引言
近年來,擴充套件模型規模已成為一個很有前景的研究領域。在自然語言處理領域,語言模型已從數億引數(BERT)擴充套件到數千億引數(GPT-3),並在下游任務中表現出顯著的改進。大型語言模型的擴充套件定律在業界也得到了廣泛研究。在視覺領域也觀察到類似的趨勢,社群正轉向基於 Transformer 的模型(如Vision Transformer、Masked Auto Encoders)。很明顯,文字、影像、影片等單一模態都從最近的規模進步中受益匪淺,框架也迅速適應以容納更大的模型。
與此同時,多模態在研究中變得越來越重要,影像-文字檢索、視覺問答、視覺對話和文字到影像生成等任務在實際應用中越來越受歡迎。訓練大規模多模態模型是自然的下一步,我們已經看到該領域的一些努力,例如 OpenAI 的 CLIP、Google 的 Parti 和 Meta 的 CM3。
在這篇部落格中,我們展示了一個案例研究,演示瞭如何使用 PyTorch Distributed 中的技術將 FLAVA 擴充套件到 100 億個引數。FLAVA 是一種視覺和語言基礎模型,可在 TorchMultimodal 中使用,在單模態和多模態基準測試中均表現出有競爭力的效能。我們還在本部落格中提供了相關的程式碼指標。執行用於擴充套件 FLAVA 的示例指令碼的說明可以在此處找到。
FLAVA 擴充套件概述
FLAVA 是一種基礎多模態模型,由基於 Transformer 的影像和文字編碼器組成,然後是一個基於 Transformer 的多模態融合模組。它使用各種損失在單模態和多模態資料上進行預訓練。這包括掩碼語言、影像和多模態建模損失,這些損失要求模型從其上下文(自監督學習)重建原始輸入。它還使用影像文字匹配損失對對齊影像-文字對的正例和負例以及 CLIP 風格的對比損失進行訓練。除了多模態任務(如影像-文字檢索)之外,FLAVA 在單模態基準(NLP 的 GLUE 任務和視覺的影像分類)上也表現出有競爭力的效能。
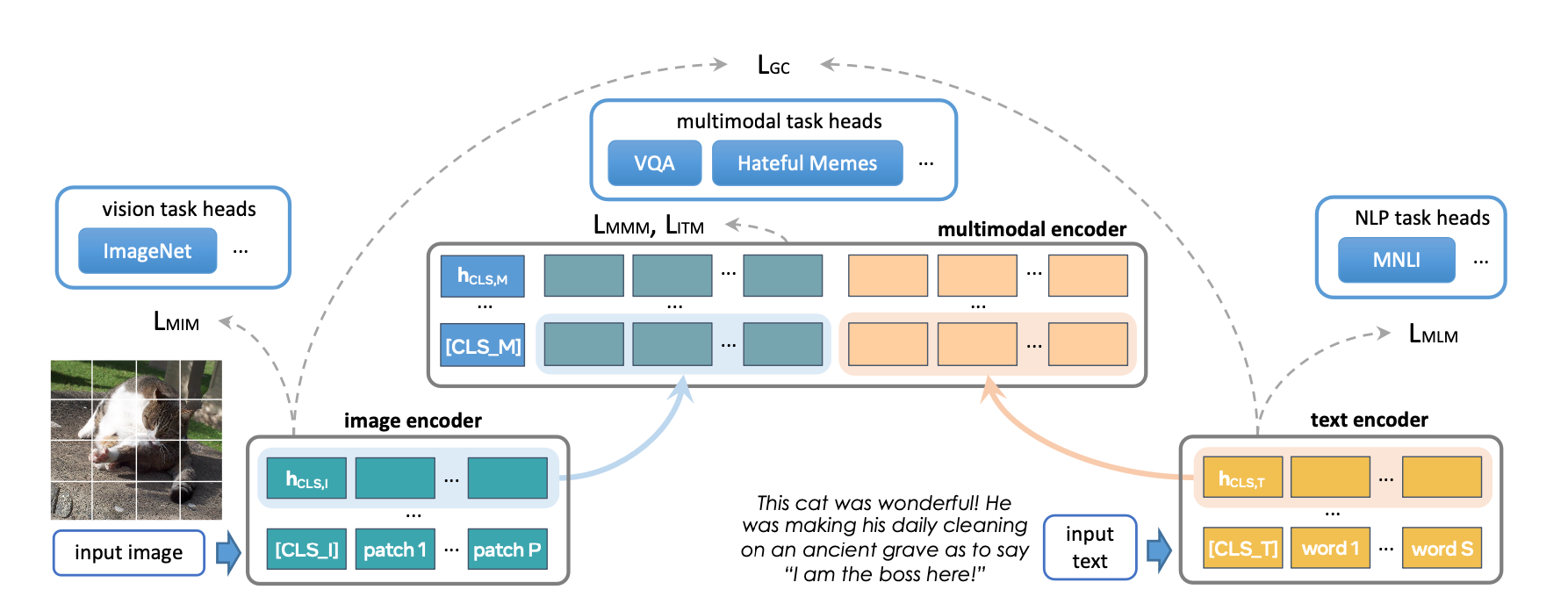
