引言
ZenFlow是2025年夏季引入的DeepSpeed新擴充套件,旨在作為大型語言模型(LLM)訓練的無停滯解除安裝引擎。解除安裝是一種廣泛使用的技術,用於緩解LLM模型規模不斷增長所導致的GPU記憶體壓力。然而,近年來CPU-GPU效能差距已擴大數個數量級。傳統的解除安裝框架(如DeepSpeed ZeRO-Offload)通常由於在較慢的CPU上解除安裝計算而導致嚴重的GPU停滯。
我們很高興釋出ZenFlow,它透過重要性感知流水線解耦了GPU和CPU更新。透過將CPU工作和PCIe傳輸與GPU計算完全重疊,我們看到了超過85%的停滯減少,以及高達5倍的加速!這確保了我們可以在享受解除安裝帶來的記憶體優勢的同時,不會因為較慢的硬體而犧牲訓練速度。
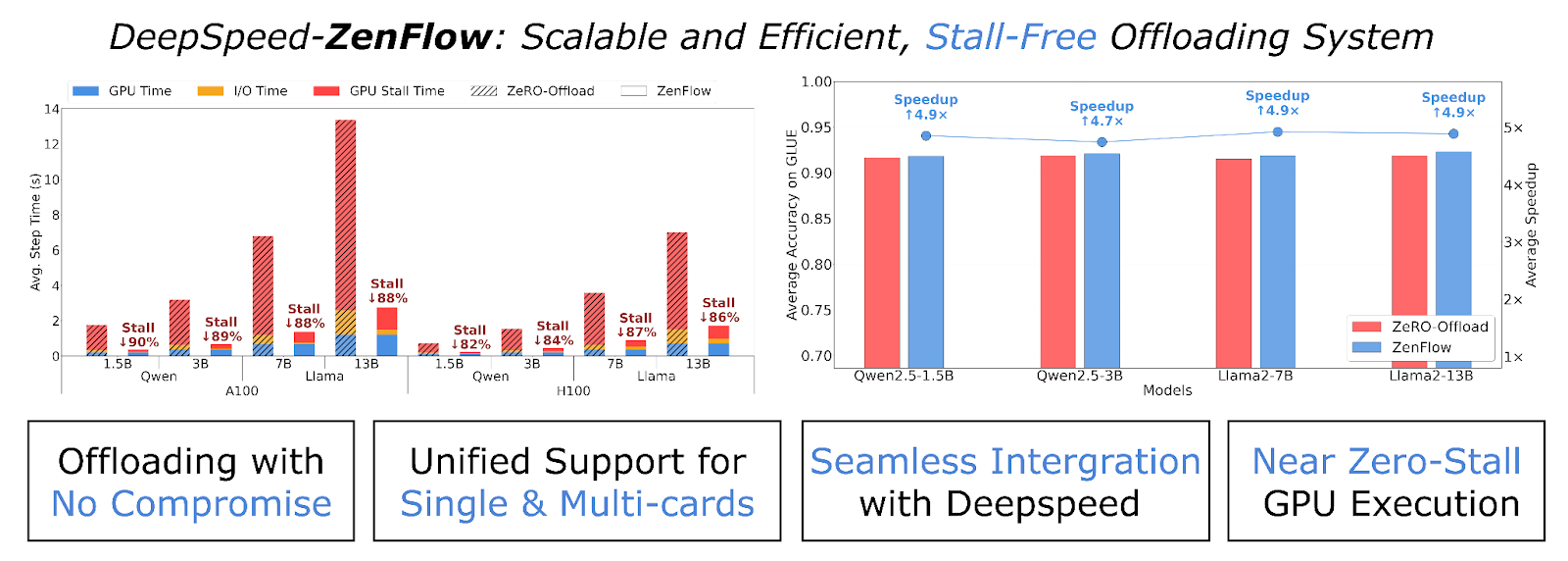
圖1:ZenFlow是DeepSpeed用於LLM訓練的無停滯解除安裝引擎。它透過優先處理重要梯度以進行即時GPU更新,並將其餘梯度推遲到非同步CPU側累積,從而解耦了GPU和CPU的更新。透過將CPU工作和PCIe傳輸與GPU計算完全重疊,ZenFlow消除了停滯,並在單GPU和多GPU設定中實現了高硬體利用率。
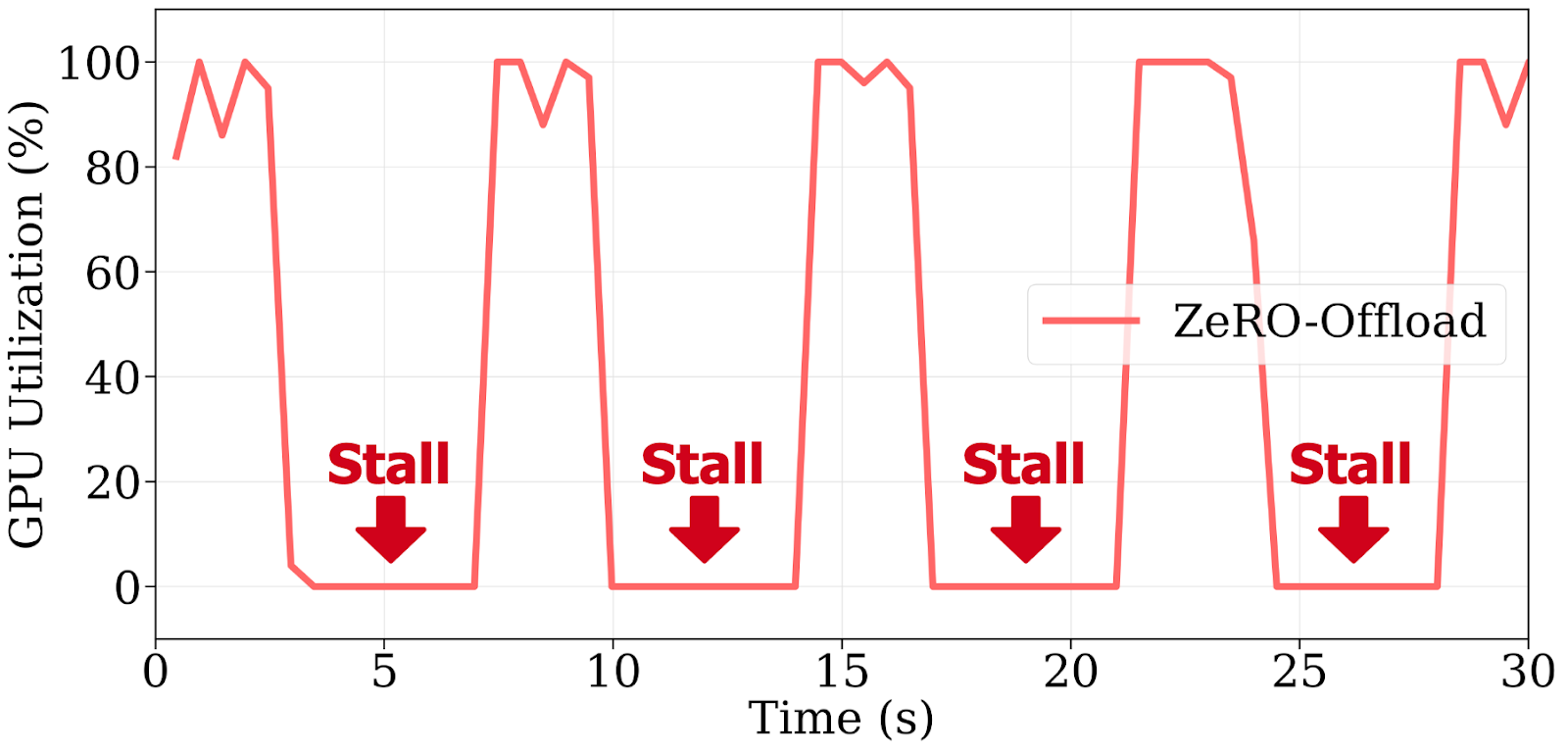
圖2:ZeRO-Offload由於阻塞CPU更新和PCIe傳輸,導致重複的GPU停滯,在4塊A100上訓練Llama 2-7B時,每步閒置時間超過60%。
