新一代 CPU 由於其內建的專用指令,在機器學習 (ML) 推理方面提供了顯著的效能改進。結合其靈活性、快速開發速度和低運營成本,這些通用處理器為現有的其他硬體解決方案提供了一種替代的 ML 推理解決方案。
AWS、Arm、Meta 等公司幫助優化了 PyTorch 2.0 在基於 Arm 的處理器上的推理效能。因此,我們很高興地宣佈,基於 Arm 的 AWS Graviton 例項在 PyTorch 2.0 上的推理效能,對於 ResNet-50 而言,比之前的 PyTorch 版本快了 3.5 倍,對於 BERT 而言,快了 1.4 倍,這使得基於 Graviton 的例項成為 AWS 上這些模型最快的計算最佳化例項(見下圖)。
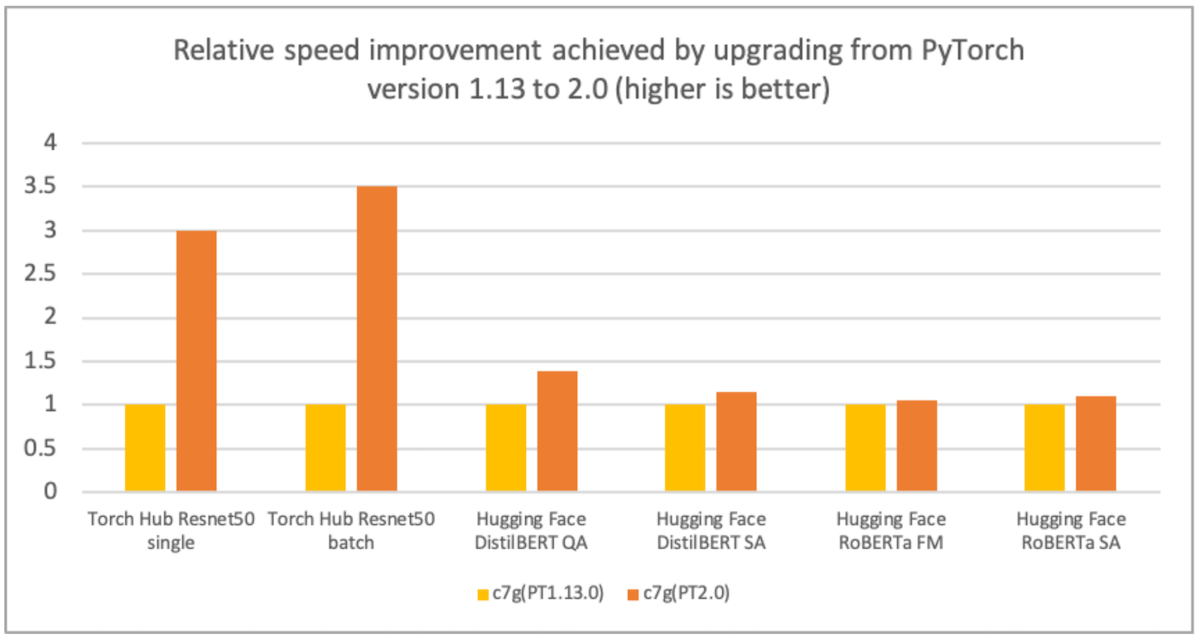
圖 1:從 PyTorch 1.13 版升級到 2.0 版所實現的相對速度提升(越高越好)。效能在 c7g.4xlarge 例項上測量。
如下圖所示,我們測量了使用基於 Graviton3 的 c7g 例項進行 PyTorch 推理,在 Torch Hub ResNet-50 和多個 Hugging Face 模型上,與可比較的基於 x86 的計算最佳化 Amazon EC2 例項相比,可節省高達 50% 的成本。對於該圖,我們首先測量了五種例項型別每百萬次推理的成本。然後,我們將每百萬次推理的成本結果標準化為 c5.4xlarge 例項,該例項在圖表的 Y 軸上是“1”的基線測量值。
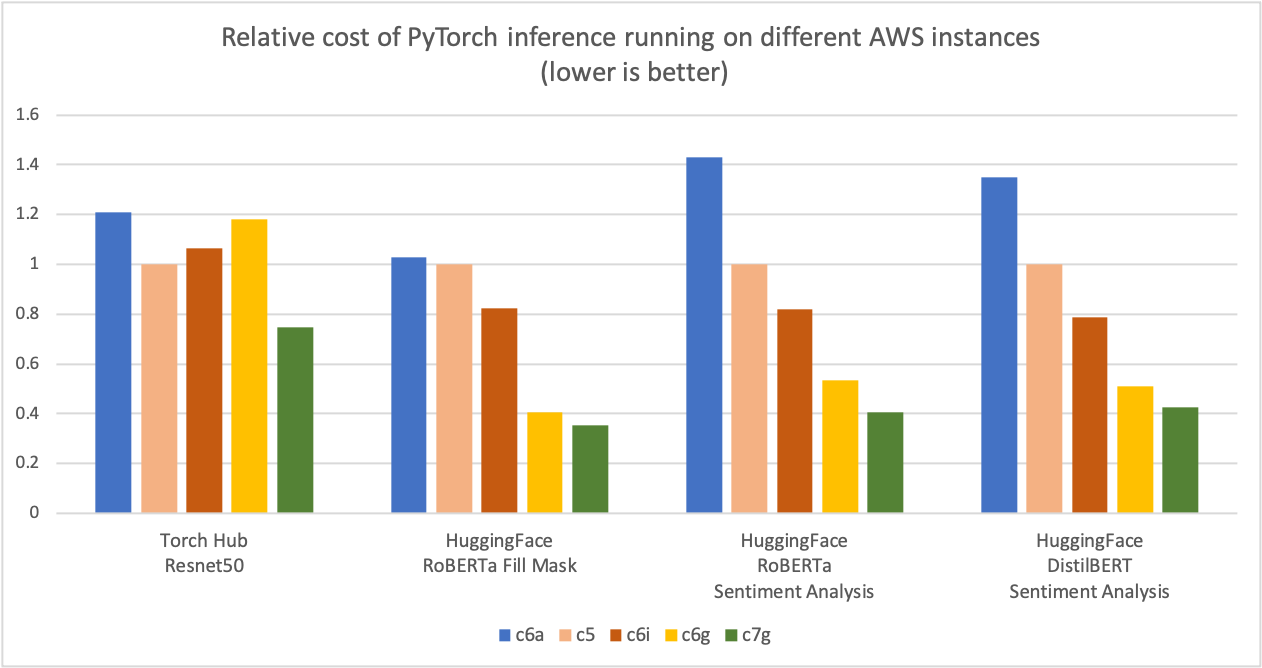
