我們很高興正式推出 torchao,這是一個 PyTorch 原生庫,它透過利用低位資料型別、量化和稀疏性來使模型更快、更小。torchao 是一個易於訪問的技術工具包,(大部分)用易於閱讀的 PyTorch 程式碼編寫,涵蓋推理和訓練。這篇部落格將幫助您選擇適合您工作負載的技術。
我們對 Llama 3 和擴散模型等流行的生成式人工智慧模型進行了技術基準測試,並發現準確性下降極小。除非另有說明,基線是在 A100 80GB GPU 上執行的 bf16。
Llama 3 的核心指標如下:
- 使用 int4 僅權重(weight only)量化和 HQQ 的 autoquant,Llama 3 8B 推理速度提升 97%
- Llama 3.1 8B 在 128K 上下文長度推理時,透過量化 KV 快取,峰值視訊記憶體(VRAM)減少 73%
- Llama 3 70B 在 H100 上使用 float8 訓練,預訓練速度提升 50%
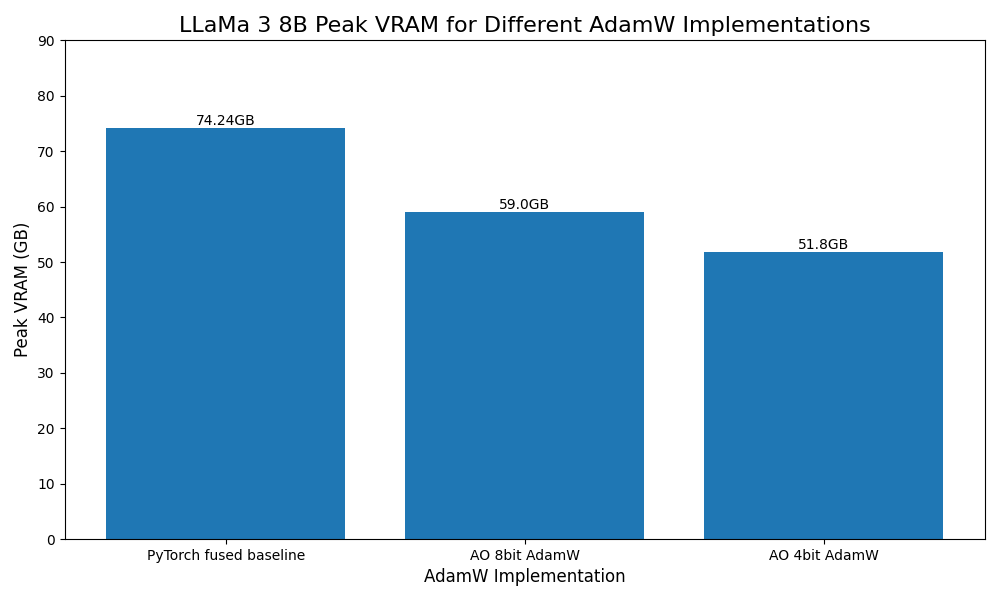
- Llama 3 8B 使用 4 位量化最佳化器,峰值視訊記憶體(VRAM)減少 30%。
擴散模型推理的核心指標如下:
- 在 H100 上的 flux1.dev 上,使用 float8 動態量化推理和 float8 行式(row-wise)縮放,速度提升 53%
- CogVideoX 使用 int8 動態量化,模型視訊記憶體(VRAM)減少 50%
下面我們將介紹 torchao 中可用於推理和訓練模型的一些技術。
推理
我們的推理量化演算法 適用於包含 nn.Linear 層的任意 PyTorch 模型。可以使用我們的頂級 quantize_ API 選擇針對各種資料型別和稀疏佈局的僅權重(weight only)和動態啟用量化。
from torchao.quantization import (
quantize_,
int4_weight_only,
)
quantize_(model, int4_weight_only())
有時,由於開銷,量化層可能會使其變慢,因此如果您希望我們為您選擇模型中每個層的量化方式,您可以執行:
model = torchao.autoquant(torch.compile(model, mode='max-autotune'))
quantize_ API 有幾種不同的選項,具體取決於您的模型是計算密集型(compute bound)還是記憶體密集型(memory bound)。
from torchao.quantization import (
# Memory bound models
int4_weight_only,
int8_weight_only,
# Compute bound models
int8_dynamic_activation_int8_semi_sparse_weight,
int8_dynamic_activation_int8_weight,
# Device capability 8.9+
float8_weight_only,
float8_dynamic_activation_float8_weight,
)
我們還與 HuggingFace diffusers 團隊合作,在 diffusers-torchao 中對擴散模型進行了廣泛的基準測試,其中我們展示了 Flux.1-Dev 上 53.88% 的速度提升和 CogVideoX-5b 上 27.33% 的速度提升。

我們的 API 是可組合的,例如,我們已經組合了稀疏性和量化,為 ViT-H 推理帶來了 5% 的速度提升。
但也可以做一些事情,例如將權重量化為 int4,將 KV 快取量化為 int8,以支援 Llama 3.1 8B 在不到 18.9GB 的 VRAM 中以完整的 128K 上下文長度執行。
QAT
