審閱人: Yunsang Ju(Naver GplaceAI 負責人), Min Jean Cho(Intel), Jing Xu(Intel), Mark Saroufim(Meta)
引言
在此,我們將分享我們如何在不降低效能或質量的情況下,將 AI 工作負載從 GPU 伺服器遷移到 Intel CPU 伺服器的經驗,並在此過程中每年節省約 34 萬美元(請參閱結論)。
我們的目標是透過提供各種 AI 模型來增強線上到線下 (O2O) 體驗,從而為消費者創造價值。隨著新模型需求的持續增長以及高成本 GPU 資源的有限性,我們需要將相對輕量級的 AI 模型從 GPU 伺服器遷移到 Intel CPU 伺服器,以減少資源消耗。然而,在相同的設定下,CPU 伺服器存在 RPS、推理時間等效能下降數十倍的問題。我們應用了各種工程技術並對模型進行了輕量化,以解決此問題,併成功過渡到 Intel CPU 伺服器,僅透過三倍的橫向擴充套件就實現了與 GPU 伺服器相同或更好的效能。
有關我們團隊的更詳細介紹,請參閱 NAVER Place AI 開發團隊介紹。
我稍後還會再次提及,但在整個工作中,我從 Intel 和 PyTorch 撰寫的 從第一性原理理解 PyTorch Intel CPU 效能中獲得了大量幫助。
問題定義
1:服務架構
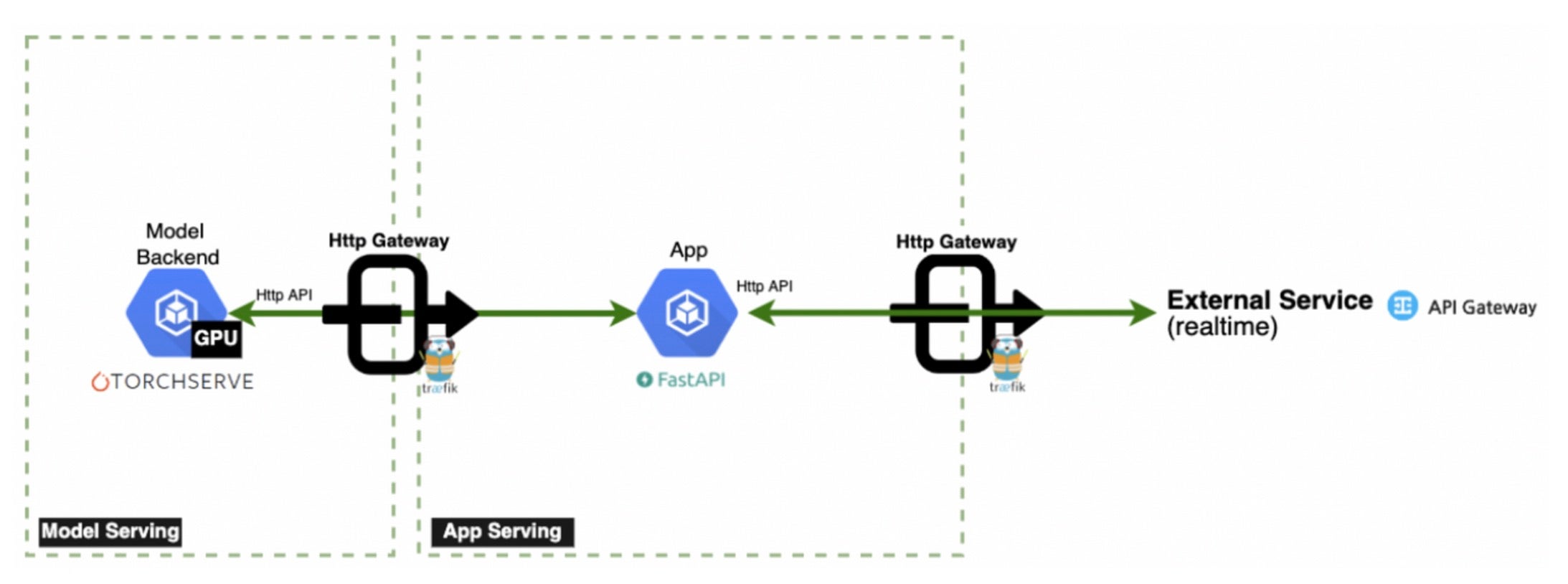
簡化服務架構(圖片來源: NAVER GplaceAI)
為了便於理解,將簡要介紹我們的服務架構。CPU 密集型任務,例如將輸入預處理為張量格式(然後轉發到模型)以及將推理結果後處理為人類可讀的輸出(例如自然語言和影像格式)在應用伺服器 (FastAPI) 上執行。模型伺服器 (TorchServe) 專門處理推理操作。為了服務的穩定執行,需要以足夠的吞吐量和低延遲執行以下操作。
具體的處理順序如下
- 客戶端透過 Traefik 閘道器嚮應用伺服器提交請求。
- 應用伺服器透過執行調整大小、轉換等操作對輸入進行預處理,並將其轉換為 Torch 張量,然後請求模型伺服器。
- 模型伺服器執行推理並將特徵返回給應用伺服器
- 應用伺服器通過後處理將特徵轉換為人類可理解的格式,並將其返回給客戶端
2: 吞吐量和延遲測量
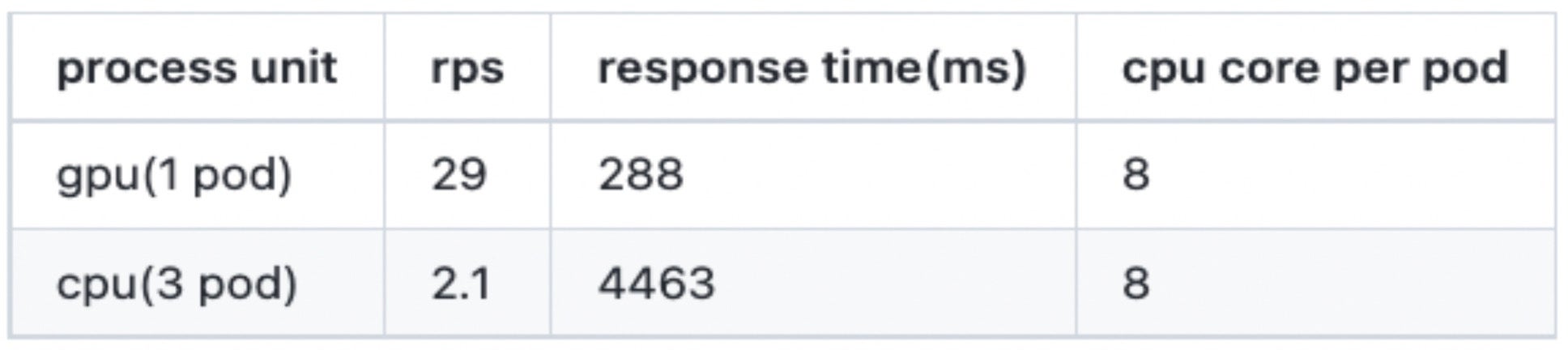
影像評分模型比較
在所有其他條件不變的情況下,部署在三倍數量的 CPU 伺服器 pod 上,但 RPS(每秒請求數)和響應時間卻顯著下降了十倍以上。雖然 CPU 推理效能不如 GPU 並不令人意外,但嚴峻的形勢顯而易見。考慮到在有限資源內保持效能的目標,在不進行額外擴充套件的情況下,需要實現大約 10 到 20 倍的效能提升。
3: 吞吐量方面的挑戰
