在這篇部落格中,我們介紹了 PyTorch 中大型語言模型的端到端量化感知訓練 (QAT) 流程。我們展示了 PyTorch 中的 QAT 如何在 hellaswag 上將 Llama3 的準確率降低程度**恢復高達 96%**,在 wikitext 上將困惑度降低程度**恢復高達 68%**,優於訓練後量化 (PTQ)。我們介紹了 torchao 中的 QAT API,並展示了使用者如何利用它們在 torchtune 中進行微調。
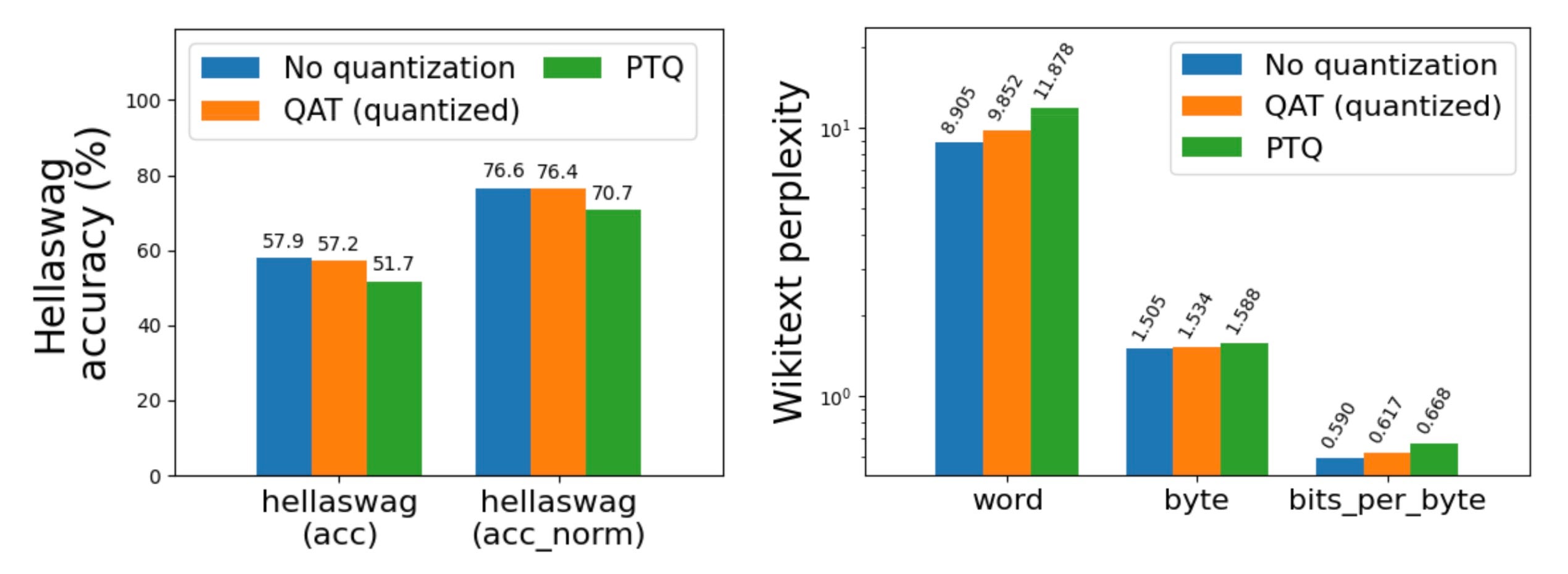
圖 1: Llama3-8B 在 C4 資料集(英文子集)上進行微調,使用和不使用 QAT,採用 int8 每 token 動態啟用 + int4 分組每通道權重,在 A100 GPU 上對 hellaswag 和 wikitext 進行評估。請注意 wikitext 的對數刻度(越低越好)。
為了證明 QAT 在端到端流程中的有效性,我們透過 executorch 將量化模型進一步降低到 XNNPACK,這是一個針對包括 iOS 和 Android 在內的後端的高度最佳化的神經網路庫。**降低到 XNNPACK 後,QAT 模型的困惑度比 PTQ 模型低 16.8%,同時保持相同的模型大小以及裝置上的推理和生成速度。**
| 降低模型指標 | PTQ | QAT |
| Wikitext 單詞困惑度 (↓) | 23.316 | 19.403 |
| Wikitext 位元組困惑度 (↓) | 1.850 | 1.785 |
| Wikitext 每位元組位元數 (↓) | 0.887 | 0.836 |
| 模型大小 | 3.881 GB | 3.881 GB |
| 裝置推理速度 | 5.065 token/秒 | 5.265 token/秒 |
| 裝置生成速度 | 8.369 token/秒 | 8.701 token/秒 |
表 1: QAT 在降低到 XNNPACK 的 Llama3-8B 模型上實現了 16.8% 的困惑度降低,模型大小和裝置上的推理和生成速度保持不變。線性層使用 int8 每 token 動態啟用 + int4 分組每通道權重進行量化,嵌入層額外使用 32 的分組大小量化為 int4(QAT 僅應用於線性層)。Wikitext 評估使用 5 個樣本和最大序列長度 127 在伺服器 CPU 上執行,因為裝置上不可用評估(所有 wikitext 結果越低越好)。裝置上的推理和生成在三星 Galaxy S22 智慧手機上進行基準測試。
QAT API
我們很高興使用者試用 torchao 中的 QAT API,它可以用於訓練和微調。此 API 涉及兩個步驟:準備 (prepare) 和轉換 (convert):準備步驟對模型中的線性層進行轉換,以在訓練期間模擬量化數值,而轉換步驟在訓練後實際將這些層量化為較低的位寬。轉換後的模型可以與 PTQ 模型完全相同的方式使用。
import torch
from torchtune.models.llama3 import llama3
from torchao.quantization.prototype.qat import Int8DynActInt4WeightQATQuantizer
