在這篇部落格中,我們展示了 FSDP 在預訓練示例中的可擴充套件性,一個針對 2T 令牌進行訓練的 7B 模型,並分享了我們用於實現 3,700 令牌/秒/GPU 的快速訓練速度(或在 128 個 A100 GPU 上每天 40B 令牌)的各種技術。這相當於 57% 的模型 FLOPs 利用率 (MFU) 和硬體 FLOPs 利用率 (HFU)。此外,我們觀察到 FSDP 近乎線性擴充套件到 512 個 GPU,這意味著使用這種方法在 512 個 GPU 上訓練一個 7B 模型到 2T 令牌只需不到兩週的時間。
IBM 研究人員訓練了一個 Meta Llama 2 7B 架構,針對 2T 令牌,我們將其稱為 LlamaT(est)。該模型在各種學術基準測試中表現出與 Llama 2 相當的模型質量。所有訓練程式碼以及我們實現此吞吐量的方法都可以在此部落格中找到。我們還分享了適用於 A100 和 H100 的 Llama 2 模型(7B、13B、34B 和 70B)的配置引數。
在此過程中,我們還提出了一種適用於 FSDP 的_新的_選擇性啟用檢查點機制,它在開箱即用 FSDP 的基礎上提供了 10% 的提升。我們已經開源了訓練程式碼庫以及相關的可擴充套件資料載入器,作為實現此吞吐量的方法。
PyTorch 原生訓練路徑的一個主要優勢是能夠無縫地在多個硬體後端上進行訓練。例如,AllenAI 透過 OLMo 釋出的最新端到端訓練堆疊也利用 PyTorch FSDP 在 AMD 和 NVIDIA GPU 上進行訓練。我們從 FSDP 中利用了三個主要元件來實現我們的吞吐量:
- SDPA Flash attention,可實現融合注意力核心和高效注意力計算
- 計算與通訊的重疊,可以更好地利用 GPU
- 選擇性啟用檢查點,使我們能夠在 GPU 記憶體和計算之間進行權衡
IBM 在PyTorch FSDP上與 Meta PyTorch 團隊密切合作了近兩年:引入速率限制器以在乙太網互連上實現更好的吞吐量,分散式檢查點將檢查點時間提高了一個數量級,併為 FSDP 的混合分片模式實現了早期版本的檢查點。去年底,我們使用 FSDP 對一個模型進行了端到端訓練。
訓練詳情
7B 模型在 128 個 A100 GPU 上訓練,具有 400Gbps 網路連線和 GPU Direct RDMA。我們使用 SDPA FlashAttention v2 進行注意力計算,對於這個模型,我們關閉了限制批處理大小但提供最高吞吐量的啟用檢查點——對於 128 個 GPU,每個批次的批處理大小為 100 萬個令牌,與啟用檢查點相比,吞吐量提高了約 10%。透過這些引數,我們實現了計算和通訊的幾乎完全重疊。我們使用 32 位 AdamW 最佳化器,beta1 為 0.9,beta2 為 0.95,權重衰減為 0.1,學習率以 3e-5 結束,預熱到最大學習率 3e-4,並採用餘弦排程在 2T 令牌上降低到 3e-5。訓練使用混合精度 bf16 在內部資料集上進行。訓練堆疊使用 IBM 的基礎模型堆疊用於模型架構,以及 PyTorch 2.2 釋出後的 nightly 版本用於 FSDP 和 SDPA。我們在 2023 年 11 月至 2024 年 2 月期間嘗試了幾種不同的 nightly 版本,並觀察到吞吐量的改善。
選擇性啟用檢查點
我們共同實現了一種簡單有效的選擇性啟用檢查點 (AC) 機制。在 FSDP 中,常見的做法是檢查點每個 Transformer 塊。一個簡單的擴充套件是每_n_個塊檢查點一次,以減少重新計算量,同時增加所需的記憶體。這對於 13B 模型大小非常有效,吞吐量增加了 10%。對於 7B 模型大小,我們根本不需要啟用檢查點。FSDP 的未來版本將提供運算子級別的選擇性啟用檢查點,從而實現計算-記憶體的最佳權衡。上述程式碼的實現可以在這裡找到。
吞吐量和 MFU、HFU 計算
雖然我們只訓練了 7B 模型到 2T 令牌,但我們對其他模型大小進行了大量實驗,以提供最佳配置選項。下表總結了兩種基礎設施型別——具有 128 個 GPU 和 400Gbps 節點間互連的 A100 叢集,以及具有 96 個 GPU 和 800Gbps 節點間互連的 H100 叢集。
| 模型大小 | 批次大小 | 啟用檢查點 | 吞吐量令牌/秒/GPU(A100 80GB 和 400Gbps 互連) | MFU % (A100 80GB) | HFU % (A100 80GB) | 吞吐量令牌/秒/GPU(H100 80GB 和 800Gbps 互連) | MFU % (H100 80GB) | HFU % (H100 80GB) |