Type Name # reqs # fails | Avg Min Max Med | req/s failures/s
--------|----------------------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
POST /predictions/image-scoring 37 0(0.00%) | 9031 4043 28985 8200 | 1.00 0.00
--------|----------------------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
Aggregated 37 0(0.00%) | 9031 4043 28985 8200 | 1.00 0.00
TorchServe 框架使用者提高吞吐量的首要步驟之一可能是增加 TorchServe 中的 worker 數量。這種方法在 GPU 伺服器上是有效的,因為並行工作負載處理,除了 worker 擴充套件時記憶體使用量線性增加。然而,我們發現在增加 worker 數量時效能反而下降了。識別 CPU 伺服器上效能下降的原因需要進一步調查。
4: 延遲方面的挑戰
我們主要關注的是延遲。通常,當系統實現忠實於橫向擴充套件原則時,吞吐量提升是可實現的,除了極少數最壞情況。然而,在影像評分模型的例子中,即使執行一次推理也需要超過 1 秒,並且隨著請求量的增加,延遲會增加到 4 秒。這是一種即使進行一次推理也無法滿足客戶端超時標準的情況。
提出的解決方案
需要從機器學習和工程角度進行改進。根本上縮短 CPU 上的推理時間至關重要,並且需要找出在應用通常能提高效能的配置時導致效能下降的原因,以找到最佳配置值。為此,我們與 MLE 專業人員合作,同時執行“在不損害效能的情況下對模型進行輕量化”和“確定實現最佳效能的最佳配置”等任務。透過上述方法,我們能夠有效地將工作負載處理轉移到我們的 CPU 伺服器。
1:從工程角度解決低 RPS 問題
首先,即使增加 worker 數量後效能仍然下降的原因是 GEMM 操作中邏輯執行緒導致的前端瓶頸。通常,當增加 worker 數量時,預期的改進效果是並行度的增加。相反,如果效能下降,則可以推斷出相應的權衡效應。
圖片來源: Nvidia
眾所周知,CPU 上模型推理效能不如 GPU 的原因在於硬體設計的差異,尤其是在多執行緒能力方面。深入來看,模型推理本質上是 GEMM(通用矩陣乘法)操作的重複,這些 GEMM 操作在 “融合乘加”(FMA)或 “點積”(DP)執行單元中獨立執行。如果 GEMM 操作成為 CPU 上的瓶頸,增加並行度實際上可能會導致效能下降。在研究問題時,我們在 PyTorch 文件中找到了相關資訊。
