最近的研究表明,大型模型訓練將有助於提高模型質量。在過去 3 年中,模型規模增長了 10,000 倍,從引數量為 1.1 億的 BERT 增長到萬億引數的 Megatron-2。然而,訓練大型 AI 模型並非易事——除了需要大量的計算資源外,軟體工程的複雜性也極具挑戰性。PyTorch 一直致力於構建工具和基礎設施來簡化這一過程。
PyTorch 分散式資料並行因其魯棒性和簡潔性而成為可擴充套件深度學習的主力。然而,它要求模型能夠適應單個 GPU。最近的方法,如 DeepSpeed ZeRO 和 FairScale 的全分片資料並行,允許我們透過在資料並行 worker 之間分片模型的引數、梯度和最佳化器狀態來打破這一障礙,同時仍然保持資料並行的簡潔性。
PyTorch 1.11 新增了對全分片資料並行 (FSDP) 的原生支援,目前作為原型功能提供。其實現大量借鑑了 FairScale 的版本,同時帶來了更精簡的 API 和額外的效能改進。
PyTorch FSDP 在 AWS 上的擴充套件測試表明,它可以擴充套件到訓練具有萬億引數的密集模型。在我們的實驗中,對於 GPT 1T 模型,每塊 A100 GPU 實現了 84 TFLOPS 的效能;對於 GPT 175B 模型,每塊 A100 GPU 實現了 159 TFLOPS 的效能,均在 AWS 叢集上。與 FairScale 的原始版本相比,在啟用 CPU 解除安裝時,原生 FSDP 實現也顯著縮短了模型初始化時間。
在未來的 PyTorch 版本中,我們將允許使用者在 DDP、ZeRO-1、ZeRO-2 和 FSDP 等資料並行模式之間無縫切換,以便使用者可以在統一的 API 中透過簡單的配置來訓練不同規模的模型。
FSDP 的工作原理
FSDP 是一種資料並行訓練,但與傳統的每個 GPU 維護模型引數、梯度和最佳化器狀態副本的資料並行不同,它將所有這些狀態分片到資料並行 worker 中,並且可以選擇將分片的模型引數解除安裝到 CPU。
下圖展示了 FSDP 如何處理 2 個數據並行程序
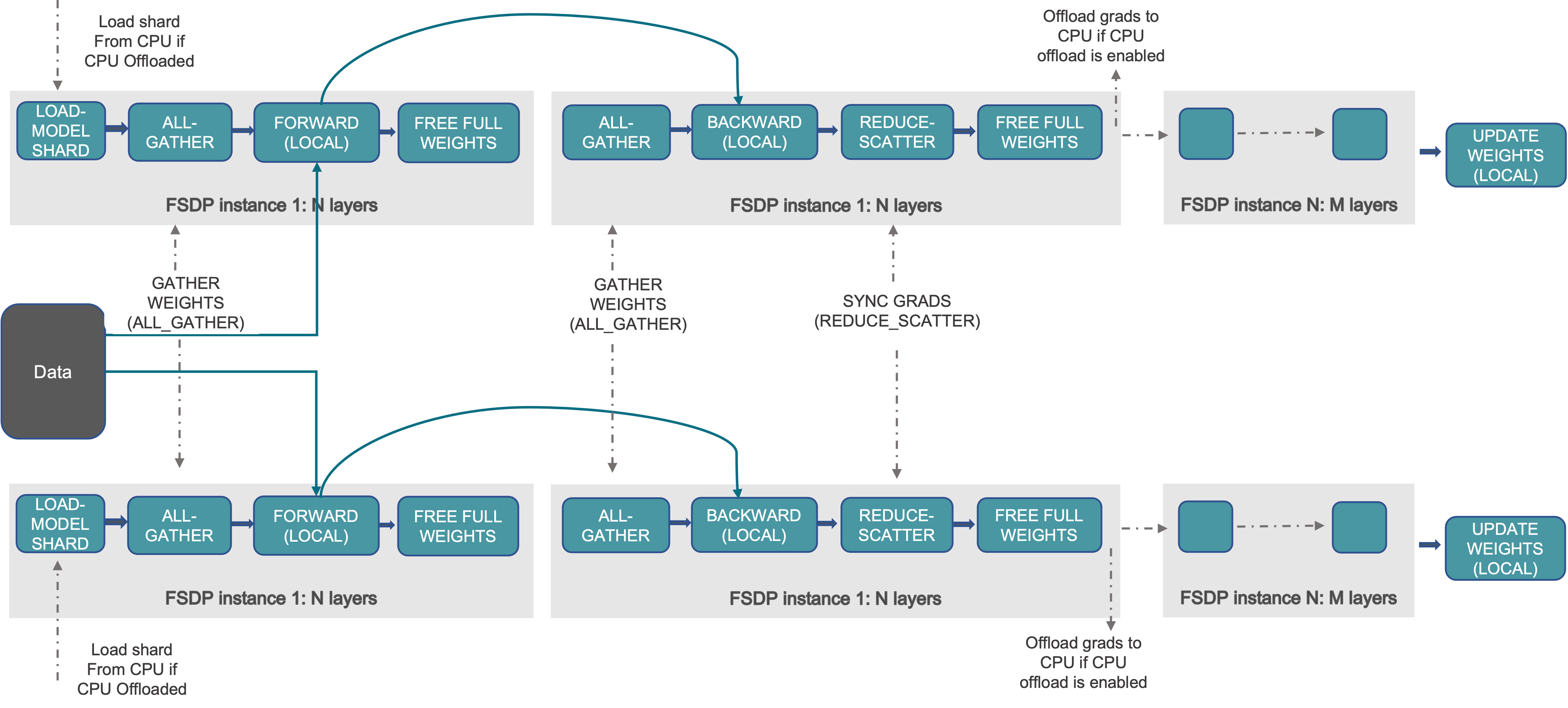
圖 1. FSDP 工作流程
通常,模型層以巢狀方式用 FSDP 包裝,以便在正向或反向計算期間,單個 FSDP 例項中的層才需要將完整引數收集到單個裝置。收集到的完整引數將在計算後立即釋放,釋放的記憶體可用於下一層的計算。透過這種方式,可以節省峰值 GPU 記憶體,從而使訓練能夠擴充套件到使用更大的模型尺寸或更大的批次大小。為了進一步最大化記憶體效率,當例項在計算中不活動時,FSDP 可以將引數、梯度和最佳化器狀態解除安裝到 CPU。
在 PyTorch 中使用 FSDP
有兩種方法可以用 PyTorch FSDP 包裝模型。自動包裝是 DDP 的即插即用替代品;手動包裝需要對模型定義程式碼進行最小的更改,並能夠探索複雜的 sharding 策略。
自動包裝
模型層應以巢狀方式包裝在 FSDP 中,以節省峰值記憶體並實現通訊和計算重疊。最簡單的方法是自動包裝,它可以作為 DDP 的即插即用替代品,而無需更改其餘程式碼。
fsdp_auto_wrap_policy 引數允許指定一個可呼叫函式來遞迴地用 FSDP 包裝層。PyTorch FSDP 提供的 default_auto_wrap_policy 函式遞迴地包裝引數數量大於 1 億的層。您可以根據需要提供自己的包裝策略。編寫自定義包裝策略的示例顯示在 FSDP API 文件中。
此外,可以可選地配置 cpu_offload 以在計算中不使用這些引數時將包裝的引數解除安裝到 CPU。這可以進一步提高記憶體效率,但代價是主機和裝置之間的資料傳輸開銷。