原始 FLAVA 模型有大約 3.5 億個引數,並使用 ViT-B16 配置(來自 Vision Transformer 論文)用於影像和文字編碼器。多模態融合 Transformer 遵循單模態編碼器,但層數減半。我們探索將每個編碼器的大小增加到更大的 ViT 變體。
擴充套件的另一個方面是增加批次大小的能力。FLAVA 利用批次內負樣本上的對比損失,這通常受益於大批次大小(如此處研究)。當在 GPU 記憶體允許的最大批次大小附近操作時,通常也能實現最大的訓練效率或吞吐量(另請參見實驗部分)。
下表顯示了我們實驗的不同模型配置。我們還在實驗部分確定了每種配置能夠適應記憶體的最大批次大小。
| 近似模型引數 | 隱藏大小 | MLP 大小 | 頭數 | 單模態層數 | 多模態層數 | 模型大小 (fp32) |
|---|---|---|---|---|---|---|
| 3.5 億(原始) | 768 | 3072 | 12 | 12 | 6 | 1.33 GB |
| 9 億 | 1024 | 4096 | 16 | 24 | 12 | 3.48 GB |
| 18 億 | 1280 | 5120 | 16 | 32 | 16 | 6.66 GB |
| 27 億 | 1408 | 6144 | 16 | 40 | 20 | 10.3 GB |
| 48 億 | 1664 | 8192 | 16 | 48 | 24 | 18.1 GB |
| 100 億 | 2048 | 10240 | 16 | 64 | 40 | 38 GB |
最佳化概述
PyTorch 提供了多種原生技術來有效地擴充套件模型。在接下來的章節中,我們將介紹其中一些技術,並展示如何將它們應用於將 FLAVA 模型擴充套件到 100 億個引數。
分散式資料並行
分散式訓練的常見起點是資料並行。資料並行將模型複製到每個 worker(GPU),並將資料集分割槽到 worker。不同的 worker 並行處理不同的資料分割槽,並在模型權重更新之前同步其梯度(透過 all reduce)。下圖展示了資料並行處理單個示例的流程(前向、反向和權重更新步驟)
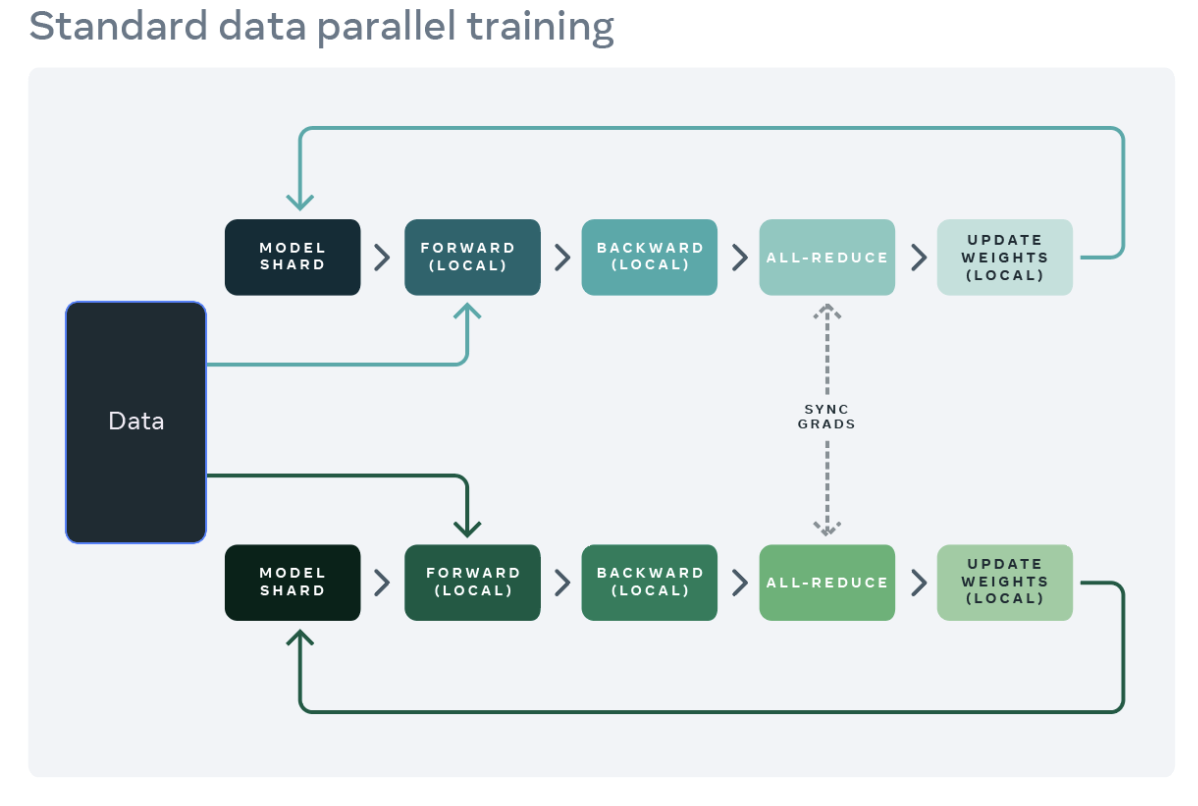
