在 TorchVision v0.10 中,我們釋出了兩個基於 SSD 架構的新的目標檢測模型。我們的計劃是分兩篇文章介紹演算法的關鍵實現細節以及它們的訓練方式。
在本系列文章的第1部分中,我們將重點介紹 Single Shot MultiBox Detector 論文中描述的 SSD 演算法的原始實現。我們將簡要地從高層次描述演算法的工作原理,然後介紹其主要組成部分,突出其程式碼的關鍵部分,最後討論我們如何訓練釋出的模型。我們的目標是涵蓋重現模型所需的所有細節,包括論文中未涵蓋但屬於 原始實現 的那些最佳化。
SSD 如何工作?
強烈建議閱讀上述論文,但這裡是一個快速簡化的回顧。我們的目標是檢測影像中物體的位置及其類別。這是 SSD 論文 中的圖5,其中包含模型的預測示例。

SSD 演算法使用一個 CNN 主幹網路,將輸入影像透過它,並從網路的不同層獲取卷積輸出。這些輸出列表稱為特徵圖。然後這些特徵圖透過分類和迴歸頭,這些頭負責預測框的類別和位置。
由於每個影像的特徵圖包含來自網路不同級別的輸出,它們的尺寸不同,因此它們可以捕獲不同尺寸的物體。在每個特徵圖上,我們平鋪了幾個預設框,這些框可以被認為是我們的粗略先驗猜測。對於每個預設框,我們預測是否存在一個物體(及其類別)及其偏移量(對原始位置的修正)。在訓練時,我們需要首先將真實標註與預設框匹配,然後我們使用這些匹配來估計我們的損失。在推理時,類似的預測框被組合以估計最終預測。
SSD 網路架構
在本節中,我們將討論 SSD 的關鍵組成部分。我們的程式碼密切遵循 論文,並使用了 官方實現 中包含的許多未記錄的最佳化。
DefaultBoxGenerator
DefaultBoxGenerator 類 負責生成 SSD 的預設框,其操作方式類似於 FasterRCNN 的 AnchorGenerator(有關它們的區別,請參見論文第4-6頁)。它生成一組具有特定寬度和高度的預定義框,這些框平鋪在影像上,作為物體可能位於何處的第一個粗略先驗猜測。這是 SSD 論文中的圖1,其中包含真實標註和預設框的視覺化。
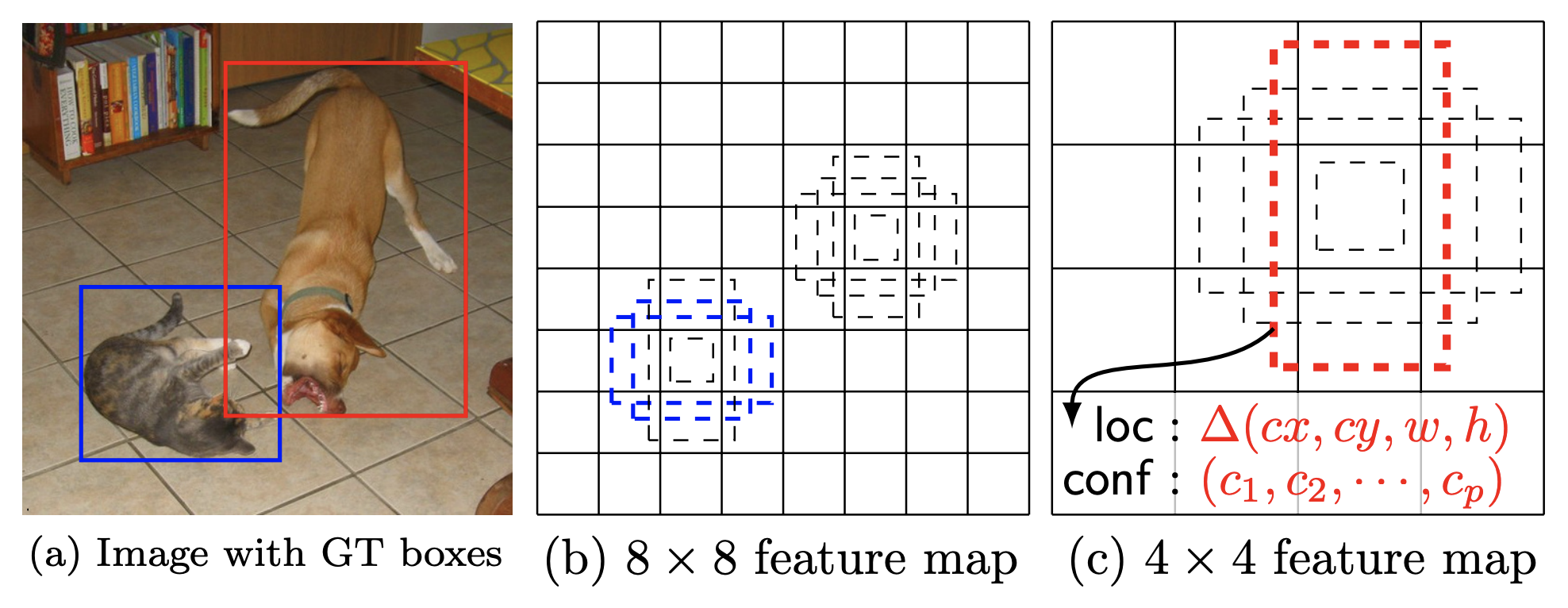
該類由一組超引數引數化,這些超引數控制其 形狀 和 平鋪方式。該實現將為那些希望嘗試新主幹網路/資料集的人 自動提供良好的猜測,但也可以傳遞 最佳化的自定義值。
