概覽
PyTorch 2.0 來了,這是 PyTorch 下一代 2.x 系列釋出的第一步。在過去幾年中,我們從 PyTorch 1.0 不斷創新和迭代,直至最新的 1.13 版本,並已遷移到新成立的 PyTorch 基金會,該基金會是 Linux 基金會的一部分。
PyTorch 除了我們出色的社群之外,其最大的優勢在於我們始終保持一流的 Python 整合、命令式風格、簡潔的 API 和豐富的選項。PyTorch 2.0 提供相同的 Eager Mode 開發和使用者體驗,同時從根本上改變並增強了 PyTorch 在編譯器層面的底層運作方式。我們能夠提供更快的效能,並支援動態形狀和分散式。
下面您將找到所有必要資訊,以更好地瞭解 PyTorch 2.0 是什麼、它的發展方向以及更重要的是如何立即開始使用(例如,教程、要求、模型、常見問題解答)。還有很多東西需要學習和開發,但我們期待社群的反饋和貢獻,以使 2.x 系列更好,並感謝所有為 1.x 系列取得成功做出貢獻的人。
PyTorch 2.x:更快、更符合Python習慣且一如既往地動態
今天,我們宣佈推出 torch.compile,這是一項將 PyTorch 效能推向新高,並開始將 PyTorch 的部分內容從 C++ 重新遷移回 Python 的功能。我們相信這是 PyTorch 的一個實質性新方向——因此我們稱之為 2.0。torch.compile 是一個完全附加(且可選)的功能,因此 2.0 從定義上來說是 100% 向後相容的。
支援 torch.compile 的是新技術——TorchDynamo、AOTAutograd、PrimTorch 和 TorchInductor。
-
TorchDynamo 使用 Python 幀評估鉤子安全地捕獲 PyTorch 程式,這是一項重大創新,是我們 5 年安全圖捕獲研發的成果。
-
AOTAutograd 透過過載 PyTorch 的自動求導引擎作為跟蹤自動微分器,用於生成提前(ahead-of-time)反向傳播跟蹤。
- PrimTorch 將 2000 多個 PyTorch 運算元規範化為大約 250 個原語運算元的封閉集合,開發者可以針對這些原語運算元構建完整的 PyTorch 後端。這大大降低了編寫 PyTorch 功能或後端的門檻。
- TorchInductor 是一個深度學習編譯器,可為多種加速器和後端生成快速程式碼。對於 NVIDIA 和 AMD GPU,它使用 OpenAI Triton 作為關鍵構建塊。
TorchDynamo、AOTAutograd、PrimTorch 和 TorchInductor 均用 Python 編寫,並支援動態形狀(即能夠傳送不同大小的張量而無需重新編譯),這使得它們靈活、易於修改,並降低了開發者和供應商的入門門檻。
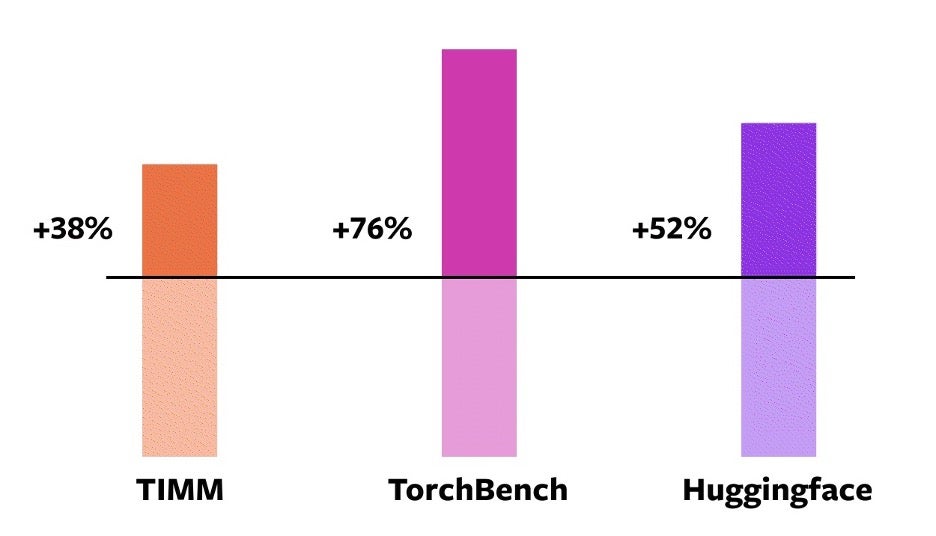
為了驗證這些技術,我們使用了來自各種機器學習領域的 163 個不同的開源模型。我們精心構建了此基準測試,以包括影像分類、目標檢測、影像生成、各種 NLP 任務(如語言建模、問答、序列分類)、推薦系統和強化學習等任務。我們將基準測試分為三類:
- 來自 HuggingFace Transformers 的 46 個模型
- 來自 TIMM 的 61 個模型:Ross Wightman 收集的最先進的 PyTorch 影像模型
- 來自 TorchBench 的 56 個模型:從 GitHub 上精選的一組流行程式碼庫
我們不會修改這些開源模型,只是在它們外面新增一個 torch.compile 呼叫。
然後,我們測量這些模型在速度上的提升並驗證其準確性。由於速度提升可能取決於資料型別,我們測量了 float32 和自動混合精度 (AMP) 的速度提升。我們報告了一個不均勻加權平均速度提升,即 0.75 * AMP + 0.25 * float32,因為我們發現 AMP 在實踐中更常見。
在這些 163 個開源模型中,torch.compile 在 93% 的時間裡都能正常工作,並且在 NVIDIA A100 GPU 上訓練時模型執行速度提高了 43%。在 Float32 精度下,平均執行速度提高了 21%,在 AMP 精度下,平均執行速度提高了 51%。
注意事項: 在 NVIDIA 3090 等桌面級 GPU 上,我們測得的速度提升低於 A100 等伺服器級 GPU。目前,我們的預設後端 TorchInductor 支援 CPU 和 NVIDIA Volta 及 Ampere GPU。它尚不支援其他 GPU、xPU 或舊款 NVIDIA GPU。
