作為 PyTorch 2.0 釋出的一部分,注意力機制的加速實現作為“Better Transformer”專案的一部分(在 PyTorch 中稱為 Accelerated Transformers)已原生新增到 PyTorch 中,即 torch.nn.functional.scaled_dot_product_attention。此實現利用了 FlashAttention 和 Memory-efficient attention 的融合核心,並支援訓練和推理。
我們還發布了一個筆記本,展示了此整合的示例 此處
在看到 擴散模型的推理速度提升 20-30% 後,我們繼續透過 🤗 Optimum 庫 實現了與 🤗 Transformers 模型的整合。與 之前針對編碼器模型的整合 類似,此整合將 Transformers 的模組替換為使用 torch.nn.functional.scaled_dot_product_attention 的高效實現。用法如下
from optimum.bettertransformer import BetterTransformer
from transformers import AutoModelForCausalLM
with torch.device(“cuda”):
model = AutoModelForCausalLM.from_pretrained(“gpt2-large”, torch_dtype=torch.float16)
model = BetterTransformer.transform(model)
# do your inference or training here
# if training and want to save the model
model = BetterTransformer.reverse(model)
model.save_pretrained(“fine_tuned_model”)
model.push_to_hub(“fine_tuned_model”)
下面總結了我們關於 torch.nn.functional.scaled_dot_product_attention 的發現
- 它最有助於在給定硬體上擬合更大的模型、序列長度或批次大小進行訓練。
- 訓練期間 GPU 上的記憶體佔用節省從 20% 到 110%+ 不等。
- 訓練期間加速從 10% 到 70% 不等。
- 推理期間加速從 5% 到 20% 不等。
- 對於小型頭部維度,
scaled_dot_product_attention的獨立加速可高達 3 倍,記憶體節省可高達 40 倍(取決於序列長度)。
您可能會對記憶體節省和加速的範圍之廣感到驚訝。在這篇博文中,我們討論了我們的基準測試、此功能的亮點以及未來 PyTorch 版本中即將進行的改進。
在下一個 Transformer 版本中,您只需安裝適當的 Optimum 版本並執行
model = model.to_bettertransformer()
即可使用 BetterTransformer API 轉換您的模型。您現在可以透過從原始碼安裝 Transformer 來試用此功能。
基準測試和與 🤗 Transformers 的用法
torch.nn.functional.scaled_dot_product_attention 可用於任何使用標準注意力的架構,並主要取代樣板程式碼
# native scaled_dot_product_attention is equivalent to the following:
def eager_sdpa(query, key, value, attn_mask, dropout_p, is_causal, scale):
scale_factor = 1 / math.sqrt(Q.size(-1)) if scale is None else scale
attn_mask = torch.ones(L, S, dtype=torch.bool).tril(diagonal=0) if is_causal else attn_mask
attn_mask = attn_mask.masked_fill(not attn_mask, -float('inf')) if attn_mask.dtype==torch.bool else attn_mask
attn_weight = torch.softmax((Q @ K.transpose(-2, -1) * scale_factor) + attn_mask, dim=-1)
attn_weight = torch.dropout(attn_weight, dropout_p)
return attn_weight @ V
在 🤗 Optimum 與 Transformer 模型的整合中,目前支援以下架構:gpt2、gpt-neo、gpt-neox、gptj、t5、bart、codegen、pegasus、opt、LLaMA、blenderbot、m2m100。預計此列表將在不久的將來擴充套件!