# Smaller version of llama3 to fit in a single GPU
model = llama3(
vocab_size=4096,
num_layers=16,
num_heads=16,
num_kv_heads=4,
embed_dim=2048,
max_seq_len=2048,
).cuda()
# Quantizer for int8 dynamic per token activations +
# int4 grouped per channel weights, only for linear layers
qat_quantizer = Int8DynActInt4WeightQATQuantizer()
# Insert "fake quantize" operations into linear layers.
# These operations simulate quantization numerics during
# training without performing any dtype casting
model = qat_quantizer.prepare(model)
# Standard training loop
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9, weight_decay=1e-5)
loss_fn = torch.nn.CrossEntropyLoss()
for i in range(10):
example = torch.randint(0, 4096, (2, 16)).cuda()
target = torch.randn((2, 16, 4096)).cuda()
output = model(example)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
optimizer.zero_grad()
# Convert fake quantize to actual quantize operations
# The quantized model has the exact same structure as the
# quantized model produced in the corresponding PTQ flow
# through `Int8DynActInt4WeightQuantizer`
model = qat_quantizer.convert(model)
# inference or generate
使用 torchtune 進行微調
我們還將此 QAT 流程整合到 torchtune 中,並提供了 recipe,以便在分散式設定中執行它,類似於現有的完全微調分散式 recipe。使用者還可以透過執行以下命令在 LLM 微調期間應用 QAT。有關更多詳細資訊,請參閱 此 README。
tune run --nproc_per_node 8 qat_distributed --config llama3/8B_qat_full
什麼是量化感知訓練?
