在上一篇文章中,我們討論了 SSD 演算法的工作原理,涵蓋了其實現細節並介紹了其訓練過程。如果您尚未閱讀上一篇部落格文章,建議您在繼續之前先查閱。
在本系列的第二部分中,我們將重點介紹 SSD 的移動友好型變體——SSDlite。我們的計劃是:首先,介紹演算法的主要組成部分,強調與原始 SSD 不同的部分;其次,討論已釋出的模型的訓練方式;最後,提供所有我們探索過的新物件檢測模型的詳細基準測試。
SSDlite 網路架構
SSDlite 是 SSD 的一種適應版本,最初在MobileNetV2 論文中簡要介紹,後來又在MobileNetV3 論文中重新使用。由於這兩篇論文的主要重點是引入新穎的 CNN 架構,因此 SSDlite 的大部分實現細節並未闡明。我們的程式碼遵循兩篇論文中提出的所有細節,並在必要時從官方實現中填補了空白。
如前所述,SSD 是一個模型系列,因為可以透過不同的骨幹網路(如 VGG、MobileNetV3 等)和不同的頭部(如使用常規卷積、可分離卷積等)進行配置。因此,SSDlite 中許多 SSD 元件保持不變。下面我們只討論那些不同的部分。
分類和迴歸頭部
根據 MobileNetV2 論文的第 6.2 節,SSDlite 將原始頭部中使用的常規卷積替換為可分離卷積。因此,我們的實現引入了新的頭部,它們使用3x3 深度可分離卷積和 1x1 投影。由於 SSD 方法的所有其他元件保持不變,因此為了建立 SSDlite 模型,我們的實現初始化 SSDlite 頭部並將其直接傳遞給 SSD 建構函式。
骨幹特徵提取器
我們的實現引入了一個新類來構建 MobileNet特徵提取器。根據 MobileNetV3 論文的第 6.3 節,骨幹網路返回具有 16 步幅的倒置殘差塊的擴充套件層輸出,以及具有 32 步幅的池化層之前的輸出。此外,骨幹網路的所有額外塊都替換為輕量級等效塊,這些塊使用 1x1 壓縮、步幅為 2 的可分離 3x3 卷積和 1x1 擴充套件。最後,為了確保即使在使用小的寬度乘數時,頭部也具有足夠的預測能力,所有卷積的最小深度尺寸都由min_depth超引數控制。
SSDlite320 MobileNetV3-Large 模型

本節討論所提供的SSDlite 預訓練模型的配置,以及為儘可能接近地復現論文結果而遵循的訓練過程。
訓練過程
在我們的references資料夾中可以找到用於在 COCO 資料集上訓練模型的所有超引數和指令碼。這裡我們討論訓練過程中最值得注意的細節。
調整的超引數
儘管論文中沒有提供用於訓練模型的超引數資訊(例如正則化、學習率和批次大小),但官方倉庫中配置檔案中列出的引數是很好的起點,我們透過交叉驗證將它們調整到最優值。所有這些都使我們的效能比基線 SSD 配置有了顯著提升。
資料增強
SSDlite 與 SSD 的一個關鍵重要區別在於,前者的骨幹網路權重只是後者的一小部分。這就是為什麼在 SSDlite 中,資料增強更側重於使模型對可變大小的物件具有魯棒性,而不是試圖避免過擬合。因此,SSDlite僅使用 SSD 變換的一個子集,從而避免了模型的過度正則化。
學習率方案
由於依賴資料增強使模型對中小尺寸物體具有魯棒性,我們發現使用大量的 epoch 對於訓練方案特別有利。更具體地說,透過使用比 SSD 多大約 3 倍的 epoch,我們能夠將精度提高 4.2mAP 點;透過使用 6 倍乘數,我們提高了 4.9mAP。進一步增加 epoch 似乎會帶來遞減的回報,並使訓練過於緩慢和不切實際。然而,根據模型配置,論文作者似乎使用了等效的16 倍乘數。
權重初始化與輸入縮放與 ReLU6
最終的一系列最佳化使我們的實現非常接近官方版本,並幫助我們彌合了精度差距,這些最佳化包括:從頭開始訓練骨幹網路而不是從 ImageNet 初始化,調整我們的權重初始化方案,改變我們的輸入縮放,並將 SSDlite 頭部中新增的所有標準 ReLU 替換為 ReLU6。請注意,由於我們從隨機權重訓練模型,我們還應用了論文中描述的透過使用骨幹網路上的縮減尾部來加速的最佳化。
實現差異
