


注意
前往末尾下載完整示例程式碼。
迴圈 DQN:訓練迴圈策略¶
作者: Vincent Moens
如何在 TorchRL 的 actor 中整合 RNN
如何將基於記憶體的策略與回放緩衝區和損失模組一起使用
PyTorch v2.0.0
gym[mujoco]
tqdm
import tempfile
概述¶
基於記憶體的策略至關重要,不僅在觀測值部分可觀測時,而且在做出明智決策需要考慮時間維度時也是如此。
迴圈神經網路長期以來一直是基於記憶體的策略的流行工具。其思想是在兩個連續步驟之間將迴圈狀態儲存在記憶體中,並將其與當前觀測值一起作為策略的輸入。
本教程展示瞭如何使用 TorchRL 在策略中整合 RNN。
關鍵學習點
在 TorchRL 的 actor 中整合 RNN;
將基於記憶體的策略與回放緩衝區和損失模組一起使用。
在 TorchRL 中使用 RNN 的核心思想是使用 TensorDict 作為資料載體,將隱藏狀態從一步傳遞到另一步。我們將構建一個策略,該策略從當前的 TensorDict 中讀取先前的迴圈狀態,並將當前的迴圈狀態寫入下一個狀態的 TensorDict 中
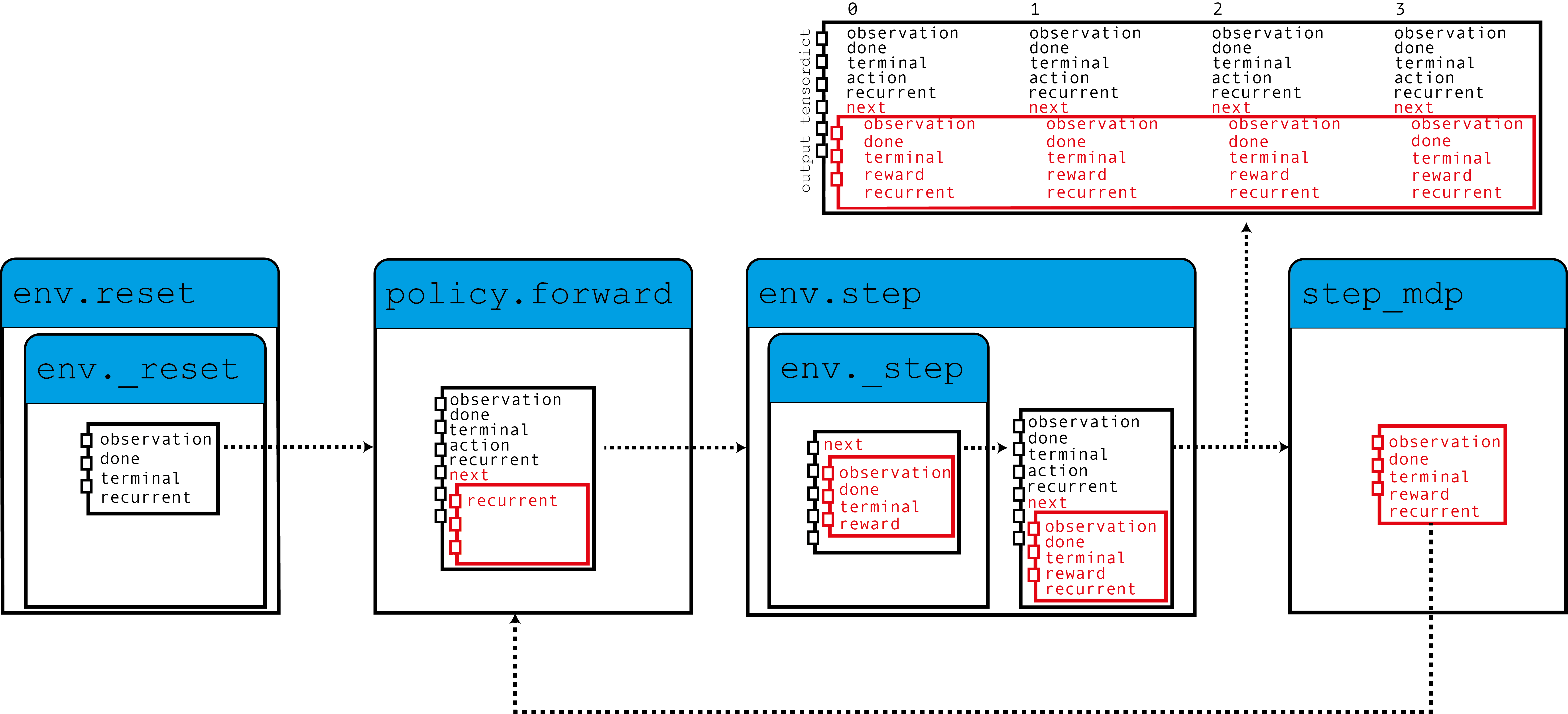
如圖所示,我們的環境使用零值迴圈狀態填充 TensorDict,策略讀取這些狀態以及觀測值以生成動作和將在下一步中使用的迴圈狀態。當呼叫 step_mdp() 函式時,下一個狀態的迴圈狀態會被帶到當前的 TensorDict 中。讓我們看看這在實踐中是如何實現的。
如果你在 Google Colab 中執行此程式碼,請確保安裝以下依賴項
!pip3 install torchrl
!pip3 install gym[mujoco]
!pip3 install tqdm
設定¶
import torch
import tqdm
from tensordict.nn import (
TensorDictModule as Mod,
TensorDictSequential,
TensorDictSequential as Seq,
)
from torch import nn
from torchrl.collectors import SyncDataCollector
from torchrl.data import LazyMemmapStorage, TensorDictReplayBuffer
from torchrl.envs import (
Compose,
ExplorationType,
GrayScale,