圖 2:在不同 AWS 例項上執行 PyTorch 推理的相對成本(越低越好)。
來源:AWS ML 部落格關於 Graviton PyTorch2.0 推理效能。
與前面的推理成本比較圖類似,下圖顯示了相同五種例項型別的模型 p90 延遲。我們將延遲結果標準化為 c5.4xlarge 例項,該例項在圖表的 Y 軸上是“1”的基線測量值。c7g.4xlarge (AWS Graviton3) 模型推理延遲比在 c5.4xlarge、c6i.4xlarge 和 c6a.4xlarge 上測量的延遲提高了高達 50%。\
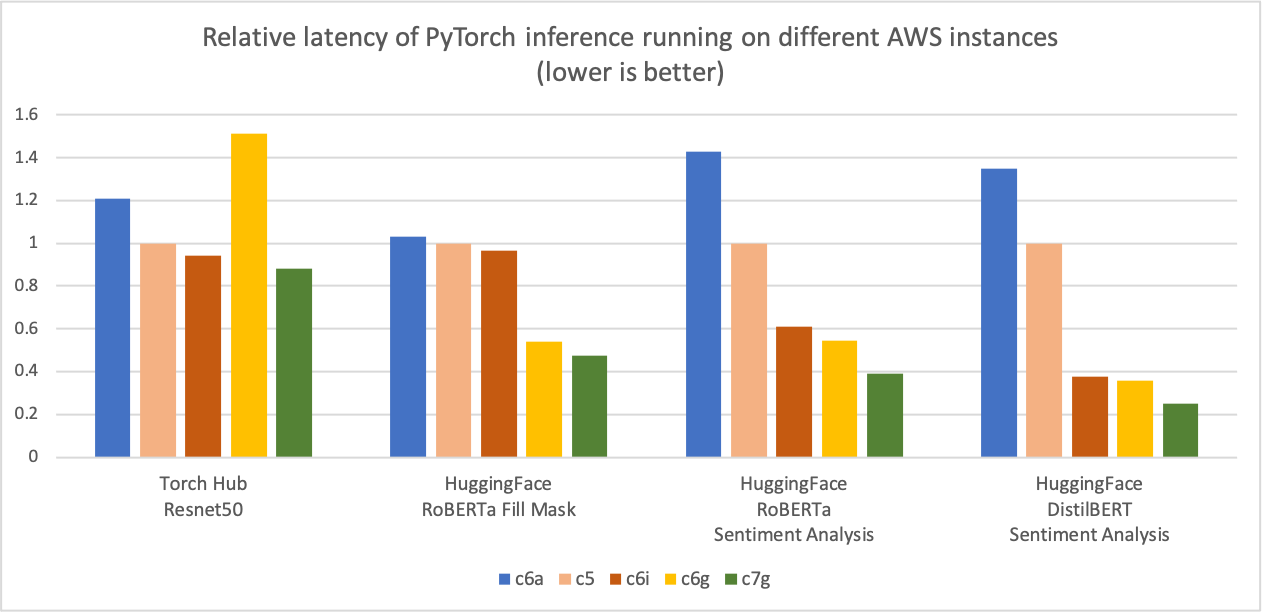
圖 3:在不同 AWS 例項上執行 PyTorch 推理的相對延遲(p90)(越低越好)。
來源:AWS ML 部落格關於 Graviton PyTorch2.0 推理效能。
最佳化詳情
PyTorch 透過 oneDNN 後端(以前稱為“MKL-DNN”)支援適用於 AArch64 平臺的 Arm® 架構計算庫 (ACL) GEMM 核心。最佳化主要針對 PyTorch ATen CPU BLAS、用於 fp32 和 bfloat16 的 ACL 核心以及 oneDNN 原始快取。沒有前端 API 更改,因此在應用程式級別無需進行任何更改即可在基於 Graviton3 的例項上啟用這些最佳化。
PyTorch 級別最佳化
我們擴充套件了 ATen CPU BLAS 介面,以透過 oneDNN 後端加速適用於 aarch64 平臺的更多運算子和張量配置。下圖突出顯示(橙色)了在 aarch64 平臺上改進 PyTorch 推理效能的最佳化元件。
