鑑於基礎模型的出現和成功,許多企業對使用雲原生方法進行大型模型訓練的興趣日益增長。一些人工智慧從業者可能認為,要實現分散式訓練作業的高 GPU 利用率,唯一的方法是在 HPC 系統(例如透過 Infiniband 互連的系統)上執行它們,並且可能不考慮乙太網連線的系統。我們演示了 PyTorch 最新的分散式訓練技術——完全分片資料並行 (FSDP) 如何在 IBM Cloud 中使用商用乙太網成功擴充套件到引數超過 100 億的模型。
PyTorch FSDP 擴充套件
隨著模型變得越來越大,標準的資料並行訓練技術僅在 GPU 能夠容納模型的完整副本及其訓練狀態(最佳化器、啟用等)時才有效。然而,GPU 記憶體的增加未能跟上模型大小的增加,因此出現了訓練此類模型的新技術(例如,完全分片資料並行、DeepSpeed),這使我們能夠在訓練期間有效地將模型和資料分佈到多個 GPU 上。在這篇博文中,我們展示了一種方法,可以使用 PyTorch 原生 FSDP API 將模型訓練顯著擴充套件到 64 個節點(512 個 GPU),同時將模型大小增加到 110 億。
什麼是完全分片資料並行?
FSDP 透過將模型引數、梯度和最佳化器狀態分片到 K 個 FSDP 單元(由包裝策略決定)來擴充套件分散式資料並行訓練 (DDP) 方法。FSDP 透過顯著減少每個 GPU 上的記憶體佔用並重疊計算和通訊,在資源和效能方面實現了大型模型訓練效率。
透過讓所有 GPU 擁有每個 FSDP 單元的一部分來減少記憶體佔用,從而實現資源效率。為了處理給定的 FSDP 單元,所有 GPU 透過 all_gather 通訊呼叫共享其本地擁有的部分。
透過將即將到來的 FSDP 單元的 all_gather 通訊呼叫與當前 FSDP 單元的計算重疊,實現效能效率。一旦當前 FSDP 單元處理完畢,非本地擁有的引數將被丟棄,從而為即將到來的 FSDP 單元釋放記憶體。此過程透過計算和通訊的重疊實現訓練效率,同時還減少了每個 GPU 所需的峰值記憶體。
接下來,我們將演示 FSDP 如何使我們能夠在分散式訓練作業中保持數百個 GPU 的高利用率,同時在標準乙太網網路上執行(系統描述在部落格末尾)。我們選擇 T5 架構進行實驗,並利用了FSDP 研討會的程式碼。在我們的每個實驗中,我們都從單個節點實驗開始建立基線,並報告按批大小歸一化的每迭代秒數指標,並根據Megatron-LM 論文計算 teraflops(有關 T5 的 teraflop 計算詳情,請參見附錄)。我們的實驗旨在最大化批大小(同時避免 cudaMalloc 重試),以充分利用計算和通訊中的重疊,如下所述。擴充套件被定義為 N 個節點的每迭代秒數(按批大小歸一化)與單個節點的比率,表示隨著新增更多節點,我們能多好地利用額外的 GPU。
實驗結果
我們使用 T5-3B 配置(BF16 混合精度、啟用檢查點和 Transformer 包裝策略)進行的第一組實驗表明,隨著我們將 GPU 數量從 8 個增加到 512 個(分別對應 1 到 64 個節點),擴充套件效率達到 95%。我們無需對現有 FSDP API 進行任何修改就取得了這些結果。我們觀察到,在這種規模下,基於乙太網的網路有足夠的頻寬來實現通訊和計算的持續重疊。
然而,當我們將 T5 模型大小增加到 110 億時,擴充套件效率大幅下降至 20%。PyTorch 分析器顯示,通訊和計算的重疊非常有限。進一步調查網路頻寬使用情況表明,重疊不佳是由單個數據包通訊中的延遲引起的,而不是所需的頻寬(事實上,我們的峰值頻寬利用率僅為可用頻寬的 1/4)。這使我們推測,如果透過增加批大小來增加計算時間,我們可以更好地重疊通訊和計算。然而,鑑於我們已經達到最大 GPU 記憶體分配,我們必須尋找重新平衡記憶體分配的機會,以允許增加批大小。我們發現模型狀態分配的記憶體比實際需要的多得多。這些預留的主要功能是預留記憶體,以便在通訊期間積極傳送/接收張量,而緩衝區過少會導致等待時間增加,而緩衝區過多會導致批大小減小。
為了實現更高的效率,PyTorch 分散式團隊引入了一個新的控制旋鈕,即 `rate_limiter`,它控制為張量傳送/接收分配的記憶體量,從而緩解記憶體壓力併為更高的批次大小提供空間。在我們的案例中,`rate_limiter` 可以將批次大小從 20 增加到 50,從而將計算時間增加 2.5 倍,並允許通訊和計算之間有更大的重疊。透過此修復,我們將擴充套件效率提高到 >75%(在 32 個節點上)!
