我們很高興地宣佈 TorchRec 和 FBGEMM 的 1.0 穩定版釋出。TorchRec 是 PyTorch 原生的推薦系統庫,由 FBGEMM(Facebook GEneral Matrix Multiplication)高效的低階核心提供支援。
TorchRec
最初於 2022 年開源,TorchRec 提供了用於建立最先進個性化模型的常用原語
- 用於在數百個 GPU 上進行分散式訓練的簡單、最佳化的 API
- 用於嵌入的高階分片技術
- 推薦系統編寫中常用的模組
- 透過 TorchRec 模型的量化和分片 API,實現分散式推理的無縫路徑
自那時起,TorchRec 取得了顯著的成熟,在 Meta 的許多生產推薦模型中被廣泛採用,用於訓練和推理,並新增了諸如:可變批次嵌入、嵌入解除安裝、零衝突雜湊等功能。此外,TorchRec 在 Meta 之外也佔有一席之地,例如 Databricks 的推薦模型和 Twitter 演算法。因此,標準的 TorchRec 功能已被標記為 stable,並具有 PyTorch 風格的 BC 保證,可在改版後的 TorchRec 文件中檢視。
FBGEMM
FBGEMM 是一個為 CPU 和 GPU 提供高效能核心的庫。自 2018 年以來,FBGEMM 透過將其範圍從 CPU 推理的效能關鍵核心擴充套件到 CPU 和 GPU 上訓練和推理的更復雜稀疏運算元——以及最近用於生成式 AI——來支援 Meta 內部和外部 AI/ML 工作負載的高效執行。
FBGEMM 透過其後端高效能核心實現為 TorchRec 提供支援,適用於推薦工作負載,從嵌入袋核心到鋸齒狀張量操作。我們與 TorchRec 一同釋出了 FBGEMM 1.0,它保證了為其核心功能服務的多個穩定 API 的功能性和向後相容性,並提供了 增強的文件。
效能
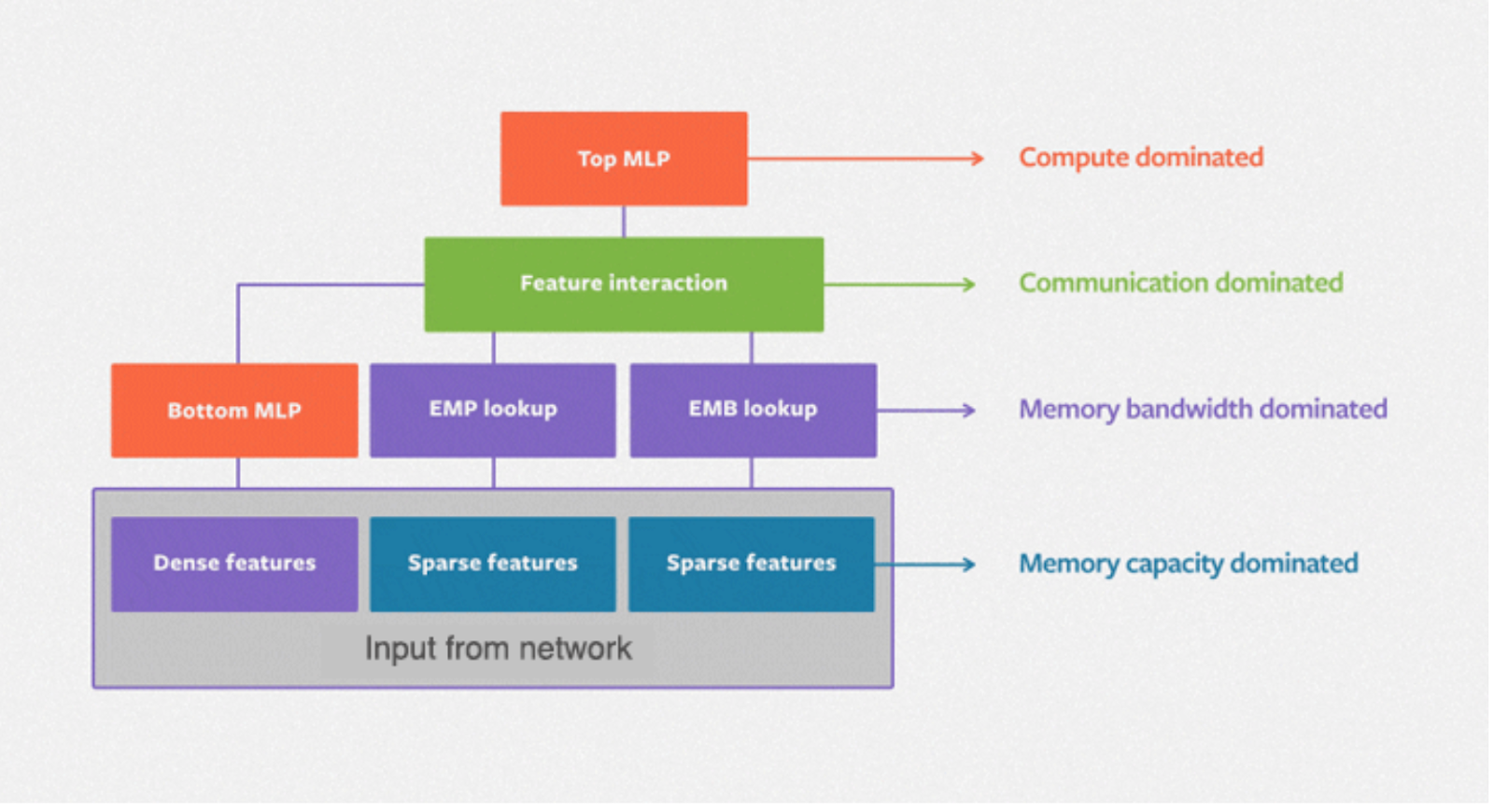
DLRM(深度學習推薦模型)是為 Meta 提供推薦功能的標準神經網路架構,其中分類特徵透過嵌入處理,而連續(密集)特徵則透過底部多層感知器處理。下圖描繪了 DLRM 的基本架構,其中在密集和稀疏特徵之間有一個二階互動層,以及一個用於生成預測的頂部 MLP。
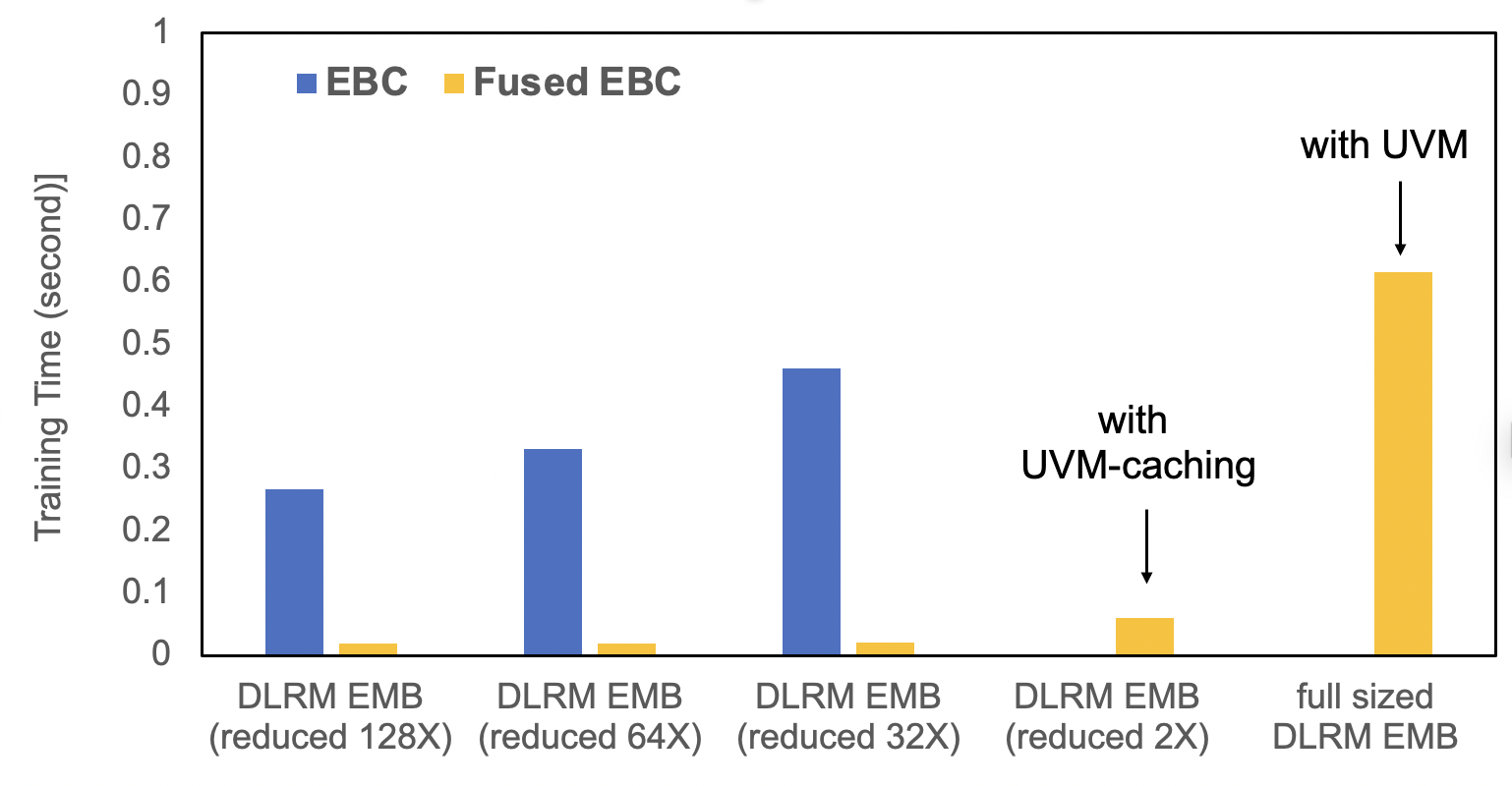