試用: torch.compile 仍處於開發的早期階段。從今天開始,您可以在 nightly 二進位制檔案中試用 torch.compile。我們預計在 2023 年 3 月初發布第一個穩定的 2.0 版本。
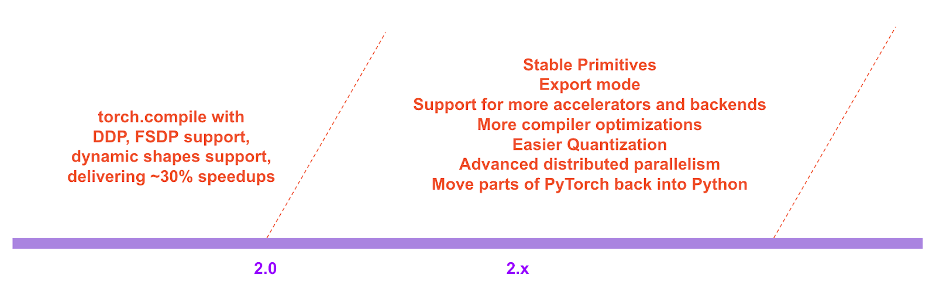
在 PyTorch 2.x 的路線圖中,我們希望在效能和可伸縮性方面進一步推動編譯模式。其中一些工作正在進行中,正如我們今天在大會上談到的那樣。其中一些工作尚未開始。其中一些工作是我們希望看到的,但我們沒有精力自己完成。如果您有興趣做出貢獻,請在本月開始的“工程師問答:2.0 現場問答系列”(詳情見本文末尾)和/或透過 Github / 論壇與我們交流。
推薦語
以下是 PyTorch 的一些使用者對我們新方向的評價
Sylvain Gugger,HuggingFace Transformers 的主要維護者
“只需新增一行程式碼,PyTorch 2.0 就能在訓練 Transformer 模型時帶來 1.5 倍到 2 倍的速度提升。這是自混合精度訓練推出以來最令人興奮的事情!”
Ross Wightman,TIMM 的主要維護者(PyTorch 生態系統中最大的視覺模型中心之一)
“它開箱即用,無需更改程式碼即可與大多數 TIMM 模型進行推理和訓練工作。”
Luca Antiga,Lightning AI 的 CTO,以及 PyTorch Lightning 的主要維護者之一
“PyTorch 2.0 體現了深度學習框架的未來。在幾乎無需使用者干預的情況下捕獲 PyTorch 程式,並開箱即用地獲得巨大的裝置端加速和程式操作,為 AI 開發者開啟了全新的維度。”
動機
我們對 PyTorch 的理念始終是把靈活性和可修改性放在首位,效能緊隨其後。我們一直追求:
- 高效能 Eager 執行
- Python 風格的內部實現
- 對分散式、自動微分、資料載入、加速器等方面的良好抽象
自 2017 年推出 PyTorch 以來,硬體加速器(如 GPU)的計算速度提升了約 15 倍,記憶體訪問速度提升了約 2 倍。因此,為了保持 Eager 執行的高效能,我們不得不將 PyTorch 內部的大部分內容遷移到 C++。將內部內容遷移到 C++ 會降低其可修改性,並增加程式碼貢獻的門檻。
從第一天起,我們就知道 Eager 執行的效能限制。2017 年 7 月,我們啟動了第一個 PyTorch 編譯器開發研究專案。編譯器需要讓 PyTorch 程式執行得更快,但不能以犧牲 PyTorch 體驗為代價。我們的關鍵標準是保留某些靈活性——支援研究人員在探索的各個階段使用的動態形狀和動態程式。

技術概覽
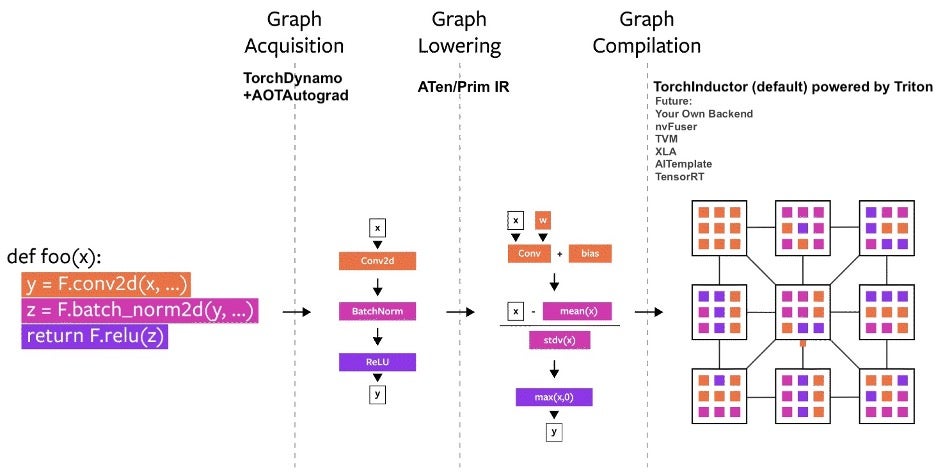
多年來,我們已經在 PyTorch 內部構建了多個編譯器專案。讓我們將編譯器分為三個部分:
- 圖獲取
- 圖降低
- 圖編譯
在構建 PyTorch 編譯器時,圖獲取是更具挑戰性的任務。
在過去的五年裡,我們構建了 torch.jit.trace、TorchScript、FX 跟蹤、Lazy Tensors。但這些都未能完全滿足我們的期望。有些靈活但不快,有些快但不靈活,有些則既不快也不靈活。有些使用者體驗很差(例如悄無聲息地出錯)。TorchScript 雖然很有前景,但它需要對您的程式碼以及您的程式碼所依賴的程式碼進行大量修改。這種對程式碼進行大量修改的需求使它對許多 PyTorch 使用者來說無法啟動。
TorchDynamo:可靠快速地獲取圖
今年早些時候,我們開始開發 TorchDynamo,它使用 PEP-0523 中引入的 CPython 功能,稱為 Frame Evaluation API。我們採用資料驅動的方法來驗證其在圖捕獲方面的有效性。我們使用 PyTorch 編寫的 7000 多個 Github 專案作為我們的驗證集。雖然 TorchScript 和其他工具很難在 50% 的時間裡獲取到圖,而且通常開銷很大,但 TorchDynamo 在 99% 的時間裡都能正確、安全且以可忽略不計的開銷獲取到圖——無需對原始程式碼進行任何更改。那時我們知道,我們終於在靈活性和速度方面突破了多年來一直困擾我們的障礙。
TorchInductor:使用即時定義 IR 快速生成程式碼
