常見問題¶
torch.compile 是否支援訓練?¶
torch.compile 支援訓練,使用 AOTAutograd 來擷取向後
TorchDynamo 的 Python
evalframe前端會擷取.forward()圖形和optimizer.step()。對於 torchdynamo 擷取的
.forward()的每個區段,它都會使用 AOTAutograd 來產生向後圖形區段。每個正向和反向圖形對(可選)都會進行最小切割分割,以在正向和反向之間儲存最小狀態。
正向和反向對會包裝在
autograd.function模組中。呼叫
.backward()的使用者程式碼仍然會觸發 eager 的 autograd 引擎,該引擎會執行每個*已編譯的向後*圖形,就好像它是一個運算一樣,也會執行任何未編譯的 eager 運算的.backward()函式。
你們是否支援分散式程式碼?¶
torch.compile 支援 DistributedDataParallel (DDP)。我們正在考慮支援其他分散式訓練函式庫。
使用 dynamo 時,分散式程式碼具有挑戰性的主要原因是 AOTAutograd 會展開正向和反向傳遞,並為後端提供 2 個圖形以進行最佳化。這對於分散式程式碼來說是一個問題,因為我們希望理想情況下將通訊操作與計算重疊。Eager pytorch 以不同的方式為 DDP/FSDP 實現了這一點 - 使用 autograd 鉤子、模組鉤子以及模組狀態的修改/變更。在 dynamo 的單純應用中,由於 AOTAutograd 編譯函式與調度程式鉤子的互動方式,應該在向後操作期間直接在操作之後執行的鉤子可能會延遲到向後操作的整個編譯區域之後。
在 distributed.py 中概述了使用 Dynamo 最佳化 DDP 的基本策略,其中主要想法是在 DDP 儲存區邊界 上進行圖形斷裂。
當 DDP 中的每個節點需要與其他節點同步其權重時,它會將其梯度和參數組織到儲存區中,這減少了通訊時間,並允許節點將其一部分梯度廣播到其他等待節點。
分散式程式碼中的圖形斷裂意味著您可以預期 dynamo 及其後端可以最佳化分散式程式的計算開銷,但不能最佳化其通訊開銷。如果減少的圖形大小剝奪了編譯器融合的機會,則圖形斷裂可能會干擾編譯速度。但是,隨著圖形大小的增加,回報會遞減,因為目前大多數計算最佳化都是局部融合。因此,在實務上,這種方法可能就足夠了。
我是否仍然需要匯出整個圖形?¶
對於絕大多數模型來說,您可能不需要,您可以按原樣使用 torch.compile(),但在某些情況下,需要完整的圖形,您可以透過執行 torch.compile(..., fullgraph=True) 來確保完整的圖形。這些情況包括
需要管道平行和其他進階分片策略的大規模訓練執行,例如 $250K+。
依賴比訓練最佳化器更積極地進行融合的推論最佳化器,例如 TensorRT 或 AITemplate。
行動訓練或推論。
未來的方向包括將通訊操作追蹤到圖形中,協調這些操作與計算最佳化,以及最佳化通訊操作。
為什麼我的程式碼會當機?¶
如果您的程式碼在沒有 torch.compile 的情況下執行良好,但在啟用它後開始當機,則最重要的第一步是找出失敗發生在堆疊的哪個部分。若要排除故障,請遵循以下步驟,並且僅在前一步驟成功時才嘗試下一步。
torch.compile(..., backend="eager"),它只會執行 TorchDynamo 正向圖形擷取,然後使用 PyTorch 執行擷取的圖形。如果這一步失敗,則表示 TorchDynamo 出現問題。torch.compile(..., backend="aot_eager"),它會執行 TorchDynamo 來擷取正向圖形,然後執行 AOTAutograd 來追蹤反向圖形,而無需任何額外的後端編譯器步驟。然後,PyTorch eager 將用於執行正向和反向圖形。如果這一步失敗,則表示 AOTAutograd 出現問題。torch.compile(..., backend="inductor")會執行 TorchDynamo 來擷取正向圖,然後執行 AOTAutograd 以使用 TorchInductor 編譯器追蹤反向圖。如果失敗,則表示 TorchInductor 出現問題。
