PyTorch 2.8 已釋出,帶來了一系列令人興奮的新功能,包括針對第三方 C++/CUDA 擴充套件的有限穩定 libtorch ABI、在英特爾 CPU 上使用原生 PyTorch 進行高效能量化 LLM 推理、實驗性 Wheel Variant 支援、Inductor CUTLASS 後端支援等。在所有這些功能中,最棒的一點是 PyTorch 現在可以在英特爾至強平臺上提供與流行 LLM 框架相比具有競爭力的低精度大語言模型 (LLM) 效能。
在 PyTorch 2.8 中,我們為英特爾至強處理器上的 LLM 啟用了並優化了常見的量化配置,包括 A16W8、DA8W8 和 A16W4 等。當在量化模型中使用 torch.compile 時,我們將量化 GEMM 的模式降級為基於模板的高效能 GEMM 核心,並在 Inductor 中使用 max-autotune,這將利用英特爾 AMX 和英特爾 AVX-512 功能來加速處理。
透過此功能,與流行的 LLM 服務框架 vLLM 在單個英特爾至強 CPU 計算節點上以離線模式執行時相比,PyTorch 原生堆疊的效能可以達到相同水平,在某些情況下甚至更好。下面列出了 PyTorch 原生和 vLLM 之間的 TTFT 和 TPOT 比較(使用 Llama-3.1-8B 作為基準模型),針對不同的低精度配置,包括 DA8W8、A16W4 和 DA8W4。
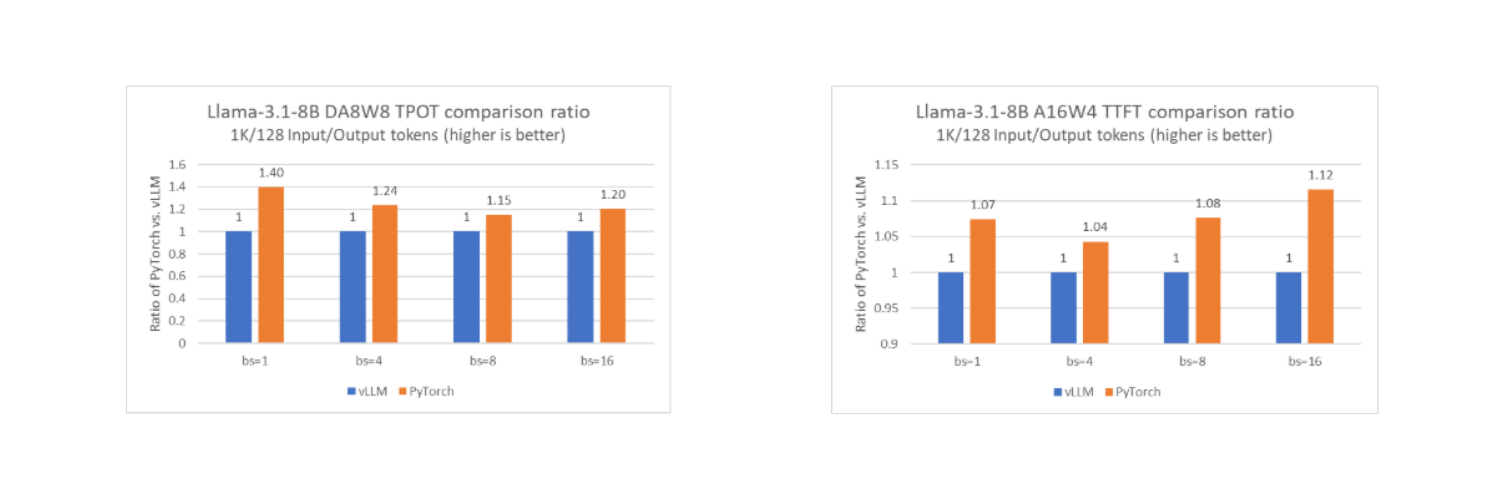
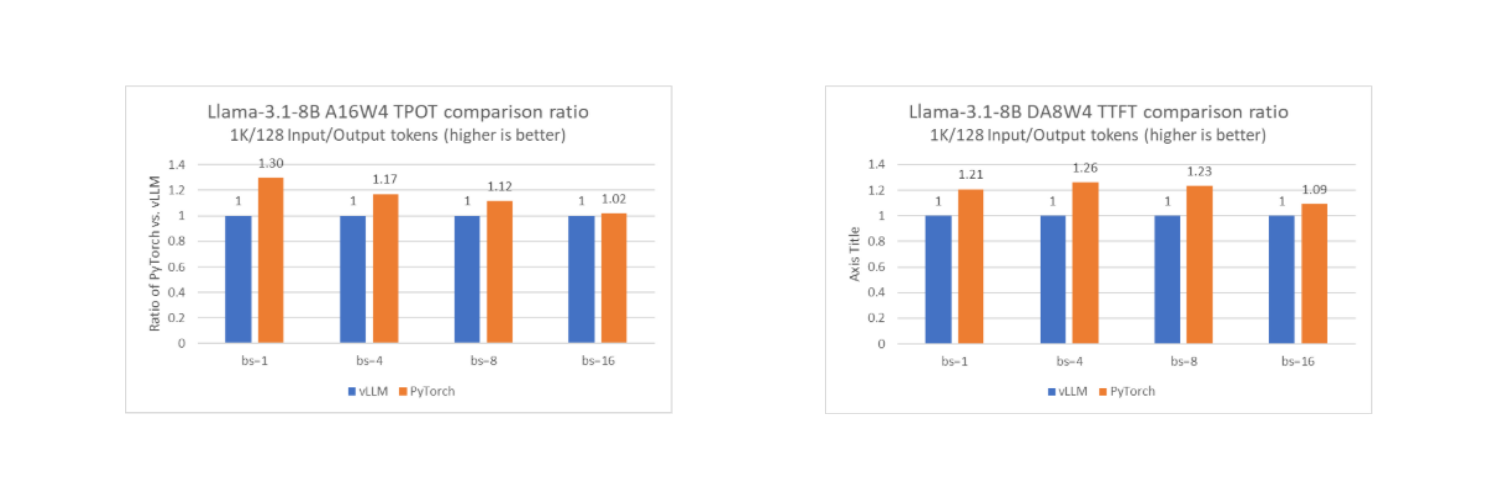
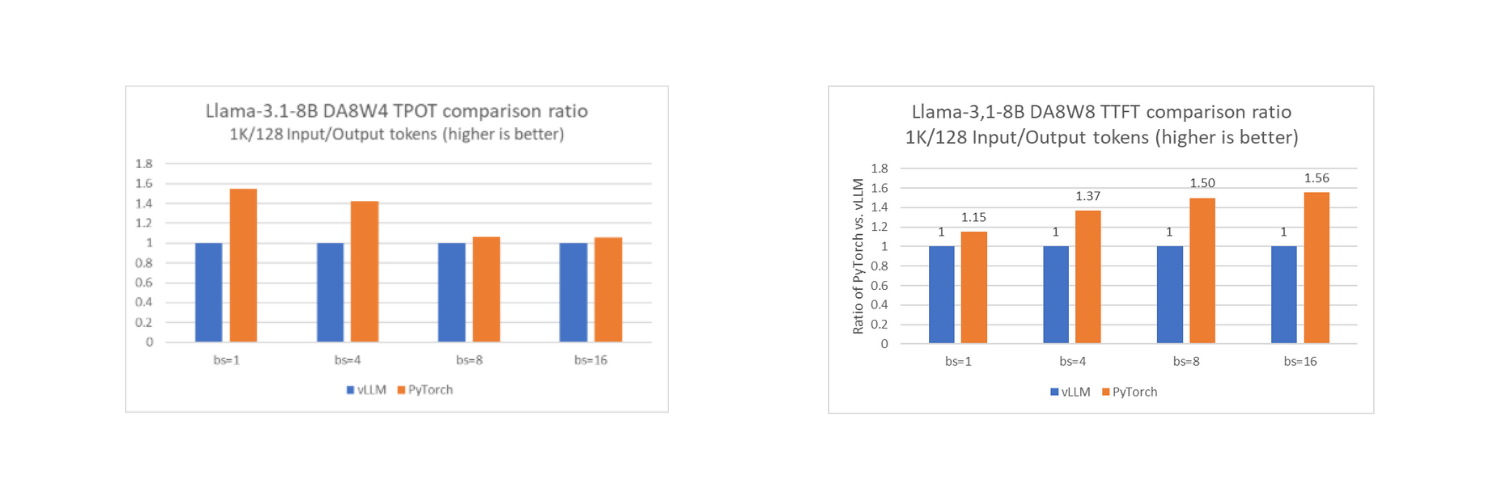 正如我們在圖中看到的,PyTorch 堆疊在大多數測試配置中都達到了相似或更好的效能。值得注意的是,vLLM 在離線模式下而不是服務模式下進行測試,這與執行原生 PyTorch 的配置一致。
正如我們在圖中看到的,PyTorch 堆疊在大多數測試配置中都達到了相似或更好的效能。值得注意的是,vLLM 在離線模式下而不是服務模式下進行測試,這與執行原生 PyTorch 的配置一致。
要使用這些功能並獲得提升的效能,使用者只需:
- 選擇一臺支援 AMX 的 X86 CPU 機器。
- 使用 Torchao 的量化方法量化模型。
- 為
torch.compile設定一些標誌以獲得最佳效能。 - 使用
torch.compile編譯模型。
然後,最佳化將自動在後臺應用。這是一個示例。
