透過 TorchAO 團隊、ExecuTorch 團隊和 Unsloth 之間的合作,PyTorch 現在提供 Phi4-mini-instruct、Qwen3、SmolLM3-3B 和 gemma-3-270m-it 的原生量化變體!這些模型利用 int4 和 float8 量化,在 A100、H100 和移動裝置上提供高效推理,同時與 bfloat16 模型相比,模型質量幾乎沒有或沒有下降。亮點:
- 我們釋出了針對伺服器和移動平臺最佳化的預量化模型:供希望在生產中部署更快模型的使用者使用
- 我們釋出了全面、可復現的量化方案和指南,涵蓋模型質量評估和效能基準測試:供將 PyTorch 原生量化應用於自己的模型和資料集的使用者使用
- 您還可以使用 unsloth 進行微調,並使用 TorchAO 量化微調後的模型
訓練後量化模型和可復現方案
到目前為止,我們已經發布了以下 Phi4-mini-instruct、Qwen3、SmolLM3-3B 和 gemma-3-270m-it 的量化變體:
| 量化方法 | 結果 | 模型 |
| 使用 hqq 演算法和 AWQ 的 Int4 僅權重(weight only)量化(適用於伺服器 H100 和 A100 GPU) |
|
Phi-4-mini-instruct-INT4 Phi-4-mini-instruct-AWQ-INT4 Qwen3-8B-INT4 Qwen3-8B-AWQ-INT4 |
| Float8 動態啟用和 float8 權重量化(適用於伺服器 H100 GPU) |
|
gemma-3-270m-it-torchao-FP8 Phi-4-mini-instruct-FP8 Qwen3-32B-FP8 |
| Int8 動態啟用和 int4 權重量化(適用於移動 CPU) |
|
Phi-4-mini-instruct-INT8-INT4 Qwen3-4B-INT8-INT4 SmolLM3-3B-INT8-INT4 |
上述每個模型在其模型卡中都包含使用 TorchAO 庫的可復現量化方案。這意味著您也可以使用 TorchAO 量化其他模型。
整合
PyTorch 原生量化模型受益於 PyTorch 生態系統中的強大整合,可提供滿足不同部署需求的穩健、高效能量化解決方案。
以下是我們在整個技術棧中用於量化、微調、評估模型質量、延遲和部署模型的工具。已釋出的量化模型和量化方案在模型準備和部署的整個生命週期中無縫協作。
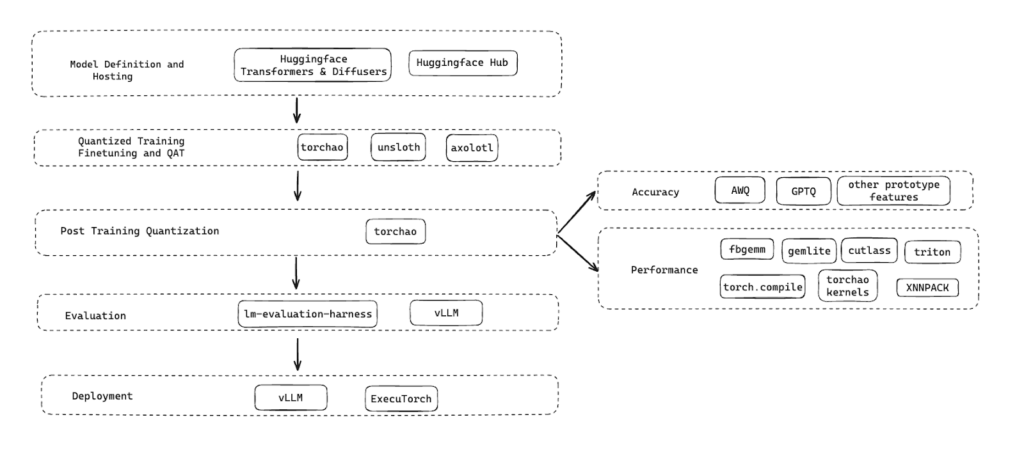
下一步
- 新功能
- 推理和訓練的 MoE 量化
- 新的資料型別支援:NVFP4
- 更多保持準確性的訓練後量化技術,例如 SmoothQuant、GPTQ、SpinQuant
- 合作
- 繼續與 unsloth 合作,向其使用者提供 TorchAO,用於微調、QAT、訓練後量化,併發布 TorchAO 量化模型
- 我們正在與 vLLM 合作,利用 FBGEMM 的快速核心,實現最佳化的端到端伺服器推理效能
行動號召
請嘗試我們的模型和量化方案,並透過在 TorchAO 中提出 問題 或在 已釋出模型頁面 開始討論,讓我們知道您的想法。您也可以在我們的 Discord 頻道 與我們聯絡。我們也很想了解社群目前如何量化模型,並希望未來在 HuggingFace 上合作釋出量化模型。