來源:https://engineering.fb.com/2021/07/15/open-source/fsdp/
PyTorch 提供了一個原生 API,DistributedDataParallel (DDP) 來啟用資料並行,它可以作為模組包裝器使用,如下所示。有關更多詳細資訊,請參閱 PyTorch 分散式文件。
from torchmultimodal.models.flava.model import flava_model_for_pretraining
import torch
import torch.distributed as dist
model = flava_model_for_pretraining().cuda()
# Initialize PyTorch Distributed process groups
# Please see https://pytorch.com.tw/tutorials/intermediate/dist_tuto.html for details
dist.init_process_group(backend=”nccl”)
# Wrap model in DDP
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[torch.cuda.current_device()])
完全分片資料並行
訓練應用程式的 GPU 記憶體使用量大致可分為模型輸入、中間啟用(用於梯度計算)、模型引數、梯度和最佳化器狀態。擴充套件模型通常會增加這些元素的每一個。使用 DDP 擴充套件模型最終可能導致記憶體不足問題,因為單個 GPU 的記憶體不足以容納所有引數、梯度和最佳化器狀態,因為它會在所有 worker 上覆制這些內容。
為了減少這種複製並節省 GPU 記憶體,我們可以將模型引數、梯度和最佳化器狀態分片到所有 worker 上,每個 worker 只管理一個分片。這種技術由微軟開發的 ZeRO-3 方法推廣開來。PyTorch 1.12 釋出了這種方法的 PyTorch 原生實現,作為 FullyShardedDataParallel (FSDP) API 的 Beta 功能。在模組的前向和反向傳播過程中,FSDP 會根據計算需要取消分片模型引數(使用 all-gather),並在計算後重新分片它們。它使用 reduce-scatter 集合操作同步梯度,以確保分片梯度在全球範圍內平均。下面詳細介紹了使用 FSDP 封裝的模型的前向和反向傳播流程