# 1. Set torch.compile flags from torch._inductor import config as inductor_config inductor_config.cpp_wrapper = True inductor_config.max_autotune = True inductor_config.cpp.enable_concat_linear = True inductor_config.cpp.use_small_dequant_buffer = True # 2. Get model model = transformers.AutoModelForCausalLM.from_pretrained(<model_id>, ...) # 3. Quantization with Torchao from torchao.quantization.quant_api import ( quantize_, Int8DynamicActivationInt8WeightConfig, Int4WeightOnlyConfig, Int8DynamicActivationInt4WeightConfig, ) ## 3.1 DA8W8 quantize_( model, Int8DynamicActivationInt8WeightConfig(set_inductor_config=False) ) ## 3.2 A16W4 quantize_( model, Int4WeightOnlyConfig( group_size=128, int4_packing_format="opaque", set_inductor_config=False, ) ) ## 3.3 DA8W4 from torchao.dtypes import Int8DynamicActInt4WeightCPULayout from torchao.quantization.quant_primitives import MappingType quantize_( model, Int8DynamicActivationInt4WeightConfig( group_size=128, layout=Int8DynamicActInt4WeightCPULayout(), act_mapping_type=MappingType.SYMMETRIC, set_inductor_config=False, ) ) # 4. Apply optimizations with torch.compile model.forward = torch.compile(model.forward) # 5. Run the quantized and optimized model # Preparation of input_ids and generate_kwargs are not shown model.generate( input_ids, **generate_kwargs )
總結