量化感知訓練 (QAT) 是一種常見的量化技術,用於緩解量化引起的模型準確率/困惑度下降。這是透過在訓練期間模擬量化數值來實現的,同時將權重和/或啟用保持在原始資料型別(通常是浮點),有效地“偽量化”值,而不是實際將它們轉換為較低的位寬。
# PTQ: x_q is quantized and cast to int8
# scale and zero point (zp) refer to parameters used to quantize x_float
# qmin and qmax refer to the range of quantized values
x_q = (x_float / scale + zp).round().clamp(qmin, qmax).cast(int8)
# QAT: x_fq is still in float
# Fake quantize simulates the numerics of quantize + dequantize
x_fq = (x_float / scale + zp).round().clamp(qmin, qmax)
x_fq = (x_fq - zp) * scale
由於量化涉及非可微運算,如舍入,QAT 反向傳播通常使用 直通估計器 (STE),這是一種估計透過非光滑函式的梯度機制,以確保傳遞給原始權重的梯度仍然有意義。透過這種方式,在計算梯度時會考慮到權重最終在訓練後會被量化,從而有效地允許模型在訓練過程中調整量化噪聲。請注意,QAT 的替代方案是量化訓練,它在訓練期間實際將值轉換為較低位寬的資料型別,但 先前的努力 僅在高達 8 位的情況下取得了成功,而 QAT 即使在較低位寬下也有效。
PyTorch 中的 QAT
我們最初在 torchao 的原型 這裡 添加了 QAT 流程。目前,我們支援線性層的 int8 動態每 token 啟用 + int4 分組每通道權重(縮寫為 8da4w)。這些設定的動機是 邊緣後端上的核心可用性 和 LLM 量化方面的先前研究 的結合,這些研究發現,與其他量化方案相比,每 token 啟用和每組權重量化可實現 LLM 的最佳模型質量。
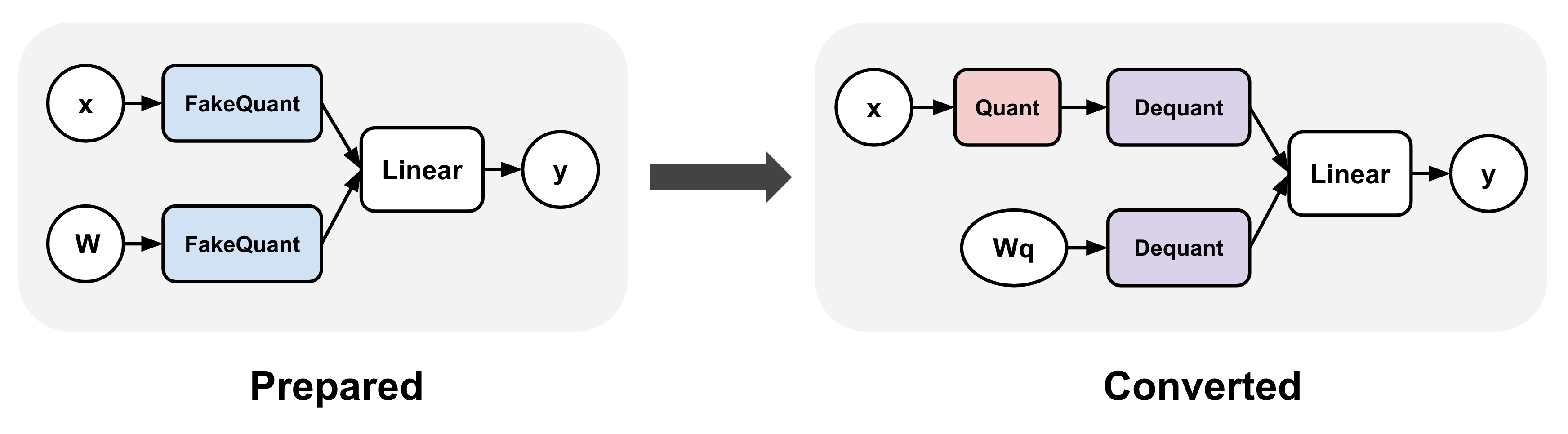