InitTracker,
ObservationNorm,
Resize,
RewardScaling,
set_exploration_type,
StepCounter,
ToTensorImage,
TransformedEnv,
)
from torchrl.envs.libs.gym import GymEnv
from torchrl.modules import ConvNet, EGreedyModule, LSTMModule, MLP, QValueModule
from torchrl.objectives import DQNLoss, SoftUpdate
is_fork = multiprocessing.get_start_method() == "fork"
device = (
torch.device(0)
if torch.cuda.is_available() and not is_fork
else torch.device("cpu")
)
環境¶
像往常一樣,第一步是構建我們的環境:它幫助我們定義問題並相應地構建策略網路。在本教程中,我們將執行一個基於畫素的 CartPole gym 環境的單例項,並進行一些自定義 transforms:轉換為灰度、調整大小為 84x84、縮小獎勵並歸一化觀測值。
注意
StepCounter transform 是輔助性的。由於 CartPole 任務的目標是使軌跡儘可能長,計數步驟可以幫助我們跟蹤策略的效能。
有兩個 transforms 對本教程的目的很重要
InitTracker將透過在 TensorDict 中新增一個布林掩碼"is_init"來標記對reset()的呼叫,該掩碼將跟蹤哪些步驟需要重置 RNN 隱藏狀態。TensorDictPrimertransform 稍微更技術性一些。它不是使用 RNN 策略所必需的。但是,它會通知環境(以及隨後的 collector)期望一些額外的鍵。新增後,呼叫 env.reset() 將使用零值張量填充 primer 中指定的條目。由於策略期望這些張量,collector 在收集過程中會將其傳遞下去。最終,我們會將隱藏狀態儲存在回放緩衝區中,這有助於我們在損失模組中引導 RNN 操作的計算(否則將用 0 初始化)。總而言之:不包含此 transform 不會對我們策略的訓練產生巨大影響,但它會使迴圈鍵從收集的資料和回放緩衝區中消失,這反過來會導致訓練稍不理想。幸運的是,我們提供的LSTMModule配備了一個輔助方法來為我們構建該 transform,所以我們可以等到構建它時再使用!
