投機解碼是一種用於推理的最佳化技術,它在生成當前 token 的同時,在一個前向傳播中對未來的 token 進行有根據的猜測。它包含一個驗證機制,以確保這些猜測的 token 的正確性,從而保證投機解碼的整體輸出與傳統解碼的輸出相同。最佳化大型語言模型(LLM)的推理成本,可以說是降低生成式 AI 成本和提高其採用率的最關鍵因素之一。為此,有多種推理最佳化技術可用,包括自定義核心、輸入請求的動態批處理和大型模型的量化。
在這篇部落格文章中,我們提供了投機解碼的指南,並展示了它如何與其他最佳化共存。我們很自豪能開源以下內容,其中包括第一個 Llama3 模型投機器:
- 適用於 Meta Llama3 8B、IBM Granite 7B lab、Meta Llama2 13B 和 Meta Code Llama2 13B 的投機器模型。
- 透過 IBM 的 HF TGI 分支進行推理的程式碼。
- 訓練您自己的投機器和相應配方的程式碼。
我們已將這些投機器部署到擁有數千日常使用者的內部生產級環境中,並觀察到語言模型(Llama3 8B、Llama2 13B 和 IBM Granite 7B)的速度提升了 2 倍,IBM Granite 20B 程式碼模型的速度提升了 3 倍。我們在這份 技術報告 中提供了我們方法的詳細解釋,並計劃在即將釋出的 ArXiv 論文中進行深入分析。
投機解碼:推理
我們在內部生產環境中執行 IBM TGIS,該環境具有連續批處理、融合核心和量化核心等最佳化。為了在 TGIS 中啟用投機解碼,我們修改了 vLLM 的分頁注意力核心。接下來,我們將描述推理引擎為啟用投機解碼而進行的關鍵更改。
投機解碼的前提是模型足夠強大,可以在單個前向傳播中預測多個 token。然而,當前的推理伺服器經過最佳化,每次只能預測一個 token。在我們的方法中,我們為 LLM 附加了多個投機頭(除了通常的一個),以預測第 _N+1_、_N+2_、_N+3_ 個… token。例如,3 個頭將預測 3 個額外的 token。投機器架構的詳細資訊將在本部落格的後面部分解釋。在推理過程中實現_效率_和_正確性_面臨兩個挑戰:一是無需複製 KV 快取即可進行預測,二是驗證預測是否與原始模型的輸出匹配。
在典型的生成迴圈中,在單個前向步驟處理完提示後,將序列長度為 1(預測的下一個 token)的輸入與 KV 快取一起輸入到模型的前向傳播中。在樸素的投機解碼實現中,每個投機頭都將擁有自己的 KV 快取,但我們修改了 vLLM 專案中開發的分頁注意力核心,以實現高效的 KV 快取維護。這確保了在較大的批次大小時吞吐量不會降低。此外,我們修改了注意力掩碼,以啟用對 _N+1_ 個 token 的驗證,從而在不偏離原始模型輸出的情況下啟用投機解碼。此實現的詳細資訊記錄在 此處。