圖 2: torchao QAT 流程。此流程涉及兩個步驟:(1)準備,它將偽量化操作插入到模型的線性層中,以及(2)轉換,它在訓練後將這些偽量化操作轉換為實際的量化和反量化操作。
此流程使用相同的量化設定(透過 Int8DynActInt4WeightQuantizer)生成與 PTQ 流程完全相同的量化模型,但量化權重實現了卓越的準確率和困惑度。因此,我們可以使用從 QAT 流程轉換的模型作為 PTQ 模型的直接替代品,並重用所有後端委託邏輯和底層核心。
實驗結果
本部落格文章中的所有實驗均使用上述 torchtune QAT 整合執行。我們使用 6-8 個配備 80 GB 記憶體的 A100 GPU,在 C4 資料集(英文子集)上對 Llama2-7B 和 Llama3-8B 進行 5000 步微調。對於所有實驗,我們使用批次大小 = 2,學習率 = 2e-5,Llama2 的最大序列長度 = 4096,Llama3 的最大序列長度 = 8192,完全分片資料並行 (FSDP) 作為我們的分散式策略,以及啟用檢查點以減少記憶體佔用。對於 8da4w 實驗,我們對權重使用 256 的分組大小。
由於預訓練資料集不易獲取,我們選擇在微調過程中執行 QAT。經驗上,我們發現前 N 步停用偽量化會帶來更好的結果,這可能是因為這樣做可以在我們開始向微調過程引入量化噪聲之前穩定權重。我們在所有實驗的前 1000 步中停用了偽量化。
我們使用 torchtune 中的 lm-evaluation-harness 整合來評估我們的量化模型。我們報告了各種常用於評估 LLM 的任務的評估結果,包括 hellaswag(一個常識性句子補全任務)、wikitext(一個下一個 token/位元組預測任務)以及一些問答任務,例如 arc、openbookqa 和 piqa。對於 wikitext,困惑度是指模型預測下一個單詞或位元組能力的倒數(越低越好),bits_per_byte 是指預測下一個位元組所需的位元數(這裡也是越低越好)。對於所有其他任務,acc_norm 是指按目標字串的位元組長度歸一化的準確率。
Int8 動態啟用 + Int4 權重量化 (8da4w)
