
此博文作者是Jae-Won Chung,密歇根大學的博士生,也是ML.ENERGY Initiative的負責人。
深度學習消耗相當大的能量。例如,在AWS p4d例項上訓練一個200B的LLM消耗了大約11.9 GWh(來源:CIDR 2024主題演講),這足以單獨為一個家庭提供一年的電力,而這個量能供超過一千個普通美國家庭使用一年。
Zeus是一個開源工具箱,用於測量和最佳化深度學習工作負載的能耗。我們的目標是,透過提供可組合且假設最少的工具,使基於精確測量的能耗最佳化儘可能簡單,適用於各種深度學習工作負載和設定。
Zeus主要提供兩類工具:
- 用於GPU能耗測量的程式設計和命令列工具
- 多種能耗最佳化工具,用於尋找最佳的ML和/或GPU配置
Zeus可以惠及以下人群:
- 測量和最佳化其電力成本
- 減少GPU散熱(透過降低功耗)
- 報告研發過程中的能耗
- 減少電力使用造成的碳足跡
第一部分:測量能耗
就像效能最佳化一樣,精確測量是有效能耗最佳化的基礎。流行的功耗估算代理,如硬體的最大功耗有時與實際測量值大相徑庭。
為了使能耗測量儘可能簡單透明,Zeus提供的核心工具是ZeusMonitor類。我們來看一下實際的程式碼片段。
from zeus.monitor import ZeusMonitor
# All four GPUs are measured simultaneously.
monitor = ZeusMonitor(gpu_indices=[0,1,2,3])
# Measure total time and energy within the window.
monitor.begin_window("training")
for e in range(100):
# Measurement windows can arbitrarily be overlapped.
monitor.begin_window("epoch")
for x, y in train_dataloader:
y_hat = model(x)
loss = criterion(y, y_hat)
loss.backward()
optim.step()
measurement = monitor.end_window("epoch")
print(f"Epoch {e}: {measurement.time} s, {measurement.total_energy} J")
measurement = monitor.end_window("training")
print(f"Entire training: {measurement.time} s, {measurement.total_energy} J")
您上面看到的是一個典型的PyTorch訓練迴圈,它使用四個GPU進行資料並行訓練。在其中,我們建立了一個ZeusMonitor例項,並傳入一個要監控的GPU索引列表。然後,使用該監視器,我們可以透過配對呼叫begin_window和end_window來測量訓練指令碼中任意執行視窗的時間和能耗。多個視窗可以以任意方式重疊和巢狀,只要它們的名稱不同,就不會影響彼此的測量。
ZeusMonitor帶來的開銷非常小——通常是個位數毫秒。這使得ZeusMonitor可以用於各種應用。例如:
- ML.ENERGY排行榜:首個關於LLM文字生成消耗多少能量的開源基準。
- ML.ENERGY競技場:一個線上服務,允許使用者根據響應質量和能耗並排比較LLM響應。
請參閱我們的部落格文章,瞭解更深入的GPU能耗測量技術細節。
第二部分:最佳化能耗
讓我向您介紹Zeus提供的兩個能耗最佳化器。
GlobalPowerLimitOptimizer
GPU允許使用者配置其最大功耗,稱為功率限制。通常,當您將GPU的功率限制從預設最大值降低時,計算速度可能會稍微變慢,但您將節省不成比例的更多能量。Zeus中的GlobalPowerLimitOptimizer會自動全域性查詢所有GPU的最佳功率限制。
