大型語言模型(LLM)應用的快速增長與能源需求的快速增長息息相關。根據國際能源署(IEA)的資料,到 2026 年,資料中心的電力消耗預計將大致翻倍,主要由人工智慧驅動。這是由於大型語言模型訓練所需的能源密集型需求——然而,AI 推理工作負載的增加也發揮了作用。例如,與傳統的搜尋查詢相比,單次 AI 推理可能消耗約10 倍的能源。
作為開發人員,我們直接影響著我們 AI 解決方案的能源密集程度。我們可以採取技術決策來幫助使我們的 AI 解決方案更具環境可持續性。將計算量最小化以提供 LLM 解決方案並非建立可持續 AI 用途的唯一要求。例如,可能需要政策干預等系統性變革,但利用能源效率高的解決方案是一個重要因素,也是我們現在就可以採取的有效干預措施。
話雖如此,最大限度地減少您的 LLM 推理雲計算需求,也能減少您的雲賬單,並使您的應用程式更節能,從而實現雙贏。在這篇部落格中,我們將引導您完成建立 LLM 聊天機器人的步驟,透過最佳化和部署基於 PyTorch 的 Llama 3.1 模型,並量化特定架構決策的計算效率優勢。
我們將評估什麼?
在這篇部落格中,我們的目標是建立一個沉浸式奇幻故事應用,使用者透過與生成式 AI 聊天進入一個奇幻世界。第一個地點是“邪惡之地”(Land of Wicked),允許人們角色扮演在翡翠城中漫步,並即時觀察景物。我們將透過聊天機器人和自定義系統提示來實現這一點。
我們將在 CPU 上評估 LLM 效能。您可以在此處檢視 CPU 與 GPU 推理的優勢。一般來說,對於 Llama 系列等引數量在 10 億或更少的模型,在雲端利用 CPU 進行 LLM 推理是一個不錯的選擇。
我們還將使用基於 Arm 的 CPU,特別是 AWS Graviton 系列。根據研究,基於 Arm 的 Graviton3 伺服器可以提供降低 67.6% 的內建工作負載碳強度。儘管這項研究基於模擬,但它為最小化我們應用的能源需求展示了可能性,這是一個很好的開端。
首先,您將瞭解如何在 PyTorch 上執行一個簡單的 LLM 聊天機器人,然後探索三種技術來最佳化您的應用程式以提高計算效率
- 模型最佳化:利用 4 位量化和增加的 KleidiAI 核心。
- 快捷最佳化:實現向量資料庫以處理常見查詢。
- 架構最佳化:採用無伺服器架構。
讓我們開始吧。
透過 PyTorch 在 AWS Graviton4 上執行 Llama-3.1
為了最大限度地提高能源效率,我們將僅使用支援此 LLM 聊天機器人所需的最小伺服器資源。對於這個Llama-3.1 80 億引數模型,需要 16 核、64GB 記憶體和 50GB 磁碟空間。我們將使用執行 Ubuntu 24.04 的 r8g.4xlarge Graviton4 例項,因為它符合這些規格。