解除安裝已成為一種標準方法,用於將大型語言模型(LLM)的微調擴充套件到超出GPU記憶體限制。ZeRO-Offload等框架透過將梯度和最佳化器狀態推送到CPU來減少GPU記憶體使用。然而,它們也建立了一個新的瓶頸:昂貴的GPU經常閒置,等待緩慢的CPU更新和PCIe資料傳輸。實際上,在4塊A100 GPU上訓練Llama 2-7B時啟用解除安裝,可以將每步時間從0.5秒增加到7秒以上,這是一個14倍的減速。
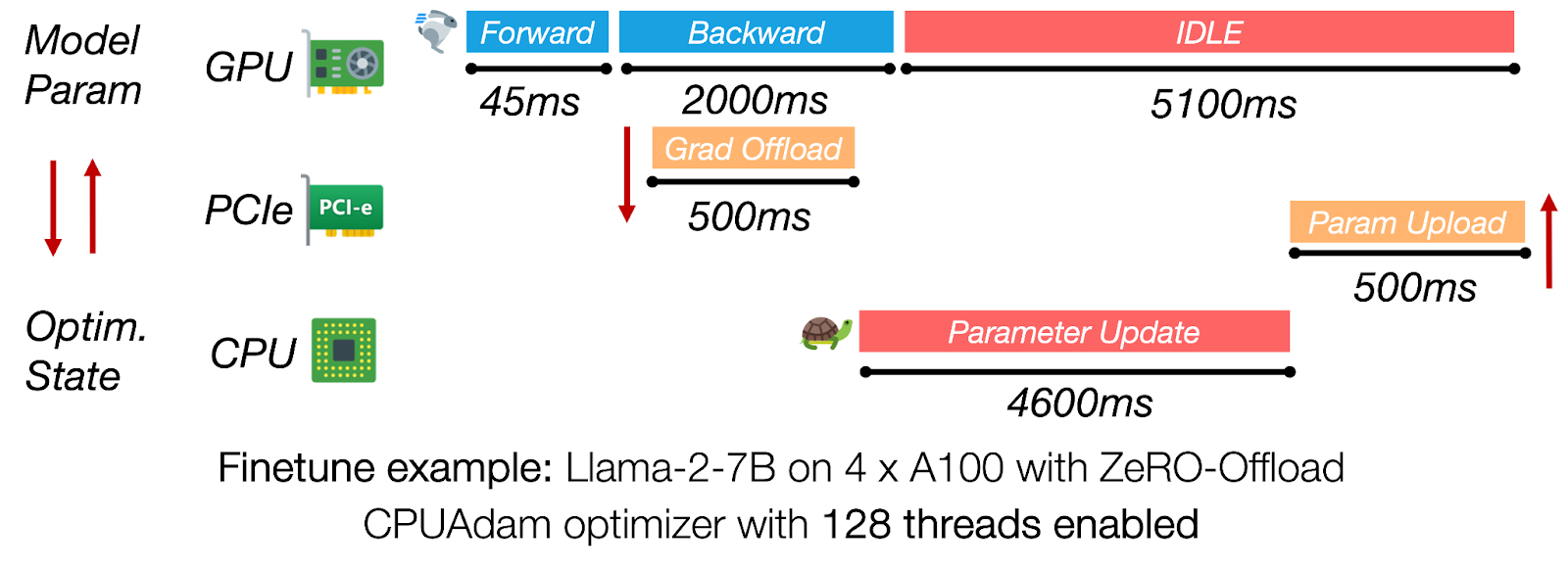
圖3:在ZeRO-Offload中,CPU側最佳化器更新和PCIe傳輸佔據了迭代時間的主導地位,使GPU閒置超過5秒。
ZenFlow 透過無停滯訓練流水線解決了這一瓶頸。它優先處理高影響力的梯度以進行即時GPU更新,同時將其餘梯度解除安裝到CPU並非同步應用它們。這些延遲的CPU更新與GPU計算完全重疊,消除了停滯並顯著提高了吞吐量。最重要的是,ZenFlow保持了相同的模型精度,並與DeepSpeed無縫整合。
ZenFlow 概覽
- 零GPU停滯: 最重要的k個梯度立即在GPU上更新;低優先順序梯度在CPU上非同步處理——沒有GPU等待時間。
- 非同步且有界: ZenFlow透過有界陳舊性策略解耦了CPU和GPU的執行,從而保持了收斂性。
- 自動調優: ZenFlow根據梯度動態在執行時調整更新間隔——無需手動調優。
ZenFlow 亮點