env = TransformedEnv(
GymEnv("CartPole-v1", from_pixels=True, device=device),
Compose(
ToTensorImage(),
GrayScale(),
Resize(84, 84),
StepCounter(),
InitTracker(),
RewardScaling(loc=0.0, scale=0.1),
ObservationNorm(standard_normal=True, in_keys=["pixels"]),
),
)
一如既往,我們需要手動初始化我們的歸一化常數
env.transform[-1].init_stats(1000, reduce_dim=[0, 1, 2], cat_dim=0, keep_dims=[0])
td = env.reset()
策略¶
我們的策略將有 3 個元件:一個 ConvNet 主幹網路、一個 LSTMModule 記憶體層和一個淺層 MLP 塊,該塊將 LSTM 輸出對映到動作值上。
卷積網路¶
我們構建一個卷積網路,並在其兩側新增一個 torch.nn.AdaptiveAvgPool2d,它將輸出壓縮成大小為 64 的向量。ConvNet 可以幫助我們完成這項工作
feature = Mod(
ConvNet(
num_cells=[32, 32, 64],
squeeze_output=True,
aggregator_class=nn.AdaptiveAvgPool2d,
aggregator_kwargs={"output_size": (1, 1)},
device=device,
),
in_keys=["pixels"],
out_keys=["embed"],
)
我們在一批資料上執行第一個模組,以獲取輸出向量的大小
n_cells = feature(env.reset())["embed"].shape[-1]
LSTM 模組¶
TorchRL 提供了一個專門的 LSTMModule 類,用於在你的程式碼庫中整合 LSTM。它是一個 TensorDictModuleBase 子類:因此,它有一組 in_keys 和 out_keys,指示在模組執行期間應讀取和寫入/更新哪些值。該類附帶了這些屬性的可自定義預定義值,以方便其構建。
注意
使用限制:該類支援幾乎所有 LSTM 特性,例如 dropout 或多層 LSTM。然而,為了遵循 TorchRL 的約定,此 LSTM 的 batch_first 屬性必須設定為 True,這在 PyTorch 中不是預設值。但是,我們的 LSTMModule 改變了此預設行為,因此我們可以直接呼叫它。
此外,LSTM 的 bidirectional 屬性不能設定為 True因為其在線上設定中無法使用。在這種情況下,預設值是正確的。
lstm = LSTMModule(
input_size=n_cells,
hidden_size=128,
device=device,
in_key="embed",
out_key="embed",
)
讓我們看看 LSTM Module 類,特別是它的 in_keys 和 out_keys
print("in_keys", lstm.in_keys)
print("out_keys", lstm.out_keys)
我們可以看到這些值包含我們指定的 in_key (和 out_key) 以及迴圈鍵名稱。out_keys 前面有一個“next”字首,表示它們需要寫入“next” TensorDict 中。我們使用此約定(可以透過傳遞 in_keys/out_keys 引數來覆蓋)來確保呼叫 step_mdp() 會將迴圈狀態移動到根 TensorDict,使其在後續呼叫期間可供 RNN 使用(參見引言中的圖)。
如前所述,我們還有一個可選的 transform 需要新增到我們的環境中,以確保迴圈狀態被傳遞到緩衝區。make_tensordict_primer() 方法正是做這件事的
env.append_transform(lstm.make_tensordict_primer())
就這樣!我們可以列印環境來檢查一切是否正常,現在我們已經添加了 primer
print(env)
MLP¶
我們使用單層 MLP 來表示我們將用於策略的動作值。
mlp = MLP(
out_features=2,
num_cells=[
64,
],
device=device,
)
並將偏置填充為零
mlp[-1].bias.data.fill_(0.0)
mlp = Mod(mlp, in_keys=["embed"], out_keys=["action_value"])
使用 Q 值選擇動作¶
我們策略的最後一部分是 Q 值模組。Q 值模組 QValueModule 將讀取我們的 MLP 生成的 "action_values" 鍵,並從中獲取具有最大值的動作。我們唯一需要做的就是指定動作空間,可以透過傳遞字串或 action-spec 來完成。這允許我們使用 Categorical(有時稱為“稀疏”)編碼或其 one-hot 版本。
qval = QValueModule(action_space=None, spec=env.action_spec)
注意
TorchRL 還提供了一個包裝類 torchrl.modules.QValueActor,它將一個模組與 QValueModule 一起包裝在 Sequential 中,就像我們在此處明確做的一樣。這樣做的好處不大,過程也不太透明,但最終結果將與我們在此處做的相似。
現在我們可以將這些元件組合到一個 TensorDictSequential 中
policy = Seq(feature, lstm, mlp, qval)
DQN 是一個確定性演算法,探索是其關鍵部分。我們將使用 \(\epsilon\)-greedy 策略,其中 epsilon 從 0.2 逐漸衰減到 0。這種衰減透過呼叫 step() 實現(參見下面的訓練迴圈)。
exploration_module = EGreedyModule(
annealing_num_steps=1_000_000, spec=env.action_spec, eps_init=0.2
)
stoch_policy = TensorDictSequential(
policy,
exploration_module,
)
將模型用於損失計算¶
我們構建的模型非常適合在序列設定中使用。然而,torch.nn.LSTM 類可以使用 cuDNN 最佳化的後端在 GPU 裝置上更快地執行 RNN 序列。我們不想錯過這個加速訓練迴圈的機會!
