在這篇文章中,我們將討論 Torchserve 的效能調優,以便在生產環境中部署您的模型。在機器學習專案的生命週期中,最大的挑戰之一就是將模型部署到生產環境中。這需要一個可靠的服務解決方案,以及能夠滿足 MLOps 需求的解決方案。一個強大的服務解決方案需要支援多模型服務、模型版本控制、指標日誌記錄、監控和擴充套件以處理高峰流量。在這篇文章中,我們將概述 Torchserve,以及如何針對生產用例調整其效能。我們將討論 Meta 的 動畫繪圖應用程式,它可以將您的人物素描轉換為動畫,以及它如何透過 Torchserve 處理高峰流量。動畫繪圖的工作流程如下。
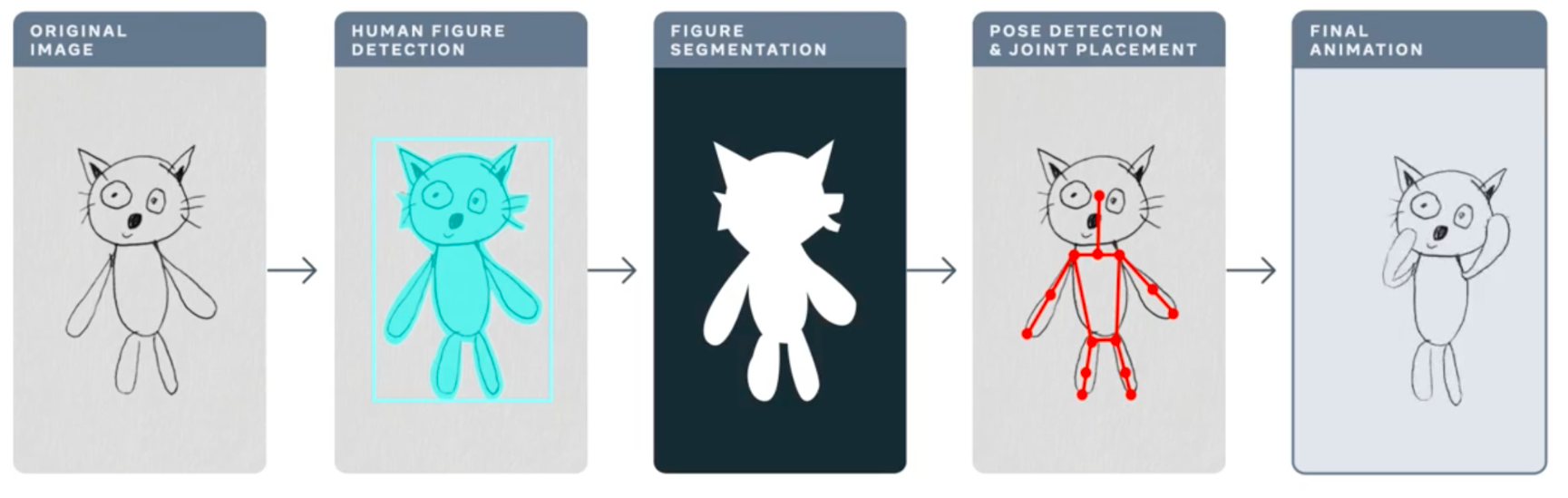
https://ai.facebook.com/blog/using-ai-to-bring-childrens-drawings-to-life
許多人工智慧系統和工具都旨在處理逼真的人類影像,兒童的繪畫增加了複雜性和不可預測性,因為它們通常以抽象、奇特的方式構建。這些型別的形態和風格變化甚至會混淆在識別逼真影像和繪畫中的物體方面表現出色最先進的人工智慧系統。Meta AI 的研究人員正在努力克服這一挑戰,以便人工智慧系統能夠更好地識別兒童以各種各樣的方式創作的人體繪畫。這篇精彩的部落格文章提供了有關動畫繪畫和所採用方法的更多詳細資訊。
Torchserve
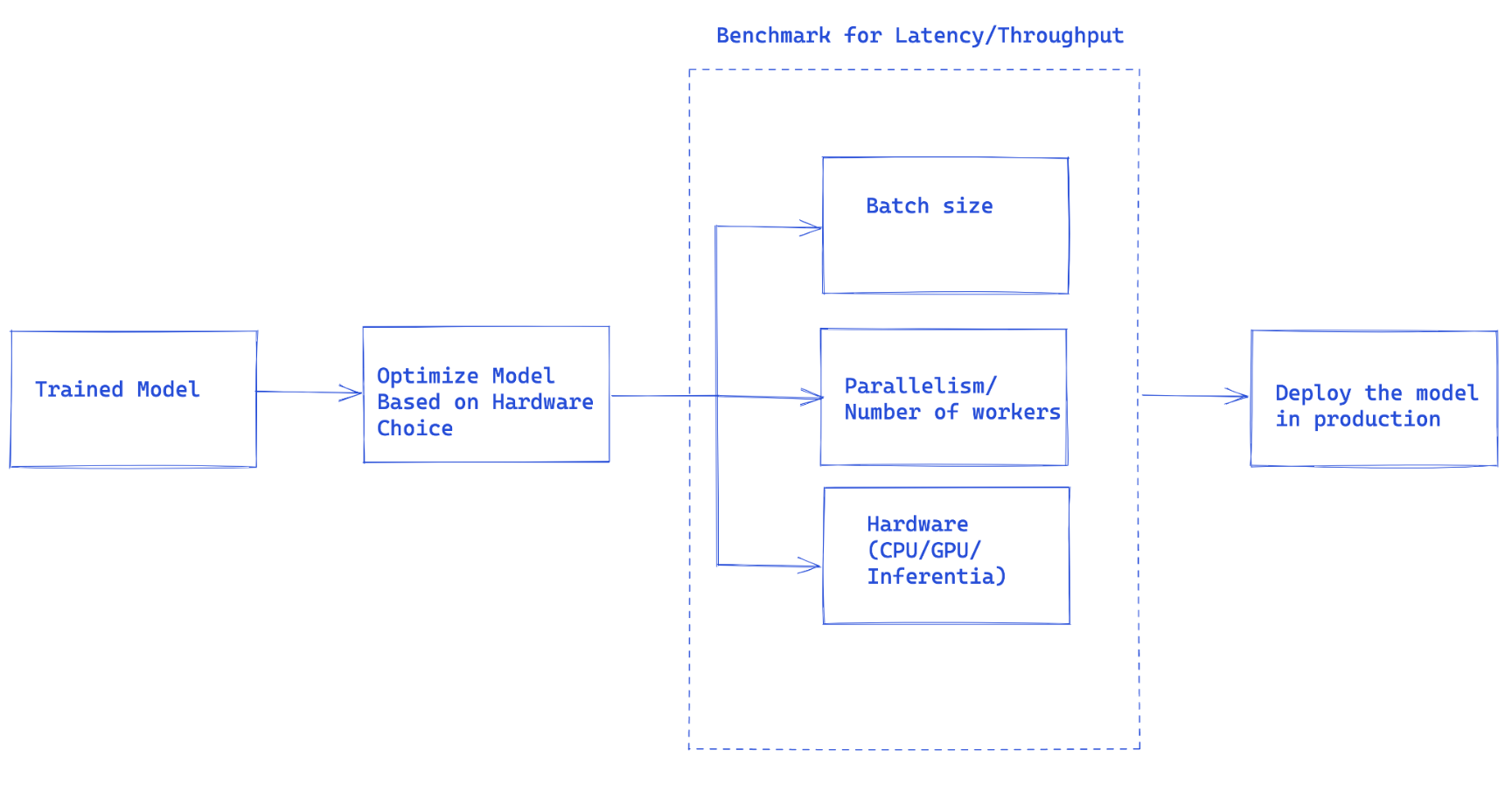
圖 1. Torchserve 效能調優的整體流程
一旦您訓練好模型,就需要將其整合到一個更大的系統中,以形成一個完整的應用程式。我們使用“模型服務”一詞來指代這種整合。基本上,模型服務就是使您訓練好的模型能夠執行推理並後續使用該模型。
Torchserve 是 Pytorch 首選的生產模型服務解決方案。它是一個高效能、可擴充套件的工具,可將您的模型封裝在 HTTP 或 HTTPS API 中。它有一個用 Java 實現的前端,負責處理從分配 worker 服務模型到處理客戶端和伺服器之間連線的多個任務。Torchserve 有一個 Python 後端,負責處理推理服務。
Torchserve 支援多模型服務和 A/B 測試的版本控制、動態批處理、日誌記錄和指標。它公開了四個 API:推理、解釋、管理和指標。
推理 API 預設監聽埠 8080,可透過 localhost 訪問,這可以在 Torchserve 配置中配置,並啟用從模型獲取預測。
解釋 API 在底層使用 Captum 提供正在服務的模型的解釋,並且也監聽埠 8080。
管理 API 允許註冊或登出並描述模型。它還允許使用者增加或減少服務模型的 worker 數量。
指標 API 預設監聽埠 8082,使我們能夠監控正在服務的模型。
Torchserve 透過支援批次推理和多個服務您模型的 worker 來讓您擴充套件模型服務並處理高峰流量。可以透過管理 API 和透過配置檔案的設定來完成擴充套件。此外,指標 API 透過預設和可自定義的指標幫助您監控模型服務。
其他高階設定,例如接收請求佇列的長度、批次輸入的ado等待時間以及許多其他屬性,都可以透過在啟動 Torchserve 時傳遞的配置檔案進行配置。
使用 Torchserve 部署模型的步驟
- 安裝 Torchserve、模型歸檔器及其依賴項。
- 選擇適合您任務的預設處理程式(例如影像分類等)或編寫自定義處理程式。