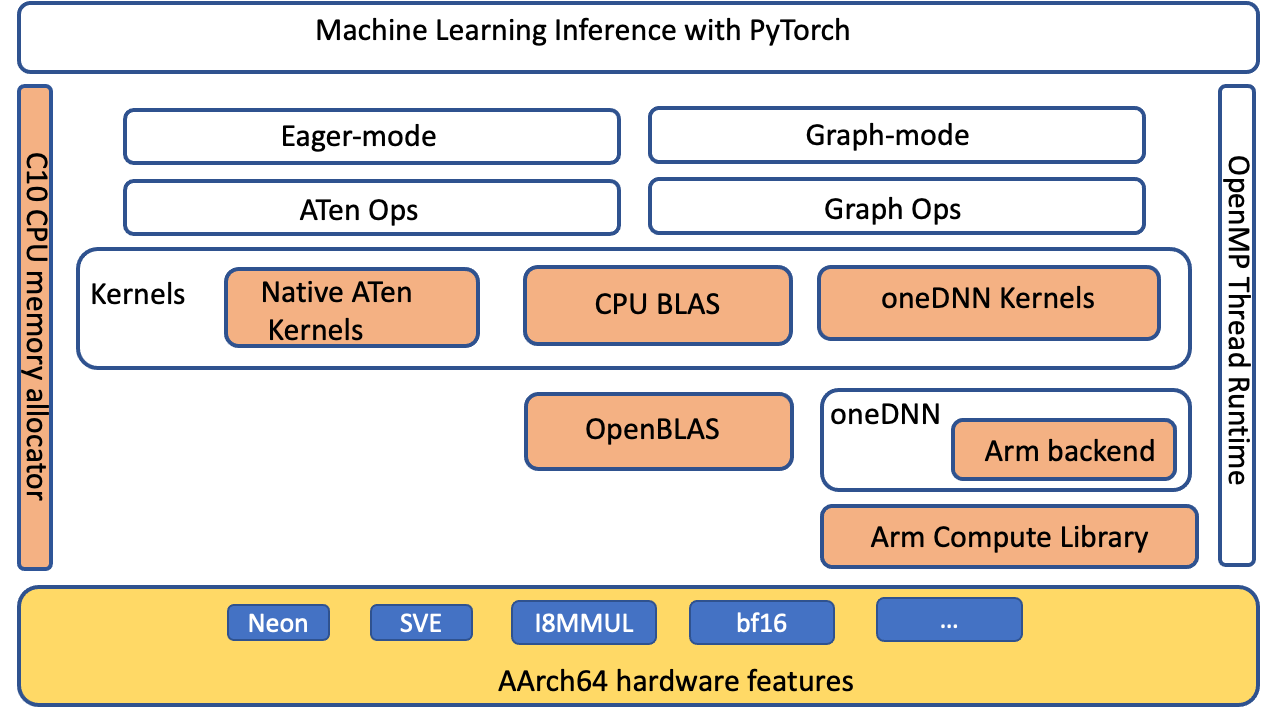
圖 4:PyTorch 軟體堆疊,突出顯示(橙色)為提高 AArch64 平臺上的推理效能而最佳化的元件
ACL 核心和 BFloat16 FPmath 模式
ACL 庫為 fp32 和 bfloat16 格式提供 Neon 和 SVE 最佳化的 GEMM 核心:這些核心提高了 SIMD 硬體利用率並減少了端到端推理延遲。Graviton3 中的 bfloat16 支援允許高效部署使用 bfloat16、fp32 和自動混合精度 (AMP) 訓練的模型。標準 fp32 模型透過 oneDNN FPmath 模式使用 bfloat16 核心,無需模型量化。與沒有 bfloat16 FPmath 支援的現有 fp32 模型推理相比,它們提供了高達兩倍的效能。有關 ACL GEMM 核心支援的更多詳細資訊,請參閱 Arm Compute Library github。
原始快取
下圖顯示了 ACL 運算子如何整合到 oneDNN 後端。如圖所示,ACL 物件被視為 oneDNN 資源,而不是原始物件。這是因為 ACL 物件是有狀態且可變的。由於 ACL 物件被視為資源物件,因此它們無法使用 oneDNN 中支援的預設原始快取功能進行快取。我們在 ideep 運算子級別為“卷積”、“矩陣乘法”和“內積”運算子實現了原始快取,以避免冗餘的 GEMM 核心初始化和張量分配開銷。
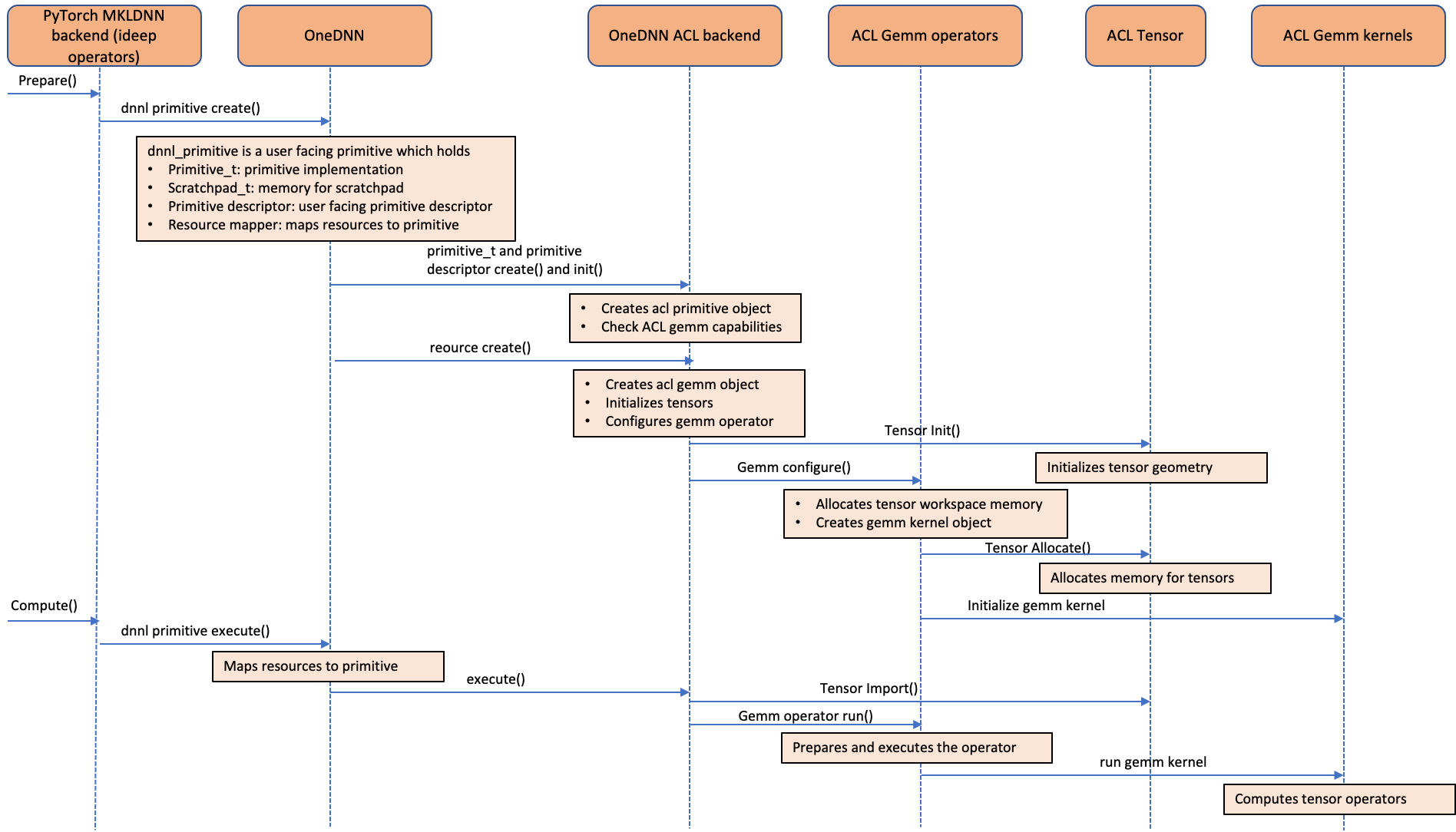
圖 5:呼叫序列圖顯示了 Arm® 架構計算庫 (ACL) GEMM 核心如何整合到 oneDNN 後端