SSDMatcher
SSDMatcher 類 擴充套件了 FasterRCNN 使用的標準 Matcher,它負責將預設框與真實標註匹配。在估計所有組合的 IoU 後,我們使用匹配器為每個預設框找到最佳的 候選 真實標註,其重疊度高於 IoU 閾值。匹配器的 SSD 版本有一個額外的步驟,以確保每個真實標註都與具有 最高重疊度 的預設框匹配。匹配器的結果用於模型訓練過程中的損失估計。
分類和迴歸頭
SSDHead 類 負責初始化網路的分類和迴歸部分。以下是其程式碼的一些值得注意的細節:
- 分類 頭和 迴歸 頭都繼承自 同一個類,該類負責為每個特徵圖進行預測。
- 特徵圖的每個級別都使用單獨的 3x3 卷積來估計 類別 logits 和 框位置。
- 每個頭在每個級別上進行的 預測數量 取決於預設框的數量和特徵圖的大小。
主幹特徵提取器
特徵提取器 重新配置並使用額外的層增強了標準 VGG 主幹網路,如 SSD 論文圖2所示。
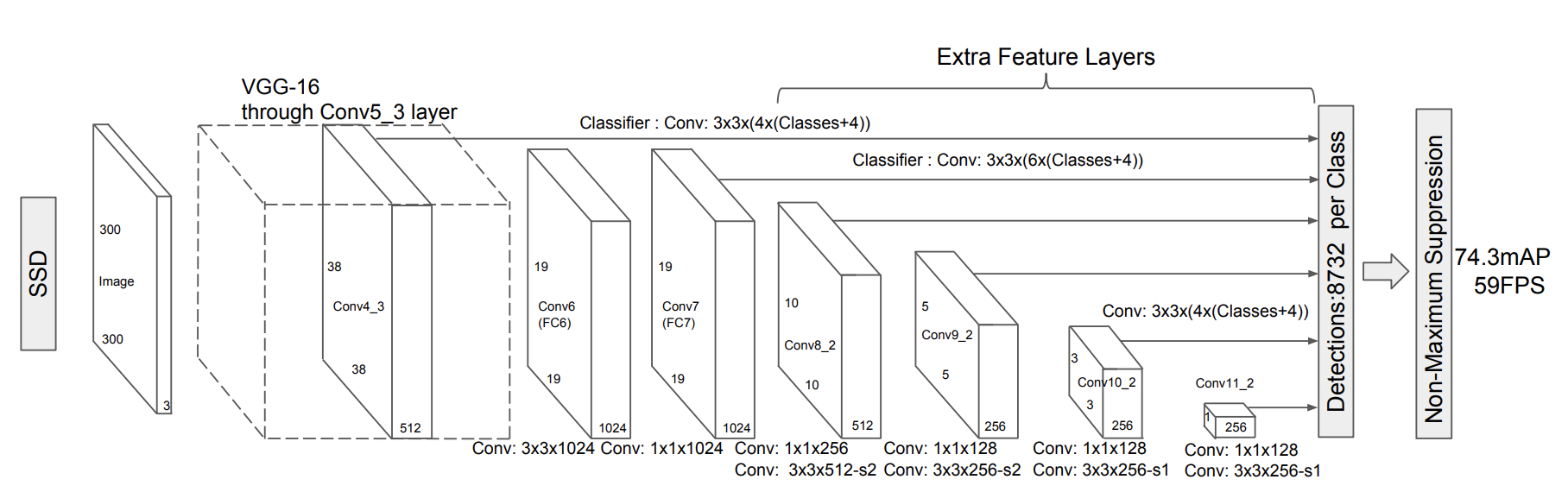
該類支援 TorchVision 的所有 VGG 模型,並且可以為其他型別的 CNN 建立類似的提取器類(參見 ResNet 的這個例子)。以下是該類的一些實現細節:
- 修補 第3個 Maxpool 層的
ceil_mode 引數對於獲得與論文相同的特徵圖大小是必要的。這是由於 PyTorch 和模型的原始 Caffe 實現之間存在細微差異。 - 它在 VGG 上添加了一系列 額外的特徵層。如果在其構建過程中
highres 引數為True,它將附加一個 額外的卷積。這對於模型的 SSD512 版本很有用。 - 如論文第3節所述,原始 VGG 的全連線層透過 第一個使用 Atrous 的 卷積轉換為卷積層。此外,maxpool5 的步長和核大小也 被修改。
- 如第3.1節所述,對 conv4_3 的輸出 使用了 L2 歸一化,並引入了一組 可學習權重 來控制其縮放。
SSD 演算法
實現中最後一個關鍵部分是 SSD 類。以下是一些值得注意的細節:
- 該演算法透過一系列與其它檢測模型相似的引數 引數化。強制引數包括:負責 估計特徵圖 的主幹網路,應該是
