ResNext WSL
import torch
model = torch.hub.load('facebookresearch/WSL-Images', 'resnext101_32x8d_wsl')
# or
# model = torch.hub.load('facebookresearch/WSL-Images', 'resnext101_32x16d_wsl')
# or
# model = torch.hub.load('facebookresearch/WSL-Images', 'resnext101_32x32d_wsl')
# or
#model = torch.hub.load('facebookresearch/WSL-Images', 'resnext101_32x48d_wsl')
model.eval()
所有預訓練模型都要求輸入影像以相同的方式進行歸一化,即由形狀為 (3 x H x W) 的 3 通道 RGB 影像組成的小批次資料,其中 H 和 W 預計至少為 224。影像必須載入到 [0, 1] 範圍內,然後使用 mean = [0.485, 0.456, 0.406] 和 std = [0.229, 0.224, 0.225] 進行歸一化。
這是一個示例執行。
# Download an example image from the pytorch website
import urllib
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
try: urllib.URLopener().retrieve(url, filename)
except: urllib.request.urlretrieve(url, filename)
# sample execution (requires torchvision)
from PIL import Image
from torchvision import transforms
input_image = Image.open(filename)
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model
# move the input and model to GPU for speed if available
if torch.cuda.is_available():
input_batch = input_batch.to('cuda')
model.to('cuda')
with torch.no_grad():
output = model(input_batch)
# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes
print(output[0])
# The output has unnormalized scores. To get probabilities, you can run a softmax on it.
print(torch.nn.functional.softmax(output[0], dim=0))
模型描述
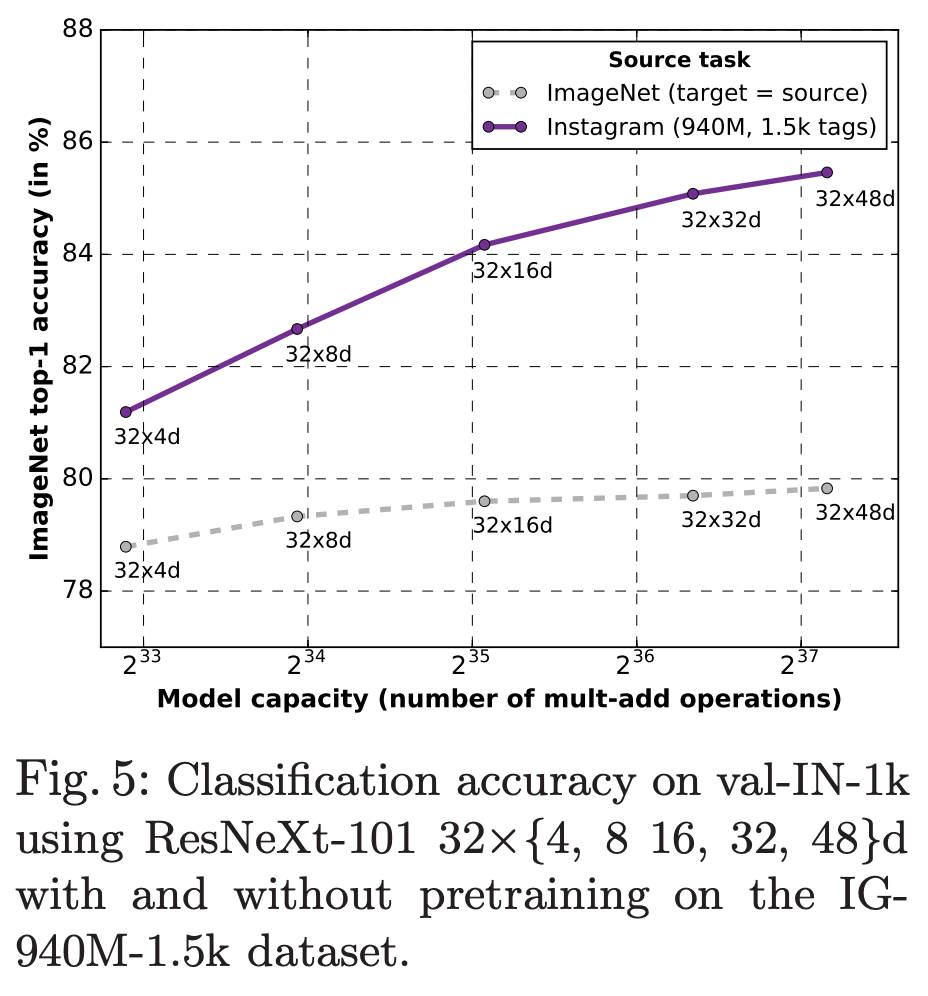
所提供的 ResNeXt 模型以弱監督方式在**9.4 億**張公共圖片上進行了預訓練,這些圖片具有 1.5K 標籤,與 1000 個 ImageNet1K 同義詞相匹配,隨後在 ImageNet1K 資料集上進行了微調。有關模型訓練的詳細資訊,請參閱 ECCV 2018 上發表的“探索弱監督預訓練的極限”(https://arxiv.org/abs/1805.00932)。
我們提供 4 種不同容量的模型。
| 模型 | #引數 | 浮點運算次數 (FLOPS) | Top-1 準確率 | Top-5 準確率 |
|---|---|---|---|---|
| ResNeXt-101 32x8d | 88M | 16B | 82.2 | 96.4 |
| ResNeXt-101 32x16d | 193M | 36B | 84.2 | 97.2 |
| ResNeXt-101 32x32d | 466M | 87B | 85.1 | 97.5 |
| ResNeXt-101 32x48d | 829M | 153B | 85.4 | 97.6 |
與從頭開始訓練相比,我們的模型顯著提高了 ImageNet 上的訓練準確性。**我們使用 ResNext-101 32x48d 模型在 ImageNet 上達到了 85.4% 的最先進準確性。**
參考文獻
