TLDR:在單個 NVIDIA GH200 上高效地對 GPT-OSS-20B 和 Qwen3-14B 模型進行全引數微調,在四個 NVIDIA GH200 超級晶片上對 Llama3-70B 進行微調,同時提供高達 600 TFLOPS 的訓練吞吐量。
目錄
- SuperOffload:在超級晶片上釋放大規模 LLM 訓練的強大潛力
- SuperOffload 亮點
- 引言
- SuperOffload 工作原理
- 1. 推測然後驗證 (STV)
- 2. 異構最佳化器計算
- 3. 超級晶片感知型別轉換
- 4. 用於最佳化器效率的 GraceAdam
- 經驗與見解
- 入門
- 致謝
SuperOffload 亮點
- 單個 GH200: 對 GPT-OSS-20B、Qwen3-14B 進行完全微調,最高可達 600 TFLOPS。
- 多 GPU: 在 2 個 NVIDIA GH200 上執行 Qwen3-30B-A3B 和 Seed-OSS-36B;在 4 個 NVIDIA GH200 上執行 Llama-70B。
- 更快的訓練: 與 ZeRO-Offload 等現有工作相比,吞吐量提高達 4 倍。
- 更高的 GPU 利用率: 將 GPU 利用率從約 50% 提升至 >80%。
- 工程和可組合性: 適用於 ZeRO-3 和 Ulysses;操作技巧(例如,NUMA 繫結、MPAM)已在教程中記錄。
引言
緊密耦合的異構 GPU/CPU 架構(又稱超級晶片,例如 NVIDIA GH200、GB200 和 AMD MI300A)的出現,為大規模人工智慧提供了新的最佳化機會。然而,如何最好地利用這種新硬體進行大規模 LLM 訓練仍有待探索。現有的解除安裝解決方案是為傳統的松耦合架構設計的,在超級晶片上表現不佳,存在高開銷和低 GPU 利用率的問題。為了解決這一差距並充分利用超級晶片進行高效 LLM 訓練,我們開發並開源了 SuperOffload。