結果
我們使用一個簡單的提示,說明了使用 Meta 的 Llama2 13B 聊天版本所獲得的加速。
圖 2:非投機生成(左)與投機生成(右)的視覺說明
我們將上述解決方案部署到內部生產環境中。下圖報告了兩個指標——首次生成 token 的時間 (TTFT) 和 token 間延遲 (ITL),在不同併發使用者數(在圖線上的數字中表示)下。我們觀察到,對於所有批次大小,投機解碼版本的 Llama2 13B 聊天模型速度幾乎是非投機版本的兩倍,而 Granite 20B 程式碼模型速度幾乎是其三倍。我們觀察到較小模型(IBM 的 Granite 7B 和 Meta Llama3 8B 模型)也有類似的行為。
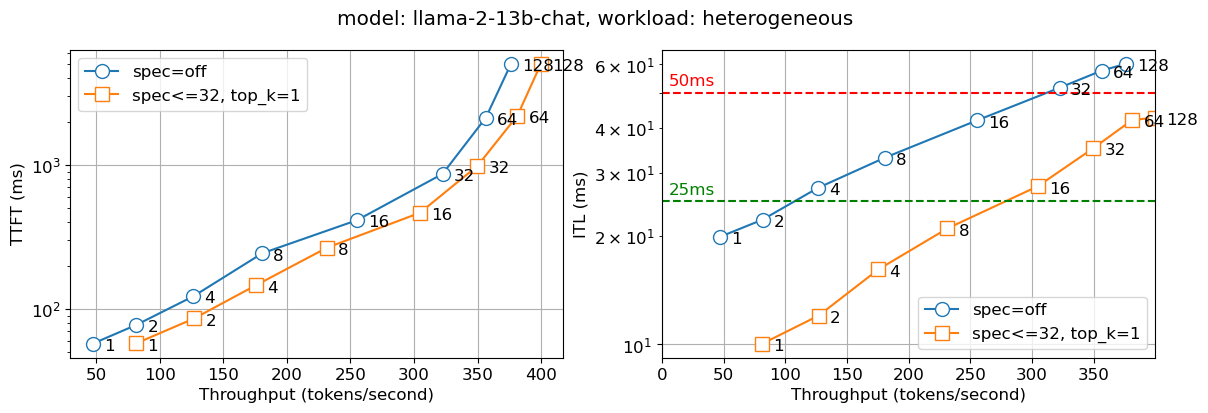
圖 3:Llama 13B 的首次生成 token 時間(TTFT – 左)和 token 間延遲(ITL – 右),圖上標示了併發使用者數
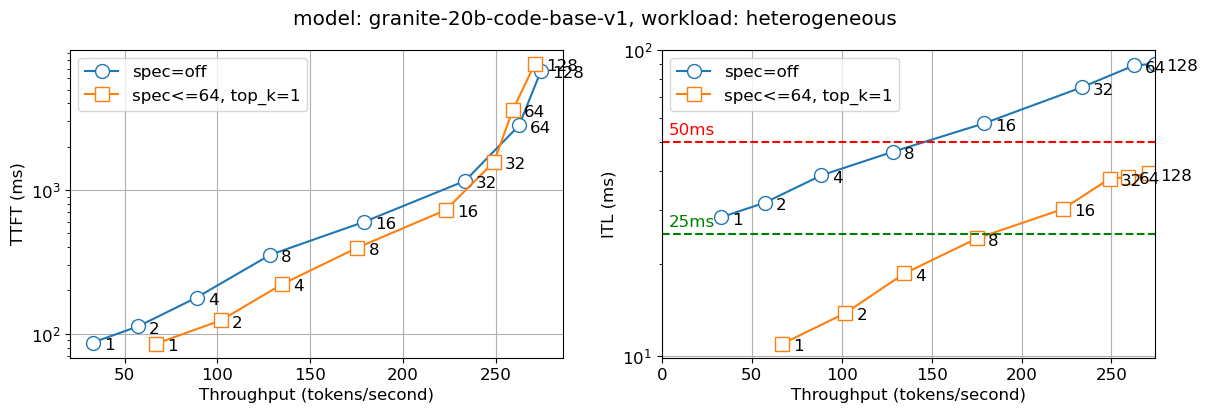
圖 4:Granite 20B Code 的首次生成 token 時間(TTFT – 左)和 token 間延遲(ITL – 右),圖上標示了併發使用者數
效率說明
我們進行了大量實驗,以確定投機器訓練的正確配置。這些配置是:
- 投機器架構:當前方法允許修改頭的數量,這對應於我們可以向前看的 token 數量。增加頭的數量也會增加所需的額外計算量和訓練複雜性。在實踐中,對於語言模型,我們發現 3-4 個頭效果很好,而對於程式碼模型,我們發現 6-8 個頭可以帶來好處。
- 計算:增加頭的數量會導致兩個方面的計算量增加,一是單次前向傳播的延遲增加,二是多個 token 所需的計算量。如果投機器在擁有更多頭時不夠準確,將導致計算浪費,從而增加延遲並降低吞吐量。
- 記憶體:增加的計算量透過每次前向傳播所需的 HBM 往返次數來抵消。請注意,如果我們能夠正確預測 3 個 token,我們就節省了 HBM 上的三次往返時間。
我們為語言模型選擇了 3-4 個頭,為程式碼模型選擇了 6-8 個頭,並且在 7B 到 20B 的不同模型尺寸上,我們觀察到與非投機解碼相比,顯著的延遲改進而沒有吞吐量損失。我們開始在批次大小超過 64 時觀察到吞吐量下降,這在實踐中很少發生。
投機解碼:訓練
投機解碼有兩種主要方法,一種是利用較小的模型(例如,Llama 7B 作為 Llama 70B 的投機器),另一種是附加投機頭(並訓練它們)。在我們的實驗中,我們發現附加投機頭的方法在模型質量和延遲增益方面都更有效。
投機器架構
