架構與元件¶
本頁介紹 ExecuTorch 的技術架構及其各個元件。本文件面向將 PyTorch 模型部署到邊緣裝置的工程師。
背景
為了針對具有多樣化硬體、嚴苛功耗要求和即時處理需求的裝置端 AI,單一的整體解決方案並不實用。相反,需要一種模組化、分層和可擴充套件的架構。ExecuTorch 定義了一個簡化的工作流程來準備(匯出、轉換和編譯)和執行 PyTorch 程式,提供了精心設計的開箱即用預設元件和定義明確的自定義入口點。這種架構極大地提高了可移植性,使工程師能夠使用高效能、輕量級、跨平臺的執行時,輕鬆整合到不同的裝置和平臺。
概覽¶
將 PyTorch 模型部署到裝置端分為三個階段:程式準備、執行時準備和程式執行,如下圖所示,並帶有多個使用者入口點。我們將在本文件中分別討論每個步驟。
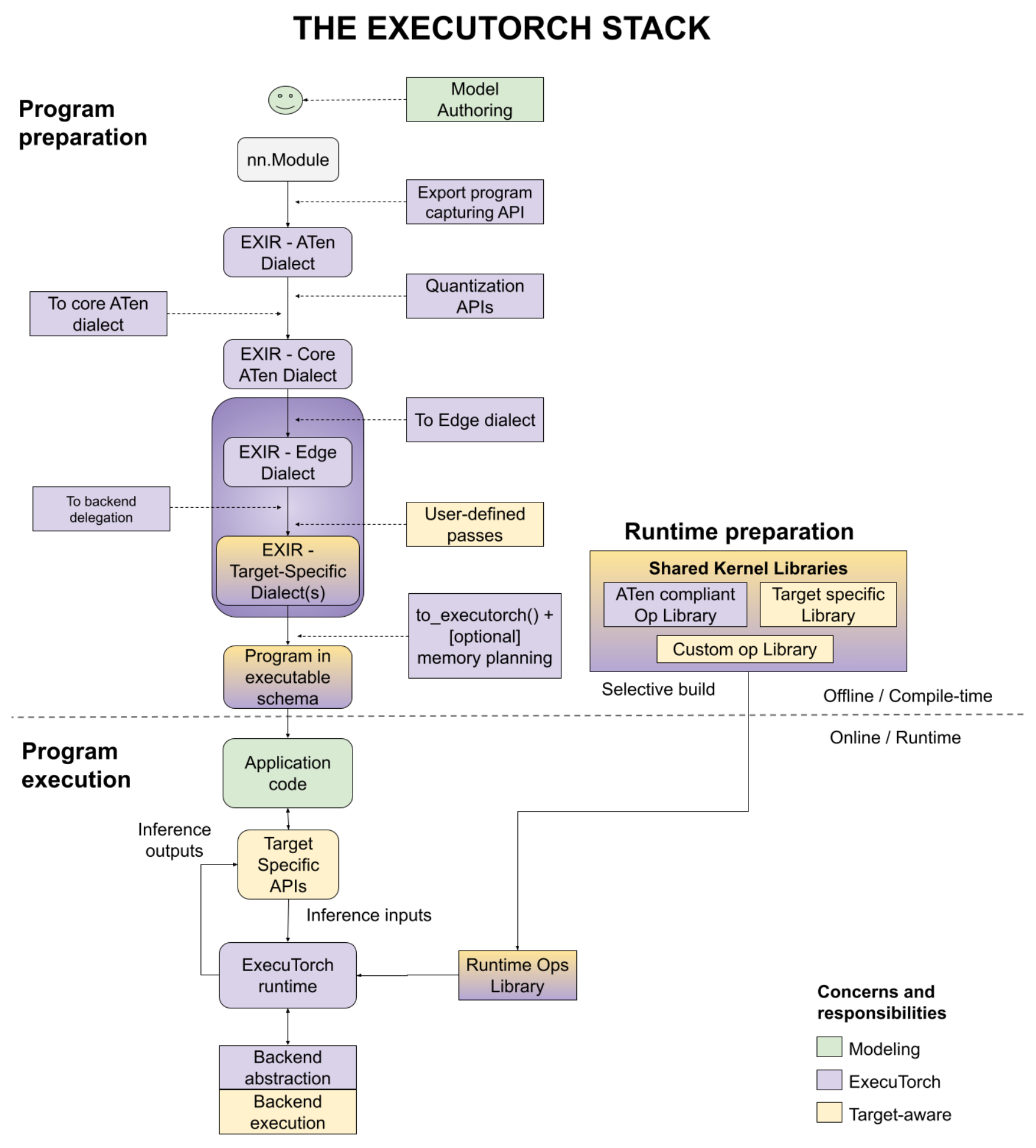
圖 1. 該圖展示了三個階段:程式準備、執行時準備和程式執行。
程式準備¶
ExecuTorch 將 PyTorch 的靈活性和可用性擴充套件到邊緣裝置。它利用 PyTorch 2 編譯器和匯出功能(TorchDynamo、AOTAutograd、量化、動態形狀、控制流等)來準備 PyTorch 程式以便在裝置上執行。
程式準備通常簡稱為 AOT(提前,ahead-of-time),因為程式的匯出、轉換和編譯是在使用 ExecuTorch 執行時(用 C++ 編寫)最終執行之前執行的。為了擁有輕量級執行時和較小的執行開銷,我們將盡可能多的工作推到 AOT 階段。
從程式原始碼開始,以下是您完成程式準備需要經歷的步驟。
程式原始碼¶
匯出¶
為了將程式部署到裝置,工程師需要一個圖形表示來編譯模型以便在各種後端上執行。使用 torch.export(),將生成帶有 ATen dialect 的 EXIR(匯出中間表示)。所有 AOT 編譯都基於此 EXIR,但如以下詳細介紹,在 Lowering 路徑上可以有多個 dialect。
ATen Dialect。PyTorch Edge 基於 PyTorch 的 Tensor 庫 ATen,該庫為高效執行提供了清晰的契約。ATen Dialect 是由完全符合 ATen 規範的 ATen 節點表示的圖形。允許使用自定義運算子,但必須使用 Dispatcher 進行註冊。它是扁平化的,沒有模組層次結構(在一個更大的模組中的子模組),但原始碼和模組層次結構保留在元資料中。這種表示也是 Autograd 安全的。
可以選擇性地,可以在將整個 ATen 圖轉換為 Core ATen 之前應用量化,無論是 QAT(量化感知訓練)還是 PTQ(訓練後量化)。量化有助於減小模型大小,這對於邊緣裝置非常重要。
Core ATen Dialect。ATen 有數千個運算子。對於一些基本轉換和核心庫實現來說,它並不理想。ATen Dialect 圖中的運算子被分解為基本運算子,以便運算子集 (op set) 更小並且可以應用更基本的轉換。Core ATen dialect 也是可序列化的,並且可以轉換為 Edge Dialect,如下所述。
邊緣編譯¶
上面討論的匯出過程在一個與最終執行程式碼的邊緣裝置無關的圖形上進行操作。在邊緣編譯步驟中,我們處理特定於邊緣的表示形式。