- 使用Torcharchive將您的模型工件(訓練好的模型檢查點和載入和執行模型所需的所有其他檔案)和處理程式打包成“.mar”檔案,並將其放置在模型儲存中。
- 開始服務您的模型.
- 執行推理。我們將在這裡更詳細地討論模型處理程式和指標。
模型處理程式
Torchserve 在後端使用處理程式來載入模型、預處理接收到的資料、執行推理和後處理響應。Torchserve 中的處理程式是一個**Python 指令碼**,所有模型初始化、預處理、推理和後處理邏輯都包含在其中。
Torchserve 為影像分類、分割、物件檢測和文字分類等多種應用程式提供了開箱即用的處理程式。如果您的用例不受預設處理程式支援,它還支援自定義處理程式。
它在自定義處理程式中提供了極大的靈活性,這可能使 Torchserve 成為**多框架**服務工具。自定義處理程式允許您定義自定義邏輯來初始化模型,該模型也可以用於從 ONNX 等其他框架載入模型。
Torchserve 的**處理程式**由四個主要**函式**組成:**初始化 (initialize)**、**預處理 (preprocess)**、**推理 (inference)** 和**後處理 (postprocess)**,每個函式都返回一個列表。下面的程式碼片段顯示了一個自定義處理程式的示例。**自定義處理程式繼承**自 Torchserve 中的 **BaseHandler**,並且可以**重寫**任何**主要函式**。下面是用於載入 Detectron2 模型進行人物檢測的處理程式示例,該模型已匯出到 Torchscript 並使用 model.half() 進行 FP16 推理,具體細節將在本文的另一部分中解釋。
class MyModelHandler(BaseHandler):
def initialize(self, context):
self.manifest = ctx.manifest
properties = ctx.system_properties
model_dir = properties.get("model_dir")
serialized_file = self.manifest["model"]["serializedFile"]
model_pt_path = os.path.join(model_dir, serialized_file)
self.device = torch.device(
"cuda:" + str(properties.get("gpu_id"))
if torch.cuda.is_available() and properties.get("gpu_id") is not None
else "cpu"
)
self.model = torch.jit.load(model_pt_path, map_location=self.device)
self.model = self.model.half()
def preprocess(self, data):
inputs = []
for request in batch:
request_body = request.get("body")
input_ = io.BytesIO(request_body)
image = cv2.imdecode(np.fromstring(input_.read(), np.uint8), 1)
input = torch.Tensor(image).permute(2, 0, 1)
input = input.to(self.device)
input = input.half()