如何利用這些最佳化
從官方儲存庫安裝 PyTorch 2.0 wheel 並設定環境變數以啟用額外的最佳化。
# Install Python
sudo apt-get update
sudo apt-get install -y python3 python3-pip
# Upgrade pip3 to the latest version
python3 -m pip install --upgrade pip
# Install PyTorch and extensions
python3 -m pip install torch
python3 -m pip install torchvision torchaudio torchtext
# Turn on Graviton3 optimization
export DNNL_DEFAULT_FPMATH_MODE=BF16
export LRU_CACHE_CAPACITY=1024
執行推理
您可以使用 PyTorch torchbench 來衡量 CPU 推理效能改進,或比較不同的例項型別。
# Pre-requisite:
# pip install PyTorch2.0 wheels and set the above mentioned environment variables
# Clone PyTorch benchmark repo
git clone https://github.com/pytorch/benchmark.git
# Setup ResNet-50 benchmark
cd benchmark
python3 install.py resnet50
# Install the dependent wheels
python3 -m pip install numba
# Run ResNet-50 inference in jit mode. On successful completion of the inference runs,
# the script prints the inference latency and accuracy results
python3 run.py resnet50 -d cpu -m jit -t eval --use_cosine_similarity
效能分析
現在,我們將使用 PyTorch 效能分析器分析 ResNet-50 在基於 Graviton3 的 c7g 例項上的推理效能。我們使用 PyTorch 1.13 和 PyTorch 2.0 執行以下程式碼,並在測量效能之前執行推理進行幾次迭代作為預熱。
# Turn on Graviton3 optimization
export DNNL_DEFAULT_FPMATH_MODE=BF16
export LRU_CACHE_CAPACITY=1024
import torch
from torchvision import models
sample_input = [torch.rand(1, 3, 224, 224)]
eager_model = models.resnet50(weights=models.ResNet50_Weights.DEFAULT)
