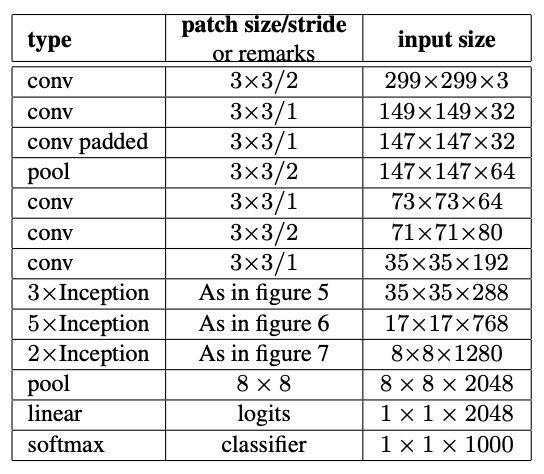
Inception_v3
import torch
model = torch.hub.load('pytorch/vision:v0.10.0', 'inception_v3', pretrained=True)
model.eval()
所有預訓練模型都要求輸入影像以相同的方式進行歸一化,即由形狀為 (3 x H x W) 的 3 通道 RGB 影像組成的小批次,其中 H 和 W 預計至少為 299。影像必須載入到 [0, 1] 的範圍,然後使用 mean = [0.485, 0.456, 0.406] 和 std = [0.229, 0.224, 0.225] 進行歸一化。
這是一個示例執行。
# Download an example image from the pytorch website
import urllib
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
try: urllib.URLopener().retrieve(url, filename)
except: urllib.request.urlretrieve(url, filename)
# sample execution (requires torchvision)
from PIL import Image
from torchvision import transforms
input_image = Image.open(filename)
preprocess = transforms.Compose([
transforms.Resize(299),
transforms.CenterCrop(299),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model
# move the input and model to GPU for speed if available
if torch.cuda.is_available():
input_batch = input_batch.to('cuda')
model.to('cuda')
with torch.no_grad():
output = model(input_batch)
# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes
print(output[0])
# The output has unnormalized scores. To get probabilities, you can run a softmax on it.
probabilities = torch.nn.functional.softmax(output[0], dim=0)
print(probabilities)
# Download ImageNet labels
!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt
# Read the categories
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Show top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
模型描述
Inception v3:基於對網路擴充套件方式的探索,旨在透過適當分解的卷積和積極的正則化儘可能高效地利用增加的計算。我們在 ILSVRC 2012 分類挑戰驗證集上對我們的方法進行了基準測試,結果表明,相對於最先進的技術取得了顯著的進步:對於單幀評估,使用每次推理計算成本為 50 億次乘加,引數少於 2500 萬的網路,實現了 21.2% 的 top-1 錯誤和 5.6% 的 top-5 錯誤。透過 4 個模型的整合和多裁剪評估,我們在驗證集上報告了 3.5% 的 top-5 錯誤(測試集上為 3.6% 的錯誤),在驗證集上報告了 17.3% 的 top-1 錯誤。
下面列出了使用預訓練模型在 ImageNet 資料集上的 1-裁剪錯誤率。
| 模型結構 | Top-1 錯誤率 | Top-5 錯誤率 |
|---|---|---|
| inception_v3 | 22.55 | 6.44 |
參考文獻
