主要收穫
- PyTorch 和 vLLM 對 AI 生態系統都至關重要,並且越來越多地被一起用於前沿生成式 AI 應用,包括大規模推理、後訓練和代理系統。
- 隨著 PyTorch 基金會轉型為一個傘式基金會,我們很高興看到專案被從超大規模企業到初創公司等各類客戶使用和支援。
- vLLM 正在利用更廣泛的 PyTorch 生態系統加速創新,受益於 torch.compile、TorchAO、FlexAttention 等專案,併合作支援異構硬體和複雜的並行化。
- 各團隊(及其他)正在合作,為大規模推理和後訓練構建 PyTorch 原生支援和整合。
甚至在 vLLM 加入 PyTorch 基金會之前,我們已經看到 PyTorch 和 vLLM 共同被世界上部署大規模 LLM 的一些頂級公司廣泛採用。有趣的是,這兩個專案有許多共同之處,包括:強大的富有遠見的領導者;由多個實體(包括工業界和學術界)的提交者組成的廣泛、自然形成的多邊治理結構;以及對開發者體驗的壓倒性關注。
此外,在過去一年多的時間裡,我們看到這兩個專案支撐了許多最受歡迎的開源 LLM,包括各種 Llama 和 DeepSeek 模型。鑑於這些相似之處以及專案之間的互補性,看到所有不同的整合點確實令人興奮。
PyTorch → vLLM 整合
在各個點進行整合的總體目標是釋放效能併為使用者帶來新功能。這包括對 Llama 模型以及更廣泛的開放模型的最佳化和支援。
torch.compile:torch.compile 是一個編譯器,可以最佳化 PyTorch 程式碼,以最少的使用者工作量提供快速效能。雖然手動調整模型的效能可能需要幾天、幾周甚至幾個月,但這種方法對於大量模型來說是不切實際的。相反,torch.compile 提供了一個方便的解決方案來最佳化模型效能。vLLM 預設使用 torch.compile 為其大部分模型生成最佳化的核心。最近的基準測試顯示,對於 Llama4、Qwen3 和 Gemma3 等流行模型,torch.compile 在 CUDA 上實現了顯著加速,範圍從 1.05 倍到 1.9 倍。
TorchAO:我們很高興地宣佈,TorchAO 現已正式支援作為 vLLM 中的量化解決方案。此次整合帶來了使用 Int4、Int8 和 FP8 資料型別的高效能推理能力,並將支援專為 B200 GPU 設計的 MXFP8、MXFP4 和 NVFP4 最佳化。此外,我們正在努力計劃對 AMD GPU 提供 FP8 推理支援,以擴充套件高效能量化推理的硬體相容性。
TorchAO 的量化 API 由強大的高效能核心集合提供支援,包括來自 PyTorch Core、FBGEMM 和 gemlite 的核心。TorchAO 技術旨在與 torch.compile 結合使用。這意味著更簡單的實現和從 PT2 獲得的自動效能提升。編寫更少的程式碼,獲得更好的效能。
此次整合最令人興奮的方面之一是它實現了無縫工作流程:vLLM 使用者現在可以使用 TorchTitan 進行 float8 訓練,使用 TorchTune 進行量化感知訓練 (QAT),然後直接透過 vLLM 載入和部署其量化模型以進行生產推理。這種端到端管道顯著簡化了從模型訓練和微調到部署的路徑,使高階量化技術更容易為開發者所用。
FlexAttention:vLLM 現在包含了 FlexAttention——一個為靈活性設計的新注意力後端。FlexAttention 提供了一個可程式設計的注意力框架,允許開發者定義自定義注意力模式,從而更容易支援新穎的模型設計而無需進行大量後端修改。