model = torch.jit.script(eager_model, example_inputs=[sample_input, ])
model = model.eval()
model = torch.jit.optimize_for_inference(model)
with torch.no_grad():
# warmup runs
for i in range(10):
model(*sample_input)
prof = torch.profiler.profile(
on_trace_ready=torch.profiler.tensorboard_trace_handler('./logs'), record_shapes=True, with_stack=True)
# profile after warmup
prof.start()
model(*sample_input)
prof.stop()
我們使用 tensorboard 來檢視效能分析器的結果並分析模型效能。
如下安裝 PyTorch Profiler Tensorboard 外掛:
pip install torch_tb_profiler
使用以下命令啟動 tensorboard:
tensorboard --logdir=./logs
在瀏覽器中啟動以下內容以檢視效能分析器輸出。效能分析器支援“概述”、“運算子”、“跟蹤”和“模組”檢視,以深入瞭解推理執行。
https://:6006/#pytorch_profiler
下圖是效能分析器的“跟蹤”檢視,它顯示了呼叫堆疊以及每個函式的執行時間。在效能分析器中,我們選擇了 forward() 函式來獲取總推理時間。如圖所示,在 PyTorch 2.0 中,ResNet-50 模型在基於 Graviton3 的 c7g 例項上的推理時間比 PyTorch 1.13 快了約 3 倍。
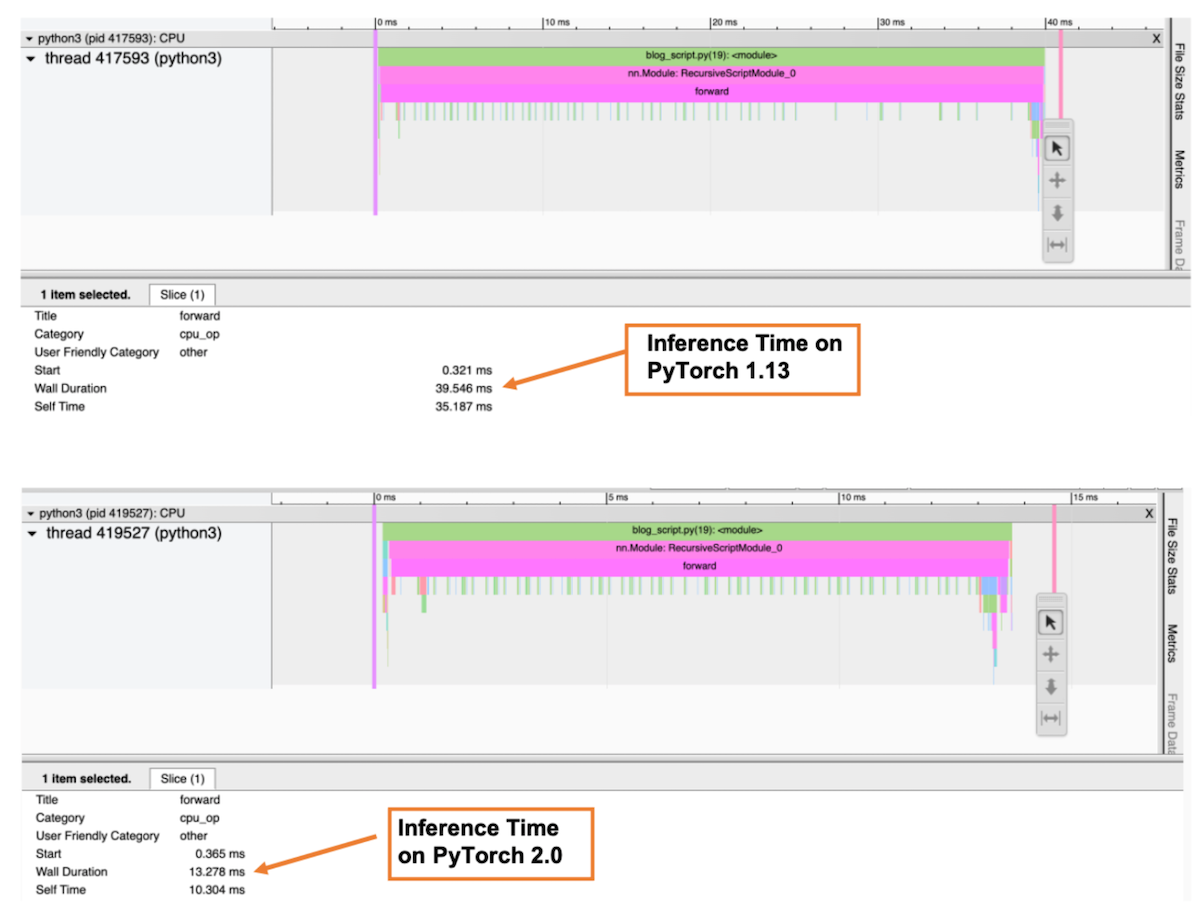
圖 6:效能分析器跟蹤檢視:PyTorch 1.13 和 PyTorch 2.0 上的前向傳播總時長
下圖是“運算子”檢視,它顯示了 PyTorch 運算子列表及其執行時間。與前面的跟蹤檢視類似,運算子檢視顯示,在 PyTorch 2.0 中,ResNet-50 模型在基於 Graviton3 的 c7g 例項上的運算子主機持續時間比 PyTorch 1.13 快了約 3 倍。
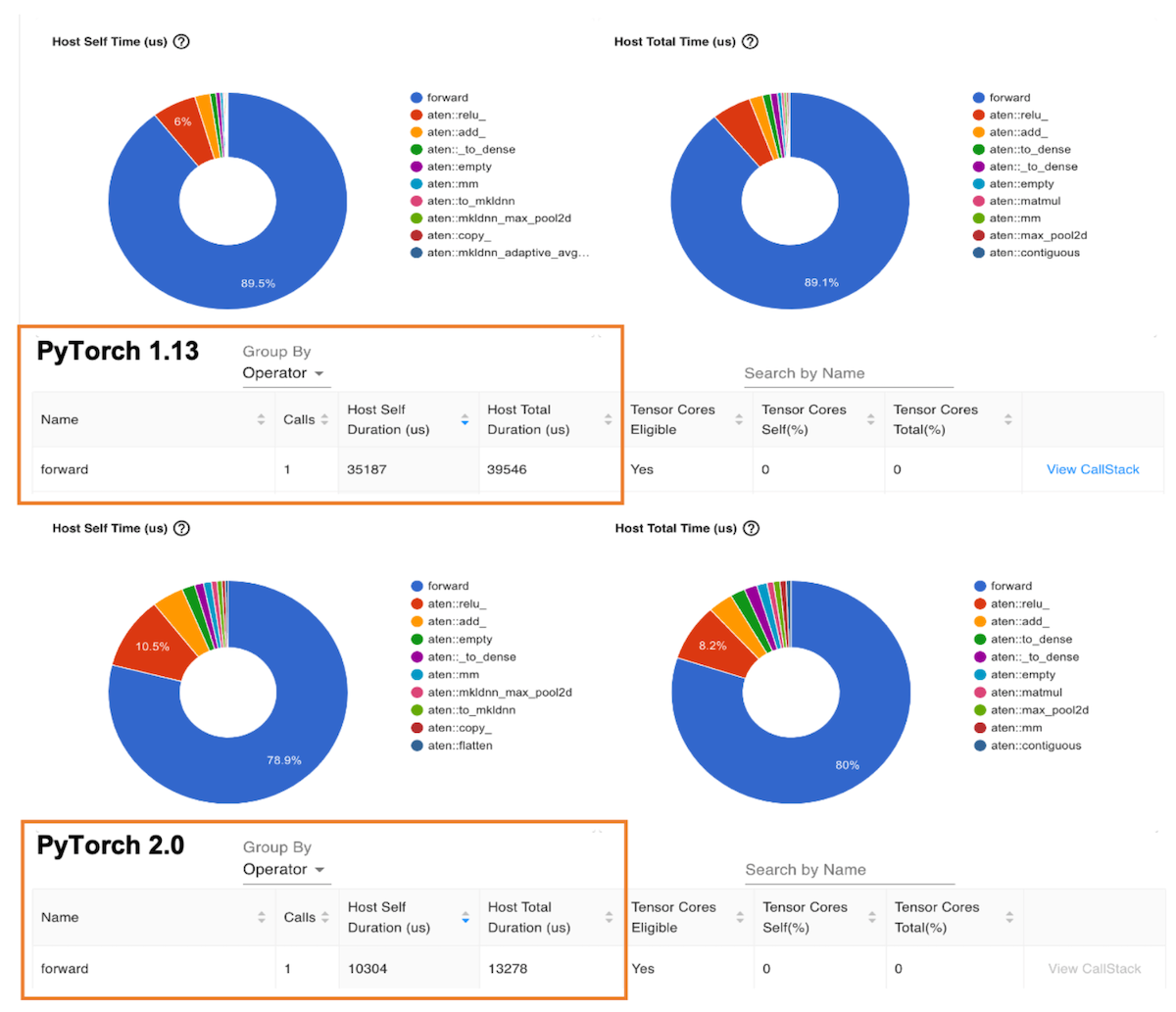
圖 7:效能分析器運算子檢視:PyTorch 1.13 和 PyTorch 2.0 上的前向運算子主機持續時間
基準測試 Hugging Face 模型
您可以使用 Amazon SageMaker Inference Recommender 工具來自動化跨不同例項的效能基準測試。藉助 Inference Recommender,您可以為給定的 ML 模型找到以最低成本提供最佳效能的即時推理端點。我們透過將模型部署到生產端點,使用 Inference Recommender 筆記本收集了上述資料。有關 Inference Recommender 的更多詳細資訊,請參閱 amazon-sagemaker-examples GitHub 儲存庫。我們為本文基準測試了以下模型:ResNet50 影像分類、DistilBERT 情感分析、RoBERTa 填充掩碼和 RoBERTa 情感分析。