從 Llama2 8da4w 量化開始,我們發現 QAT 能夠在 hellaswag 上恢復與 PTQ 相比 62% 的歸一化準確率下降,並在 wikitext 上恢復 58% 和 57% 的單詞和位元組困惑度下降(分別)。我們在大多數其他任務中看到了類似的改進。
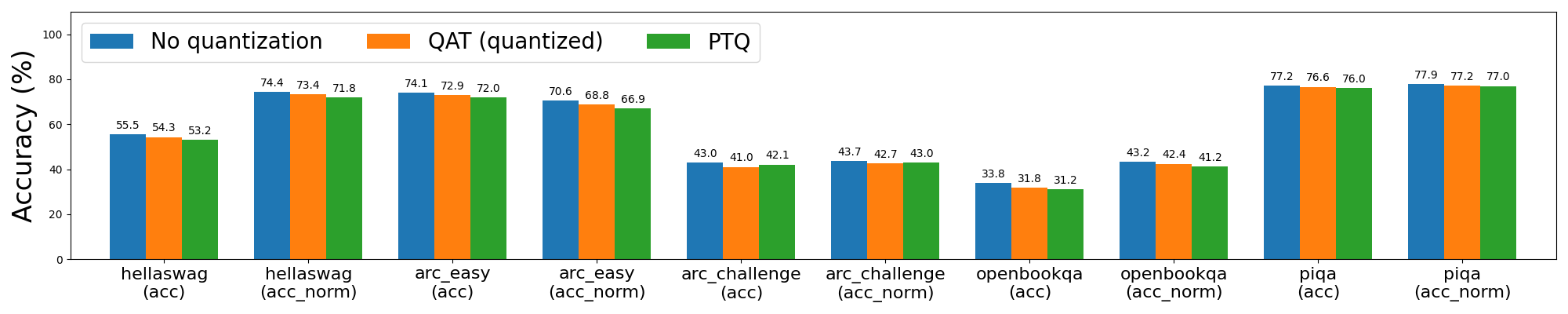
圖 3a: Llama2-7B 8da4w 量化,使用和不使用 QAT
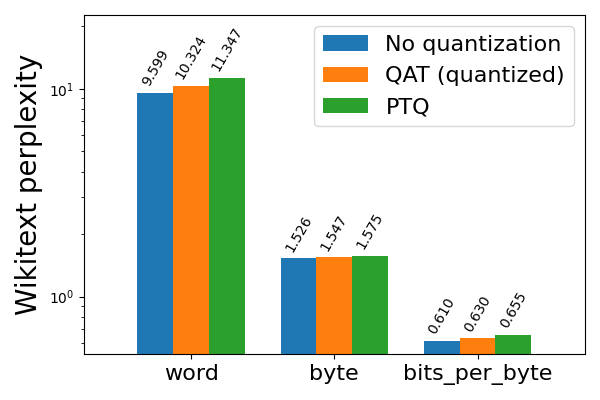
圖 3b: Llama2-7B 8da4w 量化,使用和不使用 QAT,在 wikitext 上評估(越低越好)
Llama3 8da4w 量化在使用 QAT 後看到了更顯著的改進。在 hellaswag 評估任務中,我們能夠恢復與 PTQ 相比 96% 的歸一化準確率下降,與未量化準確率相比總體下降極小(<1%)。在 wikitext 評估任務中,QAT 分別恢復了 68% 和 65% 的單詞和位元組困惑度下降。即使在對 Llama2 QAT 來說很困難的 arc_challenge 上,我們也能夠恢復 51% 的歸一化準確率下降。
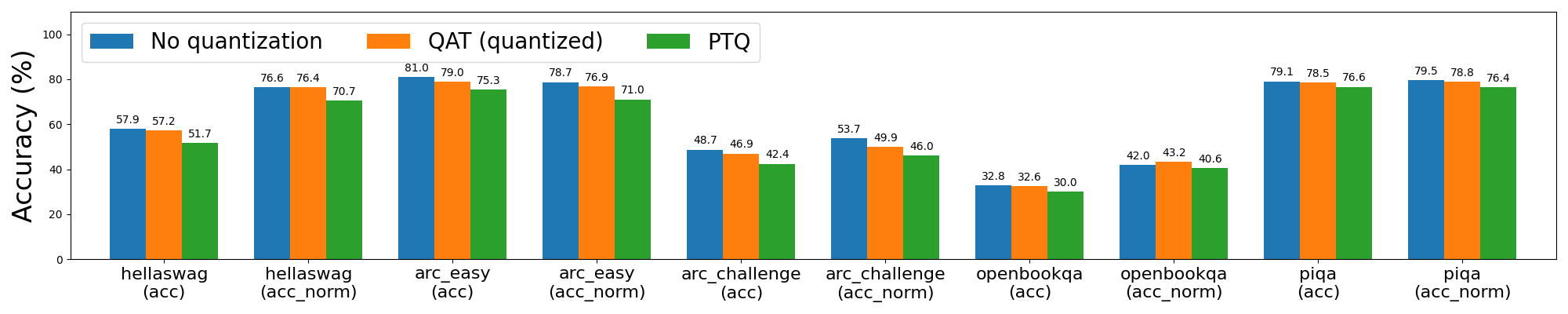
圖 4a: Llama3-8B 8da4w 量化,使用和不使用 QAT
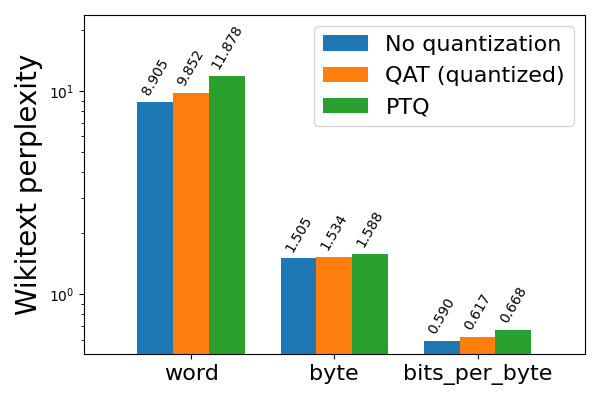
圖 4b: Llama3-8B 8da4w 量化,使用和不使用 QAT,在 wikitext 上評估(越低越好)
低位寬純權重(Weight Only)量化
我們進一步將 torchao QAT 流程擴充套件到 2 位和 3 位純權重(weight only)量化,並對 Llama3-8B 重複了相同的實驗。在較低位寬下,量化退化更嚴重,因此我們對所有實驗使用 32 的分組大小以進行更精細的量化。
然而,這對於 2 位 PTQ 仍然不夠,後者導致 wikitext 困惑度飆升。為了緩解這個問題,我們利用了先前敏感性分析的知識,即 Llama3 模型的前 3 層和後 2 層最敏感,並透過跳過量化這些層來換取量化模型尺寸的適度增加(2 位為 1.78 GB,3 位為 1.65 GB)。這將 wikitext 單詞困惑度從 603336 降低到 6766,這很顯著但仍然遠未達到可接受的水平。為了進一步改進量化模型,我們轉向 QAT。