對於 PyTorch 2.0 的新編譯器後端,我們從使用者編寫高效能自定義核函式的方式中汲取靈感:他們越來越多地使用 Triton 語言。我們還希望編譯器後端使用與 PyTorch eager 類似的抽象,並且足夠通用以支援 PyTorch 中廣泛的功能。TorchInductor 使用 Python 風格的即時定義迴圈級 IR,將 PyTorch 模型自動對映到 GPU 上的生成 Triton 程式碼和 CPU 上的 C++/OpenMP。TorchInductor 的核心迴圈級 IR 只包含約 50 個運算元,並且是用 Python 實現的,這使得它易於修改和擴充套件。
AOTAutograd:重用自動求導以實現提前圖
對於 PyTorch 2.0,我們知道我們想要加速訓練。因此,不僅要捕獲使用者級程式碼,還要捕獲反向傳播至關重要。此外,我們知道我們想要重用現有的經過實戰檢驗的 PyTorch 自動求導系統。AOTAutograd 利用 PyTorch 的 torch_dispatch 可擴充套件機制來跟蹤我們的自動求導引擎,使我們能夠“提前”捕獲反向傳播。這使我們能夠使用 TorchInductor 加速前向和反向傳播。
PrimTorch:穩定的原語運算子
為 PyTorch 編寫後端是一項挑戰。PyTorch 有 1200 多個運算子,如果考慮每個運算子的各種過載,則有 2000 多個。
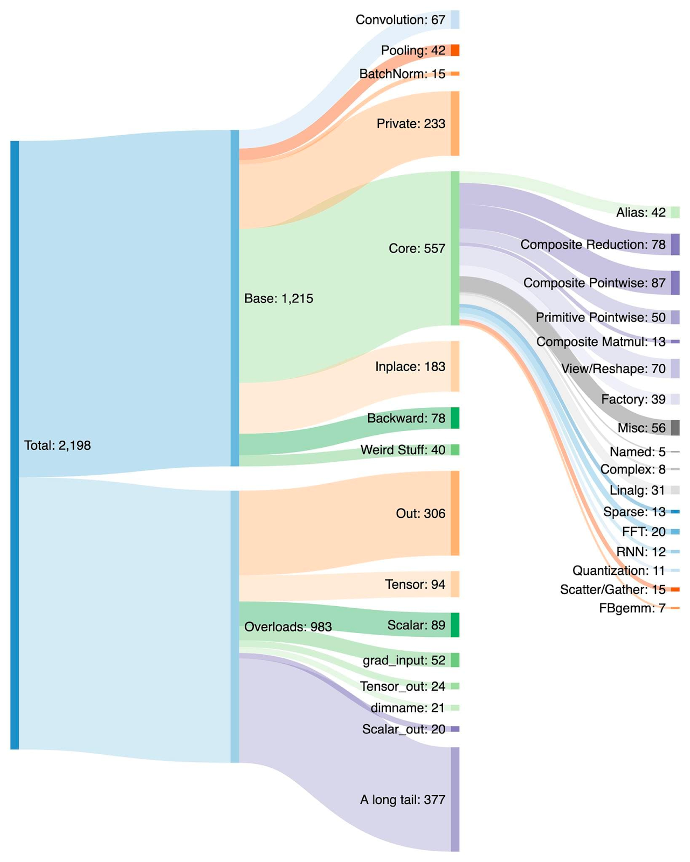
因此,編寫後端或橫切功能變得一項耗費精力的工作。在 PrimTorch 專案中,我們正在致力於定義更小、更穩定的運算元集。PyTorch 程式可以始終被降低到這些運算元集。我們的目標是定義兩個運算元集:
- Prim 運算元,大約有 250 個,級別相當低。它們適用於編譯器,因為它們的級別足夠低,需要將它們重新融合在一起才能獲得良好的效能。
- ATen 運算元,大約有 750 個規範運算元,適合原樣匯出。它們適用於已經在 ATen 級別整合的後端,或者無法透過編譯從較低級別運算元集(如 Prim 運算元)中恢復效能的後端。
我們將在下面的開發者/供應商體驗部分詳細討論此主題
使用者體驗
我們引入了一個簡單的函式 torch.compile,它包裝您的模型並返回一個編譯後的模型。
compiled_model = torch.compile(model)
這個 compiled_model 持有對您的模型的引用,並將 forward 函式編譯成一個更最佳化的版本。在編譯模型時,我們提供了一些旋鈕來調整它:
def torch.compile(model: Callable,
*,
mode: Optional[str] = "default",
dynamic: bool = False,
fullgraph:bool = False,
backend: Union[str, Callable] = "inductor",
# advanced backend options go here as kwargs
**kwargs
) -> torch._dynamo.NNOptimizedModule
-
mode 指定編譯器在編譯時應最佳化什麼。
- 預設模式是一個預設,它嘗試高效編譯,而不會花費太長時間或使用額外的記憶體。
- 其他模式,例如
reduce-overhead,會大大減少框架開銷,但會額外佔用少量記憶體。max-autotune會編譯很長時間,試圖為您提供能生成的執行最快的程式碼。
- dynamic 指定是否啟用動態形狀的程式碼路徑。某些編譯器最佳化不能應用於動態形狀程式。明確您是想要具有動態形狀還是靜態形狀的編譯程式將幫助編譯器為您提供更好的最佳化程式碼。
- fullgraph 類似於 Numba 的
nopython。它將整個程式編譯成一個單一的圖,否則會報錯解釋原因。大多數使用者不需要使用此模式。如果您非常注重效能,那麼您可以嘗試使用它。 - backend 指定要使用的編譯器後端。預設情況下使用 TorchInductor,但還有其他一些可用。

編譯體驗旨在以預設模式提供大部分好處和最大的靈活性。這是您在每種模式下獲得的心智模型。
現在,讓我們看一個編譯真實模型並執行它(使用隨機資料)的完整示例。
import torch
import torchvision.models as models
model = models.resnet18().cuda()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
compiled_model = torch.compile(model)
x = torch.randn(16, 3, 224, 224).cuda()
optimizer.zero_grad()
out = compiled_model(x)
