今天,我們釋出了 torchchat,這是一個展示如何無縫且高效能地在筆記型電腦、桌上型電腦和移動裝置上執行 Llama 3、3.1 及其他大型語言模型的庫。
在我們之前的部落格文章中,我們 展示了 如何使用原生 PyTorch 2 結合 CUDA 以出色的效能執行大型語言模型。Torchchat 在此基礎上進行了擴充套件,支援更多的目標環境、模型和執行模式。此外,它還以易於理解的方式提供了重要的功能,如匯出、量化和評估,為那些希望構建本地推理解決方案的人提供了一個端到端的故事。
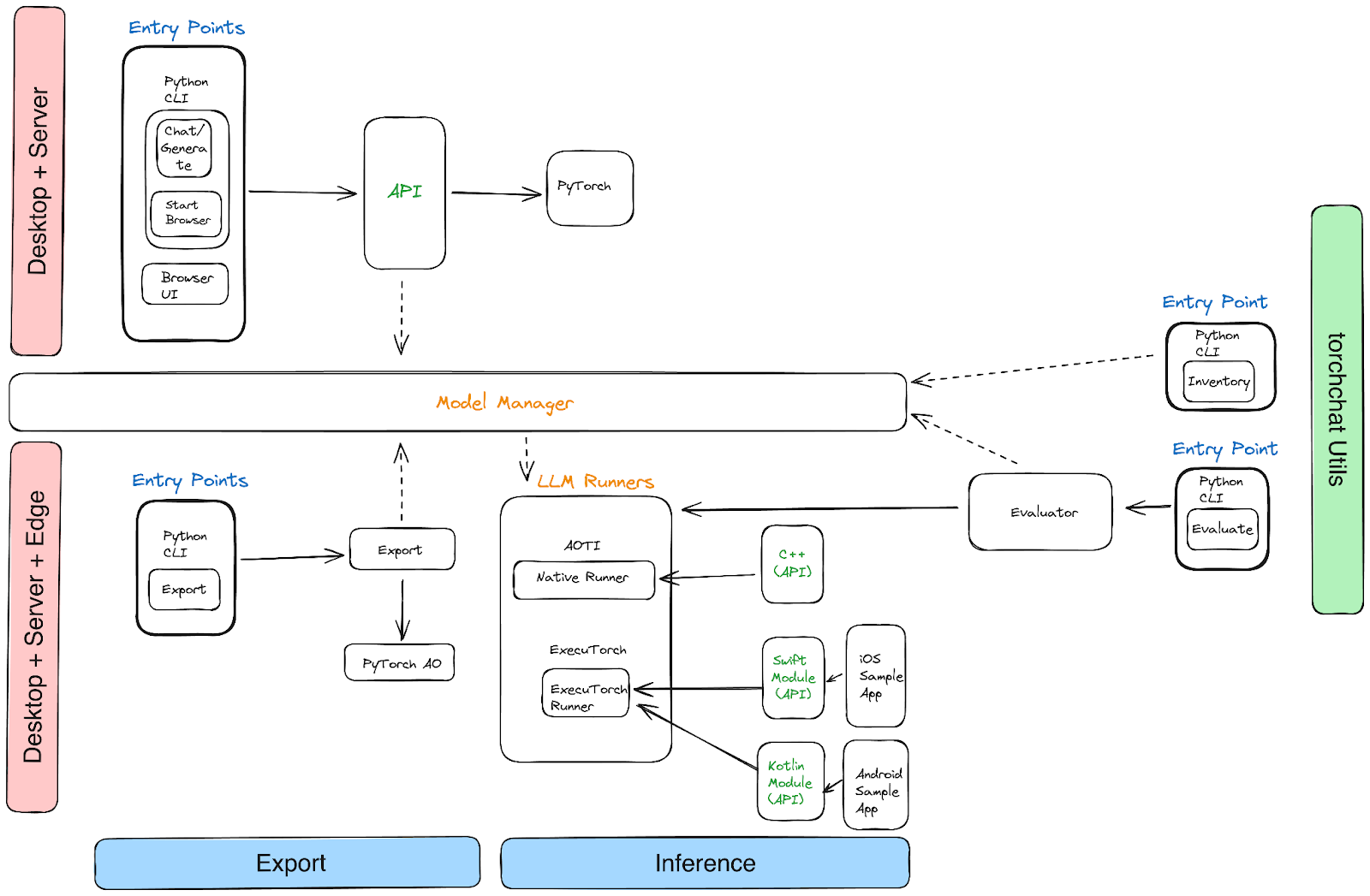
該專案分為三個部分:
- Python:Torchchat 提供了一個 REST API,可以透過 Python CLI 呼叫,也可以透過瀏覽器訪問。
- C++:Torchchat 使用 PyTorch 的 AOTInductor 後端生成適用於桌面的二進位制檔案。
- 移動裝置:Torchchat 使用 ExecuTorch 匯出 .pte 二進位制檔案以進行裝置上推理。
效能
下表記錄了 torchchat 在不同配置下 Llama 3 的效能。
Llama 3.1 的資料即將釋出。
在 Apple MacBook Pro M1 Max 64GB 筆記型電腦上執行 Llama 3 8B Instruct
| 模式 | 資料型別 | Llama 3 8B 每秒 token 數 |
| Arm 編譯 | float16 | 5.84 |
| int8 | 1.63 | |
| int4 | 3.99 | |
| Arm AOTI | float16 | 4.05 |
| int8 | 1.05 | |
| int4 | 3.28 | |
| MPS Eager | float16 | 12.63 |
| int8 | 16.9 | |
| int4 | 17.15 |
在 Linux x86 和 CUDA 上執行 Llama 3 8B Instruct
Intel(R) Xeon(R) Platinum 8339HC CPU @ 1.80GHz with 180GB Ram + A100 (80GB)
| 模式 | 資料型別 | Llama 3 8B 每秒 token 數 |
| x86 編譯 | bfloat16 | 2.76 |
| int8 | 3.15 | |
| int4 | 5.33 | |
| CUDA 編譯 | bfloat16 | 83.23 |
| int8 | 118.17 | |
| int4 | 135.16 |
在移動裝置上執行 Llama3 8B Instruct
Torchchat 使用 ExecuTorch 透過 4 位 GPTQ 在三星 Galaxy S23 和 iPhone 上實現了 > 8T/s 的效能。
結論
我們鼓勵您 克隆 torchchat 倉庫並試用它,探索其功能,並分享您的反饋,因為我們將繼續賦能 PyTorch 社群在本地和受限裝置上執行大型語言模型。讓我們攜手在任何裝置上釋放生成式 AI 和大型語言模型的全部潛力。請在發現 問題 時及時提交,因為我們仍在快速迭代。我們還邀請社群在廣泛的領域做出貢獻,包括更多模型、目標硬體支援、新的量化方案或效能改進。祝您實驗愉快!