ZenFlow 是第一個提供有界非同步更新方案的解除安裝框架,該方案在保持收斂性的同時,實現了相對於ZeRO-Offload高達5倍的端到端加速。
效能
| 特性 | 優勢 |
|---|---|
| 相對於ZeRO-Offload高達5倍的端到端加速,相對於ZeRO-Infinity高達6.3倍的加速 | 更快的收斂時間 |
| 在A100/H100節點上GPU停滯減少> 85% | 保持GPU繁忙,更高的利用率 |
| PCIe流量降低約2倍(每步1.13倍模型大小,而ZeRO中為2倍) | 減少叢集頻寬壓力 |
| 在GLUE上保持或提高了精度(OPT-350M → Llama-13B) | 無精度損失 |
| 輕量級梯度選擇(比完全AllGather便宜6000倍) | 擴充套件到多GPU設定而不會出現記憶體佔用飆升 |
| 自動調優(Zen-auto)在執行時自動調整更新間隔 | 無需手動調整引數 |
有關更詳細的效能結果,請參閱我們的arXiv論文。
設計動機
使用解除安裝訓練大型模型可以節省GPU記憶體,但通常以犧牲效能為代價。在本節中,我們將簡要討論三個主題。首先,我們解釋為什麼將CPU側最佳化器更新與GPU計算耦合會導致LLM微調期間嚴重的GPU停滯。其次,我們量化了全梯度解除安裝如何飽和A100/H100伺服器有限的PCIe頻寬,從而增加了迭代時間。最後,我們揭示了梯度高度傾斜的重要性分佈,表明同時統一更新GPU中所有引數是浪費且不必要的。
解除安裝導致的GPU停滯