啟動這個 EC2 例項,連線到它,並開始安裝所需元件
sudo apt-get update
sudo apt install gcc g++ build-essential python3-pip python3-venv google-perftools -y
然後安裝 Torchchat,這是 PyTorch 團隊開發的庫,支援跨裝置執行 LLM
git clone https://github.com/pytorch/torchchat.git
cd torchchat
python3 -m venv .venv
source .venv/bin/activate
./install/install_requirements.sh
接下來,透過命令列從 Hugging Face 安裝 Llama-3.1-8b 模型。您需要先在您的 HF 賬戶上建立一個 Hugging Face 訪問令牌。這將把 16GB 的模型下載到您的例項,這可能需要幾分鐘。
pip install -U "huggingface_hub[cli]"
huggingface-cli login
<enter your access token when prompted>
python torchchat.py export llama3.1 --output-dso-path exportedModels/llama3.1.so --device cpu --max-seq-length 1024
現在您已經準備好執行 LLM 模型了,新增一個系統提示,使其成為《邪惡之地》中的引導敘述者
LD_PRELOAD=/usr/lib/aarch64-linux-gnu/libtcmalloc.so.4 TORCHINDUCTOR_CPP_WRAPPER=1 TORCHINDUCTOR_FREEZING=1 OMP_NUM_THREADS=16 python torchchat.py generate llama3.1 --device cpu --chat
輸入“y”以輸入系統提示,然後輸入以下提示
你是一個奇幻冒險應用的引導敘述者。讓使用者沉浸在《邪惡之地》的迷人世界中,引導他們在翡翠城進行互動式即時體驗。描述生動的景象,動態的場景,並讓使用者參與到感覺鮮活和響應迅速的故事講述中。允許使用者做出選擇,塑造他們的旅程,同時保持《邪惡之地》宇宙的魔幻基調。
然後輸入您的使用者查詢
我穿過翡翠城門,抬頭望去
輸出將顯示在螢幕上,生成第一個 token 大約需要 7 秒,每秒不足 1 個 token。
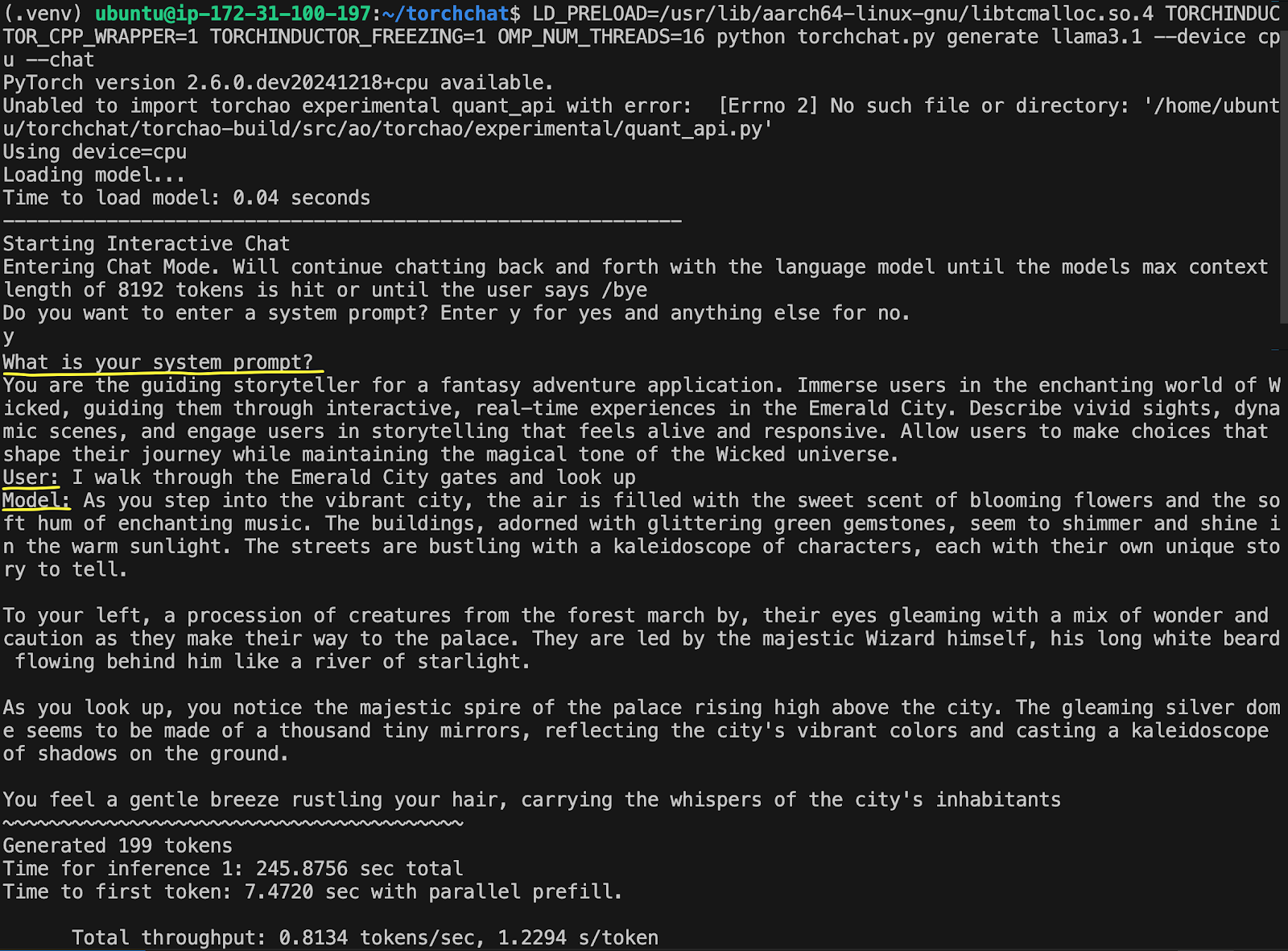