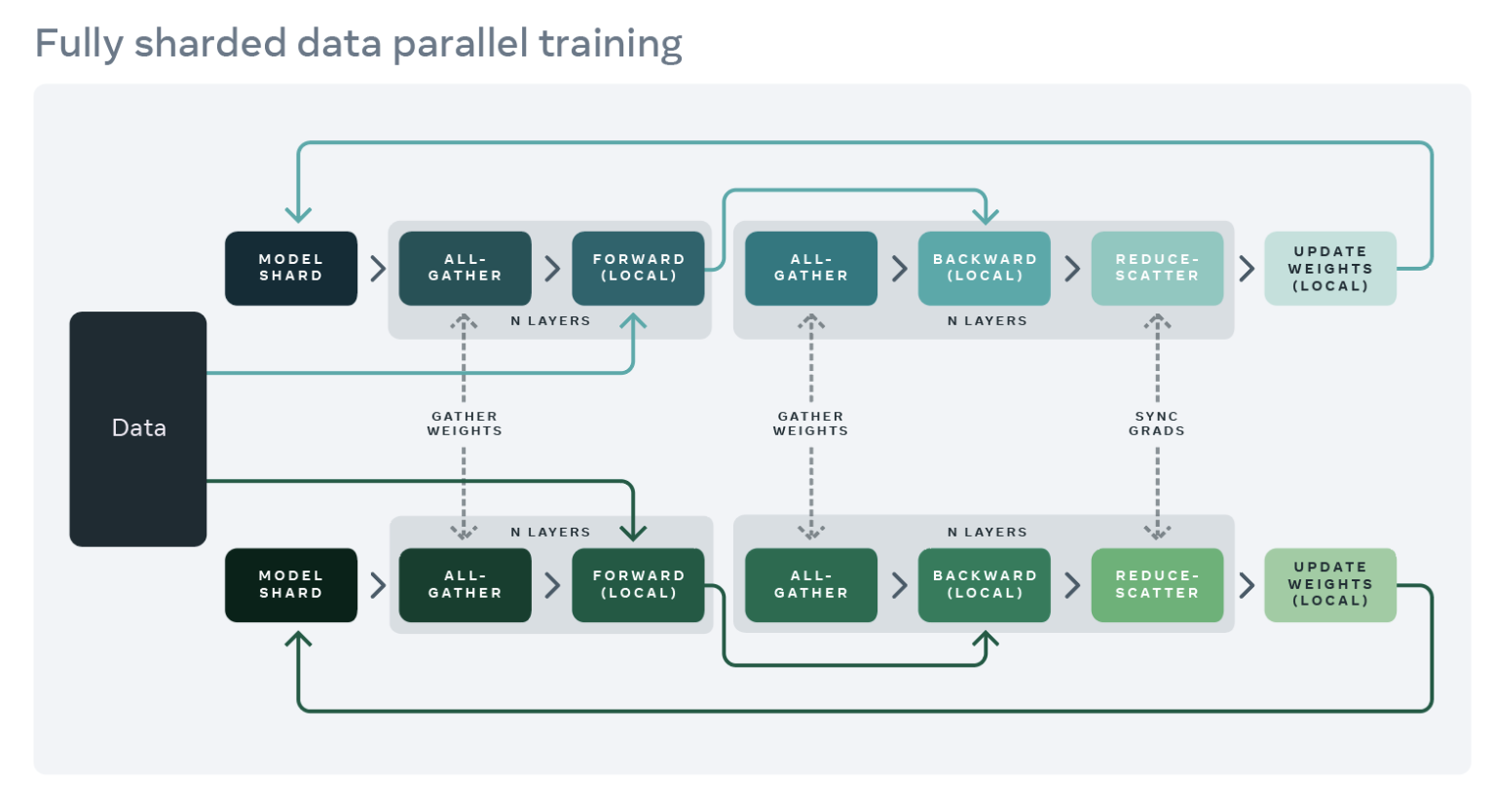
來源:https://engineering.fb.com/2021/07/15/open-source/fsdp/
要使用 FSDP,模型的子模組需要用 API 包裝,以控制何時分片或取消分片特定子模組。FSDP 提供了一個可以開箱即用的自動包裝 API(請參閱 auto_wrap_policy 引數)以及多種包裝策略和編寫自己的策略的能力。
以下示例演示了使用 FSDP 封裝 FLAVA 模型。我們將自動封裝策略指定為 transformer_auto_wrap_policy。這將把單個 Transformer 層 (TransformerEncoderLayer)、影像 Transformer (ImageTransformer)、文字編碼器 (BERTTextEncoder) 和多模態編碼器 (FLAVATransformerWithoutEmbeddings) 封裝為獨立的 FSDP 單元。這使用了遞迴封裝方法以實現高效記憶體管理。例如,在單個 Transformer 層的前向或反向傳播完成後,其引數將被丟棄,從而釋放記憶體,從而降低峰值記憶體使用量。
FSDP 還提供了許多可配置選項來調整應用程式的效能。例如,在我們的用例中,我們演示了使用新的 limit_all_gathers 標誌,它可以防止過早地收集所有模型引數,從而減輕應用程式的記憶體壓力。我們鼓勵使用者嘗試使用此標誌,它可能會提高具有高活動記憶體使用量的應用程式的效能。
import torch
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
from torch.distributed.fsdp.wrap import transformer_auto_wrap_policy
