引言
我們將混合精度和低精度訓練與 Opacus 整合,以提高吞吐量並支援更大的批處理大小訓練。我們的初步實驗表明,透過使用混合精度或低精度,可以保持與全精度訓練相同的效用。這些是早期階段的結果,我們鼓勵進一步研究低精度和混合精度對 DP-SGD 效用影響。
Opacus 在應對大型模型(如 LLM)訓練挑戰以及彌合隱私訓練與非隱私訓練之間差距方面取得了重大進展。2024 年,我們向 Opacus 引入了快速梯度裁剪,以減少基於 hook 的 DP-SGD 實現的記憶體佔用。最近,新增的 完全分片資料並行 (FSDP) 功能可以將大型模型訓練擴充套件到不同裝置。
混合精度訓練結合了不同的數值精度,在加快訓練速度和減少記憶體使用方面非常有效,同時保持了模型效用。透過將低精度(例如 BF16)操作與單精度(FP32)操作結合使用,可以訓練更大的模型,使用更大的批處理大小和更快的矩陣操作。例如,Llama 3 模型使用 FP32 和 BF16 的混合精度進行訓練,而 Llama 4 使用 BF16 和 FP8。我們邀請開發人員和研究人員利用混合精度和其他最近引入的技術,將 Opacus 訓練擴充套件到更大的模型。
混合精度和低精度訓練
單精度浮點數由 32 位表示。較新的 GPU 支援 16 位或 8 位浮點表示的高吞吐量算術運算。這些效率提升已被深度學習應用採用,在這些應用中,通常較低的精度不會損害模型效能。
在低精度訓練中,前向傳播、後向傳播和權重更新都以低精度資料型別(例如 BF16 或 FP8)執行。然而,低精度下的權重更新在數值上可能不穩定。
作為替代方案,混合精度訓練在高精度(FP32)下進行權重更新,僅將低精度(例如 BF16)用於前向傳播和後向傳播。此外,一些層(例如歸一化層)也以 FP32 執行操作以保持數值穩定性。
為了在 Opacus 中啟用混合精度訓練,我們添加了邏輯來處理啟用和反向傳播具有不同精度型別時(如圖 1 中的兩個綠色框所示)的每個樣本梯度的計算。此邏輯在計算每個樣本梯度的函式中實現(例如,此處)。
圖 1. 混合精度訓練的前向和後向傳播。LayerNorm 前向傳播以全精度進行。線性層操作(以及大多數其他層)以低精度進行。一個層的輸出是下一個層的輸入。

圖 2. 混合精度下的權重更新。權重始終以全精度儲存。反向傳播被轉換為全精度。

如何在 Opacus 中使用混合精度和低精度訓練