out.sum().backward()
optimizer.step()
第一次執行 compiled_model(x) 時,它會編譯模型。因此,執行時間會更長。後續執行會很快。
模式
編譯器有一些預設,以不同的方式調整編譯後的模型。您可能正在執行一個由於框架開銷而緩慢的小型模型。或者,您可能正在執行一個幾乎不適合記憶體的大型模型。根據您的需求,您可能需要使用不同的模式。
# API NOT FINAL
# default: optimizes for large models, low compile-time
# and no extra memory usage
torch.compile(model)
# reduce-overhead: optimizes to reduce the framework overhead
# and uses some extra memory. Helps speed up small models
torch.compile(model, mode="reduce-overhead")
# max-autotune: optimizes to produce the fastest model,
# but takes a very long time to compile
torch.compile(model, mode="max-autotune")
讀取和更新屬性
訪問模型屬性的方式與在 eager 模式下相同。您可以像通常那樣訪問或修改模型的屬性(例如 model.conv1.weight)。這在程式碼修正方面是完全安全可靠的。TorchDynamo 會在程式碼中插入防護措施,以檢查其假設是否成立。如果屬性以某種方式發生變化,TorchDynamo 會知道根據需要自動重新編譯。
# optimized_model works similar to model, feel free to access its attributes and modify them
optimized_model.conv1.weight.fill_(0.01)
# this change is reflected in model
鉤子
Module 和 Tensor 鉤子目前尚未完全發揮作用,但隨著我們開發完成,它們最終將發揮作用。
序列化
您可以序列化 optimized_model 或 model 的狀態字典。它們指向相同的引數和狀態,因此是等效的。
torch.save(optimized_model.state_dict(), "foo.pt")
# both these lines of code do the same thing
torch.save(model.state_dict(), "foo.pt")
目前無法序列化 optimized_model。如果您希望直接儲存物件,請改用 model。
torch.save(optimized_model, "foo.pt") # Error
torch.save(model, "foo.pt") # Works
推理與匯出
對於模型推理,在使用 torch.compile 生成編譯模型後,請在實際模型服務之前執行一些預熱步驟。這有助於緩解初始服務期間的延遲峰值。
此外,我們將引入一種名為 torch.export 的模式,它將仔細匯出整個模型和防護基礎設施,以適應需要保證和可預測延遲的環境。torch.export 需要更改您的程式,尤其是當您有依賴資料的控制流時。
# API Not Final
exported_model = torch._dynamo.export(model, input)
torch.save(exported_model, "foo.pt")
這正處於開發的早期階段。請在 PyTorch 大會上收看有關匯出路徑的演講以獲取更多詳細資訊。您還可以透過本月開始的“工程師問答:2.0 現場問答系列”參與此主題(更多詳細資訊見本文末尾)。
除錯問題
編譯模式不透明且難以除錯。您會有這樣的疑問:
- 我的程式在編譯模式下為什麼會崩潰?
- 編譯模式和 eager 模式一樣準確嗎?
- 我為什麼看不到加速效果?
如果編譯模式產生錯誤、崩潰或與 eager 模式結果不同(超出機器精度限制),則很可能不是您的程式碼的錯。但是,瞭解導致此錯誤的程式碼片段是很有用的。
為了幫助除錯和重現,我們建立了多種工具和日誌記錄功能,其中一個突出的是:Minifier。
Minifier 會自動將您看到的問題縮小到一小段程式碼。這小段程式碼會重現原始問題,您可以將縮減後的程式碼提交到 GitHub issue。這將有助於 PyTorch 團隊輕鬆快速地修復問題。