inputs.append({"image": input})
return inputs
def inference(self,inputs):
predictions = self.model(**inputs)
return predictions
def postprocess(self, output):
responses = []
for inference_output in inference_outputs:
responses_json = {
'classes': inference_output['pred_classes'].tolist(),
'scores': inference_output['scores'].tolist(),
"boxes": inference_output['pred_boxes'].tolist()
}
responses.append(json.dumps(responses_json))
return responses
指標
在生產環境中部署模型的一個基本元件是監控模型的能力。**Torchserve 定期**收集**系統級**指標,並且還**允許**新增**自定義指標**。
系統級指標包括主機上的 CPU 利用率、可用和已用磁碟空間以及記憶體,以及具有不同響應程式碼(例如 200-300、400-500 和 500 以上)的請求數量。可以在此處新增自定義指標。TorchServe 將這兩組指標記錄到不同的日誌檔案中。指標預設收集在:
- 系統指標 – log_directory/ts_metrics.log
- 自定義指標 – log directory/model_metrics.log
如前所述,Torchserve 還公開了指標 API,該 API 預設監聽埠 8082,使使用者能夠查詢和監控收集到的指標。預設的指標端點返回 Prometheus 格式的指標。您可以使用 curl 請求查詢指標,或者將Prometheus 伺服器指向該端點,並使用Grafana來建立儀表板。
在部署模型時,您可以使用 curl 請求查詢指標,如下所示:
curl http://127.0.0.1:8082/metrics
如果您想匯出已記錄的指標,請參閱此示例,該示例使用 mtail 將指標匯出到 Prometheus。在儀表板中跟蹤這些指標可以幫助您監控可能在離線基準測試執行中偶然發生或難以發現的效能退化。
在生產環境中最佳化模型效能的考量因素
圖 1 中建議的工作流程是使用 Torchserve 處理模型生產部署的總體思路。
在許多情況下,生產模型服務是根據吞吐量或延遲服務水平協議 (SLA) 進行**最佳化**的。通常,**即時應用**更關注**延遲**,而**離線應用**可能更關注更高的**吞吐量**。
有許多主要因素會影響生產環境中服務模型的效能。特別是,我們這裡關注的是使用 Torchserve 服務 Pytorch 模型,但其中大部分因素也適用於其他框架的所有模型。
- **模型最佳化**:這是將模型部署到生產環境的預備步驟。這是一個非常廣泛的討論,我們將在未來的一系列部落格中深入探討。這包括量化、剪枝以減小模型大小、使用中間表示(IR 圖)例如 Pytorch 中的 Torchscript、融合核心等技術。目前,torchprep 提供了許多這些技術作為 CLI 工具。