為什麼編譯速度很慢?¶
Dynamo 編譯– TorchDynamo 有一個內建的統計函數,用於收集和顯示每個編譯階段花費的時間。這些統計數據可以在執行
torch._dynamo後呼叫torch._dynamo.utils.compile_times()來存取。預設情況下,這會傳回一個字串,表示每個 TorchDynamo 函數按名稱花費的編譯時間。Inductor 編譯– TorchInductor 有一個內建的統計和追蹤函數,用於顯示每個編譯階段花費的時間、輸出代碼、輸出圖形可視化和 IR 轉儲。
env TORCH_COMPILE_DEBUG=1 python repro.py。這是一個除錯工具,旨在讓使用看起來像 這樣 的輸出更容易除錯/理解 TorchInductor 的內部。該除錯追蹤中的每個檔案都可以透過torch._inductor.config.trace.*啟用/停用。設定檔和圖表預設都是停用的,因為它們的產生成本很高。有關更多示例,請參閱 示例除錯目錄輸出。過度重新編譯 當 TorchDynamo 編譯函數(或其中的一部分)時,它會對區域變數和全域變數做出某些假設,以便進行編譯器最佳化,並將這些假設表示為在執行時檢查特定值的防護。如果任何這些防護失敗,Dynamo 將重新編譯該函數(或部分)最多
torch._dynamo.config.cache_size_limit次。如果您的程式達到了快取限制,您首先需要確定是哪個防護失敗以及程式的哪個部分觸發了它。 重新編譯分析器 會自動執行將 TorchDynamo 的快取限制設定為 1 並在僅觀察的「編譯器」下執行程式的過程,該「編譯器」會記錄任何防護失敗的原因。您應該確保執行程式的時間(迭代次數)至少與遇到問題時執行的時間一樣長,分析器會在這段時間內累積統計數據。
from torch._dynamo.utils import CompileProfiler
def my_model():
...
with CompileProfiler() as prof:
profiler_model = torch.compile(my_model, backend=prof)
profiler_model()
print(prof.report())
為什麼要在生產環境中重新編譯?¶
在某些情況下,您可能不希望程式預熱後出現意外的編譯。例如,如果您在延遲關鍵應用程式中提供生產流量。為此,TorchDynamo 提供了一種替代模式,其中會使用先前編譯的圖表,但不會產生新的圖表。
frozen_toy_example = dynamo.run(toy_example)
frozen_toy_example(torch.randn(10), torch.randn(10))
您是如何加快我的代碼速度的?¶
有三種主要方法可以加速 PyTorch 代碼。
透過垂直融合進行核心融合,將連續操作融合在一起,以避免過多的讀/寫。例如,融合 2 個後續的餘弦表示您可以進行 1 次讀取 1 次寫入,而不是 2 次讀取 2 次寫入。水平融合:最簡單的例子是批次處理,其中一個矩陣與一批示例相乘,但更普遍的情況是分組 GEMM,其中一組矩陣乘法被安排在一起。
亂序執行:編譯器的一般最佳化,透過預先查看圖表中確切的數據依賴關係,我們可以決定執行節點的最佳時機以及哪些緩衝區可以重複使用。
自動工作放置:類似於亂序執行點,但透過將圖表的節點與物理硬體或記憶體等資源相匹配,我們可以設計適當的時間表。
以上是加速 PyTorch 代碼的一般原則,但不同的後端在最佳化方面會有不同的取捨。例如,Inductor 首先會盡可能地進行融合,然後才會產生 Triton 核心。
Triton 還提供了加速功能,因為它可以在每個串流多處理器中自動進行記憶體合併、記憶體管理和排程,並且設計用於處理分塊計算。
但是,無論您使用哪種後端,最好都使用基準測試和查看方法,因此請嘗試使用 PyTorch 分析器,直觀地檢查生成的內核,並嘗試親自查看發生了什麼。
為什麼我沒有看到加速?¶
圖形斷裂¶
使用 Dynamo 看不到您想要的加速的主要原因是過多的圖形斷裂。那麼什麼是圖形斷裂呢?