如果您沒有看到預期的加速效果,那麼我們有 torch._dynamo.explain 工具,它會解釋您程式碼的哪些部分導致了我們所說的“圖中斷”。圖中斷通常會阻礙編譯器加速程式碼,減少圖中斷的數量可能會加速您的程式碼(直到收益遞減的某個限制)。
您可以在我們的故障排除指南中閱讀有關這些以及更多內容。
動態形狀
在研究支援 PyTorch 程式碼通用性所需的功能時,一個關鍵要求是支援動態形狀,並允許模型接收不同大小的張量,而無需在每次形狀更改時都重新編譯。
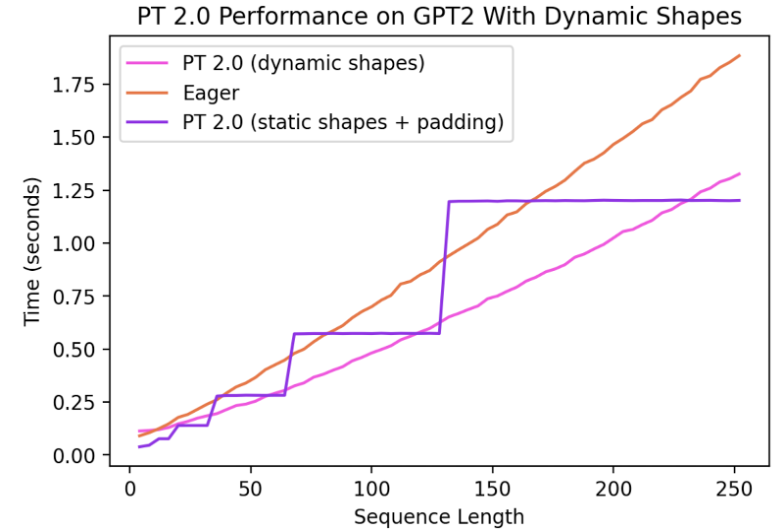
目前,對動態形狀的支援是有限的,並且正在快速開發中。它將在穩定版本中完全實現。它受 dynamic=True 引數的控制,我們在一個功能分支(symbolic-shapes)上取得了更多進展,在該分支上我們已成功使用 TorchInductor 運行了具有完整符號形狀的 BERT_pytorch 訓練。對於具有動態形狀的推理,我們有更廣泛的覆蓋。例如,讓我們看看動態形狀有用的常見設定——使用語言模型進行文字生成。
我們可以看到,即使形狀從 4 動態變化到 256,編譯模式仍能持續超越 Eager 模式達 40%。如果沒有動態形狀支援,常見的解決方法是填充到最接近的二次冪。然而,從下面的圖表可以看出,這會帶來大量的效能開銷,並且還會導致顯著更長的編譯時間。此外,有時正確地進行填充並非易事。
透過在 PyTorch 2.0 的編譯模式中支援動態形狀,我們可以獲得最佳的效能和易用性。
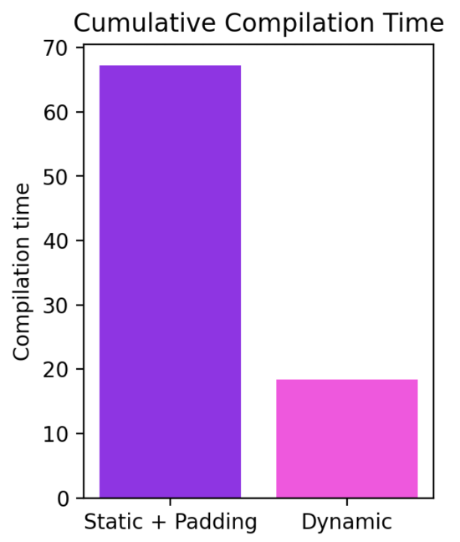
目前的工作進展非常迅速,隨著我們對基礎設施進行根本性改進,我們可能會暫時讓一些模型出現退步。有關我們動態形狀進展的最新更新可以在這裡找到。
分散式
總而言之,torch.distributed 的兩個主要分散式包裝器在編譯模式下執行良好。
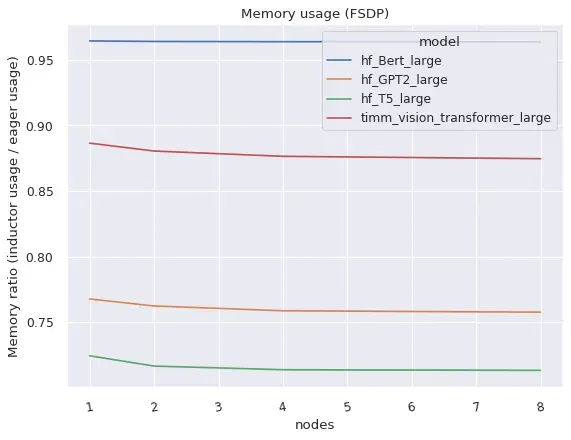
DistributedDataParallel (DDP) 和 FullyShardedDataParallel (FSDP) 均在編譯模式下工作,並相對於 eager 模式提供了改進的效能和記憶體利用率,但存在一些注意事項和限制。
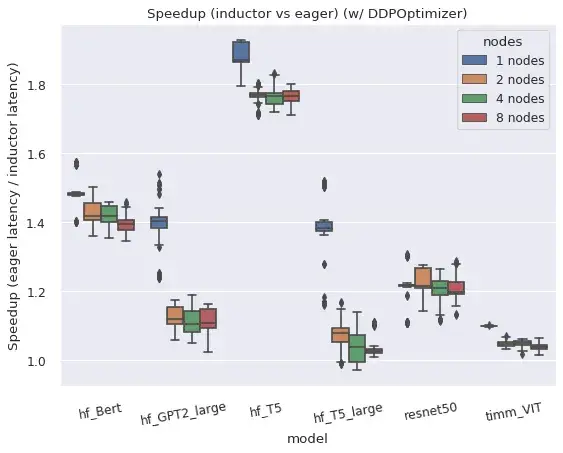
右圖:FSDP 在編譯模式下比 eager 模式佔用更少的記憶體。
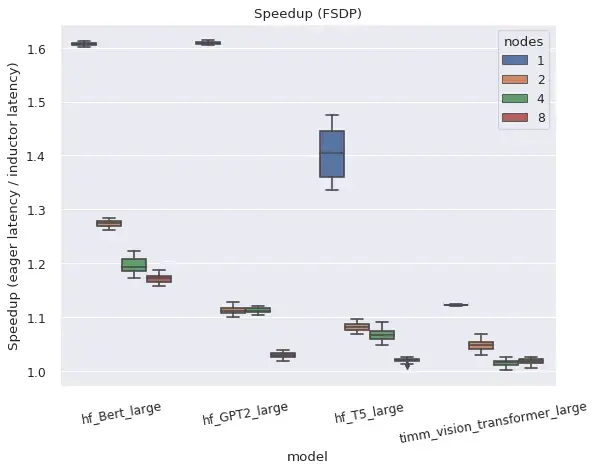
DistributedDataParallel (DDP)
DDP 依賴於將 AllReduce 通訊與反向計算重疊,並將較小的每層 AllReduce 操作分組到“桶”中以提高效率。TorchDynamo 編譯的 AOTAutograd 函式在與 DDP 簡單組合時會阻止通訊重疊,但透過為每個“桶”編譯單獨的子圖並允許通訊操作發生在子圖外部和之間,可以恢復效能。DDP 在編譯模式下目前還需要 static_graph=False。有關 DDP + TorchDynamo 方法和結果的更多詳細資訊,請參閱此帖子。
FullyShardedDataParallel (FSDP)
FSDP 本身是一個“beta”版 PyTorch 功能,由於能夠調整哪些子模組被包裝以及通常有更多的配置選項,因此它比 DDP 具有更高的系統複雜性。如果配置了 use_original_params=True 標誌,FSDP 可以與 TorchDynamo 和 TorchInductor 配合使用,適用於各種流行模型。目前預計會出現一些特定模型或配置的相容性問題,但我們會積極改進,如果提交了 github issue,特定模型可以優先處理。
使用者透過 auto_wrap_policy 引數指定模型的哪些子模組應該在 FSDP 例項中一起包裝以用於狀態分片,或者手動將子模組包裝到 FSDP 例項中。例如,許多 Transformer 模型在每個“Transformer 塊”都被包裝在單獨的 FSDP 例項中時工作良好,因此只需要同時例項化一個 Transformer 塊的完整狀態。Dynamo 將在每個 FSDP 例項的邊界插入圖中斷,以允許前向(和反向)中的通訊操作在圖外部並行於計算發生。
如果 FSDP 在不將子模組包裝在單獨例項中的情況下使用,它會退回到類似於 DDP 的操作模式,但沒有分桶。因此,所有梯度都在一個操作中減少,即使在 Eager 模式下也無法實現計算/通訊重疊。此配置僅在 TorchDynamo 中測試了功能性,但未測試效能。