| 7B | 2 | 否 | 3700 | 0.57 | 0.57 | 7500 | 0.37 | 0.37 |
| 13B | 2 | 選擇性 | 1800 | 0.51 | 0.59 | 3800 | 0.35 | 0.40 |
| 34B | 2 | 是 | 700 | 0.47 | 0.64 | 1550 | 0.32 | 0.44 |
| 70B | 2 | 是 | 370 | 0.50 | 0.67 | 800 | 0.34 | 0.45 |
表 1:各種模型大小在 A100 和 H100 GPU 上的模型和硬體 FLOPS 利用率
HFU 數字使用PyTorch FLOP 計算器和 A100 和 H100 GPU 的理論 bf16 效能計算,而 MFU 數字使用NanoGPT和PaLM 論文中概述的方法計算。我們還注意到,對於較大的模型,我們有意將每個 GPU 的批處理大小保持在 2,以模仿訓練 4k 序列長度模型時所做的選擇,並在不超過 4M 令牌的流行批處理大小的情況下,在多達 512 個 GPU 上實現這一點。超出此範圍,我們將需要張量並行或序列並行。
我們注意到上表中,對於 A100,啟用重新計算會導致 MFU 降低,而 HFU 增加!隨著更好的啟用檢查點方案的引入,我們期望 MFU 能夠增加並趕上 HFU。然而,我們觀察到對於 H100,MFU 和 HFU 都相對較低。我們分析了 H100 上的 PyTorch 配置檔案跟蹤,並觀察到由於網路“窺探”而導致 10% 的差距。此外,我們推測 H100 的 HBM 頻寬是導致 H100 上 HFU/MFU 降低的原因,並且無法獲得 3 倍的改進(H100 在理論上比 A100 快 3 倍——312 vs 989TFLOPS,但 HBM 頻寬僅為 A100 的不到 2 倍——2.0 vs 3.35TBps)。我們計劃嘗試其他配置選項,如張量並行,以改進 H100 上 70B 模型的引數。
模型詳情
訓練的損失曲線如下圖所示。
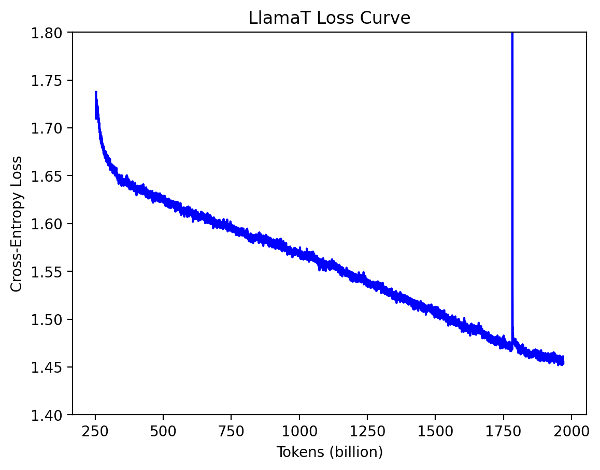
圖 1:LlamaT 訓練損失曲線
2T 檢查點透過儲存庫中提供的指令碼轉換為 Hugging Face 格式,然後我們使用lm-evaluation-harness計算關鍵學術基準,並將其與在 Llama2-7B 上執行的結果進行比較。這些結果已捕獲在下表中。
| 評估指標 | Llama2-7B (基線) | LlamaT-7B |
| MMLU (零樣本) | 0.41 | 0.43 |
| MMLU (5 樣本加權平均) | 0.47 | 0.50 |
| Arc challenge | 0.46 | 0.44 |
| Arc easy | 0.74 | 0.71 |
| Boolq | 0.78 | 0.76 |
| Copa | 0.87 | 0.83 |
| Hellaswag | 0.76 | 0.74 |
| Openbookqa | 0.44 | 0.42 |
| Piqa | 0.79 | 0.79 |
| Sciq | 0.91 | 0.91 |
| Winogrande | 0.69 | 0.67 |
| Truthfulqa | 0.39 | 0.39 |
| GSM8k (8 樣本) | 0.13 | 0.11 |
表 1:LM 評估 harness 分數
我們觀察到該模型與 Llama2 競爭激烈(粗體字表示更好)。
訓練歷程
訓練穩定,沒有崩潰,儘管我們確實遇到了一些小問題
0-200B 令牌:我們觀察到迭代時間(執行一個訓練步驟所需的時間)變慢。我們停止了作業以確保資料載入器沒有導致任何減速,並且檢查點效能良好且準確。我們沒有發現任何問題。此時,PyTorch 中已經提供了 HSDP 檢查點程式碼,我們藉此機會切換到 PyTorch 檢查點程式碼。
200B 令牌-1.9T:我們在 12 月底沒有對作業進行任何手動干預。當我們 1 月初回來時,磁碟空間已超出限制,檢查點無法寫入,儘管訓練作業仍在繼續。最後一個已知檢查點是 1.5T。
1.5T-1.7T:我們使用 lm-evaluation-harness 評估了 1.5T 檢查點,發現由於 Hugging Face 分詞器引入了分隔符令牌,並且我們的資料載入器也附加了它自己的文件分隔符,模型在兩個文件之間多訓練了一個特殊令牌。我們修改了資料載入器以消除額外的特殊令牌,並從 1.7T 令牌開始使用修改後的資料載入器繼續訓練。
1.7T-2T:由於特殊令牌的改變,損失最初飆升,但很快在幾十億個令牌內恢復。訓練在沒有任何其他手動干預的情況下完成!