TorchRec 提供了標準化模組,並在融合嵌入查詢方面進行了顯著最佳化。EBC 是一種傳統的 PyTorch 嵌入模組實現,包含一組 torch.nn.EmbeddingBags。FusedEBC 由 FBGEMM 提供支援,用於在嵌入表上執行高效能操作,具有融合最佳化器和 UVM 快取/管理以緩解記憶體限制,是分片 TorchRec 模組中用於分散式訓練和推理的最佳化版本。下面的基準測試展示了 FusedEBC 相較於傳統 PyTorch 嵌入模組實現 (EBC) 的巨大效能提升,以及 FusedEBC 能夠透過 UVM 快取處理比 GPU 記憶體可用嵌入大得多的嵌入的能力。
TorchRec 資料型別
TorchRec 提供了標準的資料型別和模組,以便輕鬆處理分散式嵌入。這是一個透過 TorchRec 設定嵌入表集合的簡單示例
from torchrec import EmbeddingBagCollection
from torchrec import KeyedJaggedTensor
from torchrec import JaggedTensor
ebc = torchrec.EmbeddingBagCollection(
device="cpu",
tables=[
torchrec.EmbeddingBagConfig(
name="product_table",
embedding_dim=64,
num_embeddings=4096,
feature_names=["product"],
pooling=torchrec.PoolingType.SUM,
),
torchrec.EmbeddingBagConfig(
name="user_table",
embedding_dim=64,
num_embeddings=4096,
feature_names=["user"],
pooling=torchrec.PoolingType.SUM,
)
]
)
product_jt = JaggedTensor(
values=torch.tensor([1, 2, 1, 5]), lengths=torch.tensor([3, 1])
)
user_jt = JaggedTensor(values=torch.tensor([2, 3, 4, 1]), lengths=torch.tensor([2, 2]))
kjt = KeyedJaggedTensor.from_jt_dict({"product": product_jt, "user": user_jt})