預設情況下,TorchRL 損失函式在執行任何 LSTMModule 或 GRUModule 的 forward 呼叫時會使用此功能。如果您需要手動控制,RNN 模組對一個上下文管理器/裝飾器 set_recurrent_mode 敏感,它處理底層 RNN 模組的行為。
由於我們還有一些未初始化的引數,因此在建立最佳化器等之前應該對其進行初始化。
policy(env.reset())
DQN 損失¶
我們的 DQN 損失函式要求我們傳入策略,並且再次傳入動作空間。雖然這可能看起來是多餘的,但很重要,因為我們要確保 DQNLoss 和 QValueModule 類相容,但彼此之間沒有強依賴關係。
為了使用 Double-DQN,我們需要一個 delay_value 引數,它會建立一個不可微分的網路引數副本,用作目標網路。
loss_fn = DQNLoss(policy, action_space=env.action_spec, delay_value=True)
由於我們使用雙 DQN,我們需要更新目標引數。我們將使用 SoftUpdate 例項來執行此操作。
updater = SoftUpdate(loss_fn, eps=0.95)
optim = torch.optim.Adam(policy.parameters(), lr=3e-4)
Collector 和回放緩衝區¶
我們構建了最簡單的資料 collector。我們將嘗試使用一百萬幀來訓練我們的演算法,每次向緩衝區擴充套件 50 幀。緩衝區將設計為儲存 2 萬條軌跡,每條軌跡 50 步。在每個最佳化步驟(每次資料收集 16 次)中,我們將從緩衝區收集 4 個專案,總共 200 個轉換。我們將使用 LazyMemmapStorage 儲存將資料儲存在磁碟上。
注意
為了提高效率,我們在此處只運行了幾千次迭代。在實際設定中,總幀數應設定為 100 萬。
buffer_scratch_dir = tempfile.TemporaryDirectory().name
collector = SyncDataCollector(env, stoch_policy, frames_per_batch=50, total_frames=200)
rb = TensorDictReplayBuffer(
storage=LazyMemmapStorage(20_000, scratch_dir=buffer_scratch_dir),
batch_size=4,
prefetch=10,
)
訓練迴圈¶
為了跟蹤進度,我們每收集 50 次資料,就會在環境中執行一次策略,並在訓練後繪製結果。
utd = 16
pbar = tqdm.tqdm(total=collector.total_frames)
longest = 0
traj_lens = []
for i, data in enumerate(collector):
if i == 0:
print(
"Let us print the first batch of data.\nPay attention to the key names "
"which will reflect what can be found in this data structure, in particular: "
"the output of the QValueModule (action_values, action and chosen_action_value),"
"the 'is_init' key that will tell us if a step is initial or not, and the "
"recurrent_state keys.\n",
data,
)
pbar.update(data.numel())
# it is important to pass data that is not flattened
rb.extend(data.unsqueeze(0).to_tensordict().cpu())
for _ in range(utd):
s = rb.sample().to(device, non_blocking=True)
loss_vals = loss_fn(s)
loss_vals["loss"].backward()
optim.step()
optim.zero_grad()
longest = max(longest, data["step_count"].max().item())
pbar.set_description(
f"steps: {longest}, loss_val: {loss_vals['loss'].item(): 4.4f}, action_spread: {data['action'].sum(0)}"
)
exploration_module.step(data.numel())
updater.step()
with set_exploration_type(ExplorationType.DETERMINISTIC), torch.no_grad():
rollout = env.rollout(10000, stoch_policy)
traj_lens.append(rollout.get(("next", "step_count")).max().item())
讓我們繪製結果
if traj_lens:
from matplotlib import pyplot as plt
plt.plot(traj_lens)
plt.xlabel("Test collection")
plt.title("Test trajectory lengths")
結論¶
我們已經瞭解瞭如何在 TorchRL 的策略中整合 RNN。現在你應該能夠
建立一個充當
TensorDictModule的 LSTM 模組透過
InitTrackertransform 指示 LSTM 模組需要重置將此模組整合到策略和損失模組中
確保 collector 知道迴圈狀態條目,以便它們可以與其餘資料一起儲存在回放緩衝區中
延伸閱讀¶
TorchRL 文件可以在這裡找到。