下面的示例展示瞭如何使用自動包裝來包裝 FSDP。
from torch.distributed.fsdp import (
FullyShardedDataParallel,
CPUOffload,
)
from torch.distributed.fsdp.wrap import (
default_auto_wrap_policy,
)
import torch.nn as nn
class model(nn.Module):
def __init__(self):
super().__init__()
self.layer1 = nn.Linear(8, 4)
self.layer2 = nn.Linear(4, 16)
self.layer3 = nn.Linear(16, 4)
model = DistributedDataParallel(model())
fsdp_model = FullyShardedDataParallel(
model(),
fsdp_auto_wrap_policy=default_auto_wrap_policy,
cpu_offload=CPUOffload(offload_params=True),
)
手動包裝
手動包裝透過對模型某些部分選擇性地應用 wrap 來探索複雜的 sharding 策略可能很有用。整體設定可以傳遞給 enable_wrap() 上下文管理器。
from torch.distributed.fsdp import (
FullyShardedDataParallel,
CPUOffload,
)
from torch.distributed.fsdp.wrap import (
enable_wrap,
wrap,
)
import torch.nn as nn
from typing import Dict
class model(nn.Module):
def __init__(self):
super().__init__()
self.layer1 = wrap(nn.Linear(8, 4))
self.layer2 = nn.Linear(4, 16)
self.layer3 = wrap(nn.Linear(16, 4))
wrapper_kwargs = Dict(cpu_offload=CPUOffload(offload_params=True))
with enable_wrap(wrapper_cls=FullyShardedDataParallel, **wrapper_kwargs):
fsdp_model = wrap(model())
使用上述兩種方法之一用 FSDP 包裝模型後,可以像本地訓練一樣訓練模型,如下所示
optim = torch.optim.Adam(fsdp_model.parameters(), lr=0.0001)
for sample, label in next_batch():
out = fsdp_model(input)
loss = criterion(out, label)
loss.backward()
optim.step()
基準測試結果
我們使用 PyTorch FSDP 在 AWS 叢集上對 175B 和 1T GPT 模型進行了廣泛的擴充套件測試。每個叢集節點都是一個例項,配備 8 塊 NVIDIA A100-SXM4-40GB GPU,節點間透過 AWS Elastic Fabric Adapter (EFA) 連線,網路頻寬為 400 Gbps。