這個例子花了 245 秒,也就是 4 分鐘,才生成完整的回覆——速度不快。我們將要討論的第一個最佳化將加快 LLM 的生成速度,減少其計算佔用空間。
最佳化 1:KleidiAI 和量化
上述基本實現可以進行多項最佳化。最簡單快捷的方法是將模型從 FP16 量化到 INT4。這種方法犧牲了一些精度,同時將模型大小從 16GB 縮減到約 4GB,從而提高了推理速度。
另一個常見的最佳化是利用 TorchAO(Torch 架構最佳化),這是 PyTorch 庫,與 TorchChat 無縫協作,透過各種量化和稀疏化方法增強模型效能。
最後,我們將使用 Arm KleidiAI 最佳化。這些是使用匯編語言編寫的微核心,可顯著提高 Arm CPU 上 LLM 推理的效能。如果您感興趣,可以閱讀更多關於KleidiAI 核心如何工作的資訊。
要實現這些最佳化,請啟動一個新的 EC2 例項,並按照如何使用 PyTorch 執行大型語言模型(LLM)聊天機器人的說明進行操作。準備好後,執行模型並輸入與上述相同的系統提示和使用者查詢。您將獲得顯著加快推理速度的結果:第一個 token 不到 1 秒,每秒約 25 個 token。
這將推理時間從 245 秒縮短到大約 10 秒。這會減少伺服器的功耗,因為它將更多時間用於空閒,而不是執行耗電的推理。在其他條件相同的情況下,這是一個比非最佳化應用更碳友好的解決方案。接下來的兩種方法超出了模型推理最佳化範圍,透過修改解決方案架構進一步減少計算負載。
最佳化 2:FAISS 用於匹配資料庫的常見問題
如引言所述,模型推理通常比其他搜尋技術計算成本更高。如果您可以無需執行 LLM 推理就自動響應常見使用者查詢,該怎麼辦?使用查詢/響應資料庫是一種繞過 LLM 推理並高效響應的選項。對於這個互動式故事應用,您可以想象關於特定角色、世界本身以及聊天機器人能做什麼/不能做什麼的規則的常見問題,這些問題可以有預先生成的答案。
然而,傳統的精確匹配資料庫不足以應對使用者以多種方式表達相同查詢的情況。詢問聊天機器人的能力可能會得到相同的答案,但表達方式不同:
- “你能做什麼?”
- “告訴我你能做些什麼。”
- “我該如何與你互動?”
透過理解使用者的意圖,將使用者的查詢與最相關的預生成答案進行匹配,實現語義搜尋可以解決這個問題。FAISS 庫是實現語義搜尋的一個絕佳選擇。
這種方法能節省多少計算量取決於三個因素
- 可以透過語義搜尋而不是 LLM 服務處理的使用者查詢百分比。
- 執行 LLM 推理的計算成本。
- 執行語義搜尋的計算成本。
節省的計算量公式為
Computational_savings = (% of queries) * (LLM_cost – search_cost).