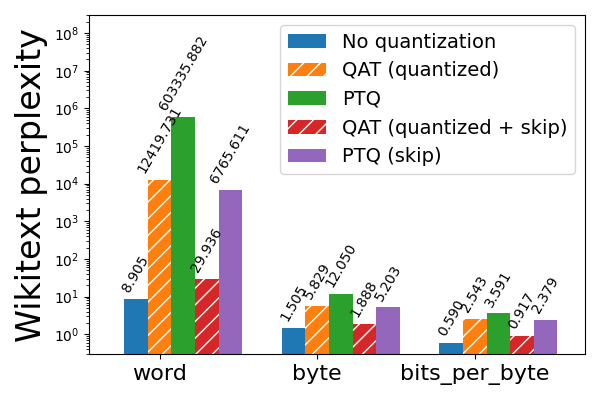
圖 5a: Llama3-8B 2 位純權重(weight only)量化,使用和不使用 QAT,在 wikitext 上評估(越低越好)。帶有“skip”的條形表示跳過對模型前 3 層和後 2 層的量化,這些層對量化更敏感。請注意對數刻度。
我們觀察到,在跳過對前 3 層和後 2 層的量化的情況下應用 QAT,進一步將單詞困惑度降低到一個更合理的 30(從 6766)。更普遍地說,QAT 能夠恢復與 PTQ 相比 hellaswag 上 53% 的歸一化準確率下降,以及 wikitext 上 99% 和 89% 的單詞和位元組困惑度下降(分別)。然而,如果不跳過敏感層,QAT 在緩解量化模型質量下降方面的效果要差得多。
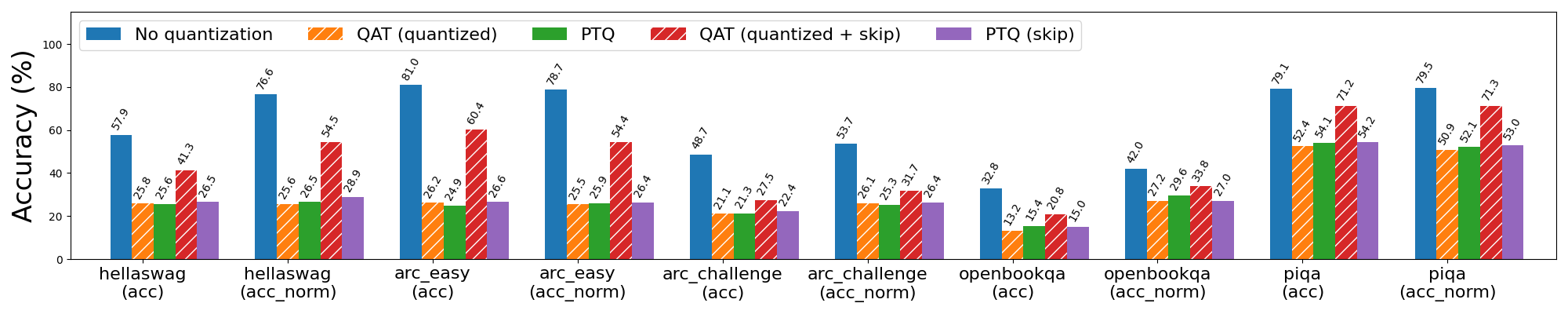
圖 5b: Llama3-8B 2 位純權重(weight only)量化,使用和不使用 QAT。帶有“skip”的條形表示跳過對模型前 3 層和後 2 層的量化,這些層對量化更敏感。
對於 3 位純權重(weight only)量化,QAT 即使不跳過前 3 層和後 2 層也有效,儘管跳過這些層仍然會為 PTQ 和 QAT 帶來更好的結果。在跳過的情況下,QAT 能夠恢復與 PTQ 相比 hellaswag 上 63% 的歸一化準確率下降,以及 wikitext 上 72% 和 65% 的單詞和位元組困惑度下降(分別)。
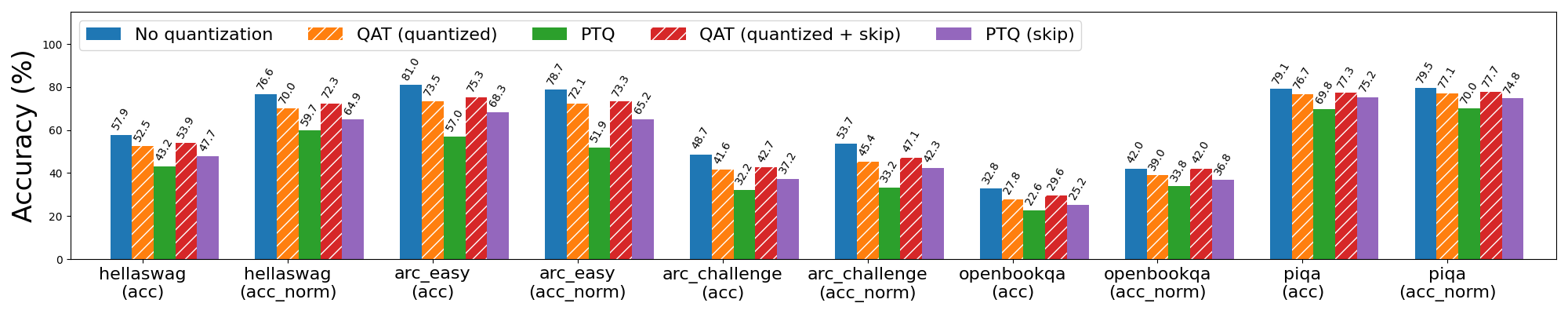
圖 6a: Llama3-8B 3 位純權重(weight only)量化,使用和不使用 QAT。帶有“skip”的條形表示跳過對模型前 3 層和後 2 層的量化,這些層對量化更敏感。
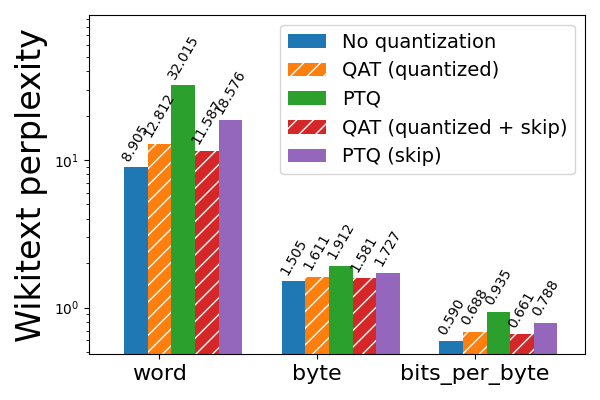
圖 6b: Llama3-8B 3 位純權重(weight only)量化,使用和不使用 QAT,在 wikitext 上評估(越低越好)。帶有“skip”的條形表示跳過對模型前 3 層和後 2 層的量化,這些層對量化更敏感。請注意對數刻度。
QAT 開銷
