總結
PyTorch 分散式檢查點 (DCP) 正在投入解決互操作性障礙,以確保像 HuggingFace safetensors 這樣的流行格式能夠與 PyTorch 生態系統良好協作。由於 HuggingFace 已成為推理和微調領域的主導格式,DCP 開始支援 HuggingFace safetensors。這些更改的第一個客戶是 torchtune,他們看到了改進的使用者體驗,因為他們現在可以直接使用 DCP API 清晰地讀寫 HuggingFace。
問題
由於 HuggingFace 被廣泛使用,擁有超過 500 萬用戶,許多機器學習工程師希望以 safetensors 格式儲存和載入他們的檢查點,以便輕鬆地與他們的生態系統協作。透過在 DCP 中原生支援 safetensors 格式,我們的使用者的檢查點操作在以下方面得到簡化:
- DCP 目前有自己的自定義格式,因此希望使用 HuggingFace 模型但又想利用 DCP 的 效能優勢 和功能的使用者,必須構建自定義轉換器和元件,才能在兩個系統之間工作。
- 使用者不再需要每次都將檢查點下載和上傳到本地儲存,HuggingFace 模型現在可以直接儲存和載入到他們選擇的 fsspec 支援的儲存中。
如何使用
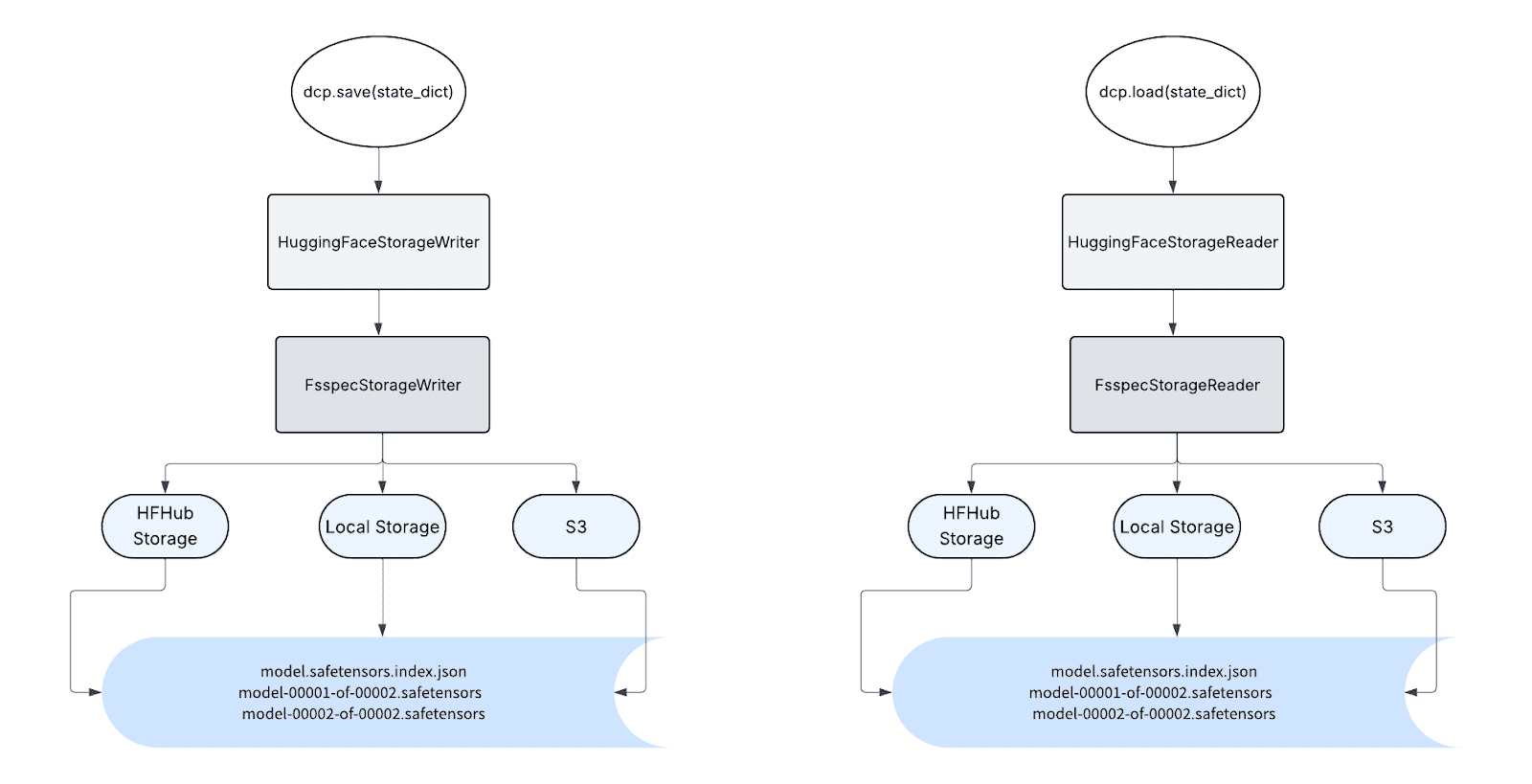
從使用者的角度來看,使用 safetensors 所需的唯一更改是使用新的 載入規劃器 和 儲存讀取器 呼叫載入,類似地,使用新的 儲存規劃器 和 儲存寫入器 呼叫儲存。
載入和儲存 API 呼叫如下
load(
state_dict=state_dict,
storage_reader=HuggingFaceStorageReader(path=path),
)
save(
state_dict=state_dict,
storage_writer=HuggingFaceStorageWriter(
path=path,
fqn_to_index_mapping=mapping
),
)
HuggingFaceStorageReader 和 HuggingFaceStorageWriter 可以接受任何基於 fsspec 的路徑,因此它可以以 HF safetensors 格式讀寫到任何 fsspec 支援的後端,包括本地儲存和 HF 儲存。由於 HuggingFace safetensors 元資料本身不提供與 DCP 元資料相同級別的資訊,因此分散式檢查點目前在這些 API 中尚未得到良好支援,但 DCP 計劃在未來原生支援此功能。
torchtune
我們 HuggingFace DCP 支援的第一個客戶是 torchtune——一個用原生 PyTorch 編寫的訓練後庫。torchtune 使用者獲取模型權重的主要方式是從 Hugging Face Hub。以前,使用者必須透過額外的 CLI 命令下載模型權重並上傳訓練好的檢查點;新的 DCP API 允許他們直接讀寫 HuggingFace,從而帶來更好的使用者體驗。
此外,DCP 中對 safetensor 序列化的支援極大地簡化了 torchtune 中的檢查點程式碼。不再需要針對特定格式的檢查點解決方案,從而提高了專案中的開發人員效率。
未來工作
DCP 計劃處理 HuggingFace safetensors 檢查點的分散式載入和儲存以及重新分片。DCP 還計劃支援將合併後的最終檢查點生成到單個檔案以供釋出的功能。