給定一個像這樣的程式:
def some_fun(x):
...
torch.compile(some_fun)(x)
...
Torchdynamo 將嘗試將 some_fun() 中的所有 torch/tensor 操作編譯成單個 FX 圖形,但它可能無法將所有內容都擷取到一個圖形中。
某些圖形斷裂的原因是 TorchDynamo 無法克服的,例如呼叫 PyTorch 以外的 C 擴展對 TorchDynamo 是不可見的,並且可以在 TorchDynamo 無法引入必要的防護以確保編譯的程式可以安全重複使用的情況下執行任意操作。
為了最大程度地提高效能,圖形斷裂越少越好。
找出圖形斷裂的原因¶
要識別程式中的所有圖形斷裂以及斷裂的相關原因,可以使用 torch._dynamo.explain。此工具在提供的函數上執行 TorchDynamo,並匯總遇到的圖形斷裂。以下是一個使用示例:
import torch
import torch._dynamo as dynamo
def toy_example(a, b):
x = a / (torch.abs(a) + 1)
print("woo")
if b.sum() < 0:
b = b * -1
return x * b
explanation = dynamo.explain(toy_example)(torch.randn(10), torch.randn(10))
print(explanation)
"""
Graph Count: 3
Graph Break Count: 2
Op Count: 5
Break Reasons:
Break Reason 1:
Reason: builtin: print [<class 'torch._dynamo.variables.constant.ConstantVariable'>] False
User Stack:
<FrameSummary file foo.py, line 5 in toy_example>
Break Reason 2:
Reason: generic_jump TensorVariable()
User Stack:
<FrameSummary file foo.py, line 6 in torch_dynamo_resume_in_toy_example_at_5>
Ops per Graph:
...
Out Guards:
...
"""
要在遇到第一個圖形斷裂時拋出錯誤,您可以使用 fullgraph=True 禁用 Python 回退,如果您使用過基於匯出的編譯器,這應該很熟悉。
def toy_example(a, b):
...
torch.compile(toy_example, fullgraph=True, backend=<compiler>)(a, b)
為什麼我更改代碼後沒有重新編譯?¶
如果您透過設定 env TORCHDYNAMO_DYNAMIC_SHAPES=1 python model.py 啟用了動態形狀,則您的代碼不會在形狀更改時重新編譯。我們添加了對動態形狀的支援,這避免了在形狀變化小於 2 倍的情況下重新編譯。這在諸如 CV 中的不同圖像大小或 NLP 中的可變序列長度等情況下特別有用。在推理場景中,通常無法事先知道批次大小是多少,因為您需要從不同的客戶端應用程式中獲取可以獲取的內容。
一般來說,TorchDynamo 會盡可能避免不必要地重新編譯,因此,例如,如果 TorchDynamo 找到 3 個圖形,而您的更改只修改了一個圖形,則只會重新編譯該圖形。因此,避免潛在的長時間編譯的另一個技巧是在模型第一次編譯後對其進行預熱,之後的編譯速度會快得多。冷啟動編譯時間仍然是我們可見地追蹤的一個指標。
為什麼我會得到錯誤的結果?¶
如果您設定環境變數 TORCHDYNAMO_REPRO_LEVEL=4,也可以將準確性問題最小化,它的運作方式類似於 git 二分模型,完整的重現可能類似於 TORCHDYNAMO_REPRO_AFTER="aot" TORCHDYNAMO_REPRO_LEVEL=4,我們需要這樣做的原因是,無論是 Triton 代碼還是 C++ 後端,下游編譯器都會生成代碼,這些下游編譯器的數值可能會以微妙的方式有所不同,但會對您的訓練穩定性產生巨大影響。因此,準確性除錯器對於我們檢測代碼生成或後端編譯器中的錯誤非常有用。
如果您希望確保 torch 和 triton 之間的隨機數生成相同,則可以啟用 torch._inductor.config.fallback_random = True。
為什麼我會遇到 OOM?¶
