我們很高興正式宣佈 torchcodec,這是一個用於將影片解碼為 PyTorch 張量的庫。它快速、準確且易於使用。在影片上執行 PyTorch 模型時,torchcodec 是我們將這些影片轉換為模型可用資料的推薦方式。
torchcodec 的亮點包括
- 直觀的解碼 API,將影片檔案視為幀的 Python 序列。我們支援基於索引和基於顯示時間的幀檢索。
- 強調準確性:我們確保您獲得請求的幀,即使您的影片具有可變幀率。
- 豐富的取樣 API,使檢索幀批次變得簡單高效。
- 一流的 CPU 解碼效能。
- CUDA 加速解碼,可在同時解碼大量影片時實現高吞吐量。
- 支援您已安裝的 FFmpeg 版本中所有可用的編解碼器。
- 適用於 Linux 和 Mac 的簡單二進位制安裝。
易於使用
簡單直觀的 API 是我們主要的設計原則之一。我們從簡單的解碼和提取影片特定幀開始
from torchcodec.decoders import VideoDecoder
from torch import Tensor
decoder = VideoDecoder("my_video.mp4")
# Index based frame retrieval.
first_ten_frames: Tensor = decoder[10:]
last_ten_frames: Tensor = decoder[-10:]
# Multi-frame retrieval, index and time based.
frames = decoder.get_frames_at(indices=[10, 0, 15])
frames = decoder.get_frames_played_at(seconds=[0.2, 3, 4.5])
所有解碼的幀都是 PyTorch 張量,可以直接輸入模型進行訓練。
當然,在 ML 訓練管道中更常見的是從影片中取樣多個片段。片段只是按顯示順序排列的幀序列——但這些幀通常並*不*是連續的。我們的取樣 API 使這變得簡單
from torchcodec.samplers import clips_at_regular_timestamps
clips = clips_at_regular_timestamps(
decoder,
seconds_between_clip_starts=10,
num_frames_per_clip=5,
seconds_between_frames=0.2,
)
上述呼叫生成一批片段,其中每個片段相隔 10 秒開始,每個片段包含 5 幀,這些幀相隔 0.2 秒。有關更多資訊,請參閱我們的 解碼 和 取樣 教程!
快速效能
效能是我們的另一個主要設計原則。用於 ML 訓練的影片解碼與用於播放的影片解碼具有不同的效能要求。典型的 ML 影片訓練管道將處理許多不同的影片(有時高達數百萬!),但每個影片只採樣少量幀(幾十到幾百)。
因此,我們特別關注解碼器在影片中多次查詢、每次查詢後解碼少量幀時的效能。我們提供了以下四種場景的實驗