- **批次推理:**它指的是將多個輸入送入模型,這在訓練過程中至關重要,在推理時管理成本也非常有幫助。硬體加速器針對並行性進行了最佳化,批次處理有助於使計算能力飽和,並通常導致更高的吞吐量。推理中的主要區別在於您不能等待太長時間才能從客戶端填充批次,這稱為動態批次處理。
- **Worker 數量:** Torchserve 使用 worker 來服務模型。Torchserve worker 是 Python 程序,它們儲存模型權重的副本以執行推理。worker 過少意味著您沒有充分利用並行性,但 worker 過多會導致 worker 爭用並降低端到端效能。
- **硬體:**根據模型、應用以及延遲、吞吐量預算選擇合適的硬體。這可能是 Torchserve 支援的硬體之一,**CPU、GPU、AWS Inferentia**。有些硬體配置旨在實現最佳效能,而另一些則更適合經濟高效的推理。根據我們的實驗,我們發現 GPU 在較大的批次大小下表現最佳,而合適的 CPU 和 AWS Inferentia 對於較小的批次大小和低延遲則更具成本效益。
Torchserve 效能調優的最佳實踐
為了在使用 Torchserve 部署模型時獲得最佳效能,我們在這裡分享一些最佳實踐。Torchserve 提供了一個基準測試套件,可以提供有用的見解,以便對如下所述的不同選擇做出明智的決定。
- **最佳化您的模型**是第一步,Pytorch 模型最佳化教程。**模型最佳化**選擇也與**硬體**選擇密切**相關**。我們將在另一篇部落格文章中更詳細地討論它。
- **決定**模型部署的**硬體**可能與延遲、吞吐量預算以及每次推理的成本密切相關。根據模型和應用程式的大小,它可能會有所不同。對於某些模型,如計算機視覺模型,在 CPU 上生產執行歷史上一直是不划算的。然而,透過在 Torchserve 中新增諸如 IPEX 等最佳化,這變得更加經濟和具有成本效益,您可以在此項調查性的案例研究中瞭解更多資訊。
- Torchserve 中的**worker**是提供並行性的 Python 程序,應仔細設定 worker 數量。預設情況下,Torchserve 啟動的 worker 數量等於主機上的 VCPU 或可用 GPU 數量,這可能會大大增加 Torchserve 的啟動時間。Torchserve 公開了一個配置屬性來設定 worker 數量。為了透過**多個 worker**提供**高效的並行性**並避免它們爭用資源,我們**建議**在 CPU 和 GPU 上遵循以下設定作為基準:**CPU**:在處理程式中,設定 `torch.set_num_threads(1)`,然後將 worker 數量設定為 `num physical cores / 2`。但最佳的執行緒配置可以透過利用 Intel CPU 啟動指令碼來實現。**GPU**:可用 GPU 的數量可以透過 config.properties 中的number_gpus來設定。Torchserve 使用輪詢方式將 worker 分配給 GPU。我們建議按如下方式設定 worker 數量:`worker 數量 = (可用 GPU 數量) / (獨特模型數量)`。請注意,Ampere 之前的 GPU 不提供任何多例項 GPU 的資源隔離。
- **批處理大小**可以直接影響延遲和吞吐量。為了更好地利用計算資源,需要增加批處理大小。然而,延遲和吞吐量之間存在權衡。**較大的批處理大小**可以**提高吞吐量,但也會導致更高的延遲**。批處理大小可以透過兩種方式在 Torchserve 中設定,要麼透過 config.properties 中的模型配置,要麼在註冊模型時使用管理 API。