Dynamo 仍處於 alpha 測試階段,因此存在一些 OOM 的來源,如果您遇到了 OOM,請嘗試按順序停用以下配置,然後在 GitHub 上提交 issue,以便我們解決根本問題 1. 如果您使用的是動態形狀,請嘗試停用它們,我們預設停用了它們:env TORCHDYNAMO_DYNAMIC_SHAPES=0 python model.py 2. Inductor 中預設啟用了帶有 Triton 的 CUDA 圖形,但移除它們可能會緩解一些 OOM 問題:torch._inductor.config.triton.cudagraphs = False。
torch.func 是否適用於 torch.compile(用於 grad 和 vmap 轉換)?¶
將 torch.func 轉換應用於使用 torch.compile 的函數確實有效。
import torch
@torch.compile
def f(x):
return torch.sin(x)
def g(x):
return torch.grad(f)(x)
x = torch.randn(2, 3)
g(x)
在使用 torch.compile 處理的函數內呼叫 torch.func 轉換¶
使用 torch.compile 編譯 torch.func.grad¶
import torch
def wrapper_fn(x):
return torch.func.grad(lambda x: x.sin().sum())(x)
x = torch.randn(3, 3, 3)
grad_x = torch.compile(wrapper_fn)(x)
使用 torch.compile 編譯 torch.vmap¶
import torch
def my_fn(x):
return torch.vmap(lambda x: x.sum(1))(x)
x = torch.randn(3, 3, 3)
output = torch.compile(my_fn)(x)
編譯支援的函數以外的函數(逃生出口)¶
對於其他轉換,作為一種解決方法,請使用 torch._dynamo.allow_in_graph。
allow_in_graph 是一個逃生出口。如果您的代碼不適用於 torch.compile(它會檢查 Python 位元組碼),但您相信它可以透過符號追蹤方法(如 jax.jit)運作,則請使用 allow_in_graph。
透過使用 allow_in_graph 註釋函數,您必須確保您的代碼滿足以下要求:
函數中的所有輸出都只依賴於輸入,而不依賴於任何擷取的張量。
您的函數是函數式的。也就是說,它不會改變任何狀態。這一點可能會放寬;我們實際上支援從外部看起來是函數式的函數:它們可能具有就地 PyTorch 操作,但可能不會改變函數的全局狀態或輸入。
您的函數不會引發與數據相關的錯誤。
import torch
@torch.compile
def f(x):
return torch._dynamo.allow_in_graph(torch.vmap(torch.sum))(x)
x = torch.randn(2, 3)
f(x)
一個常見的陷阱是使用 allow_in_graph 來註釋調用 nn.Module 的函數。這是因為輸出現在取決於 nn.Module 的參數。若要使其正常運作,請使用 torch.func.functional_call 來提取模組狀態。
NumPy 是否適用於 torch.compile?¶
從 2.1 版開始,torch.compile 可以理解處理 NumPy 陣列的原生 NumPy 程式,以及透過 x.numpy()、torch.from_numpy 和相關函數在 PyTorch 和 NumPy 之間轉換的混合 PyTorch-NumPy 程式。
torch.compile 支援哪些 NumPy 功能?¶
torch.compile 中的 NumPy 遵循 NumPy 2.0 預覽版。
一般來說,torch.compile 能夠追蹤大多數 NumPy 構造,當它無法追蹤時,它會退回到 Eager 模式,並讓 NumPy 執行該程式碼片段。即使如此,torch.compile 的語義在某些功能上仍與 NumPy 略有不同
NumPy 純量:我們將它們建模為 0 維陣列。也就是說,
np.float32(3)在torch.compile下會返回一個 0 維陣列。為了避免圖形斷裂,最好使用這個 0 維陣列。如果這會破壞您的程式碼,您可以透過將 NumPy 純量轉換為相關的 Python 純量類型bool/int/float來解決此問題。負跨距:
np.flip和使用負步長進行切片會返回一個副本。類型提升:NumPy 的類型提升將在 NumPy 2.0 中發生變化。新規則在 NEP 50 中有說明。
torch.compile實作的是 NEP 50,而不是目前即將棄用的規則。{tril,triu}_indices_from/{tril,triu}_indices返回陣列,而不是陣列的元組。
還有一些功能我們不支援追蹤,我們會優雅地退回到 NumPy 來執行它們