在 Opacus 中,只需幾行額外的程式碼即可實現低精度和混合精度訓練。它看起來與非隱私訓練非常相似。請記住,Opacus 將模型、最佳化器和資料載入器等訓練元件封裝到 PrivacyEngine 中,PrivacyEngine 是該庫的主要介面。此後,訓練迴圈與原生 PyTorch 相同。
低精度訓練
與 Opacus 的全精度訓練相比,我們只需要:
- 在訓練開始前將模型權重轉換為低精度,以及
- 將輸入轉換為低精度。
from opacus import PrivacyEngine # cast model weights to lower precision before training model = model.to(torch.bfloat16) model.train() privacy_engine = PrivacyEngine() model, optimizer, dataloader = privacy_engine.make_private( module=model, optimizer=optimizer, data_loader=dataloader, noise_multiplier=noise_multiplier max_grad_norm=max_grad_norm ) for x, y in train_loader: # cast input to lower precision # integer inputs should stay as integers # (if y is a float, y should also be cast) if x.is_floating(): x = x.to(torch.bfloat16) # proceed with training step as usual output = model(x) optimizer.zero_grad() loss = criterion(output, y) loss.backward() optimizer.step()
混合精度訓練
PyTorch 透過 torch.amp 包支援混合精度訓練,我們也在利用它。前向傳播和損失計算在上下文內,而後向傳播應在上下文之外。這裡的主要變化是添加了 torch.amp 上下文。