對限制擴充套件效率的因素的持續調查發現,速率限制器正在建立 GPU 空閒時間的重複流水線氣泡。這是由於速率限制器對每組記憶體緩衝區的分配和釋放採用了阻塞和重新整理方法。透過等待整個塊完成才啟動新的 all_gather,GPU 在每個塊開始時都處於空閒狀態,等待新的 all_gather 引數集到達。透過採用滑動視窗方法緩解了這種氣泡。在單個 all_gather 步驟及其計算完成(而不是一整塊)後,記憶體被釋放,並且下一個 all_gather 以更均勻的方式立即發出。這一改進消除了流水線氣泡,並將擴充套件效率提高到 >90%(在 32 個節點上)。
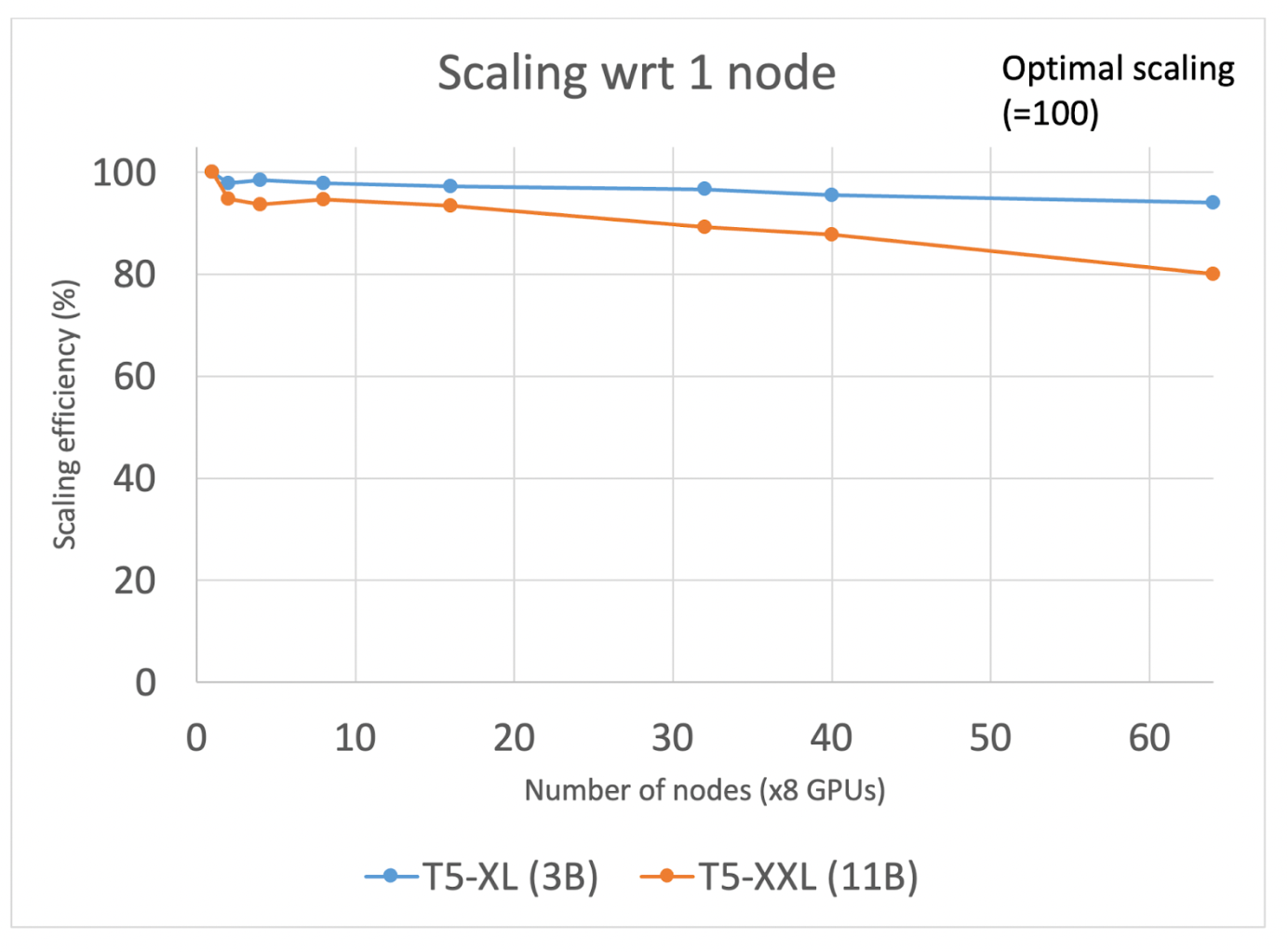
圖 1:T5-XL (3B) 和 T5-XXL (11B) 從 1 個節點擴充套件到 64 個節點
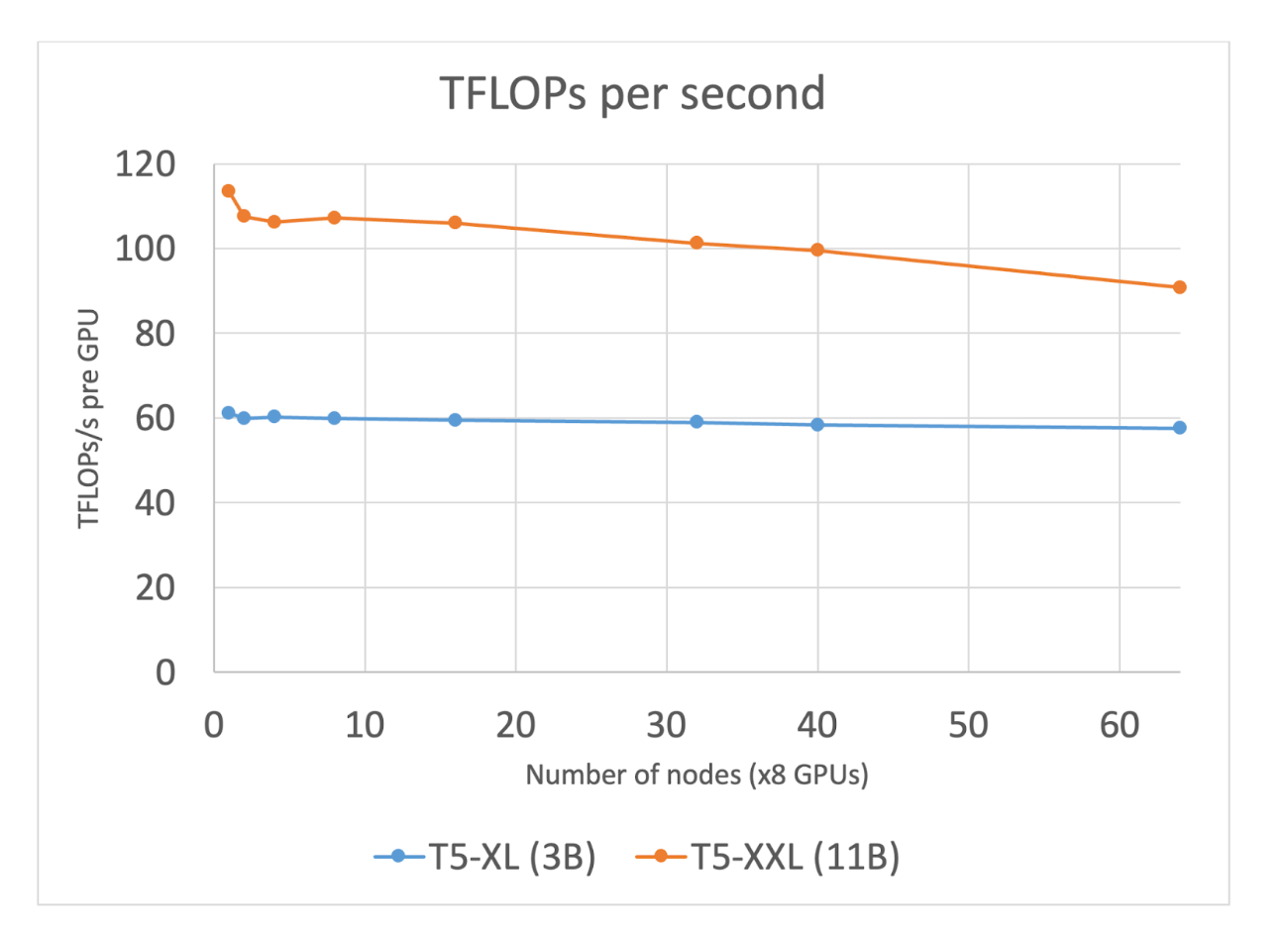
圖 2:隨著節點數量的增加,T5-XL(3B) 和 T5-XXL (11B) 的 TFLOPs/sec 使用量
IBM Cloud AI 系統和中介軟體
用於此工作的 AI 基礎設施是 IBM Cloud 上的一個大規模 AI 系統,由近 200 個節點組成,每個節點都配備 8 塊 NVIDIA A100 80GB 顯示卡、96 個 vCPU 和 1.2TB CPU RAM。節點內的 GPU 顯示卡透過 NVLink 連線,卡間頻寬為 600GBps。節點透過 2 條 100Gbps 乙太網鏈路連線,採用基於 SRIOV 的 TCP/IP 堆疊,提供 120Gbps 的可用頻寬。