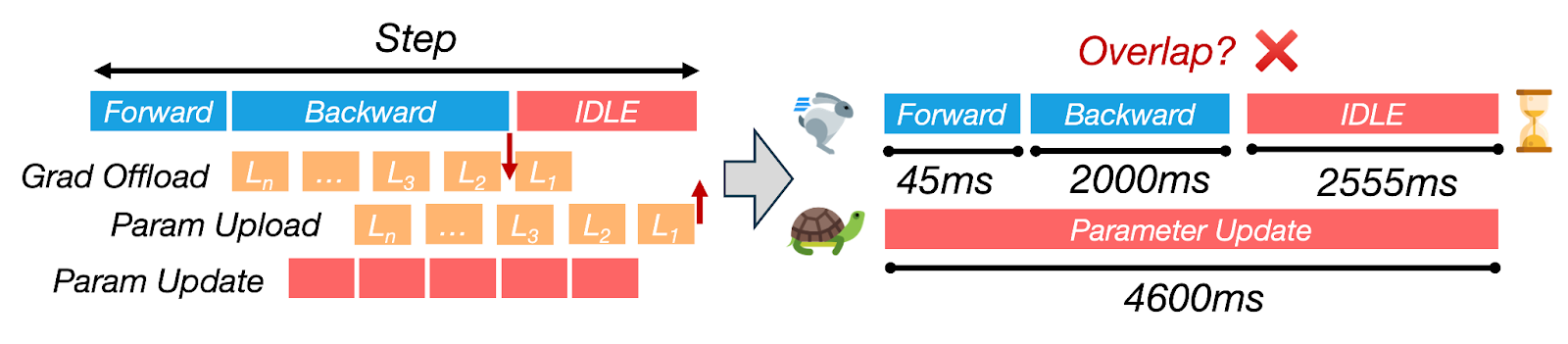
圖4:CPU更新主導了步長時間,由於與計算的重疊不足,導致GPU閒置超過60%。
同步解除安裝框架(例如,ZeRO-Offload)在CPU執行完整最佳化器步驟並將更新的引數傳輸回GPU時,使GPU處於空閒狀態。對於Llama-2-7B在4塊A100上的訓練,CPU路徑可能需要超過4秒,而反向傳播則需要大約2秒,因此每次迭代超過60%的時間是純粹的GPU等待時間。消除這種序列化對於實現高GPU利用率至關重要。
頻寬瓶頸
單個訓練步驟將完整的模型梯度副本從GPU傳輸到CPU,並將完整的模型引數副本傳回,即每步PCIe流量為模型大小的2倍。即使在PCIe 4.0(約32 GB/s)上,Llama-2-13B每次迭代也要傳輸約40 GB,增加了超過1秒的傳輸延遲。
梯度重要性不均
並非所有梯度都同等重要。我們的分析表明,在微調過程中,前1%的梯度通道貢獻了超過90%的L²範數能量。換句話說,大多數更新對模型學習的影響很小,但在傳統解除安裝流水線中仍會產生不成比例的高計算和I/O成本。
梯度重要性的這種傾斜為更好的設計打開了大門:立即在GPU上更新關鍵梯度,並將其餘梯度推遲到CPU上進行非同步批次、低優先順序的更新。ZenFlow將這一想法轉化為一個原則性的、高效的訓練引擎。
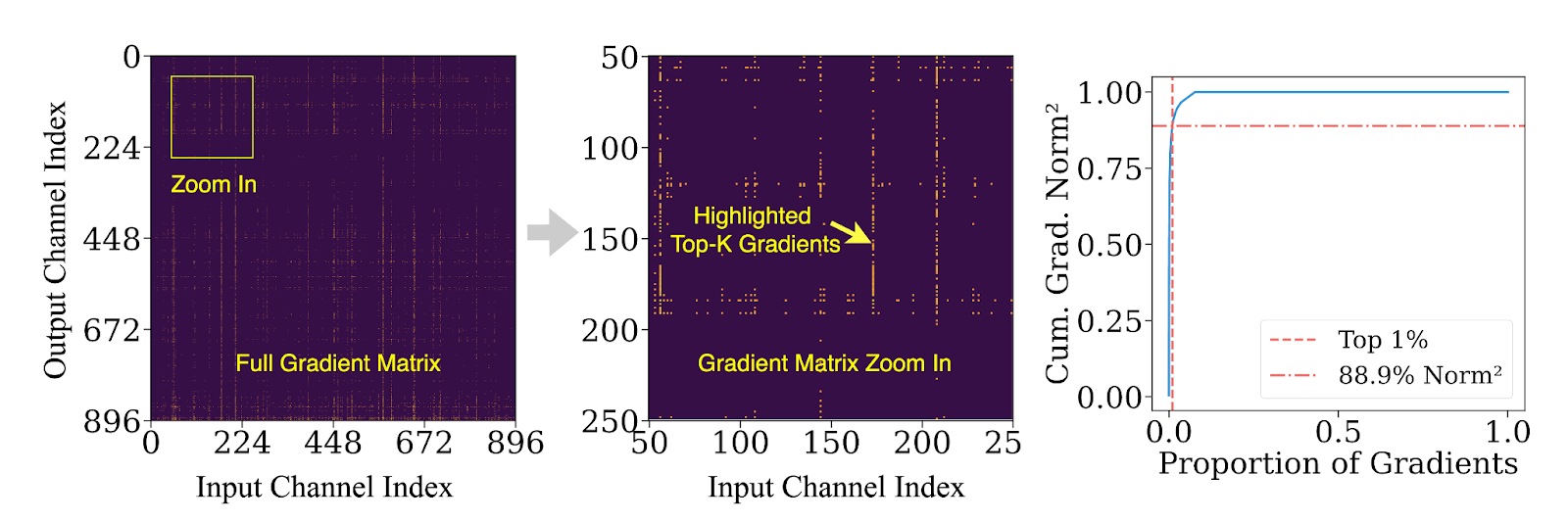
圖5:前1%的梯度可能貢獻超過85%的梯度範數。