開發者/供應商體驗
透過 PyTorch 2.0,我們希望簡化後端(編譯器)整合體驗。為此,我們專注於減少運算元數量和簡化為構建 PyTorch 後端所需的運算元集的語義。
以圖形形式表示,PT2 棧如下:
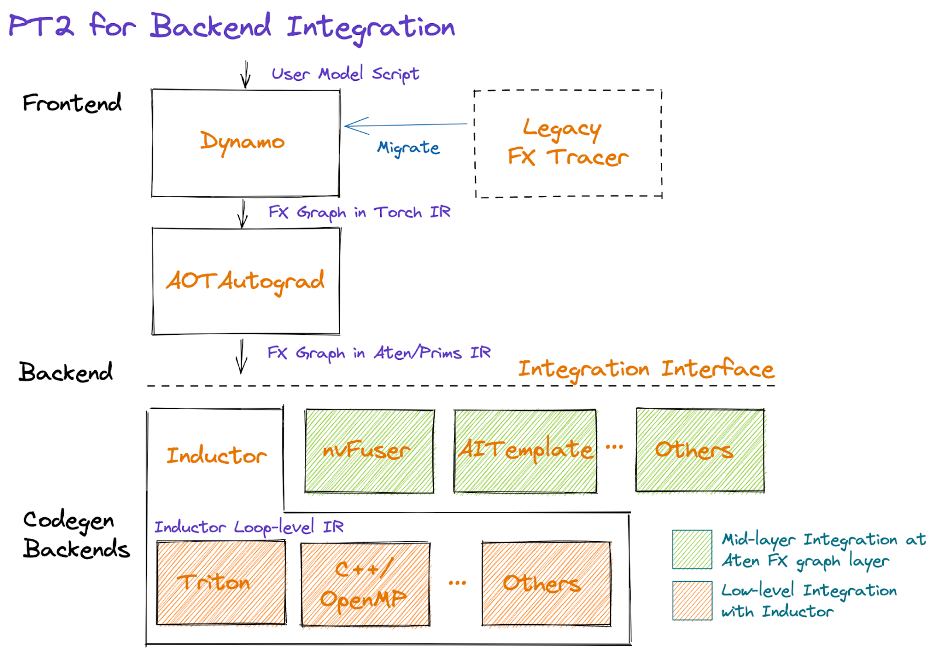
從圖的中間開始,AOTAutograd 動態地以提前(ahead-of-time)方式捕獲自動求導邏輯,生成 FX 圖格式的前向和反向運算元圖。
我們提供了一組經過強化的分解(即用其他運算元實現的運算元),可以利用它們來減少後端需要實現的運算元數量。我們還透過一種稱為“功能化”(functionalization)的過程,透過選擇性地重寫複雜的 PyTorch 邏輯(包括修改和檢視)以及保證運算元元資料資訊(如形狀傳播公式),來簡化PyTorch 運算元的語義。這項工作正在積極進行中;我們的目標是提供一組具有簡化語義的、大約 250 個的原始且穩定的運算元,稱為 PrimTorch,供應商可以利用(即選擇使用)它們來簡化他們的整合。
在減少和簡化運算元集之後,後端可以選擇在 Dynamo(即中間層,緊接 AOTAutograd 之後)或 Inductor(底層)整合。我們將在下面描述做出此選擇的一些考慮因素,以及未來圍繞後端混合的工作。
Dynamo 後端
擁有現有編譯器堆疊的供應商可能會發現,最容易整合作為 TorchDynamo 後端,接收基於 ATen/Prims IR 的 FX 圖。請注意,對於訓練和推理,整合點將緊接在 AOTAutograd 之後,因為我們目前將分解作為 AOTAutograd 的一部分應用,並且如果針對推理,則僅跳過與反向傳播相關的步驟。
Inductor 後端
供應商還可以將他們的後端直接整合到 Inductor 中。Inductor 接收由 AOTAutograd 生成的包含 ATen/Prim 操作的圖,並將其進一步降低到迴圈級 IR。目前,Inductor 為逐點、歸約、散佈/聚集和視窗操作提供了迴圈級 IR 的降低。此外,Inductor 建立融合組,進行索引簡化,維度摺疊,並調整迴圈迭代順序以支援高效的程式碼生成。供應商可以透過提供從迴圈級 IR 到硬體特定程式碼的對映來進行整合。目前,Inductor 有兩個後端:(1)生成多執行緒 CPU 程式碼的 C++,(2)生成高效能 GPU 程式碼的 Triton。這些 Inductor 後端可以作為替代後端的靈感。
後端混合介面(即將推出)
我們已經構建了工具,用於將 FX 圖劃分為包含後端支援的運算元的子圖,並急切地執行剩餘部分。這些工具可以擴充套件以支援“後端混合”,配置圖形的哪些部分由哪個後端執行。然而,目前還沒有一個穩定的介面或約定供後端公開其運算元支援、對運算元模式的偏好等。這仍然是一項正在進行的工作,我們歡迎早期採用者的反饋。
總結
我們對 PyTorch 2.0 及未來的發展方向感到非常興奮。通往最終 2.0 版本的道路將充滿坎坷,但請儘早加入我們。如果您有興趣深入研究或為編譯器做出貢獻,請繼續閱讀下面的內容,其中包含有關如何開始的更多資訊(例如,教程、基準測試、模型、常見問題解答)以及本月開始的工程師問答:2.0 現場問答系列。其他資源包括:
使用 PyTorch 2.0 加速 Hugging Face 和 TIMM 模型
作者:Mark Saroufim
torch.compile() 透過一行裝飾器程式碼 torch.compile(),可以輕鬆地嘗試不同的編譯器後端來加速 PyTorch 程式碼。它可以直接作為 nn.Module 的替代品,而無需您修改任何原始碼,與 torch.jit.script() 的作用類似。我們預計這一行程式碼的更改將為您正在執行的絕大多數模型帶來 30%-2 倍的訓練時間加速。
opt_module = torch.compile(module)
torch.compile 支援任意 PyTorch 程式碼、控制流、突變,並提供對動態形狀的實驗性支援。我們對這項進展感到非常興奮,稱之為 PyTorch 2.0。
這個公告對我們來說與眾不同之處在於,我們已經對一些最流行的開源 PyTorch 模型進行了基準測試,並獲得了 30% 到 2 倍的顯著加速 https://github.com/pytorch/torchdynamo/issues/681。