SuperOffload 引入了一系列新穎的技術,可以在 LLM 訓練中同時充分利用 Hopper GPU、Grace CPU 和 NVLink-C2C。與假設 GPU-CPU 互連速度慢(例如,PCIe-Gen4 為 64GB/秒)的現有解除安裝解決方案不同,SuperOffload 利用更快的互連(例如,NVLink-C2C 為 900GB/秒)來提高 GPU 和 CPU 利用率以及訓練吞吐量。使用 SuperOffload,像 GPT-OSS-20B、Qwen3-14B 和 Phi-4 這樣的模型可以在單個 GH200 上進行完全微調,在適度設定下(序列長度 4k,批大小 4)提供高達 600 TFLOPS 的訓練吞吐量。這比 ZeRO-Offload 等現有工作高出高達 4 倍 的吞吐量。SuperOffload 甚至可以擴充套件到更大的模型,包括在兩個 GH200 上執行 Qwen3-30B-A3B 和 Seed-OSS-36B,以及在四個 GH200 上執行 Llama-70B。
SuperOffload 構建在 DeepSpeed ZeRO Stage 3 之上,並可在 DeepSpeed 版本 >= 0.18.0 中使用。為了方便整合到 LLM 微調管道中,SuperOffload 與 Hugging Face Transformers 相容,並且不需要對模型程式碼進行任何更改。
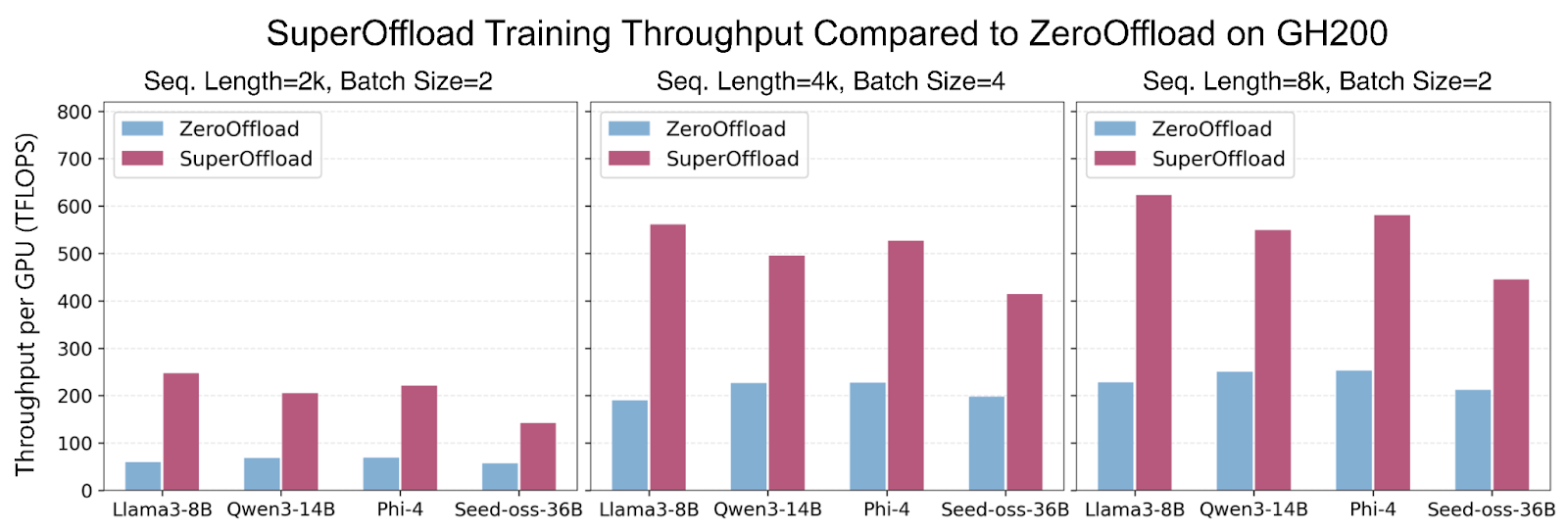