from opacus import PrivacyEngine privacy_engine = PrivacyEngine() model, optimizer, dataloader = privacy_engine.make_private( module=model, optimizer=optimizer, data_loader=dataloader, noise_multiplier=noise_multiplier max_grad_norm=max_grad_norm ) for x, y in train_loader: # mixed precision training context for forward pass with torch.amp.context("cuda", dtype=torch.bfloat16): output = model(x) optimizer.zero_grad() loss = criterion(output, y) # backward pass is outside of amp context loss.backward() optimizer.step()
BERT 微調任務
我們實驗使用 SNLI 資料集微調預訓練的 BERT-base 模型(類似於 此 Opacus 教程)。我們考慮兩種常見的 DP-SGD 微調設定:
- 僅微調模型的最後幾層,同時凍結所有其他層,或
- 使用 LoRA(低秩自適應)微調所有層。
在第一種情況下,鑑於線性層的寬度很大,幽靈裁剪可以改善記憶體使用。在第二種情況下,由於 LoRA 的有效層寬度非常小,幽靈裁剪沒有用處。
我們僅使用 FP32、僅使用 BF16 或混合精度進行訓練。
我們發現,雖然非隱私訓練在所有精度設定下具有相同的效用,但使用 BF16 對最後幾層進行 DP-SGD 微調會導致效能下降。混合精度訓練可以彌補這種效用損失。透過 LoRA 微調,DP-SGD 在所有精度設定下都保持相同的效用。我們假設使用 DP-SGD 的低精度訓練在僅微調線性層時表現最佳,如 LoRA 的情況。然而,當涉及其他型別的層(例如歸一化層)時,它會損害效用,這些層通常需要高精度操作。因此,LoRA 是我們推薦的 DP-SGD 低/混合精度微調設定。
記憶體和速度改進
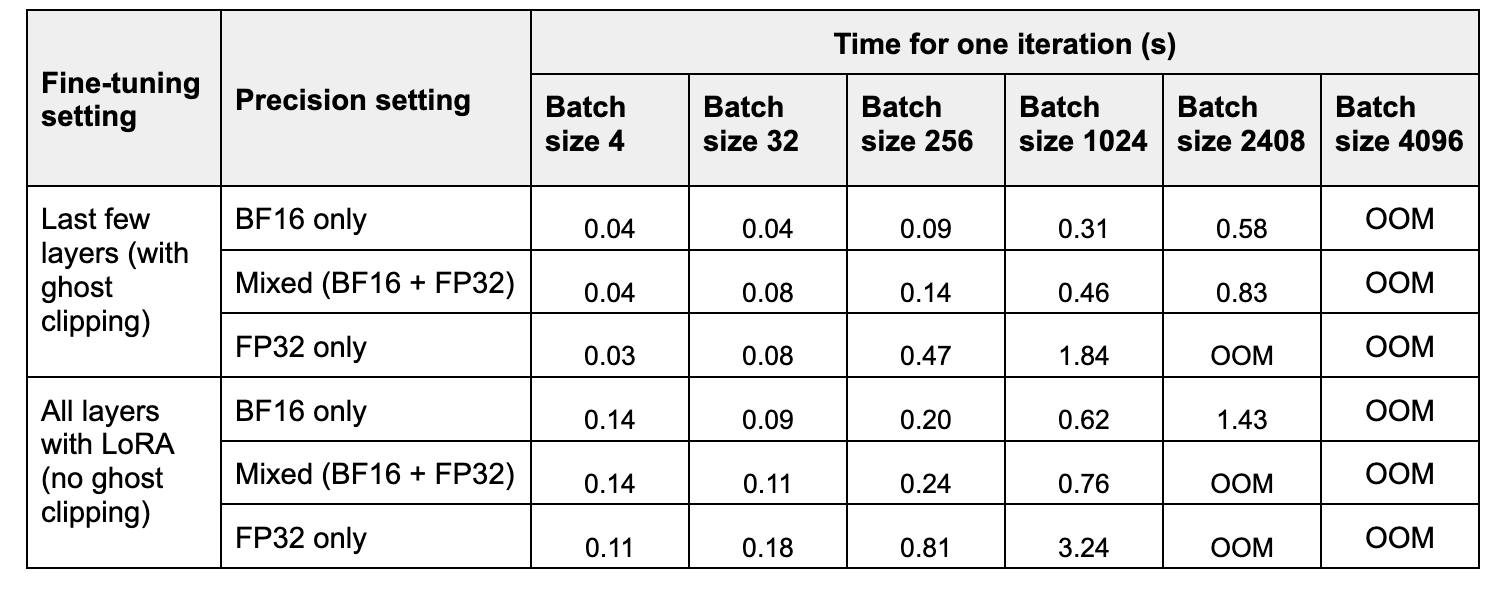
在表 2 中,我們比較了三種精度設定下一次前向和後向傳播的峰值記憶體和時間。與 FP32 相比,BF16 將峰值記憶體提高了 約 2 倍,而混合精度將其提高了 約 1.2-1.4 倍。請注意,在小批次大小下,混合精度可能比 FP32 使用更多記憶體,因為模型權重以低精度和高精度儲存兩次。