當兩個邏輯執行緒同時執行 GEMM 時,它們將共享相同的核心資源,導致前端瓶頸
此資訊強調了邏輯執行緒可能導致 CPU GEMM 操作中的瓶頸,這有助於我們直觀地理解為什麼增加 worker 數量時效能會下降。這是因為 torch 執行緒的預設值對應於 CPU 的物理核心值。
root@test-pod:/# lscpu
…
Thread(s) per core: 2
Core(s) per socket: 12
…
root@test-pod:/# python
>>> import torch
>>> print(torch.get_num_threads())
24
當 worker_num 增加時,匯流排程數增加,增加量為物理核心數 * worker 數量的乘積。因此,邏輯執行緒被利用。為了提高效能,每個 worker 的匯流排程數被調整為與物理核心數對齊。下面可以看到,當 worker_num 增加到 4 並且匯流排程數與物理核心數對齊時,RPS 指標大約增加了三倍,達到 6.3(從之前的 2.1)。
Type Name # reqs # fails | Avg Min Max Med | req/s failures/s
--------|----------------------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
POST /predictions/image-scoring 265 0(0.00%) | 3154 1885 4008 3200 | 6.30 0.00
--------|----------------------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
Aggregated 265 0(0.00%) | 3154 1885 4008 3200 | 6.30 0.00
注意事項 1:我們的團隊使用 Kubernetes 來維護我們的部署。因此,我們正在根據 pod 的 CPU 資源限制進行調整,而不是使用 lscpu 命令檢查到的節點的物理核心數。(將每個 worker 的 torch 執行緒設定為 8/4 = 2 或 24/4 = 6 會導致效能下降。)
注意事項 2:由於每個 worker 的 torch 執行緒設定只能配置為整數,因此建議將 CPU 限制設定為可被 worker_num 整除,以便充分利用 CPU 使用率。

例如)核心數=8,worker_num=3 的情況下:int(8/worker_num) = 2,2*worker_num/8 = 75%

例如)核心數=8,worker_num=4 的情況下:int(8/worker_num) = 2,2*worker_num/8 = 100%
