Silero 語音轉文字模型

# this assumes that you have a proper version of PyTorch already installed
pip install -q torchaudio omegaconf soundfile
import torch
import zipfile
import torchaudio
from glob import glob
device = torch.device('cpu') # gpu also works, but our models are fast enough for CPU
model, decoder, utils = torch.hub.load(repo_or_dir='snakers4/silero-models',
model='silero_stt',
language='en', # also available 'de', 'es'
device=device)
(read_batch, split_into_batches,
read_audio, prepare_model_input) = utils # see function signature for details
# download a single file, any format compatible with TorchAudio (soundfile backend)
torch.hub.download_url_to_file('https://opus-codec.org/static/examples/samples/speech_orig.wav',
dst ='speech_orig.wav', progress=True)
test_files = glob('speech_orig.wav')
batches = split_into_batches(test_files, batch_size=10)
input = prepare_model_input(read_batch(batches[0]),
device=device)
output = model(input)
for example in output:
print(decoder(example.cpu()))
模型描述
Silero 語音轉文字模型以緊湊的形式為幾種常用語言提供企業級語音轉文字功能。與傳統的 ASR 模型不同,我們的模型對各種方言、編解碼器、領域、噪聲和較低取樣率(為簡單起見,音訊應重新取樣到 16 kHz)具有魯棒性。模型接收歸一化後的音訊樣本(即,除了歸一化到 -1…1 之外,不進行任何預處理),並輸出帶有令牌機率的幀。為了簡單起見,我們提供了一個解碼器實用程式(我們可以將其包含在模型本身中,但在某些匯出場景中,指令碼模組在儲存模型工件(即標籤)時存在問題)。
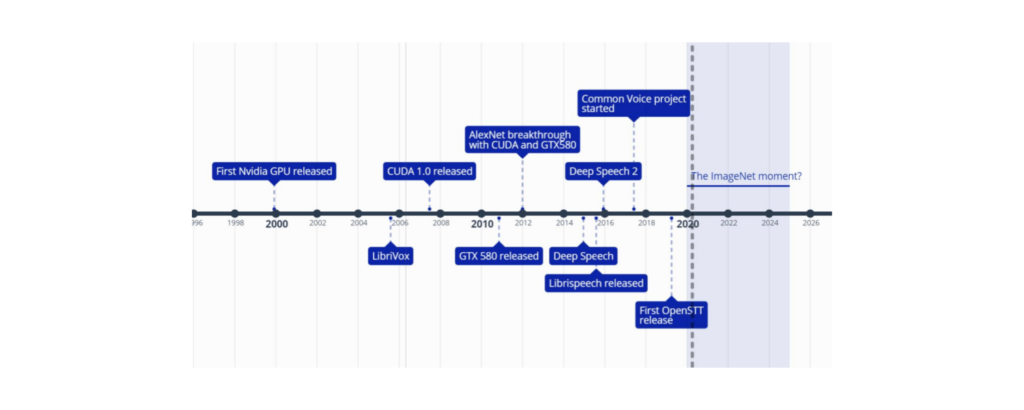
我們希望我們為 Open-STT 和 Silero 模型所做的努力能讓語音領域的 ImageNet 時刻更早到來。
支援的語言和格式
截至本頁面更新,支援以下語言:
- 英語
- 德語
- 西班牙語
要檢視始終保持最新的語言列表,請訪問我們的儲存庫,並檢視yml檔案以瞭解所有可用的檢查點。
其他示例和基準
有關其他示例和其他模型格式,請訪問此連結。有關質量和效能基準,請參閱維基。這些資源將不時更新。