這裡沒有任何技巧,我們透過 pip 安裝了像 https://github.com/huggingface/transformers、https://github.com/huggingface/accelerate 和 https://github.com/rwightman/pytorch-image-models 這樣的流行庫,然後在它們上面運行了 torch.compile(),僅此而已。
同時獲得性能和便利性是很少見的,但這就是核心團隊覺得 PyTorch 2.0 如此令人興奮的原因。
要求
適用於 GPU(新一代 GPU 的效能將顯著提高)
pip3 install numpy --pre torch --force-reinstall --index-url https://download.pytorch.org/whl/nightly/cu117
適用於 CPU
pip3 install --pre torch --index-url https://download.pytorch.org/whl/nightly/cpu
可選:驗證安裝
git clone https://github.com/pytorch/pytorch
cd tools/dynamo
python verify_dynamo.py
可選:Docker 安裝
我們還在 PyTorch 每夜版二進位制檔案中提供了所有必需的依賴項,您可以透過以下方式下載
docker pull ghcr.io/pytorch/pytorch-nightly
對於臨時實驗,只需確保您的容器可以訪問所有 GPU
docker run --gpus all -it ghcr.io/pytorch/pytorch-nightly:latest /bin/bash
入門
請閱讀 Mark Saroufim 的完整部落格文章,他將帶領您瞭解教程和真實模型,以便您今天即可試用 PyTorch 2.0。
我們 PyTorch 的目標是構建一個廣度優先的編譯器,以加速開源中絕大多數人們實際執行的模型。Hugging Face Hub 最終成為了我們極其寶貴的基準測試工具,確保我們進行的任何最佳化都能真正幫助加速人們想要執行的模型。
這篇部落格教程將準確地向您展示如何重現這些加速效果,讓您和我們一樣對 PyTorch 2.0 感到興奮。所以請嘗試使用 PyTorch 2.0,享受免費的效能提升,如果您沒有看到,請提出問題,我們將確保您的模型得到支援 https://github.com/pytorch/torchdynamo/issues。
畢竟,除非您的模型確實執行得更快,否則我們不能聲稱我們建立了廣度優先。
常見問題
-
什麼是 PT 2.0?
2.0 是最新的 PyTorch 版本。PyTorch 2.0 提供了相同的 Eager Mode 開發體驗,同時透過 torch.compile 添加了編譯模式。這種編譯模式有可能在訓練和推理期間加速您的模型。 -
為什麼是 2.0 而不是 1.14?
PyTorch 2.0 本來會是 1.14。我們釋出了我們認為會顯著改變您使用 PyTorch 方式的重大新功能,因此我們將其稱為 2.0。 -
如何安裝 2.0?有什麼額外的要求嗎?
安裝最新的 nightly 版本
CUDA 11.8
pip3 install numpy --pre torch torchvision torchaudio --force-reinstall --index-url https://download.pytorch.org/whl/nightly/cu118CUDA 11.7
pip3 install numpy --pre torch torchvision torchaudio --force-reinstall --index-url https://download.pytorch.org/whl/nightly/cu117CPU
pip3 install numpy --pre torch torchvision torchaudio --force-reinstall --index-url https://download.pytorch.org/whl/nightly/cpu -
2.0 程式碼是否與 1.X 向後相容?
是的,使用 2.0 不需要您修改 PyTorch 工作流。一行程式碼model = torch.compile(model)即可最佳化您的模型以使用 2.0 堆疊,並與您的其餘 PyTorch 程式碼順暢執行。這是完全可選的,您不需要使用新的編譯器。 -
2.0 預設啟用嗎?
2.0 是釋出的名稱。torch.compile 是 2.0 中釋出的功能,您需要明確使用 torch.compile。 - 如何將我的 PT1.X 程式碼遷移到 PT2.0?