主要收穫和更高的速度
我們展示瞭如何使用 FSDP 訓練一個模型到 2T 令牌,效能出色,達到 3700 令牌/秒/GPU,並生成了一個高質量模型。作為此項工作的一部分,我們開源了所有訓練程式碼和實現此吞吐量的引數。這些引數不僅可以用於大規模執行,還可以用於小規模微調執行。您可以在這裡找到程式碼。
FSDP API 以 PyTorch 原生方式實現了ZeRO演算法,並允許對大型模型進行微調和訓練。過去,我們已經看到了 FSDP 的驗證點(Stanford Alpaca、Hugging Face、Llama 2 recipes),它們使用簡單的訓練迴圈對各種 LLM(如 Meta Llama 2 7B 到 70B Llama)進行微調,並實現了良好的吞吐量和訓練時間。
最後,我們注意到有幾個可以加速訓練的槓桿:
- 節點最佳化,可以加速特定操作(例如,使用 Flash Attention V2 進行注意力計算)
- 圖最佳化(例如,融合核心,torch.compile)
- 計算-通訊重疊
- 啟用重新計算
我們在這篇部落格中利用了 1、3 和 4 的一個變體,並正在與 Meta PyTorch 團隊密切合作,以獲取 torch.compile (2) 以及具有每個運算子選擇性啟用重新計算的更高階版本 4。我們計劃分享一個簡單的格式化程式碼和示例資料,以便攝取到我們的資料載入器中,從而使其他人能夠使用該程式碼庫進行模型訓練。
致謝
有幾個團隊參與了實現這一驗證點,我們要感謝 Meta 和 IBM 的各個團隊。特別地,我們向 PyTorch 分散式團隊、Facebook Research 和 Applied AI 團隊表示感謝,他們構建了FSDP API並根據我們的反饋進行了增強。我們還要感謝 IBM Research 的資料團隊,他們策劃了本次練習中使用的資料語料庫,以及 IBM Research 的基礎設施團隊(特別是 Claudia Misale、Shweta Salaria 和 Seetharami Seelam),他們優化了 NCCL 和網路配置。透過構建和利用所有這些元件,我們成功地展示了 LlamaT 的驗證點。
選擇性啟用檢查點由 IBM 的 Linsong Chu、Davis Wertheimer、Mudhakar Srivatsa 和 Raghu Ganti 構思,並由 Meta 的 Less Wright 實現。
特別感謝Stas Bekman和Minjia Zhang,他們提供了大量的反饋並幫助改進了這篇部落格。他們的見解對於突出訓練最佳化的關鍵方面和探索進一步的增強至關重要。
附錄
通訊計算重疊
在多節點設定中訓練的另一個關鍵方面是能夠重疊通訊和計算。在 FSDP 中,有多種重疊的機會——在正向傳播的 FSDP 單元收集階段以及反向傳播計算期間。在正向傳播期間重疊收集,同時計算前一個單元,以及在反向計算期間重疊下一個單元的收集和梯度分散,有助於將 GPU 利用率提高近 2 倍。我們將在 400Gbps 網路互連和 A100 80GB GPU 上說明這一點。在 HSDP 的情況下,正向傳播的預取階段沒有節點間流量,重疊僅用於反向梯度計算階段。當然,HSDP 只有在模型可以在單個節點內分片時才可行,這將模型大小限制在約 30B 引數左右。
下圖顯示了 FSDP 中的三個步驟,底部是節點之間的通訊,影像下半部分的頂部是計算流。對於沒有啟用重新計算的 7B 模型,我們觀察到重疊是完整的。實際上,可實現的重疊百分比為 90%,因為正向傳播的第一個塊和反向傳播的最後一個塊無法重疊。

下面顯示了上述三步過程的單個步驟的放大檢視。我們可以清楚地看到計算和通訊的粒度以及它們如何以交錯的方式重疊。