Edge Dialect。所有運算子要麼符合帶有 dtype 和記憶體佈局資訊(表示為
dim_order)的 ATen 運算子,要麼是註冊的自定義運算子。標量被轉換為 Tensor。這些規範允許後續步驟專注於一個更小的 Edge 領域。此外,它還支援基於特定 dtype 和記憶體佈局的選擇性構建。
使用 Edge dialect,有兩種目標感知的方式將圖進一步 Lowering 到 Backend Dialect。此時,特定硬體的委託可以執行許多操作。例如,iOS 上的 Core ML、Qualcomm 上的 QNN 或 Arm 上的 TOSA 可以重寫圖。此級別的選項包括
後端委託 (Backend Delegate)。這是將圖(完整或部分)編譯到特定後端的入口點。在此轉換期間,編譯後的圖會替換為語義等效的圖。編譯後的圖稍後將在執行時解除安裝到後端(也稱為
委託)以提高效能。使用者自定義 Passes。使用者也可以執行目標特定的轉換。這方面很好的例子包括核心融合、非同步行為、記憶體佈局轉換等。
編譯為 ExecuTorch 程式¶
上述 Edge 程式適合編譯,但不適合執行時環境。裝置端部署工程師可以降低圖,使其能夠被執行時高效載入和執行。
在大多數 Edge 環境中,動態記憶體分配/釋放具有顯著的效能和功耗開銷。可以使用 AOT 記憶體規劃和靜態執行圖來避免這種情況。
ExecuTorch 執行時是靜態的(在圖表示的意義上,但仍然支援控制流和動態形狀)。為了避免輸出建立和返回,所有函式式運算子表示都轉換為 out 變體(輸出作為引數傳遞)。
使用者可以選擇應用自己的記憶體規劃演算法。例如,嵌入式系統可能有多層記憶體層次結構。使用者可以自定義記憶體規劃以適應該記憶體層次結構。
程式會被輸出為 ExecuTorch 執行時能夠識別的格式。
最後,輸出的程式可以序列化為 flatbuffer 格式。
執行時準備¶
有了序列化的程式,並提供了核心庫(用於運算子呼叫)或後端庫(用於委託呼叫),模型部署工程師現在可以為執行時準備程式。
ExecuTorch 具有 選擇性構建 API,用於構建僅連結程式使用的核心的執行時,這可以顯著減小最終應用程式的二進位制檔案大小。
程式執行¶
ExecuTorch 執行時使用 C++ 編寫,依賴項極少,以實現可移植性和執行效率。由於程式已在 AOT 階段充分準備,核心執行時元件非常精簡,包括:
平臺抽象層
日誌記錄和可選的效能分析
執行資料型別
核心與後端登錄檔
記憶體管理
Executor 是載入和執行程式的入口點。執行會從這個非常精簡的執行時觸發相應的運算子核心或後端執行。
開發者工具¶
使用者應該能夠高效地使用上述流程從研究轉向生產。生產力至關重要,以便使用者編寫、最佳化和部署模型。我們提供 ExecuTorch 開發者工具來提高生產力。開發者工具未在圖中顯示。相反,它是一個覆蓋三個階段開發者工作流程的工具集。
在程式準備和執行期間,使用者可以使用 ExecuTorch 開發者工具來分析、除錯或視覺化程式。由於端到端流程都在 PyTorch 生態系統內,使用者可以將效能資料與圖視覺化以及對程式原始碼和模型層次結構的直接引用進行關聯和顯示。我們認為這是快速迭代並將 PyTorch 程式 Lowering 到邊緣裝置和環境的關鍵元件。