DefaultBoxGenerator類的 已配置例項 的anchor_generator,輸入影像 將被調整到的尺寸,以及分類的num_classes,不包括 背景。 - 如果未提供 head,建構函式將 初始化 預設的
SSDHead。為此,我們需要知道主幹網路生成的每個特徵圖的輸出通道數。最初,我們嘗試從主幹網路 檢索此資訊,如果不可用,我們將 動態估計它。 - 該演算法 重用了 其他檢測模型使用的標準 BoxCoder 類。該類負責 編碼和解碼 邊界框,並配置為使用與 原始實現 相同的先驗方差。
- 儘管我們重用了標準的 GeneralizedRCNNTransform 類 來調整和歸一化輸入影像,但 SSD 演算法 對其進行了配置,以確保影像尺寸保持固定。
以下是實現的兩個核心方法:
compute_loss方法估計 SSD 論文第5頁描述的標準 Multi-box 損失。它使用 平滑 L1 損失 進行迴歸,並使用標準的 交叉熵損失 以及 難例挖掘(hard-negative sampling) 進行分類。- 與所有檢測模型一樣,
forward方法當前的行為取決於模型處於訓練模式還是評估模式。它首先 調整和歸一化輸入影像,然後 透過主幹網路 獲取特徵圖。然後特徵圖 透過頭 獲取預測,然後該方法 生成預設框。
SSD300 VGG16 模型
SSD 是一個模型家族,因為它可以配置不同的主幹網路和不同的頭部配置。在本節中,我們將重點介紹提供的 SSD 預訓練模型。我們將討論其配置細節和用於重現報告結果的訓練過程。
訓練過程
該模型使用 COCO 資料集進行訓練,其所有超引數和指令碼都可以在我們的 references 資料夾中找到。下面我們提供訓練過程中最值得注意的方面的詳細資訊。
論文超引數
為了在 COCO 上取得最佳結果,我們採用了論文第3節中描述的關於最佳化器配置、權重正則化等超引數。此外,我們發現採用 官方實現 中關於 DefaultBox 生成器 平鋪配置 的最佳化很有用。這項最佳化在論文中沒有描述,但對於提高小物體檢測精度至關重要。
資料增強
實現論文第6頁和第12頁描述的 SSD 資料增強策略 對於重現結果至關重要。更具體地說,使用隨機的“放大”和“縮小”變換使模型對各種輸入尺寸具有魯棒性,並提高了其在小中型物體上的精度。最後,由於 VGG16 有相當多的引數,包含在增強中 的光度失真具有正則化作用,並有助於避免過擬合。