from zeus.monitor import ZeusMonitor
from zeus.optimizer.power_limit import GlobalPowerLimitOptimizer
# The optimizer measures time and energy through the ZeusMonitor.
monitor = ZeusMonitor(gpu_indices=[0,1,2,3])
plo = GlobalPowerLimitOptimizer(monitor)
for e in range(100):
plo.on_epoch_begin()
for x, y in train_dataloader:
plo.on_step_begin()
y_hat = model(x)
loss = criterion(y, y_hat)
loss.backward()
optim.step()
plo.on_step_end()
plo.on_epoch_end()
在我們熟悉的PyTorch訓練迴圈中,我們例項化了GlobalPowerLimitOptimizer,並向其傳遞了一個ZeusMonitor例項,透過該例項,最佳化器可以感知到GPU。然後,我們只需要讓最佳化器知道訓練進度(步數和epoch邊界),最佳化器就會透明地完成所有必要的分析並收斂到最佳功率限制。
如果您正在使用HuggingFace的Trainer或SFTTrainer,整合會更加簡單:
from zeus.monitor import ZeusMonitor
from zeus.optimizer.power_limit import HFGlobalPowerLimitOptimizer
# ZeusMonitor actually auto-detects CUDA_VISIBLE_DEVICES.
monitor = ZeusMonitor()