為了驗證原生縮放點積注意力的優勢,我們進行了推理和訓練基準測試,結果如下所示。
 在單個 A10G GPU、AWS g5.4xlarge 例項上進行的推理基準測試
在單個 A10G GPU、AWS g5.4xlarge 例項上進行的推理基準測試
 在單個 A10G GPU、AWS g5.4xlarge 例項上進行的訓練基準測試
在單個 A10G GPU、AWS g5.4xlarge 例項上進行的訓練基準測試
 在單個 A100-SXM4-80GB、Nvidia DGX 上進行的訓練基準測試
在單個 A100-SXM4-80GB、Nvidia DGX 上進行的訓練基準測試
在此基準測試中,最有趣的發現是原生 SDPA 允許使用更長的序列長度和批次大小,而不會出現記憶體不足問題。此外,推理期間可實現高達 20% 的加速,訓練期間甚至更大。
正如訓練基準測試所示,較小的頭部維度似乎帶來了更高的加速和記憶體節省,我們將在下一節中討論。
藉助 🤗 Accelerate 庫,透過將 device_map=”auto” 傳遞給 from_pretrained 方法,該實現還支援多 GPU 設定。以下是在兩個 A100-SXM4-80GB 上進行訓練的一些結果。
 在兩個 A100-SXM4-80GB、Nvidia DGX 上進行的訓練基準測試,使用 🤗 Accelerate 庫進行分散式訓練
在兩個 A100-SXM4-80GB、Nvidia DGX 上進行的訓練基準測試,使用 🤗 Accelerate 庫進行分散式訓練
請注意,某些核心僅支援 sm_80 計算能力(即 A100 GPU 的計算能力),這限制了在各種硬體上的可用性,尤其是當頭部維度不是 2 的冪時。例如,截至 PyTorch 2.0.0 訓練期間,opt-2.7b (headim=80) 和 gpt-neox-20b (headdim=96) 無法排程到使用 Flash Attention 的核心,除非在 A100 GPU 上執行。未來可能會開發出更好的核心:https://github.com/pytorch/pytorch/issues/98140#issuecomment-1518101895
Flash Attention、記憶體高效注意力與數學差異
原生 scaled_dot_product_attention 依賴於三種可能的後端實現:Flash Attention、記憶體高效注意力,以及所謂的數學實現,它為所有 PyTorch 平臺提供硬體無關的備用方案。
當給定問題大小存在融合核心時,將使用 Flash Attention 或記憶體高效注意力,從而有效降低記憶體佔用,因為在記憶體高效注意力的情況下,GPU 全域性記憶體上執行 O(N) 記憶體分配,而不是傳統急切注意力實現的經典 O(N^2)。透過 Flash Attention,預計記憶體訪問(讀寫)次數會減少,因此兩者都能帶來加速和記憶體節省。
“數學”實現只是一個使用 PyTorch C++ API 的實現。此實現中值得注意的是,查詢和鍵張量會單獨縮放以提高數值穩定性,因此會啟動兩個 aten::div 操作,而不是在不包含此數值穩定性最佳化的急切實現中可能只啟動一個操作。
頭部維度對加速和記憶體節省的影響
在對 torch.nn.functional.scaled_dot_product_attention 進行基準測試時,我們注意到隨著頭部維度的增加,加速/記憶體增益會降低。這對於某些架構來說是一個問題,例如 EleutherAI/gpt-neo-2.7B,它的頭部維度相對較大,為 128,或者 EleutherAI/gpt-j-6B(以及派生模型,如 PygmalionAI/pygmalion-6b),它的頭部維度為 256(實際上目前由於頭部維度過大而無法排程到融合核心)。
這種趨勢可以在下圖中看到,其中 torch.nn.scaled_dot_production 與上述急切實現進行獨立基準測試。此外,我們使用 torch.backends.cuda.sdp_kernel 上下文管理器來強制使用數學、Flash Attention 和記憶體高效注意力實現。
 使用記憶體高效注意力 SDP 核心(僅向前),A100
使用記憶體高效注意力 SDP 核心(僅向前),A100
 使用數學(無 dropout),A100
使用數學(無 dropout),A100
 使用 Flash Attention SDP 核心(無 dropout),A100
使用 Flash Attention SDP 核心(無 dropout),A100
 使用記憶體高效注意力 SDP 核心(無 dropout),A100