權重初始化和輸入縮放
我們發現另一個有益的方面是遵循論文提出的 權重初始化方案。為此,我們必須透過 撤銷 ToTensor() 執行的 0-1 縮放,並使用與此縮放匹配的 預訓練 ImageNet 權重 來調整我們的輸入縮放方法(特別感謝 Max deGroot 在他的倉庫中提供它們)。所有新卷積的權重都 使用 Xavier 初始化,其偏置設定為零。初始化後,網路 進行了端到端訓練。
學習率方案
如論文所述,在應用激進的資料增強後,模型需要訓練更長時間。我們的實驗證實了這一點,我們必須調整學習率、批次大小和總步數才能獲得最佳結果。我們 提出的學習方案 配置得相當保守,在步數之間顯示出平臺期跡象,因此您很可能只需訓練我們 epoch 數的 66% 就能訓練出類似的模型。
關鍵精度改進分解
需要注意的是,直接根據論文實現模型是一個迭代過程,它在編碼、訓練、bug 修復和調整配置之間迴圈,直到我們匹配論文中報告的精度。這通常還涉及簡化訓練方法或用更近期的技術進行增強。這絕不是一個線性過程,即透過一次改進一個方向來逐步提高精度,而是涉及探索不同的假設,在不同方面進行增量改進,並進行大量回溯。
考慮到這一點,下面我們嘗試總結對我們精度影響最大的最佳化。我們透過將各種實驗分組為4個主要組,並將實驗改進歸因於最接近的匹配。請注意,圖表的 Y 軸從18而不是0開始,以使最佳化之間的差異更明顯。
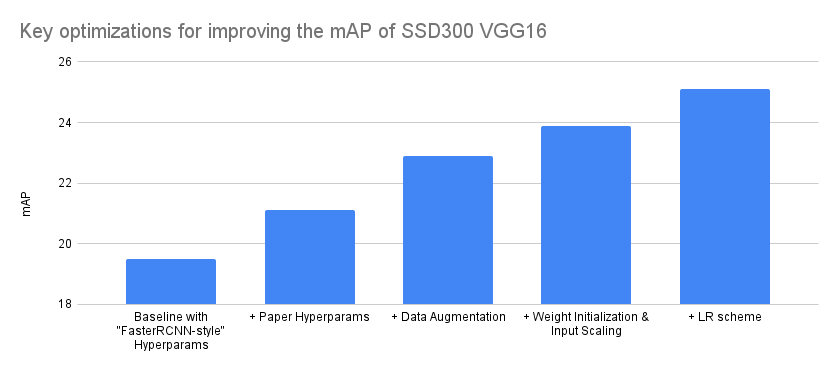
| 模型配置 | mAP 增量 | mAP |
|---|---|---|
| 帶有“FasterRCNN 風格”超引數的基線 | – | 19.5 |
| + 論文超引數 | 1.6 | 21.1 |
| + 資料增強 | 1.8 | 22.9 |
| + 權重初始化和輸入縮放 | 1 | 23.9 |
| + 學習率方案 | 1.2 | 25.1 |
我們的最終模型實現了 25.1 的 mAP,並完全重現了論文中報告的 COCO 結果。這是精度指標的 詳細分解。
希望您對本系列文章的第1部分感興趣。在第2部分中,我們將重點介紹 SSDlite 的實現,並討論它與 SSD 的區別。在此之前,我們期待您的反饋。