總結
對於 PyTorch 2.0,基於 Graviton3 的 C7g 例項是用於推理的最具成本效益的計算最佳化 Amazon EC2 例項。這些例項可在 SageMaker 和 Amazon EC2 上獲得。AWS Graviton 技術指南提供了最佳化庫列表和最佳實踐,可幫助您在不同工作負載下利用 Graviton 例項實現成本效益。
如果您發現 Graviton 上未觀察到類似效能提升的用例,請在 aws-graviton-getting-started github 上提出問題,告知我們。我們將繼續新增更多效能改進,使基於 AWS Graviton 的例項成為使用 PyTorch 進行推理最具成本效益和最高效的通用處理器。
致謝
我們謹此感謝 AWS 的 Ali Saidi(高階首席工程師)和 Csaba Csoma(高階軟體開發經理),以及 Arm 的 Ashok Bhat(高階產品經理)、Nathan Sircombe(高階工程經理)和 Milos Puzovic(首席軟體工程師)在 Graviton PyTorch 推理最佳化工作中的支援。我們還要感謝 Meta 的 Geeta Chauhan(應用 AI 工程負責人)對本部落格的指導。
關於作者
Sunita Nadampalli 是 AWS 的機器學習工程師和軟體開發經理。
Ankith Gunapal 是 Meta (PyTorch) 的 AI 合作伙伴工程師。