圖 1:SuperOffload 在不同序列長度和批大小的大模型微調中,吞吐量比 ZeRO-Offload 高達 4 倍,最高可達 600 TFLOPS。
SuperOffload 工作原理
SuperOffload 包含四種可組合的解除安裝最佳化技術:(1)推測然後驗證,(2)GPU/CPU 最佳化器計算,(3)超級晶片感知型別轉換,以及(4)GraceAdam。下面我們簡要介紹這些技術。
1. 推測然後驗證 (STV)
在大多數解除安裝解決方案中,最佳化器步驟中需要 CPU 和 GPU 之間的同步以確保數值魯棒性。例如,裁剪梯度範數需要計算全域性梯度範數,混合精度訓練需要全域性檢查 NaN 和 INF 值。這些操作要求 CPU 在收到所有梯度後才能執行最佳化器步驟和權重更新。STV 透過打破這種依賴性來避免此瓶頸,但透過將 CPU 上的推測最佳化器計算與 GPU 上的反向傳播重疊,仍然保留了訓練的語義。當梯度後處理最終完成時,推測最佳化器計算將根據需要提交、丟棄或正確重播。STV 對訓練穩定性的後驗證使其能夠與之前的預驗證方法相比,安全地縮短關鍵路徑。下圖說明了 SuperOffload 如何以與傳統方法(如 ZeRO-Offload)不同的方式排程反向傳播和最佳化器計算。
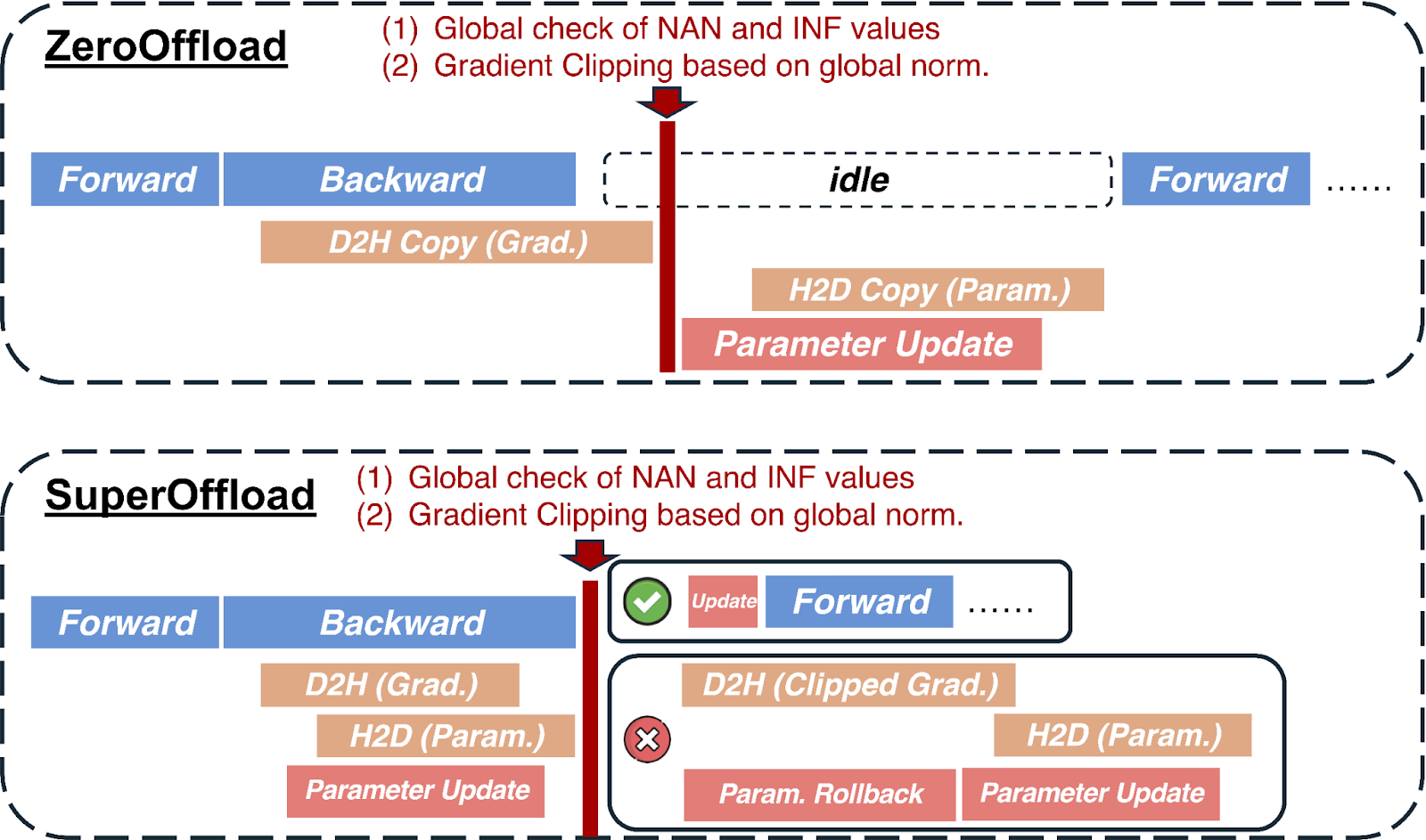
圖 2:之前的解除安裝方法存在全域性梯度範數和 NaN 和 INF 值的全域性檢查問題,這使得最佳化器步驟暴露在關鍵路徑上,並阻礙了重疊機會。在 SuperOffload 中,我們引入了推測然後驗證排程來解決這個問題。