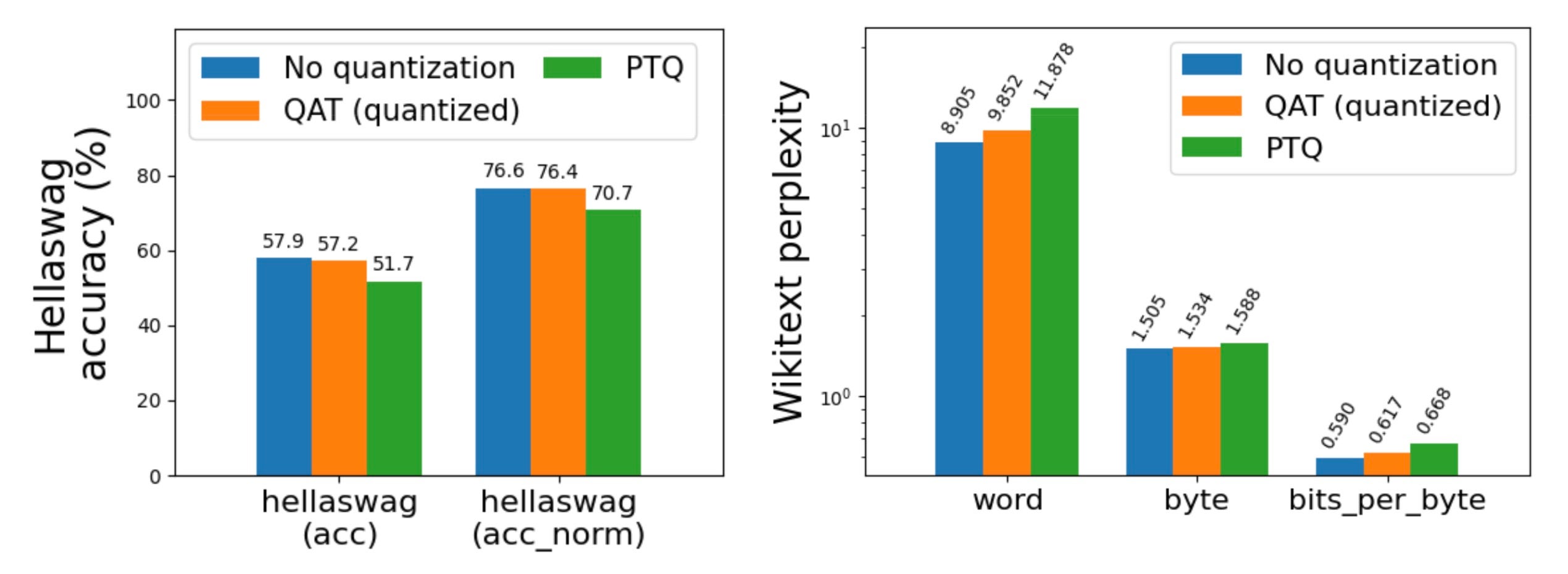
訓練後量化,尤其是低於 4 位的量化,可能會導致嚴重的精度下降。透過使用 量化感知訓練 (QAT),我們成功地在 hellaswag 上恢復了高達 96% 的精度下降。我們已將其作為 torchtune 中的端到端配方整合,並提供了最少的 教程。
訓練
低精度計算和通訊
torchao 提供了易於使用的端到端工作流程,用於降低訓練計算和分散式通訊的精度,從 `torch.nn.Linear` 層的 float8 開始。這是一個將您的訓練執行的計算 gemms 轉換為 float8 的單行程式碼:
from torchao.float8 import convert_to_float8_training
convert_to_float8_training(model)
有關如何使用 float8 將 LLaMa 3 70B 預訓練加速高達 1.5 倍 的端到端示例,請參閱我們的 README,以及 torchtitan 的 部落格 和 float8 配方。
LLaMa 3 70B float8 預訓練與 bfloat16 的效能和準確性
 (來源:https://dev-discuss.pytorch.org/t/enabling-float8-all-gather-in-fsdp2/2359)
(來源:https://dev-discuss.pytorch.org/t/enabling-float8-all-gather-in-fsdp2/2359)
我們正在將訓練工作流程擴充套件到更多資料型別和佈局
低位最佳化器
受 Bits and Bytes 的啟發,我們還添加了 8 位和 4 位最佳化器的原型支援,可作為 AdamW 的直接替代。
from torchao.prototype.low_bit_optim import AdamW8bit, AdamW4bit
optim = AdamW8bit(model.parameters())
整合
我們一直積極致力於確保 torchao 在一些最重要的開源專案中良好執行。
- Huggingface transformers 作為 推理後端
- 在 diffusers-torchao 中 作為加速擴散模型的參考實現
- 在 HQQ 中用於 快速 4 位推理
- 在 torchtune 中 用於 PyTorch 原生 QLoRA 和 QAT 配方
- 在 torchchat 中 用於訓練後量化
- 在 SGLang 中用於 int4 和 int8 訓練後量化
結論
如果您有興趣讓您的模型在訓練或推理時更快、更小,我們希望您會發現 torchao 有用且易於整合。
pip install torchao
我們對接下來有很多興奮的事情,包括低於 4 位、用於高吞吐量推理的高效能核心、擴充套件到更多層、縮放型別或粒度、MX 硬體支援以及支援更多硬體後端。如果以上任何一項聽起來令人興奮,您可以在這裡關注我們的進展:https://github.com/pytorch/ao
如果您有興趣參與 torchao 的工作,我們建立了 貢獻者指南,如果您有任何問題,我們會在 discord.gg/gpumode 的 #torchao 頻道上與您交流。
致謝
我們很幸運能站在巨人的肩膀上,並與一些最優秀的開源人士合作。謝謝!
- Bits and Bytes 在低位最佳化器和 QLoRA 方面的開創性工作
- Answer.ai 在使 FSDP 和 QLoRA 相容方面的工程工作
- Mobius Labs 在量化演算法和低位核心方面的精彩交流
- HuggingFace transformers 在實戰測試和整合我們工作方面的幫助
- HuggingFace diffusers 在廣泛基準測試和最佳實踐方面的合作
- torch.compile 使我們能夠用純 PyTorch 編寫演算法
- GPU MODE 的大部分早期貢獻者