在下一節中,我們將使用 Torchserve 基準測試套件來決定模型最佳化、硬體、worker 和批處理大小的最佳組合。
動畫繪圖效能調優
要使用 Torchserve 基準測試套件,首先我們需要一個歸檔檔案,即如上所述的“.mar”檔案,其中包含模型、處理程式以及所有其他用於載入和執行推理的工件。動畫繪圖使用 Detectron2 的 Mask-RCNN 實現作為物件檢測模型。
如何執行基準測試套件
Torchserve 中的自動化基準測試套件允許您使用不同的設定(包括批處理大小和 worker 數量)對多個模型進行基準測試,並最終為您生成報告。要開始:
git clone https://github.com/pytorch/serve.git
cd serve/benchmarks
pip install -r requirements-ab.txt
apt-get install apache2-utils
模型級設定可以在類似如下的 yaml 檔案中配置
Model_name:
eager_mode:
benchmark_engine: "ab"
url: "Path to .mar file"
workers:
- 1
- 4
batch_delay: 100
batch_size:
- 1
- 2
- 4
- 8
requests: 10000
concurrency: 10
input: "Path to model input"
backend_profiling: False
exec_env: "local"
processors:
- "cpu"
- "gpus": "all"
此 yaml 檔案將在 `benchmark_config_template.yaml` 檔案中引用,該檔案包含用於生成報告的其他設定,它還可以選擇與 AWS CloudWatch 配合使用以獲取日誌。
python benchmarks/auto_benchmark.py --input benchmark_config_template.yaml
**執行基準測試**後,結果將寫入“csv”檔案,可在“_ /tmp/benchmark/ab_report.csv_”中找到,完整報告在“/tmp/ts_benchmark/report.md”中。它將包括 Torchserve 平均延遲、模型 P99 延遲、吞吐量、併發數、請求數、處理程式時間以及其他一些指標。這裡我們重點關注我們跟蹤的一些重要指標,這些指標用於調整效能,它們是**併發性**、**模型 P99 延遲**、**吞吐量**。我們特別關注這些數字與**批處理大小**、使用的**裝置**、**worker 數量**以及是否進行了任何**模型最佳化**的**組合**。
該模型的**延遲 SLA** 已設定為**100 毫秒**,這是一個即時應用程式,正如我們之前討論的,延遲更受關注,而**吞吐量**理想情況下應該儘可能高,同時**不違反延遲 SLA。**
透過搜尋空間,在不同的批處理大小(1-32)、worker 數量(1-16)和裝置(CPU、GPU)上,我們運行了一系列實驗,下表總結了其中最好的結果。
| 裝置 | 併發性 | 請求數 | Worker 數量 | 批次大小 | Payload/影像 | 最佳化 | 吞吐量 | P99 延遲 |
| CPU | 10 | 1000 | 1 | 1 | 小 | 不適用 | 3.45 | 305.3 毫秒 |
| CPU | 1 | 1000 | 1 | 1 | 小 | 不適用 | 3.45 | 291.8 毫秒 |