QAT 在整個模型中插入了許多偽量化操作,增加了微調速度和記憶體使用的大量開銷。例如,對於 Llama3-8B 這樣的模型,我們有 (32 * 7) + 1 = 225 個線性層,每個層至少有 1 個用於權重的偽量化操作,並且可能有一個用於輸入啟用的偽量化操作。記憶體佔用增加也很大,因為我們不能就地修改權重,因此在應用偽量化之前需要克隆它們,儘管這種開銷可以透過啟用啟用檢查點來最大程度地緩解。
在我們的微基準測試中,我們發現 8da4w QAT 微調比常規完全微調慢約 34%。啟用啟用檢查點後,每個 GPU 的記憶體增加約為 2.35 GB。這些開銷大部分是 QAT 工作原理的基礎,儘管我們將來可能能夠透過 torch.compile 加速計算。
| 每個 GPU 統計資料 | 完全微調 | QAT 微調 |
| 每秒中位 token 數 | 546.314 token/秒 | 359.637 token/秒 |
| 中位峰值記憶體 | 67.501 GB | 69.850 GB |
表 2: Llama3 QAT 微調開銷,用於在 6 個 A100 GPU(每個 80GB 記憶體)上使用 int8 每 token 動態啟用 + int4 分組每通道權重。
展望未來
在本部落格中,我們介紹了透過 torchao 實現的 LLM QAT 流程,將其與 torchtune 中的微調 API 整合,並展示了其在恢復大部分量化退化(與 PTQ 相比)和在某些任務上達到未量化效能方面的潛力。未來有許多探索方向:
- 超引數調優。 廣泛的超引數調優可能會進一步改善微調和 QAT 的結果。除了學習率、批次大小、資料集大小和微調步數等通用超引數外,我們還應該調整 QAT 特定的超引數,例如何時開始/停止偽量化、偽量化多少步以及偽量化值的正則化引數。
- 異常值減少技術。 在我們的實驗中,我們發現 PTQ 和 QAT 都容易受到異常值的影響。除了微調期間的簡單鉗制和正則化之外,我們還可以探索允許網路學習如何控制這些異常值的技術(例如 學習量化範圍、裁剪 softmax 和 門控注意力),或者甚至借鑑訓練後設置中的異常值抑制技術(例如 SpinQuant、SmoothQuant),並將其少量應用於微調過程。
