就緒端點,其中包含安全的 RESTful 端點,而無需在基礎設施上花費任何精力。在 SageMaker 上部署模型和執行推理有 3 個步驟。筆記本示例可以在 這裡 找到。
- 建立一個 SageMaker 模型
from datetime import datetime
instance_type = "ml.inf2.24xlarge"
endpoint_name = sagemaker.utils.name_from_base("ts-inf2-llama2-13b-b1")
model = Model(
name="torchserve-inf2-llama2-13b" + datetime.now().strftime("%Y-%m-%d-%H-%M-%S"),
# Enable SageMaker uncompressed model artifacts
model_data={
"S3DataSource": {
"S3Uri": s3_uri,
"S3DataType": "S3Prefix",
"CompressionType": "None",
}
},
image_uri=container,
role=role,
sagemaker_session=sess,
env={"TS_INSTALL_PY_DEP_PER_MODEL": "true"},
)
- 部署 SageMaker 模型
model.deploy(
initial_instance_count=1,
instance_type=instance_type,
endpoint_name=endpoint_name,
volume_size=512, # increase the size to store large model
model_data_download_timeout=3600, # increase the timeout to download large model
container_startup_health_check_timeout=600, # increase the timeout to load large model
)
- 在 SageMaker 上執行流式響應推理 當端點處於服務中時,您可以使用
invoke_endpoint_with_response_streamAPI 呼叫來呼叫模型。此功能可以將每個生成的 token 返回給使用者,從而增強使用者體驗。當生成整個序列非常耗時時,此功能尤其有用。
import json
body = "Today the weather is really nice and I am planning on".encode('utf-8')
resp = smr.invoke_endpoint_with_response_stream(EndpointName=endpoint_name, Body=body, ContentType="application/json")
event_stream = resp['Body']
parser = Parser()
for event in event_stream:
parser.write(event['PayloadPart']['Bytes'])
for line in parser.scan_lines():
print(line.decode("utf-8"), end=' ')
推理示例:
輸入
“今天天氣真好,我正計劃”
輸出
“今天天氣真好,我正計劃去海灘。我打算帶上我的相機,拍一些海灘的照片。我將拍攝沙灘、海水和人群的照片。我還將拍攝日落的照片。我真的很高興能去海灘拍照。
海灘是一個拍照的好地方。沙灘、海水和人群都是很棒的拍攝物件。日落也是一個很棒的拍攝物件。”
結論
在這篇文章中,我們展示瞭如何使用 Transformers Neuron 執行 Llama 2 模型推理,以及如何透過 Amazon SageMaker 在 EC2 Inf2 例項上使用 TorchServe 部署 Llama 2 模型服務。我們展示了使用 Inferentia2 的優勢——低延遲和低成本——這得益於 AWS Neuron SDK 中的最佳化,包括張量並行、並行上下文編碼和 KV 快取,尤其適用於 LLM 推理。要了解最新資訊,請關注 AWS Neuron 的最新版本以獲取新功能。
立即開始使用 EC2 和 SageMaker 上的 Llama 2 示例,並敬請期待如何在 Inf2 上最佳化 Llama 70B!