非數值 dtype,例如日期時間、字串、字元、void、結構化 dtype 和 recarrays。
長 dtype
np.float128/np.complex256和一些無符號 dtypenp.uint16/np.uint32/np.uint64。ndarray子類別。遮罩陣列。
深奧的 ufunc 機制,例如
axes=[(n,k),(k,m)->(n,m)]和 ufunc 方法(例如,np.add.reduce)。對
complex64/complex128陣列進行排序/排序。NumPy
np.poly1d和np.polynomial。具有 2 個或更多返回值的函數中的位置
out1, out2參數(out=tuple可以運作)。__array_function__、__array_interface__和__array_wrap__。ndarray.ctypes屬性。
我可以使用 torch.compile 編譯 NumPy 程式碼嗎?¶
當然可以!torch.compile 原生理解 NumPy 程式碼,並將其視為 PyTorch 程式碼。為此,只需使用 torch.compile 裝飾器包裝 NumPy 程式碼即可。
import torch
import numpy as np
@torch.compile
def numpy_fn(X: np.ndarray, Y: np.ndarray) -> np.ndarray:
return np.sum(X[:, :, None] * Y[:, None, :], axis=(-2, -1))
X = np.random.randn(1024, 64)
Y = np.random.randn(1024, 64)
Z = numpy_fn(X, Y)
assert isinstance(Z, np.ndarray)
使用環境變數 TORCH_LOGS=output_code 執行此範例,我們可以看到 torch.compile 能夠將乘法和求和融合到一個 C++ 核心。它還能夠使用 OpenMP 並行執行它們(原生 NumPy 是單執行緒的)。這可以輕鬆地讓您的 NumPy 程式碼速度提升 n 倍,其中 n 是您處理器中的核心數!
以這種方式追蹤 NumPy 程式碼也支援在已編譯的程式碼中斷開圖形。
我可以透過 torch.compile 在 CUDA 上執行 NumPy 程式碼並計算梯度嗎?¶
是的,您可以!為此,您可以在 torch.device("cuda") 上下文中執行您的程式碼。請參考以下範例
import torch
import numpy as np
@torch.compile
def numpy_fn(X: np.ndarray, Y: np.ndarray) -> np.ndarray:
return np.sum(X[:, :, None] * Y[:, None, :], axis=(-2, -1))
X = np.random.randn(1024, 64)
Y = np.random.randn(1024, 64)
with torch.device("cuda"):
Z = numpy_fn(X, Y)
assert isinstance(Z, np.ndarray)
在此範例中,numpy_fn 將在 CUDA 中執行。為此,torch.compile 會自動將 X 和 Y 從 CPU 移動到 CUDA,然後將結果 Z 從 CUDA 移動到 CPU。如果我們在同一個程式執行的過程中多次執行此函數,我們可能會希望避免所有這些相當耗費資源的記憶體複製操作。為此,我們只需要調整我們的 numpy_fn,使其接受 cuda 張量並返回張量即可。我們可以使用 torch.compiler.wrap_numpy 來做到這一點
@torch.compile(fullgraph=True)
@torch.compiler.wrap_numpy
def numpy_fn(X, Y):
return np.sum(X[:, :, None] * Y[:, None, :], axis=(-2, -1))
X = torch.randn(1024, 64, device="cuda")
Y = torch.randn(1024, 64, device="cuda")
Z = numpy_fn(X, Y)
assert isinstance(Z, torch.Tensor)
assert Z.device.type == "cuda"
在這裡,我們在 CUDA 記憶體中顯式建立張量,並將它們傳遞給函數,該函數在 CUDA 裝置上執行所有計算。wrap_numpy 負責在 torch.compile 級別將任何 torch.Tensor 輸入標記為具有 np.ndarray 語義的輸入。在編譯器內部標記張量是一個非常廉價的操作,因此在執行期間不會發生數據複製或數據移動。
使用此裝飾器,我們還可以透過 NumPy 程式碼進行微分!