from torchmultimodal.models.flava.model import flava_model_for_pretraining
from torchmultimodal.models.flava.text_encoder import BertTextEncoder
from torchmultimodal.models.flava.image_encoder import ImageTransformer
from torchmultimodal.models.flava.transformer import FLAVATransformerWithoutEmbeddings
from torchmultimodal.modules.layers.transformer import TransformerEncoderLayer
model = flava_model_for_pretraining().cuda()
dist.init_process_group(backend=”nccl”)
model = FSDP(
model,
device_id=torch.cuda.current_device(),
auto_wrap_policy=partial(
transformer_auto_wrap_policy,
transformer_layer_cls={
TransformerEncoderLayer,
ImageTransformer,
BERTTextEncoder,
FLAVATransformerWithoutEmbeddings
},
),
limit_all_gathers=True,
)
啟用檢查點
如上所述,中間啟用、模型引數、梯度和最佳化器狀態共同構成了整體 GPU 記憶體使用量。FSDP 可以減少後三者造成的記憶體消耗,但不能減少啟用消耗的記憶體。啟用使用的記憶體隨著批次大小或隱藏層數量的增加而增加。啟用檢查點是一種透過在反向傳播期間重新計算啟用而不是將它們保留在特定檢查點模組的記憶體中來減少記憶體使用量的技術。例如,我們觀察到在將啟用檢查點應用於 2.7B 引數模型後,前向傳播後的峰值活動記憶體減少了約 4 倍。