- 混合精度和更復雜的資料型別。 特別是在較低位寬下,我們發現跳過對某些敏感層的量化對 PTQ 和 QAT 都有效。我們是否需要完全跳過量化這些層,還是可以仍然量化它們,只是降低位寬?在 QAT 的背景下探索混合精度量化將很有趣。使用 MX4 等更新的資料型別進行訓練是另一個有前途的方向,特別是考慮到即將推出的 Blackwell GPU 將 不再支援 int4 Tensor 核心。
- 與 LoRA 和 QLoRA 的可組合性。 我們在 torchtune 中的 QAT 整合目前僅支援完全微調工作流。然而,許多使用者希望使用低秩介面卡來微調他們的模型,以大幅減少記憶體佔用。將 QAT 與 LoRA / QLoRA 等技術結合,將使使用者能夠獲得這些方法的記憶體和效能優勢,同時生成一個最終將被量化且模型質量下降最小的模型。
- 與 torch.compile 的可組合性。 這是另一種顯著加速 QAT 中偽量化計算並減少記憶體佔用的潛在方法。torch.compile 目前與 torchtune 中完全分散式微調 recipe 中使用的分散式策略不相容(無論是否使用 QAT),但將在不久的將來新增支援。
- 量化其他層。 在這項工作中,我們只探索了量化線性層。然而,在長序列長度的背景下,KV 快取通常成為吞吐量瓶頸,並且可以達到數十 GB,因此 LLM-QAT 探索了量化 KV 快取以及啟用和權重。先前的工作 也成功地將嵌入層量化到 2 位,用於其他基於 Transformer 的模型。
- 在高效能 CUDA 核心上的端到端評估。 這項工作的自然延伸是提供一個在高效能 CUDA 核心上評估的端到端 QAT 流程,類似於透過 executorch 降低到 XNNPACK 核心的現有 8da4w QAT 流程。對於 int4 純權重(weight only)量化,我們可以利用高效的 帶位打包的 int4 權重 MM 核心 進行量化,並且正在進行為該核心新增 QAT 支援的工作:https://github.com/pytorch/ao/pull/383。對於 8da4w 量化,cutlass 中也正在新增 混合 4 位/8 位 GEMM。這將是構建高效 8da4w CUDA 核心所必需的。
QAT 程式碼可在 此處 找到。請參閱 此 torchtune 教程 開始。如果您有任何其他問題,請隨時在 torchao 的 GitHub 上提出問題或聯絡 andrewor@meta.com。我們歡迎您的反饋和貢獻!