將上述實現與官方倉庫中的實現進行比較,我們發現了一些差異。其中大部分是細微的,與我們初始化權重的方式(例如,Normal 初始化與截斷 Normal)、我們引數化學習率排程的方式(例如,較小的與較大的預熱速率、較短的與較長的訓練)等有關。已知最大的差異在於我們計算分類損失的方式。更具體地說,官方倉庫中 SSDlite 結合 MobileNetV3 骨幹網路的實現沒有使用 SSD 的 Multibox 損失,而是使用了 RetinaNet 的焦點損失。這與論文的偏差相當大,由於 TorchVision 已經提供了 RetinaNet 的完整實現,我們決定使用正常的 Multi-box SSD 損失來實現 SSDlite。
關鍵精度提升細分
如前文所述,重現研究論文並將其轉化為程式碼並非一個單調遞增精度的過程,尤其是在不完全瞭解訓練和實現細節的情況下。通常,這個過程涉及大量的回溯,因為需要識別對精度有顯著影響的實現細節和引數,並將其與那些沒有顯著影響的區分開來。下面我們嘗試視覺化那些將我們的精度從基線提升的最重要的迭代。
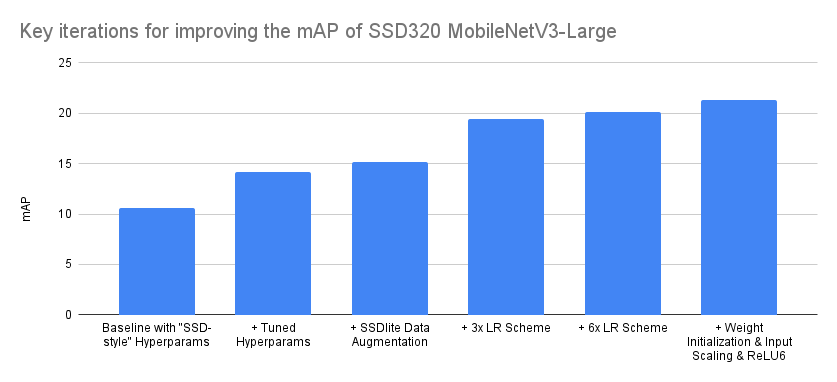
| 迭代 | mAP |
|---|---|
| 基線,使用“SSD風格”超引數 | 10.6 |
| + 調整的超引數 | 14.2 |
| + SSDlite 資料增強 | 15.2 |
| + 3x 學習率方案 | 19.4 |
| + 6x 學習率方案 | 20.1 |
| + 權重初始化 & 輸入縮放 & ReLU6 | 21.3 |
上面呈現的最佳化順序是準確的,儘管在某些情況下有些理想化。例如,儘管在超引數調整階段測試了不同的排程器,但它們都沒有提供顯著的改進,因此我們保留了基線中使用的 MultiStepLR。然而,在後來嘗試不同的學習率方案時,我們發現切換到 CosineAnnealingLR 有益,因為它需要較少的配置。因此,我們認為上述總結的主要啟示是,即使從同一家族模型的正確實現和一組最優超引數開始,也總能透過最佳化訓練方案和調整實現來發現精度提升點。誠然,上述是一個精度翻倍的極端情況,但在許多情況下,仍有大量的最佳化可以幫助我們顯著提高精度。
基準測試
下面是如何初始化這兩個預訓練模型的方法
ssdlite = torchvision.models.detection.ssdlite320_mobilenet_v3_large(pretrained=True)
ssd = torchvision.models.detection.ssd300_vgg16(pretrained=True)
以下是新檢測模型和選定舊檢測模型之間的基準測試
| 模型 | mAP | CPU 推理時間 (秒) | 引數數量 (M) |
|---|---|---|---|
| SSDLite320 MobileNetV3-Large | 21.3 | 0.0911 | 3.44 |
| SSD300 VGG16 | 25.1 | 0.8303 | 35.64 |
| SSD512 VGG16 (未釋出) | 28.8 | 2.2494 | 37.08 |
| SSD512 ResNet50 (未釋出) | 30.2 | 1.1137 | 42.70 |
| Faster R-CNN MobileNetV3-Large 320 FPN (低解析度) | 22.8 | 0.1679 | 19.39 |
| Faster R-CNN MobileNetV3-Large FPN (高解析度) | 32.8 | 0.8409 | 19.39 |
正如我們所見,SSDlite320 MobileNetV3-Large 模型是迄今為止最快、最小的模型,因此它是實際移動應用的絕佳選擇。儘管其精度低於預訓練的低解析度 Faster R-CNN 等效模型,但 SSDlite 框架具有適應性,可以透過引入更多卷積的更重頭部來提高其精度。
另一方面,SSD300 VGG16 模型相當慢且精度較低。這主要是由於其 VGG16 骨幹網路。儘管 VGG 架構極其重要且具有影響力,但如今已相當過時。因此,儘管該特定模型具有歷史和研究價值,並因此被納入 TorchVision,但我們建議需要高解析度檢測器的實際應用使用者,要麼將 SSD 與其他骨幹網路結合使用(參見此示例,瞭解如何建立一個),要麼使用 Faster R-CNN 預訓練模型之一。
希望您喜歡 SSD 系列的第二部分也是最後一部分。我們期待您的反饋。