我們還分析了模型容器,以瞭解為什麼在 worker 數量增加四倍的情況下,效能僅提高了三倍。我們監控了各種資源,其中核心利用率被認為是根本原因。
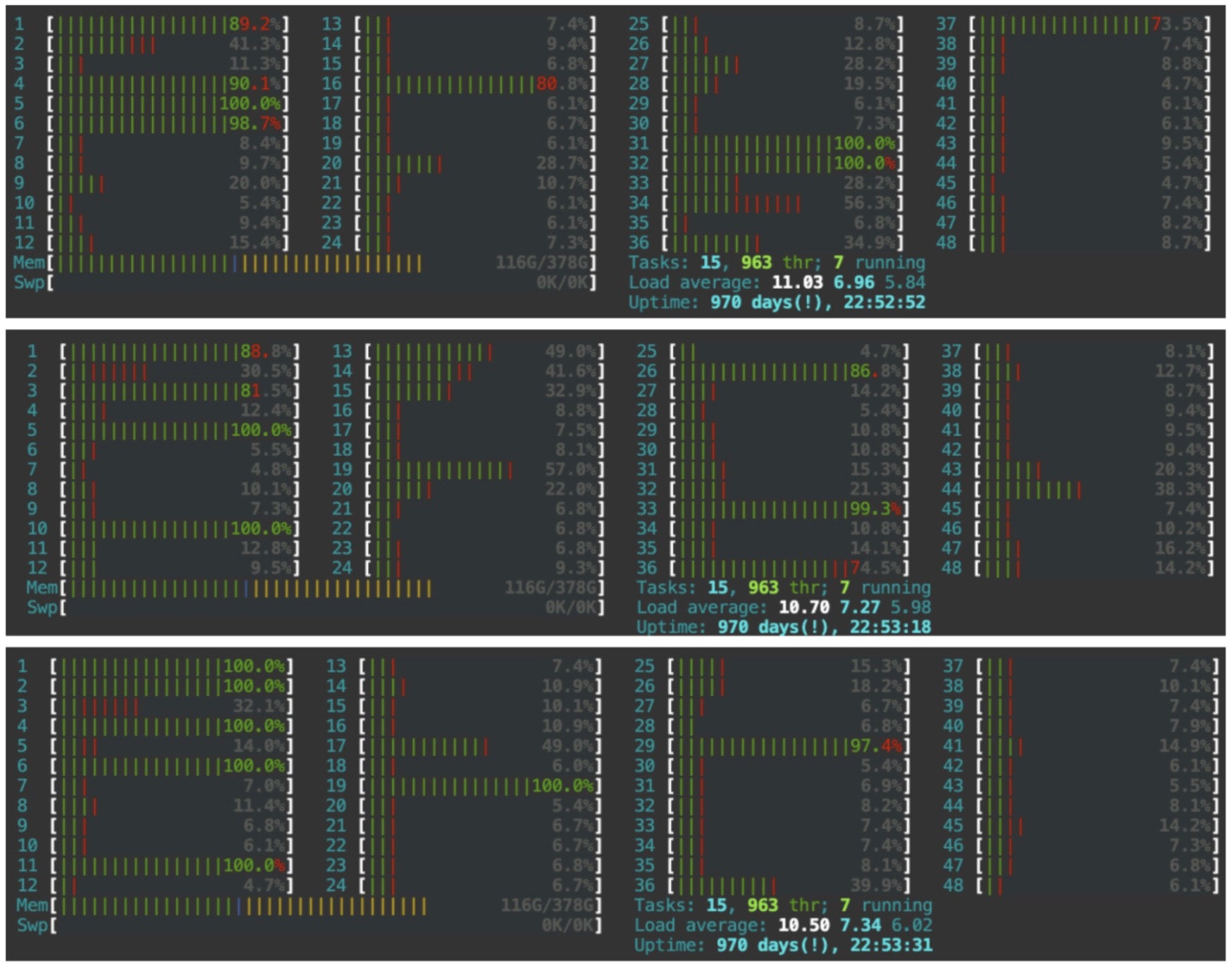
即使將匯流排程數調整為與 CPU(第二代 Intel(R) Xeon(R) Silver 4214)限制(8 核)匹配,也存在計算從邏輯執行緒到邏輯核心執行的情況。由於存在 24 個物理核心,編號 25 到 48 的核心被歸類為邏輯核心。將執行緒執行僅限於物理核心的可能性似乎提供了進一步提高效能的潛力。此解決方案的參考可以在 PyTorch-geometric 文章中提到的源文件中找到,該文章警告了 CPU GEMM 瓶頸。
根據文件中的說明,Intel 提供了 Intel® Extension for PyTorch,我們可以簡單地將核心固定到特定的插槽。應用方法也變得非常簡單,只需將以下設定新增到 torchserve config.properties 檔案中即可。(使用了 intel_extension_for_pytorch==1.13.0)
ipex_enable=true
CPU_launcher_enable=true
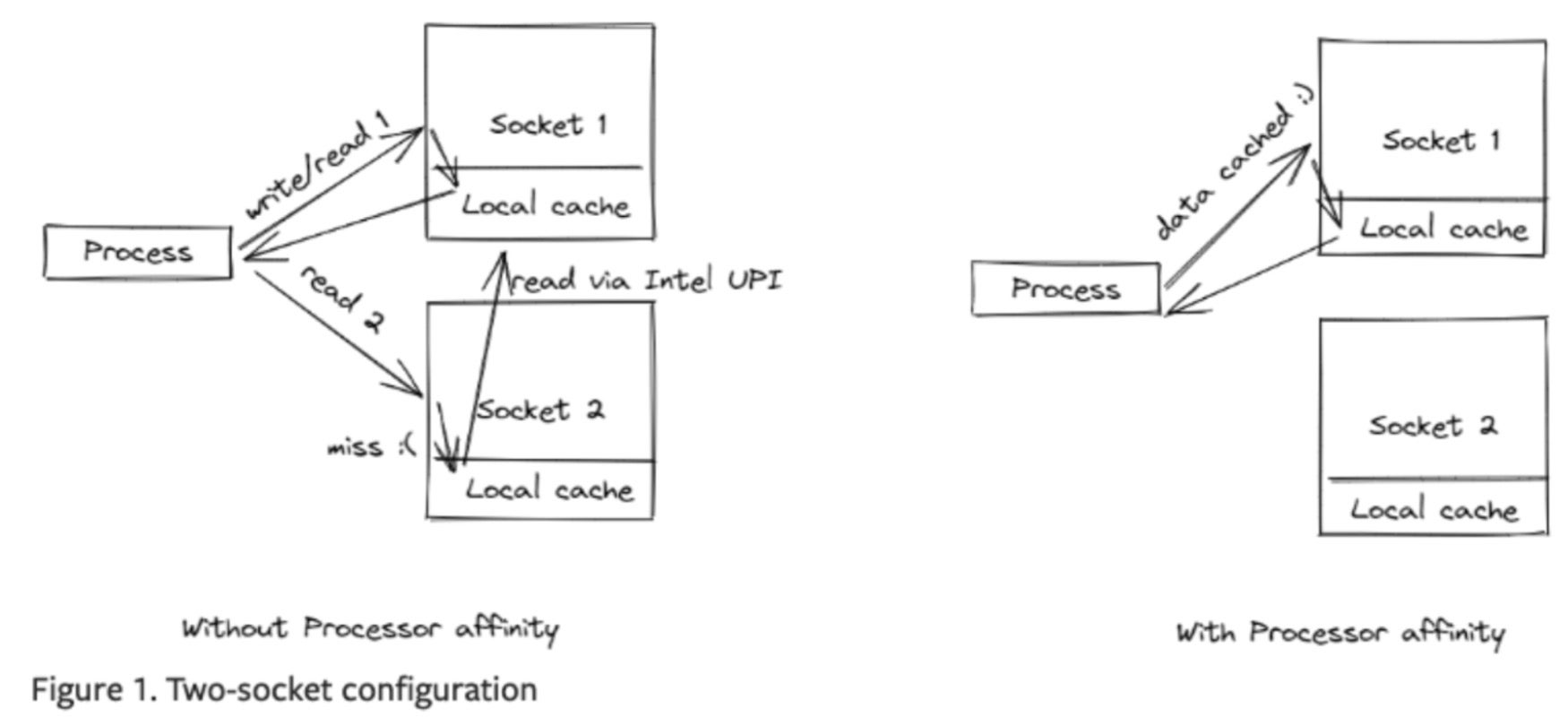
圖片來源: PyTorch
除了透過插槽繫結消除邏輯執行緒外,還有額外的好處是消除了 UPI 快取命中開銷。由於 CPU 包含多個插槽,當排程在插槽 1 上的執行緒重新排程到插槽 2 時,在透過 Intel Ultra Path Interconnect (UPI) 訪問插槽 1 的快取時會發生快取命中。此時,UPI 訪問本地快取的速度比本地快取訪問慢兩倍以上,從而導致更多的瓶頸。透過 oneAPI 驅動的 Intel® Extension for PyTorch 將執行緒繫結到插槽單元,我們觀察到 RPS 處理量比存在瓶頸時提高了四倍。
Type Name # reqs # fails | Avg Min Max Med | req/s failures/s
--------|----------------------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
POST /predictions/image-scoring 131 0(0.00%) | 3456 1412 6813 3100 | 7.90 0.00
--------|----------------------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
Aggregated 131 0(0.00%) | 3456 1412 6813 3100 | 7.90 0.00