PyTorch 提供了一個基於包裝器的啟用檢查點 API。特別是,checkpoint_wrapper 允許使用者使用檢查點包裝單個模組,而 apply_activation_checkpointing 允許使用者指定一個策略來包裝整體模組中的模組。這兩個 API 都可以應用於大多數模型,因為它們不需要對模型定義程式碼進行任何修改。但是,如果需要對檢查點片段進行更精細的控制,例如檢查點模組中的特定函式,則可以使用函式式 torch.utils.checkpoint API,儘管這需要修改模型程式碼。下面顯示了將啟用檢查點包裝器應用於單個 FLAVA Transformer 層(由 TransformerEncoderLayer 表示)。有關啟用檢查點的詳細描述,請參閱 PyTorch 文件中的描述。
from torchmultimodal.models.flava.model import flava_model_for_pretraining
from torch.distributed.algorithms._checkpoint.checkpoint_wrapper import apply_activation_checkpointing, checkpoint_wrapper, CheckpointImpl
from torchmultimodal.modules.layers.transformer import TransformerEncoderLayer
model = flava_model_for_pretraining()
checkpoint_tformer_layers_policy = lambda submodule: isinstance(submodule, TransformerEncoderLayer)
apply_activation_checkpointing(
model,
checkpoint_wrapper_fn=checkpoint_wrapper,
check_fn=checkpoint_tformer_layers_policy,
)