ZenFlow設計
ZenFlow圍繞三個關鍵思想進行設計,這些思想將關鍵和非關鍵梯度更新分開,同時最大限度地減少通訊瓶頸。以下是我們如何打破GPU和CPU計算之間的緊密耦合,以建立無停滯流水線的方法。
思路1:重要性感知Top-k梯度更新
並非所有梯度對訓練的影響都相同。ZenFlow引入了重要性感知設計,優先更新前k個最重要的梯度。這些梯度直接在GPU上更新,利用其高計算頻寬。這種方法使我們能夠將每步梯度更新的大小減少近50%,從而將通訊負載減少約2倍。
對於其餘對模型學習貢獻較小的梯度,ZenFlow將它們批次處理並在CPU上執行非同步更新。這些更新會延遲,直到它們充分累積,從而減少對訓練速度的影響。
思路2:有界非同步CPU累積
ZenFlow的非同步累積允許CPU在GPU執行其他計算時保持忙碌。我們對非關鍵梯度應用了累積視窗,允許它們在多次迭代中累積,然後再進行更新。這使得ZenFlow能夠同時處理多輪梯度更新,消除了通常花費在等待CPU最佳化器上的空閒時間。
透過仔細協調CPU更新與GPU執行,ZenFlow完全隱藏了CPU執行在GPU計算之後——確保GPU保持活躍利用,避免停滯,並最大化硬體效率。
思路3:輕量級梯度選擇
分散式訓練中的一個主要挑戰是選擇重要的梯度,同時不引入過高的通訊和GPU記憶體成本。傳統系統依賴全域性同步(透過AllGather)來收集完整梯度,這在多GPU設定中可能成為主要瓶頸。