pl_optimizer = HFGlobalPowerLimitOptimizer(monitor)
# Pass in the optimizer as a Trainer callback. Also works for SFTTrainer.
trainer = Trainer(
model=model,
train_dataset=train_dataset,
...,
callbacks=[pl_optimizer],
)
HFGlobalPowerLimitOptimizer封裝了GlobalPowerLimitOptimizer,使其能夠自動檢測步數和epoch邊界。我們在此處提供了整合示例這裡,包括執行Gemma 7B使用QLoRA進行監督微調。
現在我們知道了如何整合最佳化器,但什麼是最優功率限制呢?我們知道不同的使用者在權衡時間與能量方面可能有不同的偏好,因此我們允許使用者指定一個OptimumSelector(基本上是策略模式)來表達他們的需求。
# Built-in strategies for selecting the optimal power limit.
from zeus.optimizer.power_limit import (
GlobalPowerLimitOptimizer,
Time,
Energy,
MaxSlowdownConstraint,
)
# Minimize energy while tolerating at most 10% slowdown.
plo = GlobalPowerLimitOptimizer(
monitor,
MaxSlowdownConstraint(factor=1.1),
)
一些內建策略包括“最小化時間”(Time,這可能仍然會降低預設的功率限制,因為一些工作負載即使在較低的功率限制下也幾乎沒有減速),“最小化能量”(Energy),“兩者之間”(ZeusCost),以及“在最大減速限制下最小化能量”(MaxSlowdownConstraint)。使用者也可以根據需要建立自己的最佳選擇器。