注意事項 1:Intel® Extension for PyTorch 專注於神經網路(以下簡稱“nn”)推理最佳化,因此 nn 以外的其他技術的效能提升可能微乎其微。事實上,在作為示例的影像評分系統中,推理後應用了 svr(支援向量迴歸),效能提升僅限於 4 倍。然而,對於純粹的 nn 推理模型,例如食物識別模型,檢測到效能提升了 7 倍(2.5rps -> 17.5rps)。
Type Name # reqs # fails | Avg Min Max Med | req/s failures/s
--------|----------------------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
POST /predictions/food-classification 446 0(0.00%) | 1113 249 1804 1200 | 17.50 0.00
--------|----------------------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
Aggregated 446 0(0.00%) | 1113 249 1804 1200 | 17.50 0.00
注意事項 2:應用 Intel® Extension for PyTorch 需要 torchserve 版本 0.6.1 或更高版本。由於我們團隊使用的是 0.6.0 版本,因此存在插槽繫結無法正常工作的問題。目前,我們已修改了指導文件,指定了所需版本。
在 WorkerLifeCycle.java中,0.6.0 及以下版本不支援多 worker 繫結(ninstance 硬編碼為 1)
// 0.6.0 version
public ArrayList<String> launcherArgsToList() {
ArrayList<String> arrlist = new ArrayList<String>();
arrlist.add("-m");
arrlist.add("intel_extension_for_pytorch.cpu.launch");
arrlist.add(" — ninstance");
arrlist.add("1");
if (launcherArgs != null && launcherArgs.length() > 1) {
String[] argarray = launcherArgs.split(" ");
for (int i = 0; i < argarray.length; i++) {
arrlist.add(argarray[i]);
}
}
return arrlist;
}
// master version