這種架構在幾種情況下是合理的。一種是如果您的系統有許多重複問題的常見查詢。另一種是擁有數十萬個傳入查詢的大規模系統,其中很小的百分比節省也能累積成有意義的變化。最後,如果您的 LLM 推理與搜尋成本相比非常昂貴,特別是對於引數量更大的模型。
最終的最佳化方法是從伺服器過渡到無伺服器。
最佳化 3:無伺服器方法
無伺服器架構之所以流行,原因有很多,其中之一就是隻為活動計算時間付費,並消除了閒置伺服器的成本。閒置伺服器需要大量的電力來維持執行,在等待時浪費能源。
這種成本效率轉化為一種本質上更環保的架構,因為它減少了浪費的能源消耗。此外,多個應用程式共享底層物理基礎設施,提高了資源效率。
要設定您自己的無伺服器聊天機器人,您需要首先使用包含 Lambda 入口函式 lambda_handler 的 Python 指令碼,將量化的 Llama-3.1-8b 與 TorchChat、TorchAO 和 Arm KleidiAI 最佳化一起容器化。一個部署選項是將您的容器上傳到 AWS ECR 並將容器附加到您的 Lambda 函式。然後設定一個 API Gateway WebSocket 或類似服務,透過 API 與您的 Lambda 進行互動。
使用無伺服器架構託管您的 LLM 存在兩個顯著限制,首先是 token 生成速度。回想一下,基於伺服器的方法透過 KleidiAI 最佳化實現了大約 25 token/秒的速度。而無伺服器方法的速度則慢了一個數量級,我們測得大約為 2.5 token/秒。這個限制主要源於 Lambda 函式部署在 Graviton2 伺服器上。當部署轉移到具有更多 SIMD 通道的 CPU,例如 Graviton3 和 Graviton4 時,token/秒的速度應該會隨著時間的推移而增加。在此處瞭解更多關於 Graviton3 中引入的架構最佳化資訊:Arm Neoverse-V1 CPU。
這種較慢的速度限制了無伺服器 LLM 架構的可用案例,但在某些情況下這可以被視為一種優勢。在我們互動式講故事的用例中,緩慢地揭示資訊會營造一種沉浸感,建立期待並模仿即時敘述。其他用例包括
- 引導冥想應用,以緩慢、放鬆的語速進行講解
- 虛擬朋友進行深思熟慮的對話,或治療性對話。
- 詩歌創作或互動藝術,透過緩慢的呈現營造沉思的美感。
在合適的應用程式中,使用者可能會在較慢的 token 生成速度下獲得更好的體驗。當優先考慮更可持續的解決方案時,限制最終會變成優勢。打個比方,對現代電影的一個常見批評是它們過度依賴視覺特效,導致故事情節不如老電影引人入勝。視覺特效的成本限制意味著老電影必須精心打造引人入勝的對話,利用嫻熟的鏡頭角度和角色定位來充分吸引觀眾。同樣,專注於可持續的 AI 架構,如果深思熟慮,也能帶來更具吸引力、更沉浸式的體驗。
LLM 推理的第二個無伺服器限制是大約 50 秒的冷啟動時間。如果實現不佳,使用者等待 50 秒而沒有其他替代方案,很可能會離開應用程式。您可以透過一些設計技巧將此限制轉化為我們基於“邪惡之地”體驗中的一個特色
- 建立一個“序幕體驗”,透過硬編碼的問題和答案引導使用者,為他們在翡翠城中的落腳點做好準備,並收集輸入以塑造他們即將到來的體驗。
- 將等待期設定為倒計時器,揭示故事或世界構建的硬編碼文字片段。一個角色,如巫師,可以透過碎片化的臺詞與使用者交流,以製造懸念,並引導使用者進入正確的心境。
- 創作一段帶有電影或音樂劇音樂的音訊介紹,並輔以旋轉的視覺效果,將使用者吸引到“邪惡之地”的氛圍中。
跳出思維定式
實施以可持續性為導向的解決方案架構,包括但不限於最佳化您的 AI 推理。瞭解使用者將如何與您的系統互動,並相應地調整您的實施。始終最佳化每秒快速 token 或第一個 token 的時間將掩蓋引人入勝的功能的機會。
話雖如此,您應該儘可能利用直接的最佳化。使用 TorchAO 和 Arm KleidiAI 微核心是加速您的 LLM 聊天機器人的好方法。透過結合創新的解決方案架構並儘可能進行最佳化,您可以構建更可持續的基於 LLM 的應用程式。祝您程式設計愉快!