PipelineFrequencyOptimizer
基於我們的研究論文Perseus,管道頻率最佳化器是我們針對大型模型訓練(如GPT-3)能耗最佳化的最新工作。Perseus可以減少大型模型訓練的能耗,而訓練吞吐量幾乎沒有或可以忽略不計的退化。我們將簡要介紹其原理。
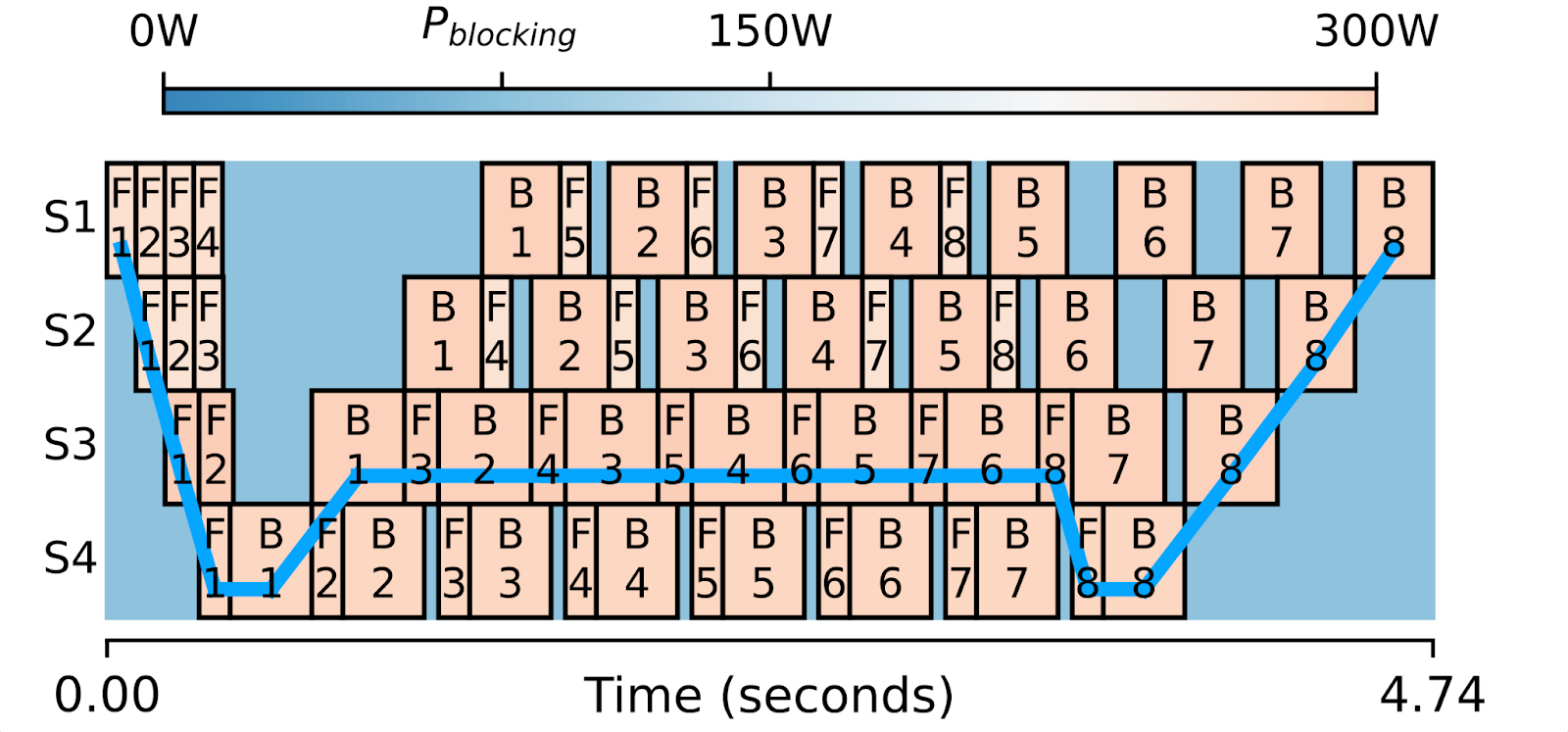
上圖是採用1F1B排程執行的四階段管道並行訓練的一次迭代的視覺化。每個方框代表一個前向或後向計算,並以其功耗著色。
這裡的關鍵觀察是,當模型被分割成管道階段時,很難將它們精確地分割成相等的大小。這導致前向/後向方框寬度不同,從而在方框之間產生計算空閒時間。您會注意到那些較小的方框可以比更寬的方框執行得稍慢,並且整體關鍵路徑(藍線)根本不會改變。
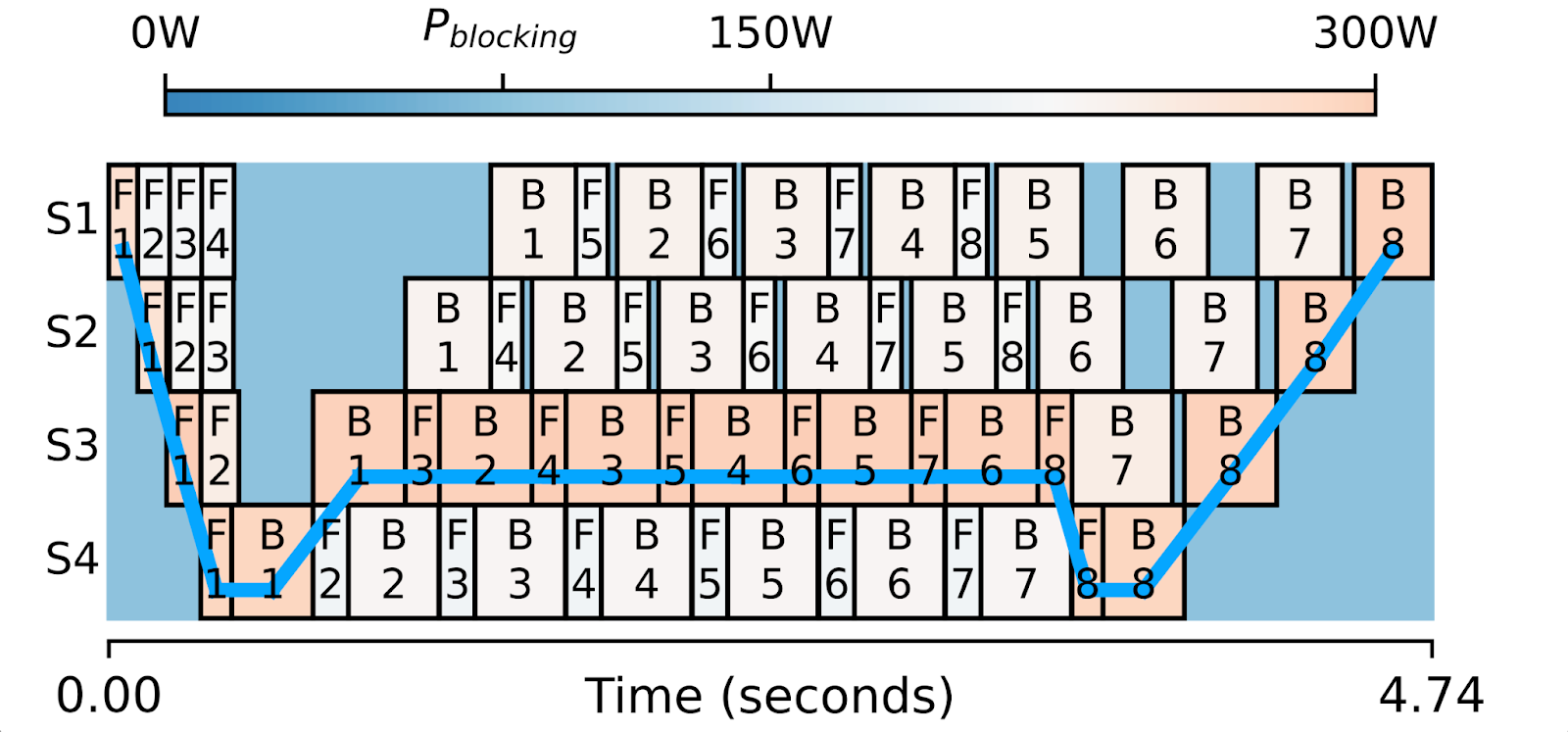
這就是Perseus自動完成的事情。它基於剖析,識別出不在關鍵路徑上的計算方框,並找出每個方框精確的減速量,以最小化能耗。如果操作正確,我們減速的計算將消耗更少的功率和能量,但管道的整體迭代時間不會改變。
請參閱我們的指南,開始使用Perseus!
最後的話
對於使用自己的本地計算的使用者來說,能耗和由此產生的電費是不容忽視的。從更大的範圍來看,能耗不僅僅是電費的問題,還涉及到資料中心的電力供應。隨著數千個GPU在叢集中執行,尋找穩定、經濟且可持續的電力來源來為資料中心供電正變得越來越具挑戰性。尋找能比減速不成比例地更多地減少能耗的方法,可以降低平均功耗,這有助於解決電力供應的挑戰。
透過Zeus,我們希望邁出深度學習能耗測量和最佳化的第一步。
想知道接下來要去哪裡?這裡有一些有用的連結:
- ML.ENERGY Initiative(即構建Zeus的人員)
- Zeus主頁/文件
- Zeus GitHub倉庫
- Zeus使用和整合示例