我們透過測量 BLOOM-176B 模型預訓練執行中撤銷推測最佳化器計算的頻率來評估 STV 的有效性。如下圖所示,這種回滾(例如,由於梯度裁剪等)在熱身期後很少發生,使得相關開銷在整個訓練執行中可以忽略不計。這使得 STV 在加速大規模訓練方面具有實用性。
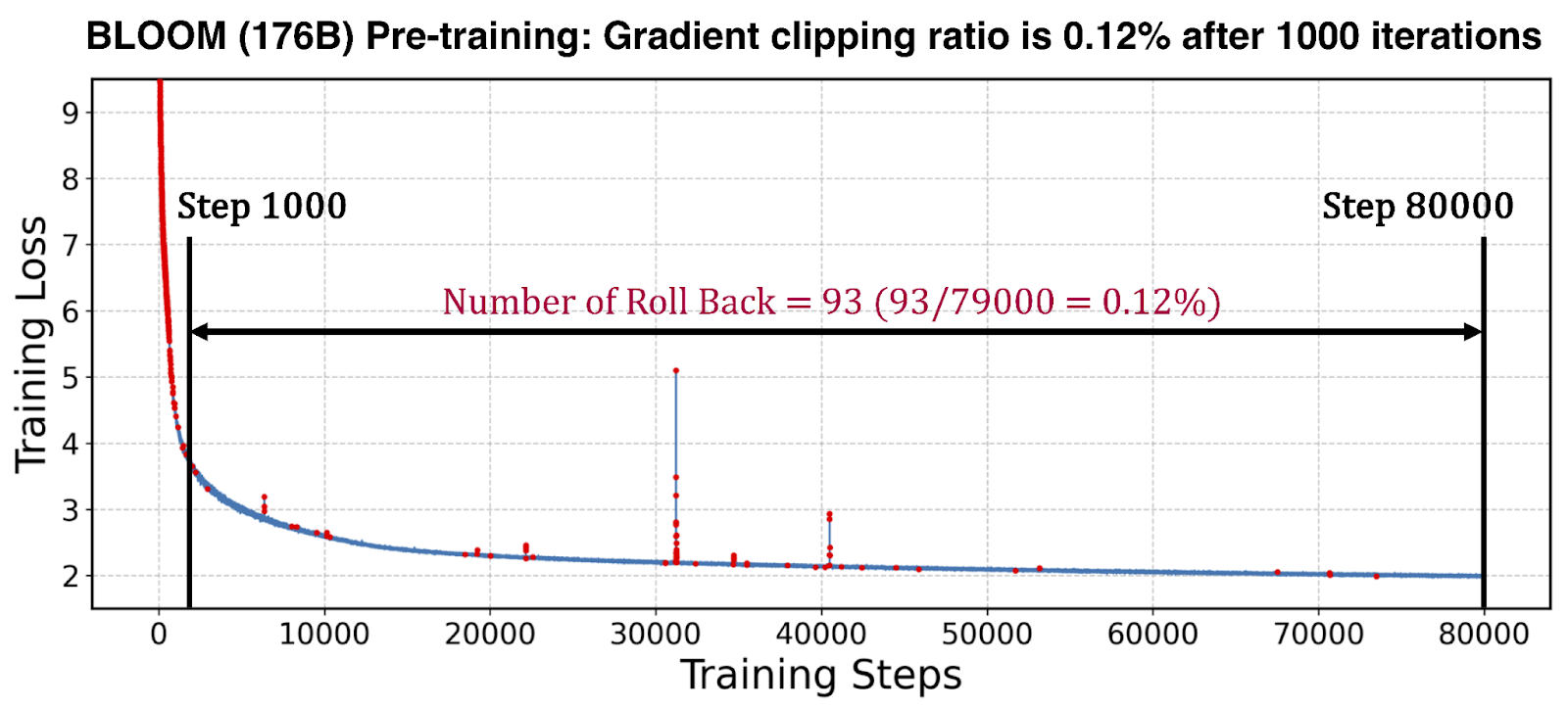
圖 3:紅點表示 BLOOM 預訓練期間觸發的梯度裁剪——熱身期後很少發生,這表明 SuperOffload 的 STV 機制有效消除了由梯度裁剪和 NaN/INF 檢查引起的同步造成的停頓。
2. 異構最佳化器計算
SuperOffload 透過在 GPU 和 CPU 之間劃分最佳化器計算來提高最佳化器效率。GPU 用於反向傳播後期建立的梯度的最佳化器計算,而 CPU 處理其餘部分。這種劃分方案有多種好處。首先,GPU 避免了空閒等待 CPU 上的最佳化器計算完成。其次,透過利用 GPU 和 CPU 計算,最佳化器計算得到減少。第三,可以避免與 GPU 最佳化器計算對應的引數和梯度在 GPU-CPU 之間傳輸。
3. 超級晶片感知型別轉換
在具有解除安裝功能的混合精度訓練中,GPU 和 CPU 之間的張量傳輸需要 GPU 上的低精度格式(例如 BF16、FP16 等)和 CPU 上的高精度格式(即 FP32)之間進行型別轉換。為了解決 PCIe 互連的頻寬限制,以前的解除安裝解決方案以低精度傳輸張量,並在 GPU 和 CPU 上根據需要進行型別轉換。然而,這在超級晶片架構上是一種次優策略,因為 GPU 計算吞吐量比 CPU 高約 100 倍,並且高頻寬互連(例如 NVLink-C2C)使傳輸成本可以忽略不計。如圖 4 所示,GH200 上的最佳策略是在 GPU 上進行張量型別轉換並以高精度格式傳輸。