IBM Cloud AI 系統自 2022 年 5 月起已準備好投入生產,並配置了 OpenShift 容器平臺以執行 AI 工作負載。我們還構建了一個用於生產 AI 工作負載的軟體堆疊,提供端到端工具用於訓練工作負載。該中介軟體利用 Ray 進行預處理和後處理工作負載,並利用 PyTorch 進行模型訓練。我們還集成了 Kubernetes 原生排程器 MCAD,它透過作業排隊、組排程、優先順序和配額管理來管理多個作業。多 NIC CNI 發現所有可用的網路介面,並將其作為一個單一的 NIC 池進行處理,從而最佳化 Kubernetes 中網路介面的使用。最後,CodeFlare CLI 支援使用桌面 CLI(例如,GPU 利用率、損失、梯度範數等應用程式指標)對整個堆疊進行單一面板的可觀察性。
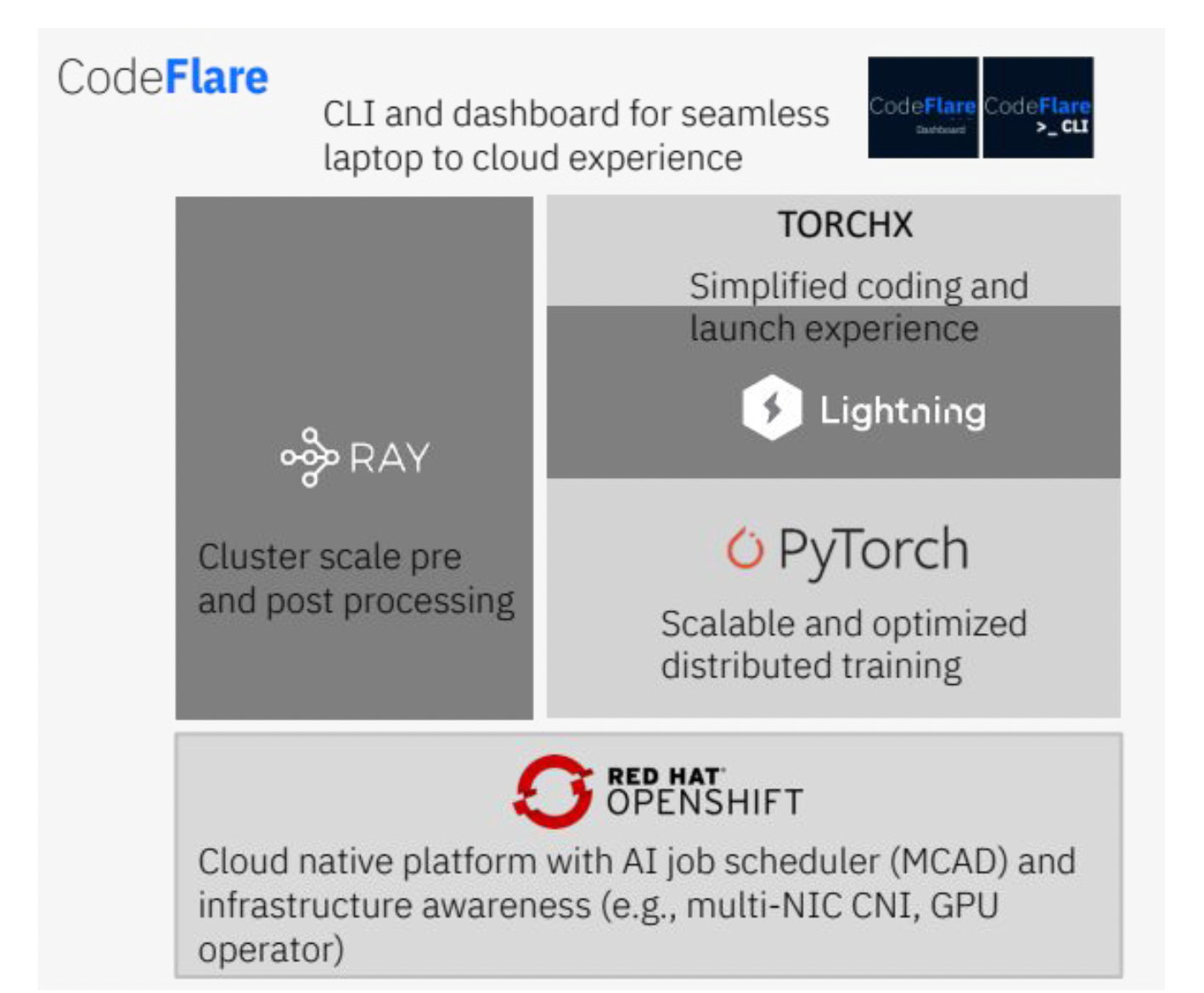
圖 3:基礎模型中介軟體堆疊
結論和未來工作
總之,我們演示瞭如何在非 InfiniBand 網路上實現 FSDP API 的卓越擴充套件。我們確定了限制 110 億引數模型訓練效率低於 20% 的瓶頸。在識別問題後,我們透過新的速率限制器控制解決了這個問題,以確保預留記憶體和通訊重疊相對於計算時間達到更最佳化的平衡。