GPT 模型使用 minGPT 實現。基準測試目的是使用隨機生成的資料集。所有實驗均以 5 萬詞彙量、fp16 精度和 SGD 最佳化器執行。
| 模型 | 層數 | 隱藏層大小 | 注意力頭 | 模型大小,數十億引數 |
|---|---|---|---|---|
| GPT 175B | 96 | 12288 | 96 | 175 |
| GPT 1T | 128 | 25600 | 160 | 1008 |
除了在實驗中使用帶有引數 CPU 解除安裝的 FSDP 外,測試中還應用了 PyTorch 中的 啟用檢查點功能。
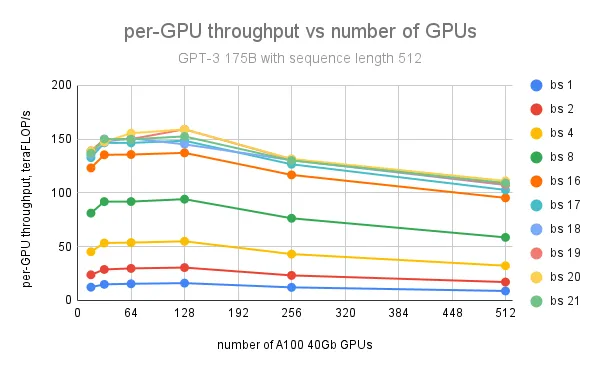
對於 GPT 175B 模型,在使用 128 個 GPU、批次大小為 20、序列長度為 512 的情況下,實現了每 GPU 最大吞吐量 159 teraFLOP/s(NVIDIA A100 峰值理論效能 312 teraFLOP/s/GPU 的 51%);進一步增加 GPU 數量會導致每 GPU 吞吐量下降,原因是節點間通訊量增加。
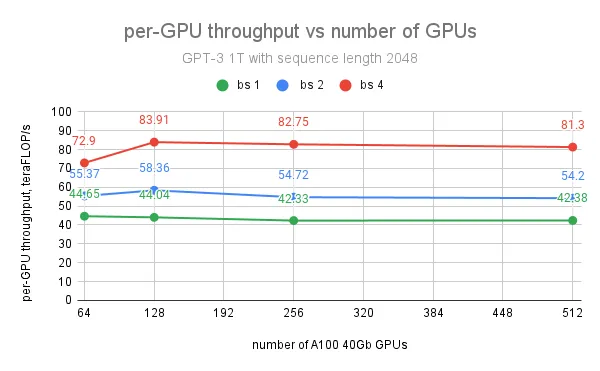
對於 GPT 1T 模型,在使用 128 個 GPU、批次大小為 4、序列長度為 2048 的情況下,實現了每 GPU 最大吞吐量 84 teraFLOP/s(峰值 teraFLOP/s 的 27%)。然而,進一步增加 GPU 數量對每 GPU 吞吐量的影響不大,因為我們觀察到 1T 模型訓練的最大瓶頸不是來自通訊,而是當峰值 GPU 記憶體達到限制時緩慢的 CUDA 快取分配器。使用記憶體容量更大的 A100 80G GPU 將主要解決這個問題,並有助於擴充套件批次大小以實現更大的吞吐量。
未來工作
在下一個 Beta 版本中,我們計劃新增高效的分散式模型/狀態檢查點 API、用於大型模型具體化的元裝置支援,以及 FSDP 計算和通訊中的混合精度支援。我們還將使其更容易在新 API 中在 DDP、ZeRO1、ZeRO2 和 FSDP 資料並行模式之間切換。為了進一步提高 FSDP 效能,還計劃減少記憶體碎片和改進通訊效率。
FSDP 兩個版本的歷史
FairScale FSDP 於 2021 年初作為 FairScale 庫的一部分發布。然後,我們開始努力將 FairScale FSDP 上游到 PT 1.11 中的 PyTorch,使其達到生產就緒狀態。我們有選擇地將 FairScale FSDP 中的關鍵功能上游和重構,重新設計了使用者介面並進行了效能改進。
在不久的將來,FairScale FSDP 將保留在 FairScale 儲存庫中用於研究專案,而通用且廣泛採用的功能將逐步上游到 PyTorch 並進行相應的強化。
同時,PyTorch FSDP 將更專注於生產就緒和長期支援。這包括更好地與生態系統整合以及在效能、可用性、可靠性、可除錯性和可組合性方面的改進。
致謝
我們感謝 FairScale FSDP 的作者:Myle Ott、Sam Shleifer、Min Xu、Priya Goyal、Quentin Duval、Vittorio Caggiano、Tingting Markstrum、Anjali Sridhar。感謝 Microsoft DeepSpeed ZeRO 團隊開發和推廣了分片資料並行技術。感謝 Pavel Belevich、Jessica Choi、Sisil Mehta 在不同叢集上使用 PyTorch FSDP 執行實驗。感謝 Geeta Chauhan、Mahesh Yadav、Pritam Damania、Dmytro Dzhulgakov 對這項工作的支援和富有洞察力的討論。