print("Call EmbeddingBagCollection Forward: ", ebc(kjt))
分片
TorchRec 提供了一個規劃器類,可以自動生成跨多個 GPU 的最佳化分片計劃。這裡我們演示瞭如何在兩個 GPU 上生成分片計劃
from torchrec.distributed.planner import EmbeddingShardingPlanner, Topology
planner = EmbeddingShardingPlanner(
topology=Topology(
world_size=2,
compute_device="cuda",
)
)
plan = planner.collective_plan(ebc, [sharder], pg)
print(f"Sharding Plan generated: {plan}")
模型並行
TorchRec 的主要分散式訓練 API 是 DistributedModelParallel,它呼叫規劃器生成分片計劃(如上所示),並根據該計劃對 TorchRec 模組進行分片。我們演示瞭如何使用 DistributedModelParallel 對我們的 EmbeddingBagCollection 進行分片嵌入分散式訓練
model = torchrec.distributed.DistributedModelParallel(ebc, device=torch.device("cuda"))
推理
TorchRec 為模型的量化和嵌入分片提供了簡單的 API,用於分散式推理。用法如下所示
from torchrec.inference.modules import (
quantize_inference_model,
shard_quant_model,
)
quant_model = quantize_inference_model(ebc)
sharded_model, _ = shard_quant_model(
quant_model, compute_device=device, sharding_device=device
)
結論
TorchRec 和 FBGEMM 現已穩定,併為大規模推薦系統優化了功能。
有關 TorchRec 和 FBGEMM 的設定,請檢視入門指南。
我們還推薦閱讀這篇全面的端到端介紹 TorchRec 和 FBGEMM 功能的教程。