透過這一改進,我們成功地將 110 億引數模型的訓練效率提高到 90%(提高了 4.5 倍,在 256 個 GPU 上)和 80%(在 512 個 GPU 上)。此外,即使我們將 GPU 數量增加到 512 個,30 億引數模型的擴充套件效率也極高,達到 95%。
這是業界首次使用 Kubernetes、標準乙太網和 PyTorch 原生 FSDP API,實現高達 110 億引數模型的如此高的擴充套件效率。這一改進使使用者能夠以經濟高效和可持續的方式在混合雲平臺上訓練大型模型。
我們計劃繼續研究僅解碼器模型的擴充套件,並將這些模型的規模擴大到 1000 億個引數以上。從系統設計的角度來看,我們正在探索 RoCE 和 GDR 等功能,這些功能可以改善乙太網網路上的通訊延遲。
致謝
本部落格的實現得益於 PyTorch 分散式團隊和 IBM 研究團隊的貢獻。
我們衷心感謝 PyTorch 分散式團隊的 Less Wright、Hamid Shojanazeri、Geeta Chauhan、Shen Li、Rohan Varma、Yanli Zhao、Andrew Gu、Anjali Sridhar、Chien-Chin Huang 和 Bernard Nguyen。
我們衷心感謝 IBM 研究團隊的 Linsong Chu、Sophia Wen、Lixiang (Eric) Luo、Marquita Ellis、Davis Wertheimer、Supriyo Chakraborty、Raghu