if (this.numWorker > 1) {
argl.add(" — ninstances");
argl.add(String.valueOf(this.numWorker));
argl.add(" — instance_idx");
argl.add(String.valueOf(this.currNumRunningWorkers));
}
2:透過模型輕量化解決慢延遲問題
我們還使用 知識蒸餾(通常縮寫為 KD)簡化了我們的模型,以進一步減少延遲。眾所周知,知識蒸餾是一種技術,將來自較大網路(教師網路)的知識傳遞給較小、輕量級網路(學生網路),該網路資源密集度較低,可以更容易地部署。有關更多詳細資訊,請參閱最初引入此概念的論文,題為 “Distilling the Knowledge in a Neural Network”。
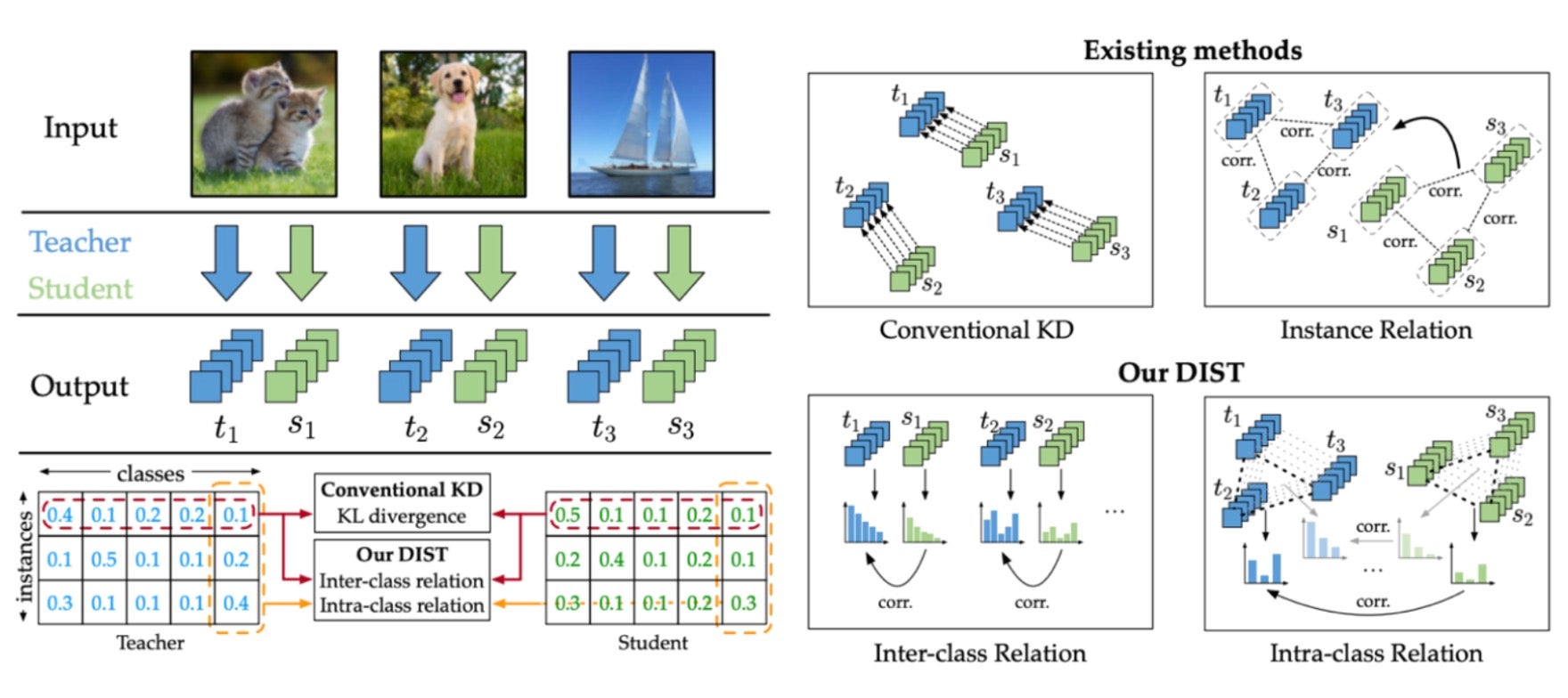
有多種知識蒸餾技術可用,由於我們主要關注準確性損失最小化,因此我們採用了 2022 年發表的論文“來自更強教師的知識蒸餾”中的方法。概念很簡單。與僅利用模型屬性值的傳統蒸餾方法不同,所選擇的方法涉及讓學生網路學習教師網路中類之間的相關性。在實際應用中,我們觀察到模型權重有效減少,同時保持高準確性。以下是我們使用上述知識蒸餾技術對幾個候選學生模型進行實驗的結果,其中根據保持的準確性水平進行了選擇。
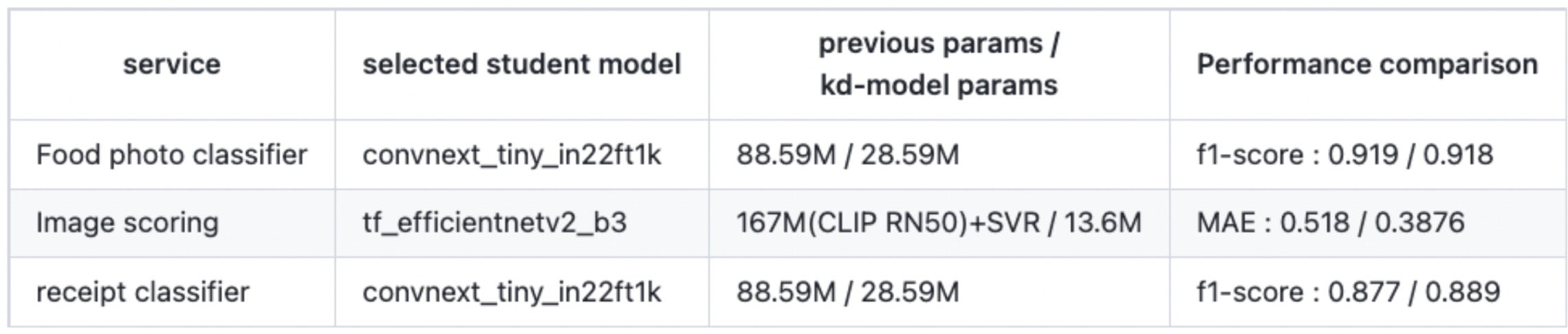
對於影像評分系統,我們採取了額外的措施來減小輸入大小。考慮到之前使用了基於 CPU 的機器學習技術 SVR(支援向量迴歸)(2 階段:CNN + SVR),即使將其簡化為 1 階段模型,在 CPU 推理中也沒有觀察到顯著的速度優勢。為了使簡化具有意義,學生模型在推理時的輸入大小需要進一步減小。因此,我們進行了實驗,將大小從 384*384 減小到 224*224。
為了進一步簡化轉換,我們將兩階段(CNN + SVR)方法統一為一個包含更大 ConvNext 的一階段模型,然後使用輕量級 EfficientNet 應用 kd 以解決準確性權衡問題。在實驗過程中,我們遇到了一個問題,即將 Img_resize 更改為 224 導致 MAE 從 0.4007 下降到 0.4296。由於輸入大小的減小,應用於原始訓練影像的各種預處理技術(例如 Affine、RandomRotate90、Blur、OneOf [GridDistortion、OpticalDistortion、ElasticTransform]、VerticalFlip)產生了反作用。透過採取這些措施,學生模型實現了有效的訓練,並且MAE 值比之前提高了 25%(從 0.518 提高到 0.3876)。
驗證
1:最終效能測量