ZenFlow透過輕量級梯度代理解決了這個問題:ZenFlow不是傳輸完整的梯度,而是使用每列梯度範數來近似每個梯度的重要性。透過計算每列梯度的緊湊摘要(例如,平方範數),ZenFlow將通訊量減少了超過4,000倍——幾乎沒有精度損失。
這種方法使ZenFlow能夠高效地跨GPU擴充套件,而不會產生高記憶體或通訊開銷,並且它支援動態梯度選擇,因為模型會演變。
整合所有:ZenFlow的零停滯流水線
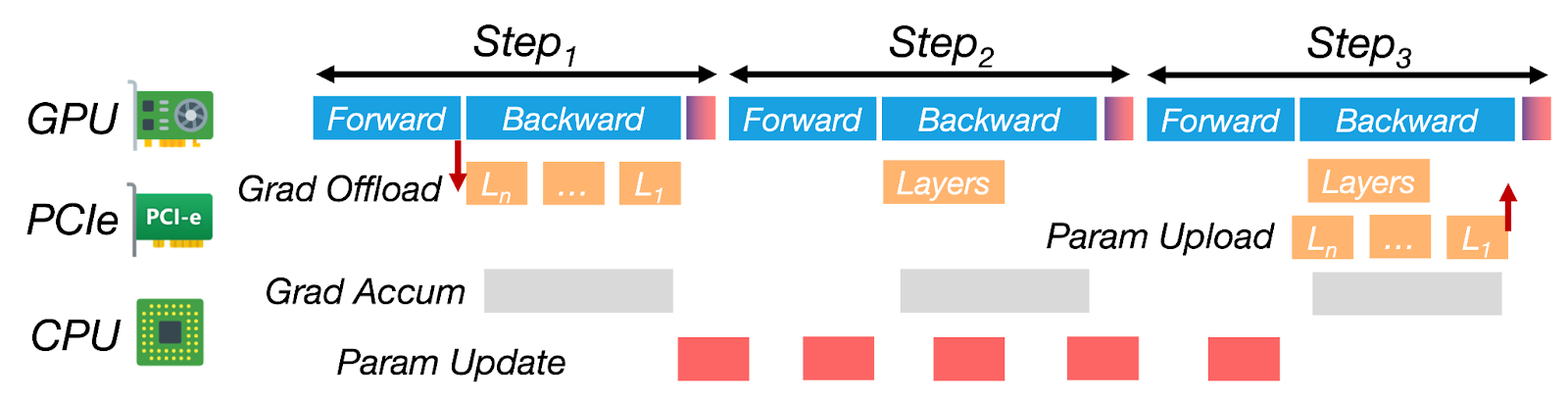
圖6:ZenFlow的無停滯流水線將CPU更新和傳輸與多步GPU計算重疊。
- GPU上的前向/後向傳播: ZenFlow在GPU上處理前向和後向傳播,立即在GPU上更新top-k梯度,而無需等待CPU。
- 梯度傳輸到CPU: 當GPU忙碌時,來自當前迭代(或先前迭代)的梯度透過專用PCIe流傳輸到CPU。這與GPU計算並行進行,不會導致任何GPU等待時間。
- CPU更新: 一旦累積了一批非關鍵梯度,CPU就會非同步執行更新。此更新通常跨越多個GPU迭代,但隱藏在GPU工作之後,使其在整個流水線中幾乎不可見。
- 雙緩衝: ZenFlow使用雙緩衝來管理新更新的梯度。當CPU更新完成後,新引數會傳回GPU。交換速度和指標翻轉一樣快——無需重新載入整個模型或重新啟動核心。
透過不斷將GPU計算與CPU側工作重疊,ZenFlow將傳統的計算→等待→更新迴圈轉變為連續的無停滯流水線。
入門:試用DeepSpeed-ZenFlow