結合使用,如上所示,使用啟用檢查點封裝 FLAVA Transformer 層,並使用 FSDP 封裝整個模型,我們能夠將 FLAVA 擴充套件到 100 億個引數。
實驗
我們對上一節中不同最佳化對系統性能的影響進行了實證研究。對於我們所有的實驗,我們使用一個帶有 8 個 A100 40GB GPU 的單節點,並進行 1000 次迭代的預訓練。所有執行都使用 PyTorch 的 自動混合精度 和 bfloat16 資料型別。TensorFloat32 格式也已啟用,以提高 A100 上的矩陣乘法效能。我們將吞吐量定義為每秒處理的平均專案數(文字或影像)(我們在測量吞吐量時忽略前 100 次迭代以考慮預熱)。我們將在未來研究訓練收斂及其對下游任務指標的影響。
圖 1 繪製了每種模型配置和最佳化的吞吐量,分別使用區域性批次大小為 8 和單個節點上可能的最大批次大小。模型變體在最佳化中沒有資料點表示該模型無法在單個節點上進行訓練。
圖 2 繪製了每種最佳化每個 worker 可能的最大批次大小。我們觀察到一些現象:
- 模型大小擴充套件:DDP 只能在一個節點上容納 3.5 億和 9 億引數的模型。透過 FSDP,由於節省了記憶體,我們能夠訓練比 DDP 大約 3 倍的模型(即 18 億和 27 億引數的變體)。將啟用檢查點 (AC) 與 FSDP 結合使用,可以訓練更大的模型,比 DDP 大約 10 倍(即 48 億和 100 億引數的變體)。
- 吞吐量
- 對於較小的模型尺寸,在批次大小保持為 8 的情況下,DDP 的吞吐量略高於或等於 FSDP,這可以透過 FSDP 所需的額外通訊來解釋。當 FSDP 和 AC 結合使用時,吞吐量最低。這是因為 AC 在反向傳播過程中重新執行檢查點的前向傳播,以計算量換取記憶體節省。然而,在 27 億引數模型的情況下,FSDP + AC 的吞吐量實際上高於單獨使用 FSDP。這是因為即使在批次大小為 8 時,使用 FSDP 的 27 億引數模型也接近記憶體限制,從而觸發 CUDA malloc 重試,這往往會減慢訓練速度。AC 有助於減輕記憶體壓力,並避免重試。