@torch.compile(fullgraph=True)
@torch.compiler.wrap_numpy
def numpy_fn(X, Y):
return np.mean(np.sum(X[:, :, None] * Y[:, None, :], axis=(-2, -1)))
X = torch.randn(1024, 64, device="cuda", requires_grad=True)
Y = torch.randn(1024, 64, device="cuda")
Z = numpy_fn(X, Y)
assert isinstance(Z, torch.Tensor)
Z.backward()
# X.grad now holds the gradient of the computation
print(X.grad)
我們一直使用 fullgraph=True,因為圖形斷裂在此上下文中會產生問題。當圖形斷裂發生時,我們需要具體化 NumPy 陣列。由於 NumPy 陣列沒有 device 或 requires_grad 的概念,因此在圖形斷裂期間會遺失這些資訊。
我們無法透過圖形斷裂傳播梯度,因為圖形斷裂程式碼可能會執行不知道如何微分的任意程式碼。另一方面,在 CUDA 執行的案例中,我們可以像在第一個範例中那樣,使用 torch.device("cuda") 上下文管理器來解決這個問題
@torch.compile
@torch.compiler.wrap_numpy
def numpy_fn(X, Y):
prod = X[:, :, None] * Y[:, None, :]
print("oops, a graph break!")
return np.sum(prod, axis=(-2, -1))
X = torch.randn(1024, 64, device="cuda")
Y = torch.randn(1024, 64, device="cuda")
with torch.device("cuda"):
Z = numpy_fn(X, Y)
assert isinstance(Z, torch.Tensor)
assert Z.device.type == "cuda"
在圖形斷裂期間,中介張量仍然需要移動到 CPU,但是當在圖形斷裂之後恢復追蹤時,圖形的其餘部分仍然在 CUDA 上追蹤。考慮到這種 CUDA <> CPU 和 CPU <> CUDA 移動,圖形斷裂在 NumPy 上下文中相當昂貴,應該避免,但至少它們允許追蹤複雜的程式碼片段。
如何在 torch.compile 下偵錯 NumPy 程式碼?¶
考慮到現代編譯器的複雜性和它們引發的令人生畏的錯誤,偵錯 JIT 編譯的程式碼具有挑戰性。關於如何診斷 torch.compile 中的執行時錯誤的教學 包含一些關於如何處理此任務的技巧和竅門。
如果上述方法不足以查明問題的根源,我們還可以使用一些 NumPy 特定的工具。我們可以透過停用對 NumPy 函數的追蹤來辨別錯誤是否完全出現在 PyTorch 程式碼中
from torch._dynamo import config
config.trace_numpy = False
如果錯誤存在於已追蹤的 NumPy 程式碼中,我們可以透過匯入 import torch._numpy as np,使用 PyTorch 作為後端,以 Eager 模式(不使用 torch.compile)執行 NumPy 程式碼。這應該僅用於**偵錯目的**,絕不能替代 PyTorch API,因為它的**效能要差得多**,而且作為私有 API,**可能會在沒有任何通知的情況下發生變化**。無論如何,torch._numpy 是 NumPy 的 Python 實作,基於 PyTorch,並且 torch.compile 在內部使用它將 NumPy 程式碼轉換為 Pytorch 程式碼。它相當易於閱讀和修改,因此如果您在其中發現任何錯誤,請隨時提交 PR 來修復它,或者乾脆提出 issue。