Medusa 使投機解碼廣受歡迎;他們的方法是在現有模型中新增一個頭,然後訓練它進行投機。我們透過將“頭”分層來修改 Medusa 架構,每個頭階段預測一個 token,然後將其饋送到下一個頭階段。這些多階段頭如下圖所示。我們正在探索透過在多個階段和基礎模型之間共享嵌入表來最小化嵌入表的方法。
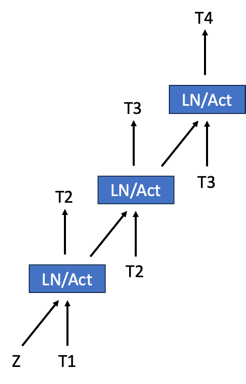
圖 4:一個 3 頭多階段投機器的簡單架構圖。Z 是來自基礎模型的狀態。
投機器訓練
出於效率原因,我們採用兩階段方法訓練投機器。在第一階段,我們使用小批次和長序列長度(4k token)進行訓練,並採用標準的因果 LM 方法進行訓練。在第二階段,我們使用來自基礎模型生成的大批次和短序列長度(256 token)。在這個訓練階段,我們調整頭以匹配基礎模型的輸出。透過大量實驗,我們發現第一階段與第二階段的步數比為 5:2 效果很好。我們下圖中展示了這些階段的進展。我們使用 PyTorch FSDP 和 IBM FMS 來訓練投機器。
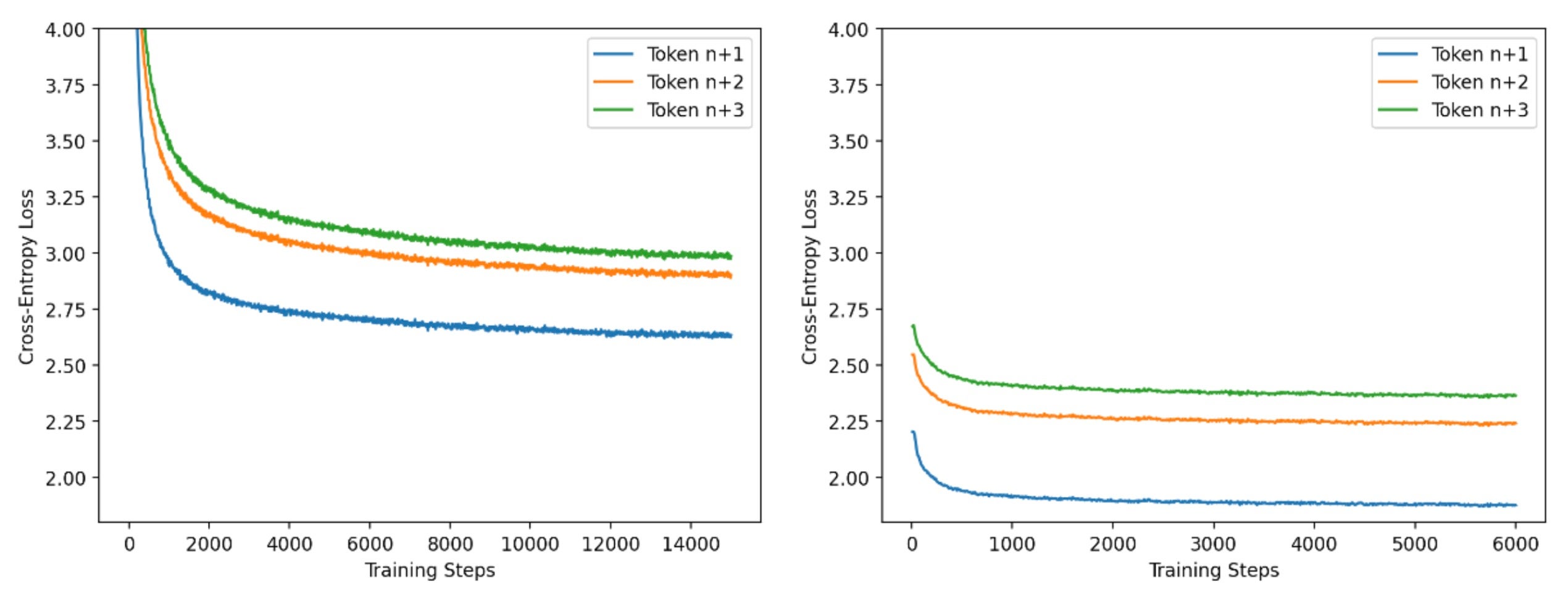
圖 5:Llama2-13B 投機器訓練的每頭訓練損失曲線,階段 1 和 2
結論和未來工作
透過這篇部落格,我們釋出了一種新的投機解碼方法和以下資產:
- 用於改進 Llama3 8B、Llama2 13B、Granite 7B 和 CodeLlama 13B 等一系列模型的 token 間延遲的模型。
- 用於推理的生產級程式碼。
- 訓練投機器的配方。
我們正在努力訓練 Llama3 70B 和 Mistral 模型的投機器,並邀請社群貢獻和幫助改進我們的框架。我們也很樂意與主要開源服務框架合作,如 vLLM 和 TGI,以回饋我們的投機解碼方法,造福社群。
致謝
有幾個團隊幫助我們實現了推理的這些延遲改進。我們衷心感謝 vLLM 團隊以清晰可重用的方式建立了分頁注意力核心。我們向 Meta 的 PyTorch 團隊表示感謝,他們為這篇部落格提供了反饋,並持續努力最佳化 PyTorch 的使用。特別感謝 IBM Research 的內部生產團隊,他們將這個原型投入生產並使其變得更加健壯。感謝 Stas Bekman 對部落格提供了富有洞察力的評論,從而改進了對計算、記憶體和投機器有效性之間權衡的解釋。
分頁注意力核心由 Josh Rosenkranz 和 Antoni Viros i Martin 整合到 IBM FMS 中。投機器架構和訓練由 Davis Wertheimer、Pavithra Ranganathan 和 Sahil Suneja 完成。建模程式碼與推理伺服器的整合由 Thomas Parnell、Nick Hill 和 Prashant Gupta 完成。