我們討論了在 PyTorch 2.8 中,與流行的 LLM 框架相比,在英特爾至強處理器上實現有競爭力的 LLM 效能的能力。此功能旨在使 PyTorch 使用者能夠使用 int8 和 int4 精度執行 LLM 僅權重(WOQ)量化,並在英特爾硬體上獲得原生體驗和最新的效能最佳化。目前的最佳化基於單個英特爾至強平臺裝置,我們將繼續支援基於多個英特爾至強平臺的推理,然後我們可以擁有更多高階功能,例如張量並行也可以生效。
致謝
PyTorch 2.8 的釋出是英特爾至強平臺的一個激動人心的里程碑,這離不開社群的深入協作和貢獻。我們衷心感謝 Alban D、 Andrey Talman、 Bin Bao、 Jason Ansel、 Jerry Zhang 和 Nikita Shulga 分享了他們寶貴的想法,一絲不苟地審查了 PR,並對 RFC 提供了富有洞察力的反饋。他們的奉獻推動了持續改進,並推動了英特爾平臺的生態系統發展。
參考資料
產品和效能資訊
測量環境:1 節點,2 個 Intel(R) Xeon(R) 6980P,128 核,TDP 500W,超執行緒開啟,睿頻開啟,總記憶體 1536GB (24x64GB DDR5 12800MT/s [8800MT/s]),SNC 3,BIOS BHSDCRB1.IPC.3544.D02.2410010029,微碼 0x11000314,1 個 I210 千兆網絡卡,1 個 3.5T INTEL SSDPF2KX038TZ,1 個 894.3G Micron_7450_MTFDKBG960TFR,2 個 1.8T INTEL SSDPE2MX020T4F,1 個 1.8T INTEL SSDPE2KX020T8,CentOS Stream 9,6.6.0-gnr.bkc.6.6.16.8.23.x86_64,僅使用一個 SNC 進行測試,輸入 token 長度:1K,輸出 token 長度:128,vLLM 在離線模式下測試。英特爾於 2025 年 7 月使用 PyTorch 2.8 RC、TorchAO (3addf30) 和 vLLM v0.8.5 進行測試。
宣告和免責條款
效能因使用、配置和其他因素而異。請訪問 效能指數網站瞭解更多資訊。效能結果基於所示配置在所示日期進行的測試,可能無法反映所有公開發布的更新。請參閱備份以獲取配置詳細資訊。沒有產品或元件能夠絕對安全。您的成本和結果可能會有所不同。英特爾技術可能需要啟用硬體、軟體或服務啟用。
英特爾公司。英特爾、英特爾徽標和其他英特爾標誌是英特爾公司或其子公司的商標。其他名稱和品牌可能屬於他人財產。
人工智慧免責宣告:
人工智慧功能可能需要軟體購買、訂閱或由軟體或平臺提供商啟用,或者可能具有特定的配置或相容性要求。詳情請訪問 www.intel.com/AIPC。結果可能有所不同。