使用記憶體高效注意力 SDP 核心(無 dropout),A100
我們看到,對於相同的問題規模,無論是僅推理還是訓練,加速都隨著頭部維度的增加而降低,例如,使用 Flash Attention 核心時,從 headdim=8 的 3.4 倍降至 headdim=128 的 1.01 倍。
隨著頭部維度的增加,記憶體節省的減少是預期的。回想標準注意力計算

由於中間計算,此標準分步計算中的全域性記憶體佔用為 2 * N * N + N * d。記憶體高效注意力建議迭代更新 softmax 歸一化常數並將其計算移到最後,從而僅進行恆定輸出記憶體分配 N * d。
因此,記憶體節省比率為 2 * N / d + 1,它隨著頭部維度的增加而降低。
在 Flash Attention 中,權衡在於頭部維度 d 和 GPU 流式多處理器共享記憶體大小 M 之間,總記憶體訪問次數為 O(N² * d²/M)。因此,記憶體訪問與頭部維度呈二次方關係,與標準注意力呈線性關係相反。原因是,在 Flash Attention 中,對於較大的頭部維度 d,鍵和值 K、V 需要分成更多塊以適應共享記憶體,反過來,每個塊需要載入完整的查詢 Q 和輸出 O。
因此,Flash Attention 的最高加速發生在比率 d² / M 足夠小的狀態下。
PyTorch 2.0.0 的當前限制
缺少比例引數
截至 PyTorch 2.0.0,torch.nn.functional.scaled_dot_product_attention 沒有比例引數,並使用隱藏大小的預設平方根 sqrt(d_k)。
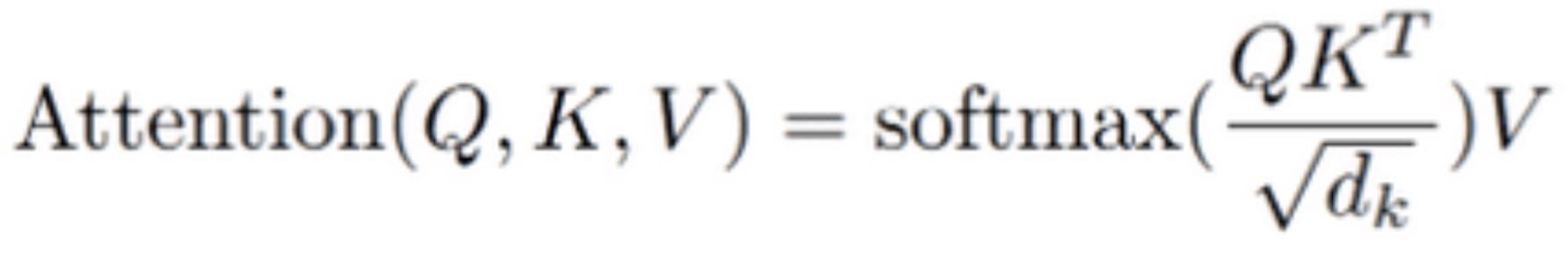
然而,一些架構(如 OPT 或 T5)在注意力中不使用縮放,這在 PyTorch 2.0.0 中強制其在呼叫 scaled_dot_product_attention 之前進行人工重新縮放。這引入了不必要的開銷,因為除了注意力中不必要的除法之外,還需要額外的乘法。
此問題的修復已合併到 PyTorch 儲存庫中。
Flash Attention / 記憶體高效注意力與自定義掩碼的支援
截至 PyTorch 2.0.0,當傳遞自定義注意力掩碼時,無法使用 Flash Attention 和記憶體高效注意力。在這種情況下,scaled_dot_product_attention 會自動排程到 C++ 實現。
然而,正如我們所見,一些架構需要自定義注意力掩碼,例如使用位置偏差的 T5。此外,在批次大小大於 1 且某些輸入可能被填充的情況下,還需要傳遞自定義注意力掩碼。對於後一種情況,替代方法是使用 SDPA 支援的 NestedTensor。
因此,對自定義掩碼的有限支援限制了 SDPA 在這些特定情況下的優勢,儘管我們希望 未來能獲得更廣泛的支援。
請注意,xformers(PyTorch 的 SDPA 部分受其啟發)目前支援任意注意力掩碼:https://github.com/facebookresearch/xformers/blob/658ebab39545f180a6075385b3897921623d6c3b/xformers/ops/fmha/cutlass.py#L147-L156。HazyResearch 的 Flash Attention 實現也支援等效的填充實現,因為使用了累積序列長度陣列以及打包的查詢/鍵/值——本質上類似於 NestedTensor。
總結
使用 torch.nn.functional.scaled_dot_product_attention 是一種免費的最佳化,它使您的程式碼更具可讀性,佔用更少的記憶體,並且在大多數常見情況下速度更快。
儘管 PyTorch 2.0.0 中的實現仍有一些小限制,但推理和訓練在大多數情況下已經從 SDPA 中大量受益。我們鼓勵您使用此原生實現來訓練或部署您的 PyTorch 模型,並將其作為 🤗 Transformers 模型的一行轉換!
未來,我們希望調整 API,以便使用者也能在基於編碼器的模型中使用 SDPA。
我們感謝 Benjamin Lefaudeux、Daniel Haziza 和 Francisco Massa 在頭部維度影響方面的建議,以及 Michael Gschwind、Christian Puhrsch 和 Driss Guessous 對這篇博文的反饋!
基準測試復現
本文中提出的基準測試是使用 torch==2.0.0、transformers==4.27.4、accelerate==0.18.0 和 optimum==1.8.0 完成的。