這個由 torch.compile 啟用的後端生成 JIT 融合核心。這使得在保持非標準注意力模式效能的同時保持靈活性。FlexAttention 目前在 vLLM 中處於早期開發階段,尚未準備好用於生產。我們將繼續投資於此整合,並計劃使其成為 vLLM 建模工具包的強大組成部分。目標是簡化對新興注意力模式和模型架構的支援,從而更容易彌合研究創新與可部署推理之間的差距。
異構硬體:PyTorch 團隊與不同的硬體供應商合作,為不同型別的硬體後端提供了堅實的支援,包括 NVIDIA GPU、AMD GPU、Intel GPU、Google TPU 等。vLLM 推理引擎利用 PyTorch 作為代理與不同的硬體對話,這顯著簡化了對異構硬體的支援。
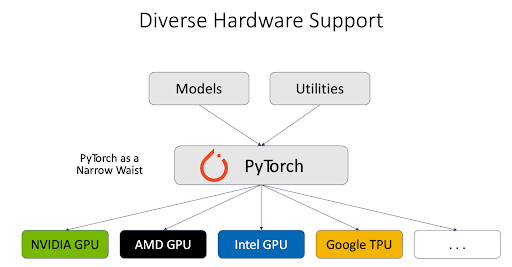
此外,PyTorch 工程師與其他 vLLM 貢獻者密切合作,以支援下一代 NVIDIA GPU。例如,我們已經徹底測試了vLLM 在 Blackwell 上對 FlashInfer 的支援,進行了效能比較,並除錯了精度問題。
PyTorch 團隊還與 AMD 合作,增強了對 vLLM + Llama4 的支援,例如AMD 上的 Llama 4 首日支援以及MI300x 上的 Llama4 效能最佳化。
並行化:在 Meta,我們在生產中利用不同型別的並行化及其組合。流水線並行化 (PP) 是其中重要的一種。vLLM 中的原始 PP 硬性依賴於 Ray。然而,並非所有使用者都利用 Ray 來管理他們的服務和協調不同的主機。PyTorch 團隊開發了支援純 torchrun 的 PP,並進一步優化了其方法以重疊微批次之間的計算。此外,PyTorch 工程師還開發了視覺編碼器的資料並行化,這對於多模態模型的效能至關重要。
持續整合 (CI):鑑於 vLLM 對 PyTorch 生態系統至關重要,我們正在合作確保專案之間的 CI 具有良好的測試覆蓋率、資金充足,並且整個社群可以依賴所有這些整合。僅僅整合 API 是不夠的;重要的是要建立 CI,以確保隨著 vLLM 和 PyTorch 都發布新版本和新功能,隨著時間的推移不會出現任何問題。更具體地說,我們正在測試 vLLM 主分支和 PyTorch nightly 版本的組合,我們相信這將為我們和社群提供監控兩個專案之間整合狀態所需的訊號。在 Meta,我們開始將一些開發工作轉移到 vLLM 主分支上,以對 vLLM 的各種正確性和效能方面進行壓力測試。此外,vLLM v1 的效能儀表板現已在hud.pytorch.org上提供。
下一步是……
這僅僅是個開始。我們正在共同努力構建以下高階功能:
1. 大規模模型推理:主要目標是確保 vLLM 在雲產品上高效大規模執行,展示關鍵能力(預填充-解碼解耦、多節點並行、高效能核心和通訊、上下文感知路由和容錯),以擴充套件到數千個節點,併成為企業構建的穩定基礎。在第二季度,Meta 工程師已經在 vLLM 引擎和 KV 聯結器 API 的基礎上原型化了解耦整合。團隊正在與社群合作嘗試新策略,並計劃將最成功的策略上游,以進一步推動 vLLM 的可能性。
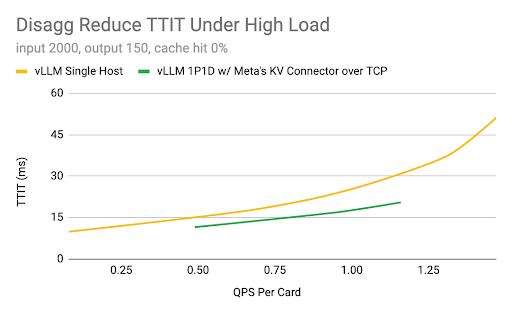
硬體:H100 GPU,96 GB HBM2e,AMD Genoa CPU,CUDA 12.4
2. 強化學習後訓練:推理時間計算正迅速成為 LLM 和代理系統的關鍵。我們正在研究端到端原生後訓練,該訓練將大規模 RL 與 vLLM 作為系統的推理骨幹相結合。
乾杯!
- PyTorch 團隊(Meta)和 vLLM 團隊