- 同時解碼和轉換來自多個影片的幀,靈感來自我們在大規模訓練管道資料載入中看到的情況:a. 十個執行緒並行解碼 50 個影片批次。
b. 對於每個影片,在均勻間隔的時間解碼 10 幀。
c. 對於每個幀,將其大小調整為 256×256 解析度。 - 在單個影片中隨機位置解碼 10 幀。
- 在單個影片的均勻間隔時間解碼 10 幀。
- 解碼單個影片的前 100 幀。
我們比較了以下影片解碼器
- Torchaudio,僅限 CPU 解碼。
- Torchvision,使用 video_reader 後端,僅限 CPU 解碼。
- Torchcodec,使用 CUDA 進行 GPU 解碼。
- Torchcodec,僅限 CPU 解碼。
使用以下三個影片
- 使用 FFmpeg 的 mandelbrot 生成模式合成生成的影片。影片長 10 秒,每秒 60 幀,解析度為 1920×1080。
- 與上面相同,但影片長 120 秒。
- NASA 的宣傳影片,長 206 秒,每秒 29.7 幀,解析度為 960×540。
實驗指令碼 在我們的倉庫中。我們的實驗在具有 22 個可用核心的 Intel 處理器和 NVIDIA GPU 的 Linux 系統上執行。對於 CPU 解碼,所有庫都指示自動確定要使用的最佳執行緒數。
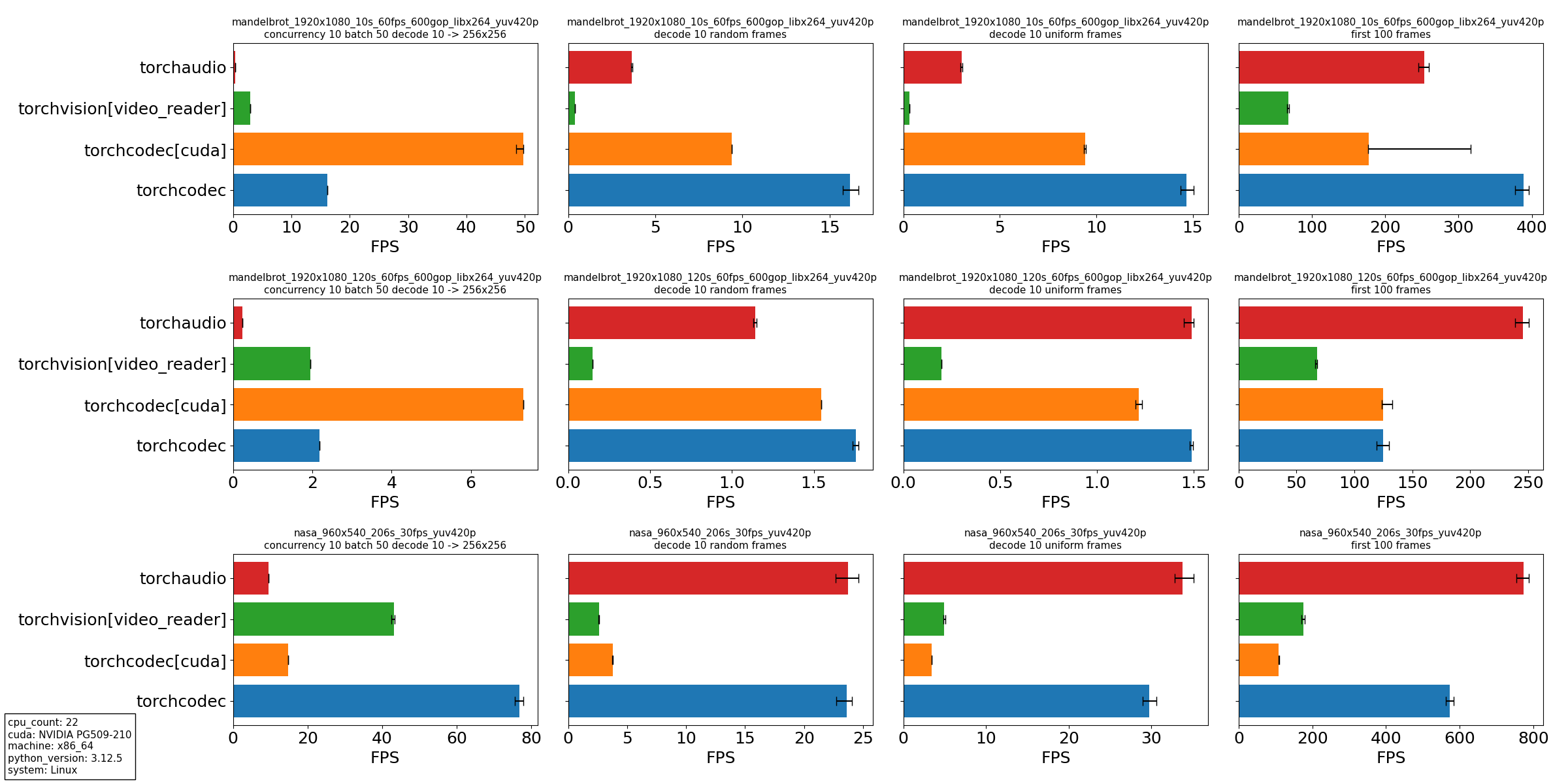
從我們的實驗中,我們得出幾個結論
- 對於我們設計它的主要用例,torchcodec 始終是表現最佳的庫:作為訓練資料載入管道的一部分,一次解碼多個影片。特別是,高解析度影片在 CUDA 中獲得了巨大的收益,解碼和轉換都在 GPU 上進行。
- torchcodec 在 CPU 上具有查詢密集型用例(如隨機和均勻取樣)的競爭力。目前,torchcodec 的效能在檔案大小較短的影片上更好。這種效能是由於 torchcodec 強調查詢準確性,這涉及到初始的線性掃描。
- 在沒有查詢的情況下,即開啟影片檔案並從頭開始解碼時,torchcodec 的競爭力不如其他庫。這再次歸因於我們對查詢準確性和初始線性掃描的強調。
在 torchcodec 中實現 近似查詢模式 應該可以解決這些效能差距,這是我們影片解碼的最高優先順序功能。
下一步是什麼?
顧名思義,torchcodec 的長期未來不僅僅是影片解碼。我們的下一個重要功能是音訊支援——從影片中解碼音訊流,以及從純音訊媒體中解碼音訊流。從長遠來看,我們希望 torchcodec 成為 PyTorch 的媒體解碼庫。這意味著隨著我們在 torchcodec 中實現功能,我們將棄用並最終移除 torchaudio 和 torchvision 中互補的功能。
我們還計劃了影片解碼改進,例如前面提到的近似查詢模式,適用於那些願意犧牲準確性以獲得性能的使用者。
最重要的是,我們正在尋求社群的反饋!我們最感興趣的是開發社群認為有價值的功能。歡迎 分享您的需求 並影響我們未來的方向!