在表 2 中,我們比較了三種精度設定下一次訓練步驟的時間。與 FP32 相比,BF16 的加速隨著批次大小的增加而增加,範圍從 約 2 倍到約 6 倍。混合精度訓練的加速範圍從 約 1 倍到約 4 倍。
實驗在配備 40GB 記憶體的 A100 GPU 上進行。
表 1. 隨著批次大小增加,一次迭代(前向+後向傳播)的峰值記憶體。
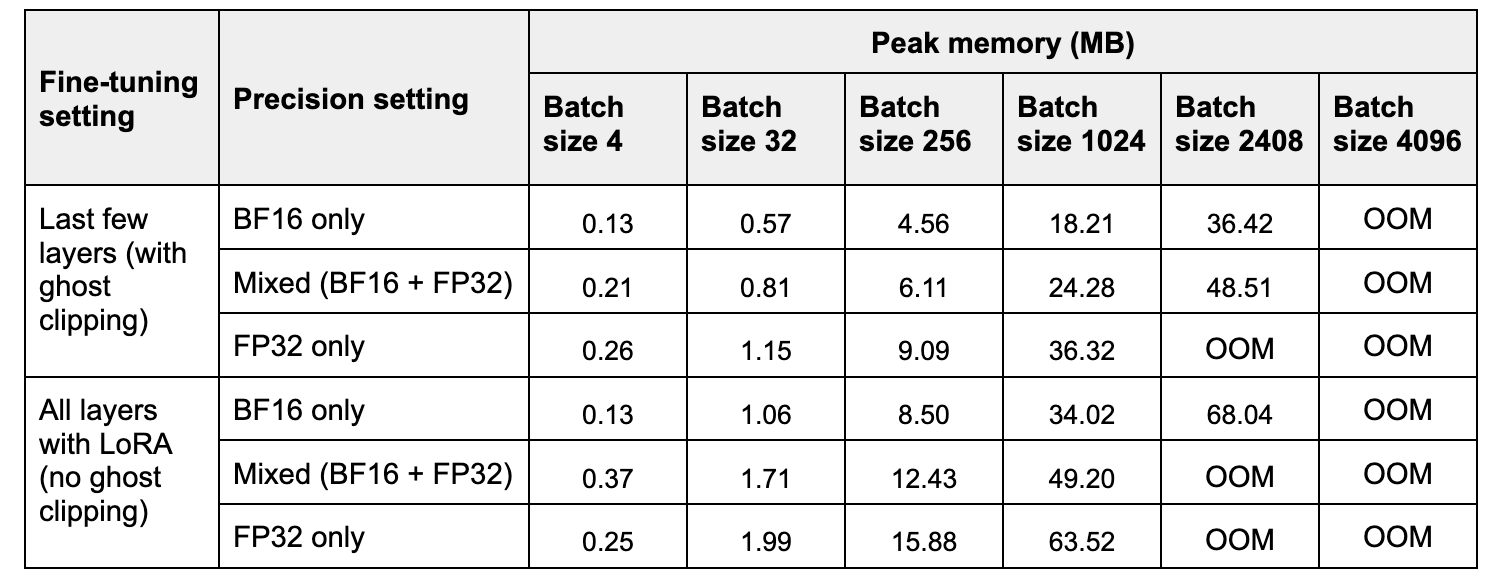
表 2. 隨著批次大小增加,一次迭代的執行時間(平均 10 次執行)。
對效用的影響
我們訓練一個 epoch,並測量在該 epoch 期間達到的最大測試集準確率。我們對 5 次執行的最大準確率進行平均。
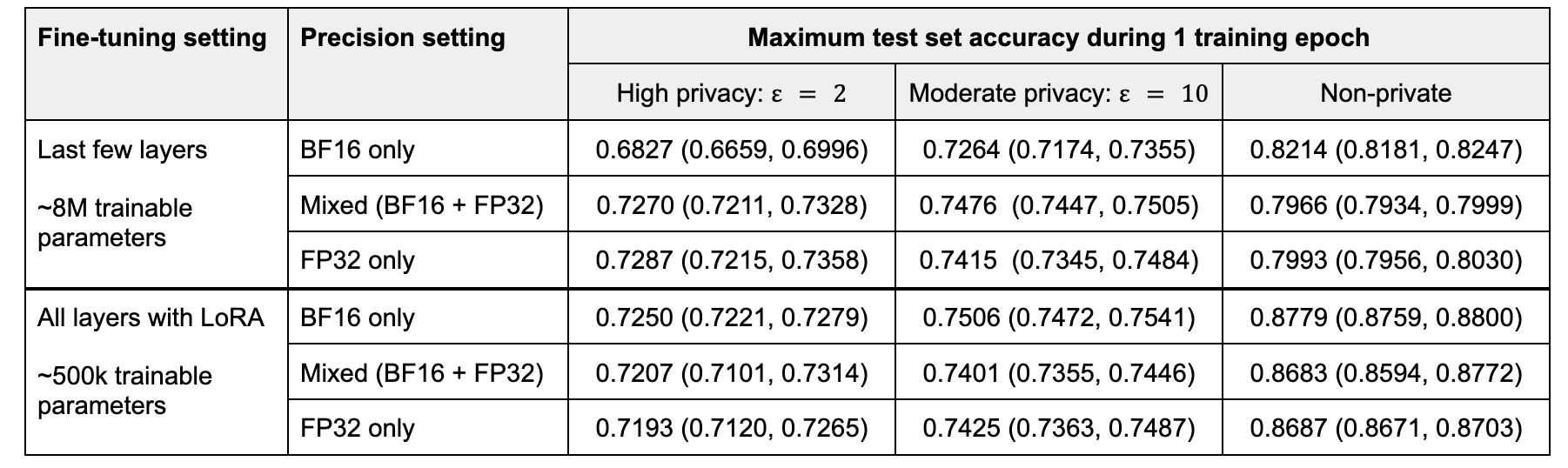
在微調最後幾層時,混合精度和 FP32 訓練的效能不相上下,而低精度訓練會導致效用顯著下降。隨著隱私預算的增加,效用差距縮小。在非隱私情況下,低精度訓練似乎有助於提高效能,這可能是由於噪聲矩陣操作的正則化效應抵消了過擬合。
透過 LoRA 微調,BF16 實現了最高的準確率,BF16 的優勢隨著隱私預算的增加而增加。混合精度和高精度訓練的效能不相上下。
我們假設使用 DP-SGD 的低精度訓練在僅微調線性層時表現最佳,如 LoRA。當微調涉及其他型別的層(例如歸一化層,它們通常需要高精度操作)時,它會損害效用。
表 3. 在不同隱私級別下,5 次執行平均的測試集準確率。批次大小 = 32。
行業用例
我們實驗使用 DP-SGD 和 LoRA(約 7M 可訓練引數)微調一個具有 8B 引數的大型語言模型。與 FP32 訓練相比,BF16 將每秒處理的樣本數提高了 3.4 倍,而混合精度提高了 1.1 倍。我們在所有精度設定下都實現了相近的損失和損失收斂速度。
結論
我們已將一種流行的訓練大型模型的通用技術整合到 Opacus 中,進一步增強了 Opacus 應對隱私訓練挑戰的能力。藉助混合精度和低精度,Opacus 實現了更高的吞吐量和更大的批處理大小訓練。我們的初步實驗表明,這可以在不犧牲效用的情況下實現。我們還提供了一些關於哪種精度型別最適合不同微調設定的見解。我們邀請開發人員和研究社群嘗試這項新功能,並提供關於 DP-SGD 在混合精度和低精度設定下的效用效能的進一步結果。
要了解有關 Opacus 的更多資訊,請訪問 opacus.ai 和 github.com/pytorch/opacus。