您的程式碼應該可以按原樣工作,無需任何遷移。如果您想使用 2.0 中引入的新編譯模式功能,那麼您可以透過一行程式碼最佳化您的模型:model = torch.compile(model)。
雖然加速主要在訓練期間觀察到,但如果您的模型執行速度快於 eager 模式,您也可以將其用於推理。import torch def train(model, dataloader): model = torch.compile(model) for batch in dataloader: run_epoch(model, batch) def infer(model, input): model = torch.compile(model) return model(\*\*input) -
為什麼要使用 PT2.0 而不是 PT 1.X?
請參閱問題 (2) 的答案。 - 執行 PyTorch 2.0 時,我的程式碼有什麼不同?
開箱即用,PyTorch 2.0 與 PyTorch 1.x 相同,您的模型在 Eager Mode 下執行,即每一行 Python 程式碼按順序執行。
在 2.0 中,如果您將模型包裝在model = torch.compile(model)中,您的模型將在執行前經歷 3 個步驟:- 圖獲取:首先將模型重寫為子圖塊。可以由 TorchDynamo 編譯的子圖會被“扁平化”,而其他子圖(可能包含控制流程式碼或其他不支援的 Python 結構)將回退到 Eager 模式。
- 圖降低:所有 PyTorch 操作都被分解為特定於所選後端的組成核心。
- 圖編譯,其中核心呼叫其相應的低階裝置特定操作。
- PT2.0 為 PT 增加了哪些新元件?
-
2.0 目前支援哪些編譯器後端?
預設且最完整的後端是 TorchInductor,但 TorchDynamo 擁有不斷增長的後端列表,可以透過呼叫torchdynamo.list_backends()找到。 -
2.0 如何進行分散式訓練?
編譯模式下的 DDP 和 FSDP 在 FP32 中可以比 Eager 模式快 15%,在 AMP 精度下可以快 80%。PT2.0 進行了一些額外的最佳化,以確保 DDP 的通訊-計算重疊與 Dynamo 的部分圖建立良好配合。請確保您執行 DDP 時設定 static_graph=False。更多詳情請參閱此處。 -
我如何瞭解更多關於 PT2.0 的發展?
PyTorch 開發者論壇是直接向構建 2.0 元件的開發者瞭解 2.0 元件的最佳場所。 -
我的程式碼在 2.0 的編譯模式下執行得更慢了!
效能下降最可能的原因是圖中斷過多。例如,模型前向傳播中的一個無害的 print 語句就會觸發圖中斷。我們有診斷這些問題的方法——更多資訊請參閱此處。 - 我之前執行的程式碼在 2.0 編譯模式下崩潰了!如何除錯?
以下是一些用於分類您的程式碼可能出現故障的位置並列印有用日誌的技術:https://pytorch.com.tw/docs/stable/torch.compiler_faq.html#why-is-my-code-crashing。
工程師問答:2.0 現場問答系列
我們將舉辦一系列現場問答環節,供社群與專家進行更深入的問題探討和交流。請回來檢視全年主題的完整日曆。如果您無法參加:1) 它們將被錄製以供將來觀看,2) 您可以參加我們每週五太平洋標準時間上午 10 點的開發基礎設施辦公時間 @ https://github.com/pytorch/pytorch/wiki/Dev-Infra-Office-Hours。
請點選這裡檢視日期、時間、描述和連結。
免責宣告:在加入現場會議和提交問題時,請勿分享您的個人資訊、姓氏和公司。
| 主題 | 主持人 |
| 使用 2.0 的全新開發者體驗(安裝、設定、克隆示例、使用 2.0 執行) | Suraj Subramanian 領英 | 推特 |
| PT2 效能分析和除錯 | Bert Maher 領英 | 推特 |
| 深度解析 TorchInductor 和 PT 2.0 後端整合 | Natalia Gimelshein、Bin Bao 和 Sherlock Huang Natalia Gimelshein 領英 Sherlock Huang 領英 |
| 無需 C++ 和 functorch 即可擴充套件 PyTorch:JAX 風格的可組合函式轉換用於 PyTorch | Anjali Chourdia 和 Samantha Andow Anjali Chourdia 領英 | 推特 Samantha Andow 領英 | 推特 |
| 深度解析 TorchDynamo | Michael Voznesensky 領英 |
| 使用 TorchData 重新思考資料載入:Datapipes 和 Dataloader2 | Kevin Tse 領英 |
| 可組合訓練(+ torcheval、torchsnapshot) | Ananth Subramaniam |
| 如何以及為何向 PyTorch 貢獻程式碼和教程 | Zain Rizvi、Svetlana Karslioglu 和 Carl Parker Zain Rizvi 領英 | 推特 Svetlana Karslioglu 領英 | 推特 |
| 動態形狀與計算最大批次大小 | Edward Yang 和 Elias Ellison Edward Yang 推特 |
| PyTorch 2.0 匯出:PyTorch 的健全全圖捕獲 | Michael Suo 和 Yanan Cao Yanan Cao 領英 |
| 使用 DistributedTensor 和 PyTorch DistributedTensor 進行二維並行 | Wanchao Liang 和 Alisson Gusatti Azzolini Wanchao Liang 領英 | 推特 Alisson Gusatti Azzolini 領英 |
| TorchRec 和 FSDP 在生產環境中的應用 | Dennis van der Staay、Andrew Gu 和 Rohan Varma Dennis van der Staay 領英 Rohan Varma 領英 | 推特 |
| PyTorch 在裝置上的未來 | Raziel Alvarez Guevara 領英 | 推特 |
| TorchMultiModal 介紹部落格 擴充套件部落格 |
Kartikay Khandelwal 領英 | 推特 |
| 更優的 Transformer(+與 Hugging Face 整合)、模型服務和最佳化 部落格 1 GitHub |
Hamid Shojanazeri 和 Mark Saroufim Mark Saroufim 領英 | 推特 |
| PT2 與分散式 | Will Constable 領英 |