Ganti、Mudhakar Srivatsa、Seetharami Seelam、Carlos Costa、Abhishek Malvankar、Diana Arroyo、Alaa Youssef 和 Nick Mitchell。
附錄
浮點運算次數計算
T5-XXL(110 億)架構有兩種型別的 T5 塊,一種是編碼器,另一種是解碼器。遵循 Megatron-LM 的方法,其中每個矩陣乘法需要 2m×k×n 次浮點運算,第一個矩陣的大小為 m×k,第二個矩陣的大小為 k×n。編碼器塊由自注意力層和前饋層組成,而解碼器塊由自注意力層、交叉注意力層和前饋層組成。
注意力塊(自注意力和交叉注意力)包括 QKV 投影,需要 6Bsh2 次操作;注意力矩陣計算,需要 2Bs2h 次操作;對值的注意力,需要 2Bs2h 次計算;以及注意力後線性投影,需要 2Bsh2 次操作。最後,前饋層需要 15Bsh2 次操作。
編碼器塊的總數為 23Bsh2+4Bs2h,而解碼器塊的總數為 31Bsh2+8Bs2h。總共有 24 個編碼器和 24 個解碼器塊,以及 2 個前向傳播(因為我們丟棄了啟用)和 1 個後向傳播(相當於 2 個前向傳播),最終的 FLOPs 計算結果為 96×(54Bsh2+ 12Bs2h) + 6BshV。其中,B 是每個 GPU 的批大小,s 是序列長度,h 是隱藏狀態大小,V 是詞彙大小。我們對略有不同的 T5-XL(30 億)架構重複了類似的計算。