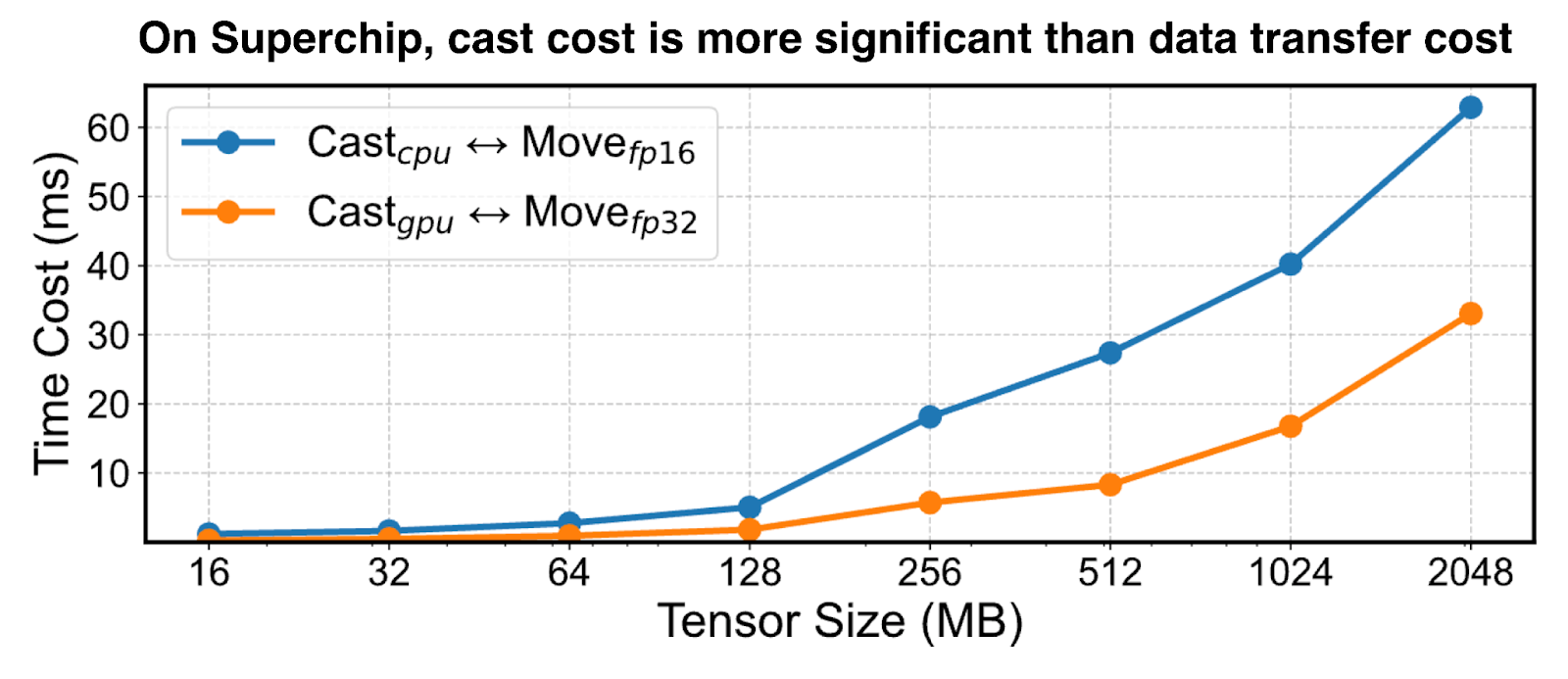
圖 4:GH200:在 GPU 上將張量轉換為低/高精度並以高精度傳輸在超級晶片上更高效。
4. 用於最佳化器效率的 GraceAdam
現有的 LLM 訓練解除安裝解決方案需要流行 Adam 最佳化器的 CPU 實現,例如 PyTorch Adam 和 DeepSpeed CPU-Adam。然而,這些對於超級晶片來說是不夠的,因為它們沒有針對 Grace CPU 架構進行最佳化。為了解決這個問題,我們建立了 GraceAdam,這是一種針對 Grace CPU 的高效 Adam 最佳化器實現。GraceAdam 利用底層 ARM 架構特性,例如可伸縮向量擴充套件 (SVE)、顯式記憶體層次結構管理和指令級並行性,實現了高效能。下圖 5 顯示,在 GH200 超級晶片上,GraceAdam 比 PyTorch Adam (PT-CPU) 快 3 倍,比 CPU-Adam 快 1.3 倍。據我們所知,GraceAdam 是第一個針對 Grace CPU 開源的 Adam 最佳化器實現。
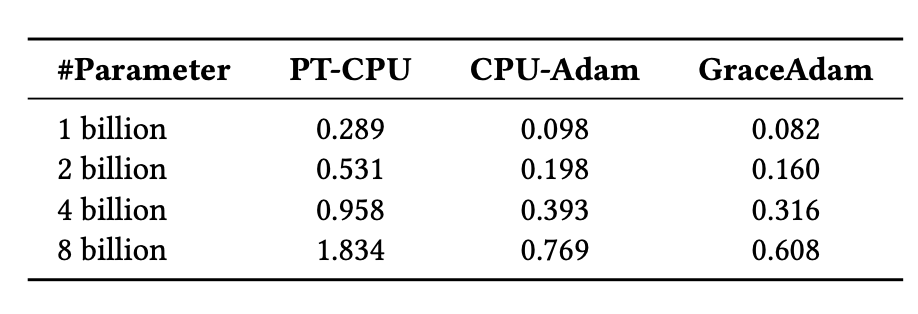
圖 5:使用 GraceAdam 在 GH200 上高效進行 Adam 最佳化器計算。
經驗與見解
- NUMA 繫結: 將每個 GPU 與其直接關聯的 CPU 配對,以最大化頻寬。在 DeepSpeed 中:
--bind_cores_to_rank
- MPAM(記憶體系統資源分割槽和監控): 減少 CPU 和 GPU 之間的干擾。
如何在 NVIDIA 超級晶片上啟用 MPAM:
# i. Install the kernel from NVIDIA NV-Kernels. # ii. Check MPAM support: grep MPAM /boot/config-$(uname -r) # Expected output: CONFIG_ARM64_MPAM=y CONFIG_ACPI_MPAM=y CONFIG_ARM64_MPAM_DRIVER=y CONFIG_ARM64_MPAM_RESCTRL_FS=y # Verify resctrl filesystem: ls -ld /sys/fs/resctrl # iii. Mount resctrl: mount -t resctrl resctrl /sys/fs/resctrl # iv. Create partitions: mkdir /sys/fs/resctrl/p1 /sys/fs/resctrl/p2 # v. Set CPU cores & memory configs (example from experiments): /sys/fs/resctrl/p1/cpus_list: 0-6 /sys/fs/resctrl/p2/cpus_list: 7-71 /sys/fs/resctrl/p1/schemata: MB:1=100 L3:1=ff0 /sys/fs/resctrl/p2/schemata: MB:1=20 L3:1=f
入門
使用 SuperOffload 的端到端微調示例可在我們的教程/自述檔案中找到:DeepSpeedExamples:SuperOffload。要快速啟用 SuperOffload,請將以下開關新增到您的 DeepSpeed 配置中(有關完整上下文,請參閱教程):
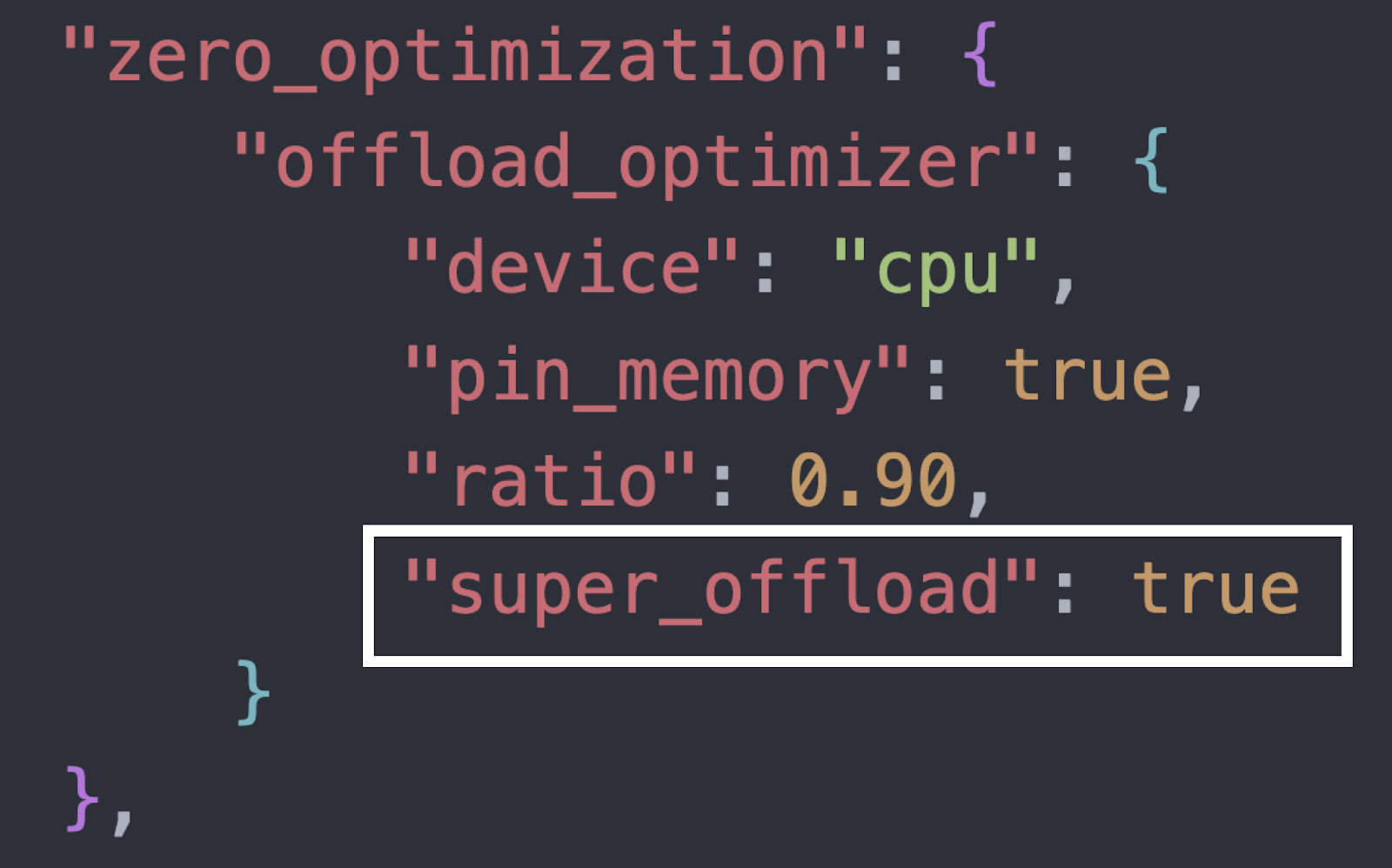
圖 6:在 DeepSpeed 配置中透過一行程式碼啟用 SuperOffload。
提示:在超級晶片平臺(例如 GH200/GB200/MI300A)上,結合“經驗與見解”中的 NUMA 繫結和 MPAM 設定,以穩定頻寬並提高階到端效能。
致謝
這項工作是 伊利諾伊大學厄巴納-香檳分校 (UIUC)、Anyscale 和 Snowflake 之間的緊密合作。
我們還要感謝國家超級計算應用中心 (NCSA) 的 William Gropp、Brett Bode 和 Gregory H. Bauer,以及 NVIDIA 的 Dan Ernst、Ian Karlin、Giridhar Chukkapalli、Kurt Rago 和其他人,感謝他們在 Grace CPU 上支援 MPAM 方面提供的寶貴討論和指導。
歡迎社群反饋和貢獻。有關啟用和示例,請參閱上面的“入門”。
BibTeX
@inproceedings{superoffload, author = {Xinyu Lian and Masahiro Tanaka and Olatunji Ruwase and Minjia Zhang}, title = "{SuperOffload: Unleashing the Power of Large-Scale LLM Training on Superchips}", year = {2026}, booktitle = {Proceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating System (ASPLOS'26)} }