Intel 宣佈 PyTorch 2.8 在分散式訓練方面取得了重大進展:為 Intel® GPU(Intel® XPU 裝置)原生集成了 XCCL 後端。這直接將 Intel® oneAPI Collective Communications Library (oneCCL) 支援引入 PyTorch,為開發人員提供了無縫、開箱即用的體驗,可在 Intel 硬體上擴充套件 AI 工作負載。
在 Intel® GPU 上實現無縫分散式訓練
在此版本之前,PyTorch 缺乏在 Intel GPU 上進行分散式訓練的內建方法,這使得使用者無法充分利用高階功能。PyTorch 2.8 中原生 XCCL 後端的引入彌補了這一空白。XCCL 的整合遵循了由 公開 RFC 指導的透明、社群驅動的流程,以確保設計符合 PyTorch 的可用性和可靠性核心原則。
這種整合對於以下方面至關重要:
- 提供無縫使用者體驗: 對於大多數開發人員來說,在 Intel GPU 上進行分散式訓練現在可以正常工作,與在其他硬體上的簡單體驗保持一致。這消除了以前的進入障礙並簡化了工作流程。
- 保證功能對等: 確保最先進的 PyTorch 功能,例如完全分片資料並行性 v2 (FSDP2),在 Intel 硬體上無縫工作。
- 生態系統的未來保障: 允許 Intel 硬體立即受益於 PyTorch 中所有未來的分散式增強。
如何使用 XCCL 後端
此功能的主要目標是為 XPU 裝置上的使用者提供一個簡單且與現有後端(如 NCCL 和 Gloo)一致的分散式 API。為了確保可靠性,我們付出了巨大的努力來重構測試,使其與後端無關,從而使 XCCL 的單元測試透過率很高。
使用新後端非常簡單。要使用 XCCL 顯式初始化程序組,您可以將其指定為後端。
# No extra imports needed! import torch import torch.distributed as dist # Check if the XPU device and XCCL are available if torch.xpu.is_available() and dist.is_xccl_available(): # Initialize with the native 'xccl' backend dist.init_process_group(backend='xccl', ...)
為了獲得更流暢的體驗,PyTorch 2.8 在 Intel XPU 裝置上執行時會自動選擇 XCCL 作為預設後端。
# On XPU devices, PyTorch 2.8 will automatically activate the XCCL backend dist.init_process_group(...)
XCCL 的成功經驗
原生 XCCL 支援對 PyTorch 的影響是立竿見影且意義重大的。
無縫生態系統整合:TorchTitan
現在,基於 PyTorch 構建的框架只需少量修改(如果有的話)即可在 Intel GPU 上執行。例如,用於生成式 AI 模型大規模訓練的平臺 TorchTitan 可以與 XCCL 後端無縫、開箱即用地執行。使用 TorchTitan,我們成功地使用先進的多維並行性(FSDP2 和張量並行性)在 XPU 裝置上預訓練了 Llama3 模型。這些模型表現出卓越的收斂性,並擴充套件到 2K 級別,與競爭對手旗鼓相當。
Argonne 國家實驗室:使用 Aurora 超級計算機進行科學 AI 研究
截至 2025 年 6 月,美國能源部 (DOE) Argonne 國家實驗室的 Aurora 百億億次超級計算機在 HPL-MxP AI 效能基準測試中排名第二 [1,2]。它擁有 10,624 個計算節點,每個節點承載六個 Intel GPU。
作為我們與 Argonne 持續合作的一部分,我們利用 PyTorch 原生的大規模分散式訓練功能,使科學家能夠使用 Aurora 解決當今最具挑戰性的問題,從氣候建模和藥物發現到宇宙學和基礎物理學。
案例研究 1:CosmicTagger 模型
我們為 CosmicTagger 模型(一個用於分析中微子資料的基於 U-Net 的分割模型)啟用了 XCCL 後端。結果非常出色:
- 該模型在使用分散式資料並行 (DDP) 進行擴充套件(單個節點內的多個裝置)分散式訓練時實現了 99% 的擴充套件效率。
- 使用 Float32 和 BFloat16 精度測試資料集,它平均達到了約 78% 的準確率。
- 在 FP32 精度弱擴充套件執行中,該模型在擴充套件(跨多個節點的多個裝置)分散式訓練中,擴充套件到 2,048 個 Aurora 節點(24,576 個級別) 時,實現了近 92% 的擴充套件效率(見圖 1)。
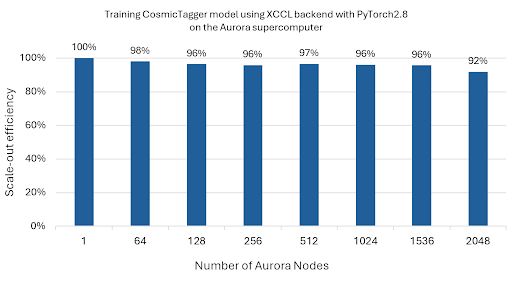
圖 1:CosmicTagger 模型擴充套件到 2,048 個 Aurora 節點(24,576 個級別)的擴充套件效率結果。
* 擴充套件效率衡量分散式訓練中效能擴充套件的程度。擴充套件配置的擴充套件效率計算為使用多個級別在節點內訓練時的每個級別的吞吐量,並相對於使用相同數量但獨立並行執行的最低吞吐量級別進行歸一化。多節點擴充套件訓練的擴充套件效率計算為使用多個節點時的每個級別的吞吐量,並相對於使用單個節點時的每個級別的吞吐量進行歸一化。
案例研究 2:LQCD-su3-4d 模型
LQCD-su3-4d 模型用於高保真物理模擬,以求解夸克和膠子的量子色動力學 (QCD) 理論。我們為該模型啟用了 XCCL 後端,並使用 PyTorch 的 DDP 成功地在多達 2,048 個 Aurora 節點(24,576 個級別) 上進行 FP64 精度訓練,在弱擴充套件執行中實現了超過 89% 的擴充套件效率(見圖 2)。
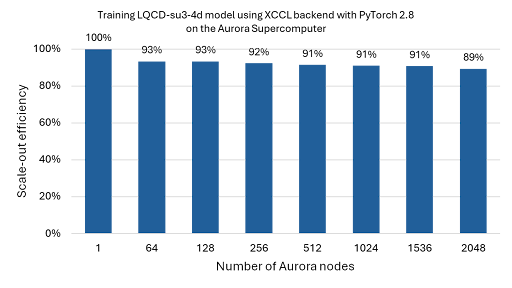
圖 2:LQCD-su3-4d 模型擴充套件到 2,048 個 Aurora 節點(24,576 個級別)的擴充套件效率結果。
案例研究 3:Llama3 模型預訓練
為了支援 Argonne 雄心勃勃的 AuroraGPT 專案 [3],我們已開始使用 TorchTitan 在 Aurora 上預訓練大型語言模型。圖 3 展示了使用 FSDP2 和 XCCL 後端在單個 Aurora 節點(12 個級別)上執行的 Llama3-8B 模型的收斂性研究,展示了穩定的訓練和成功的檢查點。
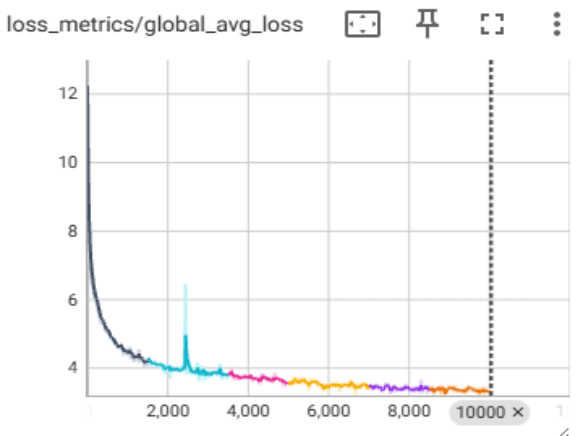
圖 3:單個 Aurora 節點上的 Llama3-8b 收斂性研究。
案例研究 4:將 Llama3 8B 預訓練擴充套件到 2K 級別
Llama 3 8B 模型預訓練已使用 TorchTitan 中提供的多維並行性(見圖 4)在 C4 資料集上擴充套件到 2K 級別。TorchTitan 中可用的超引數和模型未經任何更改就被使用。節點內使用 TP,節點間使用 FSDP。
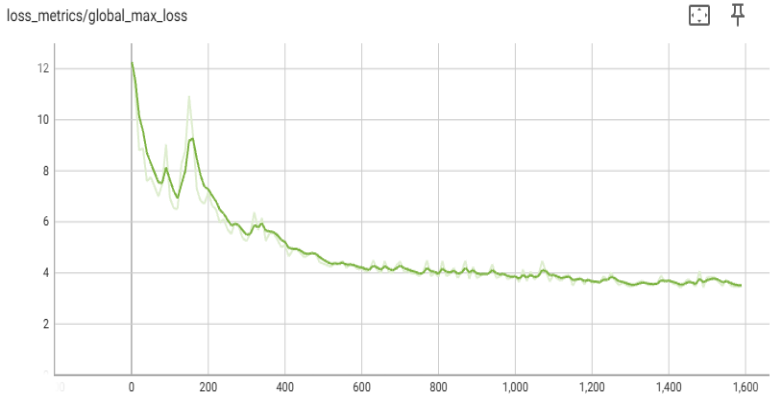
圖 4:Aurora 上 2K 級別的 Llama3-8b 收斂性研究。
立即開始!
原生 XCCL 支援現已在 PyTorch 2.8 中提供。更新您的環境,將您在 Intel 硬體上的分散式訓練提升到一個新的水平。
請注意:在 PyTorch 2.8 中,原生 XCCL 支援適用於 Linux 系統上的 Intel® 資料中心 GPU。
有關更多詳細資訊,請檢視官方文件:
- PyTorch 分散式概述: https://pytorch.com.tw/docs/stable/distributed.html
- is_xccl_available 檢查: https://pytorch.com.tw/docs/stable/distributed.html#torch.distributed.distributed_c10d.is_xccl_available
參考文獻:
[1] Argonne 國家實驗室的 Aurora 超級計算機: https://www.anl.gov/aurora
[2] HPL-MxP 基準測試結果: https://hpl-mxp.org/results.md
[3] Argonne 國家實驗室的 AuroraGPT 專案: https://auroragpt.anl.gov/
效能因使用、配置和其他因素而異。Intel、Intel 徽標和其他 Intel 標記是 Intel Corporation 或其子公司的商標。其他名稱和品牌可能屬於其他公司的財產。