下表顯示了使用 CPU 伺服器對本文中提到的三個模型進行的最終效能改進。
# Food photo classifier (pod 3): 2.5rps -> 84 rps
Type Name # reqs # fails | Avg Min Max Med | req/s failures/s
--------|----------------------------------------------------------------------------|------|------------|-------|------|-------|-------|--------|---------
POST /predictions/food-classification 2341 0(0.00%) | 208 130 508 200 | 84.50 0.00
--------|----------------------------------------------------------------------------|--------|-------------|------|-------|--------|------|--------|----------
Aggregated 2341 0(0.00%) | 208 130 508 200 | 84.50 0.00
# Image scoring (pod 3): 2.1rps -> 62rps
Type Name #reqs #fails | Avg Min Max Median | req/s failures/s
--------|---------------------------------------------------------------------------------|--------|-------------|--------|-------|--------|---------|--------|---------
POST /predictions/image-scoring 1298 0 (0.00%) | 323 99 607 370 | 61.90 0.00
--------|---------------------------------------------------------------------------------|--------|-------------|--------|------|--------|---------|--------|----------
Aggregated 1298 0(0.00%) | 323 99 607 370 | 61.90 0.00
# receipt classifier(pod 3) : 20rps -> 111.8rps
Type Name # reqs # fails | Avg Min Max Med | req/s failures/s
--------|----------------------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
POST /predictions/receipt-classification 4024 0(0.00%) | 266 133 2211 200 | 111.8 0.00
--------|----------------------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
Aggregated 4020 0(0.00%) | 266 133 2211 200 | 111.8 0.00
2: 流量映象
如前所述,我們團隊的服務架構在應用伺服器前面使用“traefik”工具作為閘道器,正如文章開頭簡要介紹的那樣。為了最終驗證,我們利用了 traefik 閘道器的映象功能,將生產流量映象到 staging 環境進行了一個月的驗證,然後才將其應用於生產環境,目前已投入執行。
關於映象的詳細資訊超出了本主題的範圍,因此此處省略。感興趣的讀者請參閱文件: https://doc.traefik.io/traefik/routing/services/#mirroring-service。
結論
至此,關於在保持服務質量的同時從 GPU 模型伺服器過渡到 CPU 伺服器的討論結束。透過這項努力,我們團隊在韓國和日本各節省了 15 個 GPU,從而每年節省了約 34 萬美元。儘管我們在 NAVER 內部直接購買和使用 GPU,但我們基於穩定支援 T4 GPU 的 AWS EC2 例項計算了大致的成本降低。
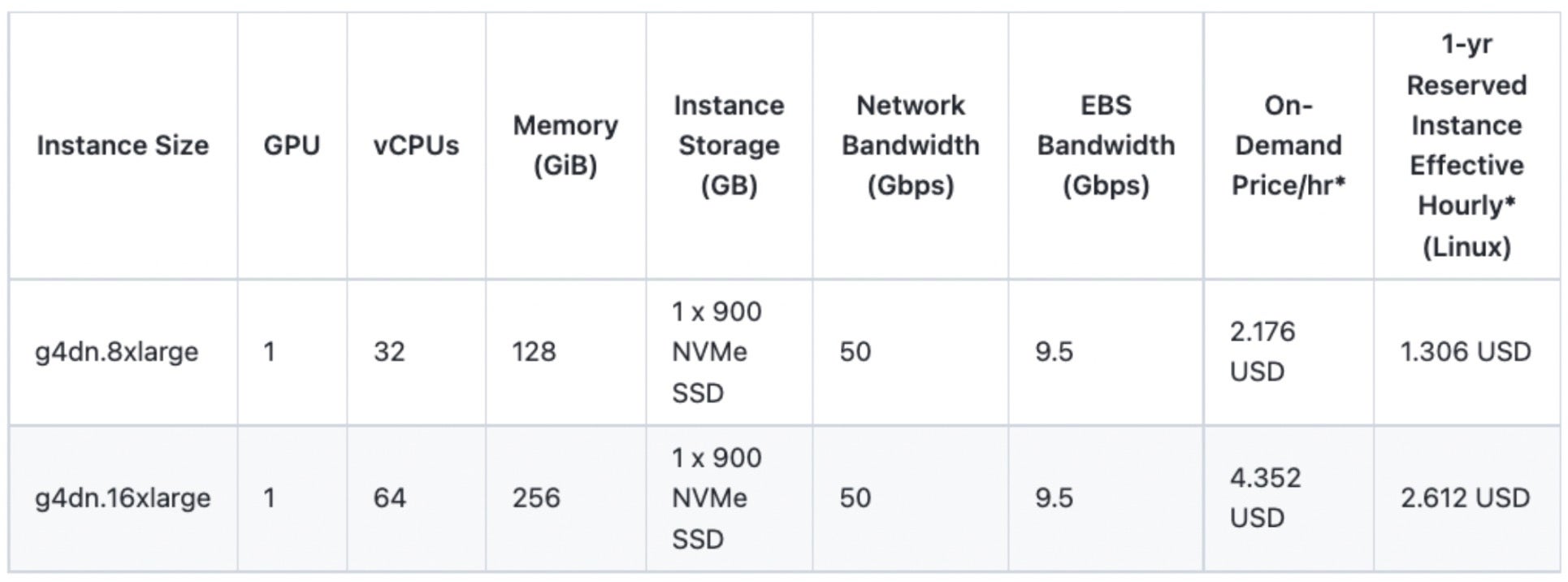
計算:1.306(1 年期預留例項有效每小時成本)* 24(小時)* 365(天)* 15(GPU 數量)* 2(韓國 + 日本)
這些獲得的 GPU 將用於進一步推進和增強我們團隊的 AI 服務,提供卓越的服務體驗。我們真誠地感謝您的鼓勵和期待:)
瞭解更多
- https://www.intel.com/content/www/us/en/developer/ecosystem/pytorch-foundation.html
- https://pytorch-geometric.readthedocs.io/en/latest/advanced/CPU_affinity.html#binding-processes-to-physical-cores
- https://arxiv.org/pdf/2205.10536.pdf