- 對於 DDP 和 FSDP + AC,每個模型的吞吐量都隨著批次大小的增加而增加。對於單獨的 FSDP,這適用於較小的變體。然而,對於 18 億和 27 億引數的模型,我們觀察到在增加批次大小時吞吐量下降。造成這種情況的一個潛在原因(如上所述)是,在記憶體限制下,PyTorch 的 CUDA 記憶體管理可能不得不重試 cudaMalloc 呼叫和/或執行昂貴的碎片整理步驟以查詢空閒記憶體塊來處理工作負載的記憶體需求,這可能導致訓練速度變慢。
- 對於只能使用 FSDP 訓練的較大模型(18 億、27 億、48 億),實現最高吞吐量的設定是 FSDP + AC 擴充套件到最大批次大小。對於 100 億引數模型,我們觀察到較小批次大小和最大批次大小的吞吐量幾乎相等。這可能與直覺相反,因為 AC 會增加計算量,並且最大批次大小可能會導致由於在 CUDA 記憶體限制下執行而產生昂貴的碎片整理操作。然而,對於這些大型模型,批次大小的增加足以掩蓋這種開銷。
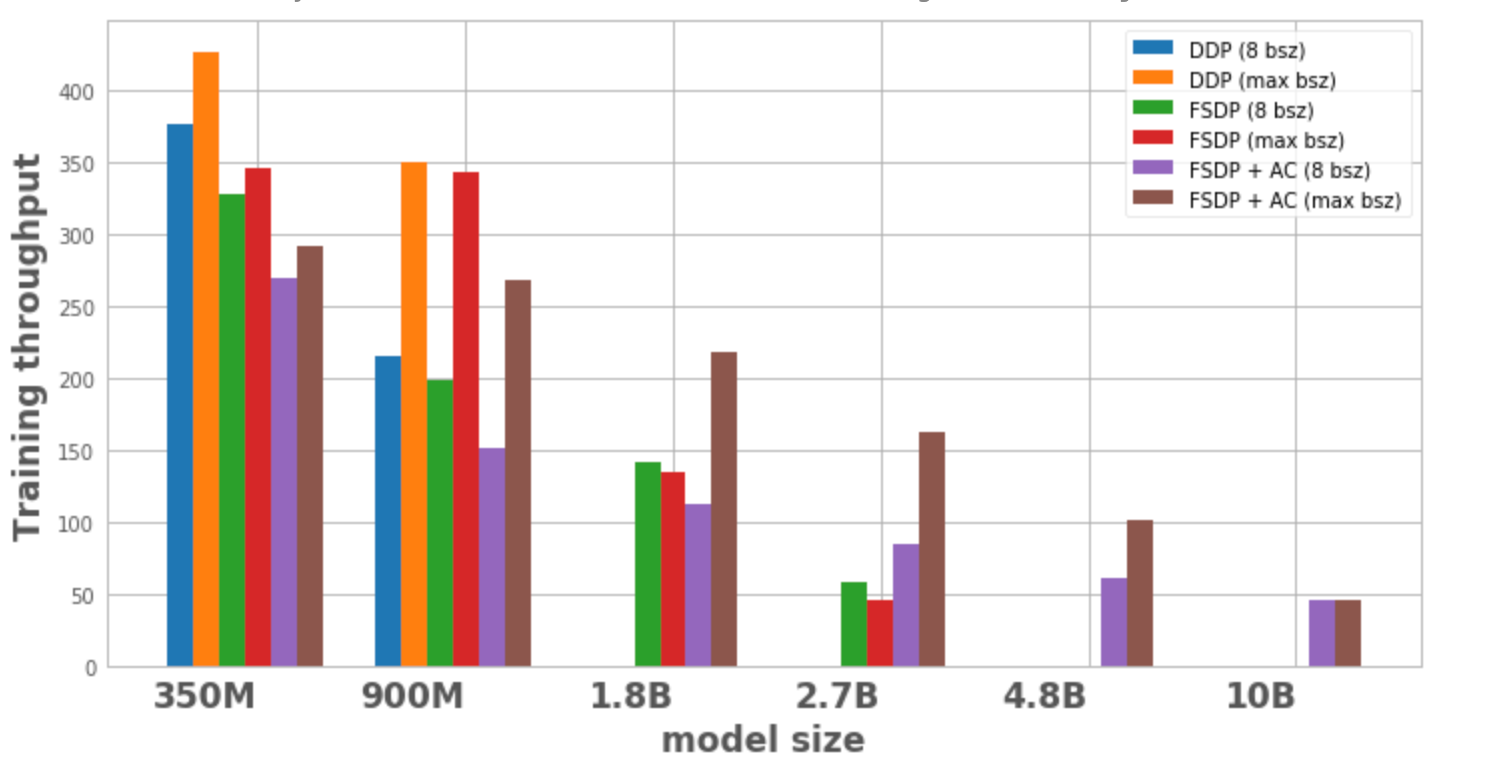
圖 1:不同配置的訓練吞吐量
- 批次大小:單獨的 FSDP 能夠實現比 DDP 略高的批次大小。對於 3.5 億引數模型,使用 FSDP + AC 可以實現比 DDP 大約 3 倍的批次大小,對於 9 億引數模型,可以實現大約 5.5 倍的批次大小。即使對於 100 億引數模型,最大批次大小約為 20,這已經相當不錯了。這實質上允許使用更少的 GPU 實現更大的全域性批次大小,這對於對比學習任務特別有用。
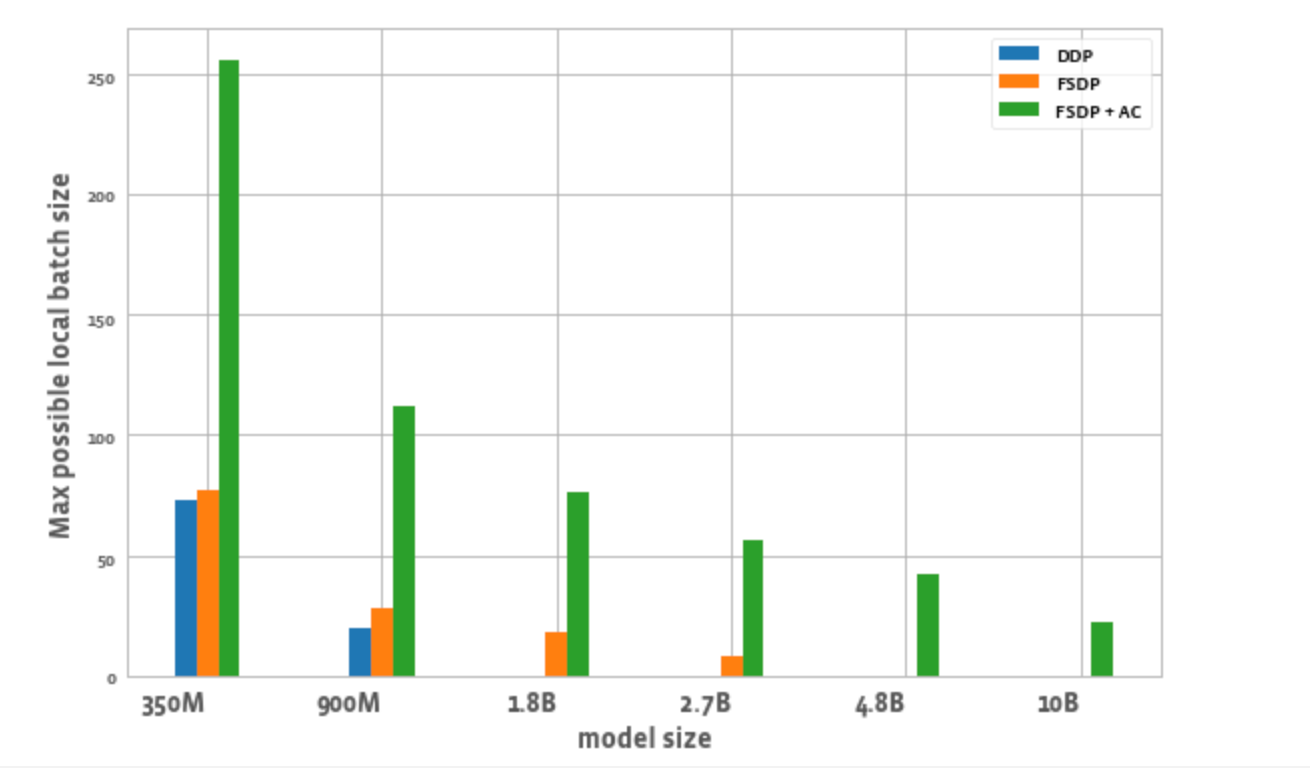
圖 2:不同配置可能的最大區域性批次大小
結論
隨著世界邁向多模態基礎模型,擴充套件模型引數和高效訓練正成為關注的焦點。PyTorch 生態系統旨在透過為研究社群提供用於訓練和擴充套件多模態模型的不同工具來加速該領域的創新。透過 FLAVA,我們提供了一個擴充套件多模態理解模型的示例。未來,我們計劃增加對其他型別模型(如多模態生成模型)的支援,並展示它們的擴充套件因素。我們還希望自動化許多這些擴充套件和記憶體節省技術(如分片和啟用檢查點),以減少使用者為實現所需規模和最大訓練吞吐量所需的實驗量。