要試用DeepSpeed-ZenFlow,請參閱我們DeepSpeedExamples倉庫中的ZenFlow示例以及DeepSpeed中的ZenFlow教程。
引用
@article{lan2025zenflow,
title = {ZenFlow: 透過非同步更新實現無停滯解除安裝訓練},
author = {Tingfeng Lan and Yusen Wu and Bin Ma and Zhaoyuan Su and Rui Yang and Tekin Bicer and Masahiro Tanaka and Olatunji Ruwase and Dong Li and Yue Cheng},
journal = {arXiv 預印本 arXiv:2505.12242},
year = {2025}
}
致謝
這項工作是弗吉尼亞大學 (UVA)、加利福尼亞大學默塞德分校 (UC Merced)、阿貢國家實驗室 (ANL) 和 DeepSpeed 團隊密切合作的成果。
貢獻者包括來自UVA的Tingfeng Lan、Yusen Wu、Zhaoyuan Su、Rui Yang和Yue Cheng;來自UC Merced的Bin Ma和Dong Li;來自ANL的Tekin Bicer;以及來自DeepSpeed團隊的Olatunji Ruwase和Masahiro Tanaka。我們特別感謝Olatunji Ruwase和Masahiro Tanaka的早期反饋和富有洞察力的討論,以及對開源社群的支援。