如果程式在匯入 torch._numpy as np 時可以正常運作,則錯誤很可能出在 TorchDynamo。如果是這種情況,請隨時提出 issue 並附上 最小可重現範例。
我使用 torch.compile 編譯了一些 NumPy 程式碼,但我沒有看到任何速度提升。¶
最好的起點是 關於如何偵錯這類 torch.compile 問題的一般建議教學。
某些圖形斷裂可能是由於使用了不受支援的功能而發生的。請參閱 torch.compile 支援哪些 NumPy 功能?。更一般地說,請務必牢記,一些廣泛使用的 NumPy 功能與編譯器的配合度不高。例如,就地修改會使編譯器內的推理變得困難,並且通常會導致比其非就地修改 counterparts 更差的效能。因此,最好避免使用它們。使用 out= 參數也是如此。相反,最好使用非就地操作,並讓 torch.compile 優化記憶體使用。與數據相關的操作(例如透過布林遮罩進行遮罩索引)或與數據相關的控制流程(例如 if 或 while 構造)也是如此。
應該使用哪個 API 進行細粒度追蹤?¶
在某些情況下,您可能需要從 torch.compile 編譯中排除一小部分程式碼。本節提供了一些答案,您可以在 TorchDynamo 細粒度追蹤 API 中找到更多資訊。
如何在函數上斷開圖形?¶
在函數上斷開圖形不足以充分表達您希望 PyTorch 做什麼。您需要更具體地說明您的使用案例。您可能要考慮的一些最常見的使用案例
如果您想在此函數框架和遞迴呼叫的框架上停用編譯,請使用
torch._dynamo.disable。如果您希望特定運算子(例如
fbgemm)使用 eager 模式,請使用torch._dynamo.disallow_in_graph。
一些不常見的使用案例包括:
如果您想在函數框架上停用 TorchDynamo,但在遞迴呼叫的框架上重新啟用它,請使用
torch._dynamo.disable(recursive=False)。如果您想防止函數框架被內聯,請在您想防止內聯的函數開頭使用
torch._dynamo.graph_break。
torch._dynamo.disable 和 torch._dynamo.disallow_in_graph 之間有什麼區別?¶
Disallow-in-graph 在運算子級別起作用,或者更具體地說,在您在 TorchDynamo 提取的圖表中看到的運算子級別起作用。
Disable 在函數框架級別起作用,並決定 TorchDynamo 是否應該查看函數框架。
torch._dynamo.disable 和 torch._dynamo_skip 之間有什麼區別?¶
備註
torch._dynamo_skip 已被棄用。
您很可能需要 torch._dynamo.disable。但在不太可能的情況下,您可能需要更精確的控制。假設您只想在 a_fn 函數上停用追蹤,但想在 aa_fn 和 ab_fn 中繼續追蹤。下圖展示了這個使用案例:
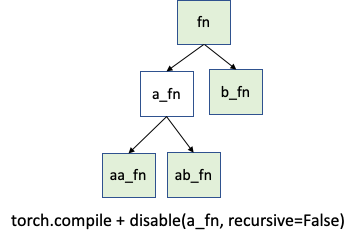
在這種情況下,您可以使用 torch._dynamo.disable(recursive=False)。在以前的版本中,此功能由 torch._dynamo.skip 提供。現在由 torch._dynamo.disable 中的 recursive 標誌支援。