| GPU | 10 | 1000 | 1 | 1 | 小 | 不適用 | 41.05 | 25.48 毫秒 |
| GPU | 1 | 1000 | 1 | 1 | 小 | 不適用 | 42.21 | 23.6 毫秒 |
| GPU | 10 | 1000 | 1 | 4 | 小 | 不適用 | 54.78 | 73.62 毫秒 |
| GPU | 10 | 1000 | 1 | 4 | 小 | model.half() | 78.62 | 50.69 毫秒 |
| GPU | 10 | 1000 | 1 | 8 | 小 | model.half() | 85.29 | 94.4 毫秒 |
該模型在 CPU 上,在所有嘗試過的批處理大小、併發性和 worker 數量設定下,延遲均未達到 SLA,實際上高出了約 13 倍。
**將模型服務****轉移到 GPU**,可以立即將**延遲**從 305 毫秒**提高**約 **13 倍**,降至 23.6 毫秒。
我們可以對模型進行的最**簡單**的**最佳化**之一是將其精度降低到 **fp16**,這隻需一行程式碼(**model.half()**),可以將**模型 P99 延遲**減少 **32%**,並以幾乎相同的幅度提高吞吐量。
還可以透過對模型進行 Torchscript 最佳化並使用optimize_for_inference或其他技巧(包括 onnx 或 tensorrt 執行時最佳化,它們利用激進融合)進行其他最佳化,這些超出了本文的範圍。我們將在單獨的帖子中討論模型最佳化。
我們發現在 CPU 和 GPU 上,將**worker 數量設定為 1** 在本例中效果最佳。
- 將模型遷移到 GPU,使用**worker 數量 = 1**,**批處理大小 = 1**,與 **CPU 相比,吞吐量增加了約 12 倍**,**延遲減少了約 13 倍**。
- 將模型遷移到 GPU,使用 **model.half()**,**worker 數量 = 1**,**批處理大小 = 8**,在**吞吐量**方面取得了**最佳**結果,並且延遲仍在可容忍範圍內。(**與 CPU 相比,吞吐量增加了約 25 倍**,**延遲仍滿足 SLA(94.4 毫秒)**)。
注意:如果您正在執行基準測試套件,請確保設定了適當的 `batch_delay`,並將請求的併發數設定為與您的批處理大小成比例的數字。這裡的併發性指的是傳送到伺服器的併發請求數量。
結論
在這篇文章中,我們討論了 Torchserve 在生產環境中調整效能時需要考慮的因素和可用的配置。我們探討了 Torchserve 基準測試套件作為一種工具,可以幫助我們調整效能並深入瞭解模型最佳化、硬體選擇和總體成本的可能選項。我們以 Animated Drawings 應用程式(使用 Detectron2 的 Mask-RCNN 模型)作為案例研究,展示了使用基準測試套件進行效能調優的過程。
有關 Torchserve 效能調優的更多詳細資訊,請參閱我們的文件此處。此外,如有任何疑問和反饋,請隨時在Torchserve 儲存庫上提交工單。
致謝
我們要感謝 Somya Jain (Meta)、Christopher Gustave (Meta) 在本部落格的許多步驟中提供的巨大支援和指導,併為 Sketch Animator 工作流程提供了見解。此外,特別感謝來自 AWS 的李寧,為 Torchserve 的自動化基準測試套件,使效能調優變得更加容易所做的巨大努力。