


注意
跳轉至末尾 下載完整的示例程式碼。
TorchRL 目標: 編寫 DDPG 損失函式¶
作者: Vincent Moens
概述¶
TorchRL 將強化學習演算法的訓練分解為各種元件,這些元件將組裝到你的訓練指令碼中:環境、資料收集和儲存、模型以及最後的損失函式。
TorchRL 損失函式(或“目標函式”)是包含可訓練引數(策略模型和價值模型)的狀態物件。本教程將指導你從頭開始使用 TorchRL 編寫損失函式的步驟。
為此,我們將重點關注 DDPG,它是一種相對簡單易於編寫的演算法。深度確定性策略梯度 (DDPG) 是一種簡單的連續控制演算法。它包含學習一個動作-觀察對的引數化價值函式,然後學習一個策略,該策略在給定特定觀察時輸出最大化此價值函式的動作。
你將學到什麼
如何編寫損失模組並自定義其價值估計器;
如何在 TorchRL 中構建環境,包括 transforms(例如資料歸一化)和並行執行;
如何設計策略網路和價值網路;
如何高效地從環境中收集資料並將其儲存在經驗回放緩衝區中;
如何將軌跡(而非單一轉換)儲存在經驗回放緩衝區中;
如何評估你的模型。
先決條件¶
本教程假設你已完成PPO 教程,該教程概述了 TorchRL 元件和依賴項,例如 tensordict.TensorDict 和 tensordict.nn.TensorDictModules,儘管它應該足夠透明,即使不深入理解這些類也能理解。
注意
我們並非旨在提供該演算法的最先進 (SOTA) 實現,而是旨在提供 TorchRL 損失實現的高階示例,以及在該演算法上下文中使用的庫功能。
匯入與設定¶
%%bash pip3 install torchrl mujoco glfw
import torch
import tqdm
如果可用,我們將在 CUDA 上執行策略
is_fork = multiprocessing.get_start_method() == "fork"
device = (
torch.device(0)
if torch.cuda.is_available() and not is_fork
else torch.device("cpu")
)
collector_device = torch.device("cpu") # Change the device to ``cuda`` to use CUDA
TorchRL LossModule¶
TorchRL 提供了一系列損失函式供你在訓練指令碼中使用。目的是使損失函式易於重用/替換,並具有簡單的簽名。
TorchRL 損失函式的主要特點是
它們是狀態物件(stateful objects):包含可訓練引數的副本,因此
loss_module.parameters()會提供訓練演算法所需的一切。它們遵循
TensorDict約定:torch.nn.Module.forward()方法將接收一個從經驗回放緩衝區或任何類似資料結構中取樣的 TensorDict 作為輸入,其中包含返回損失值所需的所有必要資訊。它們輸出一個
tensordict.TensorDict例項,其中損失值儲存在"loss_<smth>"鍵下,其中smth是描述損失的字串。TensorDict 中的附加鍵可能是訓練期間有用的度量。注意
我們返回獨立損失的原因是允許使用者對不同的引數集使用不同的最佳化器。可以透過以下方式簡單地對損失進行求和
..code - block::Python
>>> loss_val = sum(loss for key, loss in loss_dict.items() if key.startswith("loss_"))
__init__ 方法¶
所有損失函式的父類是 LossModule。與庫中的許多其他元件一樣,其 forward() 方法期望從經驗回放緩衝區或任何類似資料結構中取樣的 tensordict.TensorDict 例項作為輸入。使用這種格式可以在不同的模態或模型需要讀取多個條目的複雜設定中重用該模組。換句話說,它允許我們編寫一個損失模組,該模組不關心提供給它的資料型別,而專注於執行損失函式的基本步驟,僅此而已。
為了使本教程儘可能具有啟發性,我們將獨立展示類中的每個方法,並稍後填充類。
讓我們從 __init__() 方法開始。DDPG 旨在透過一個簡單的策略解決控制任務:訓練一個策略來輸出最大化價值網路預測的價值的動作。因此,我們的損失模組需要在其建構函式中接收兩個網路:一個 actor 網路和一個價值網路。我們期望這兩個網路都是 TensorDict 相容的物件,例如 tensordict.nn.TensorDictModule。我們的損失函式需要計算目標價值並將價值網路擬合到該目標值,並生成一個動作並擬合策略,以便其價值估計最大化。
LossModule.__init__() 方法中的關鍵步驟是呼叫 convert_to_functional()。此方法將從模組中提取引數並將其轉換為函式式模組。嚴格來說,這不是必需的,完全可以在不使用它的情況下編寫所有損失函式。但是,我們鼓勵使用它,原因如下。
TorchRL 這樣做是因為強化學習演算法通常使用不同的引數集執行相同的模型,這些引數集稱為“可訓練”引數和“目標”引數。“可訓練”引數是最佳化器需要擬合的引數。“目標”引數通常是前者的副本,但存在一些時間延遲(絕對或透過移動平均稀釋)。這些目標引數用於計算與下一個觀察值相關聯的價值。使用一組與當前配置不完全匹配的價值模型目標引數的優點之一是它們為正在計算的價值函式提供了悲觀的界限。請注意下面的 create_target_params 關鍵字引數:此引數告訴 convert_to_functional() 方法在損失模組中建立一組目標引數,用於計算目標價值。如果此引數設定為 False(例如 actor 網路),則 target_actor_network_params 屬性仍然可訪問,但這隻會返回 actor 引數的分離版本。
稍後,我們將看到如何在 TorchRL 中更新目標引數。
from tensordict.nn import TensorDictModule, TensorDictSequential
def _init(
self,
actor_network: TensorDictModule,
value_network: TensorDictModule,
) -> None:
super(type(self), self).__init__()
self.convert_to_functional(
actor_network,
"actor_network",
create_target_params=True,
)
self.convert_to_functional(
value_network,
"value_network",
create_target_params=True,
compare_against=list(actor_network.parameters()),
)
self.actor_in_keys = actor_network.in_keys
# Since the value we'll be using is based on the actor and value network,
# we put them together in a single actor-critic container.
actor_critic = ActorCriticWrapper(actor_network, value_network)
self.actor_critic = actor_critic
self.loss_function = "l2"
價值估計器損失方法¶
在許多強化學習演算法中,價值網路(或 Q 值網路)基於經驗價值估計進行訓練。這可以是自舉的(TD(0),低方差,高偏差),這意味著目標價值是透過下一個獎勵獲得的,別無其他;或者可以獲得蒙特卡羅估計(TD(1)),在這種情況下將使用即將到來的整個獎勵序列(高方差,低偏差)。也可以使用中間估計器 (TD(\(\lambda\))) 來折衷偏差和方差。TorchRL 透過 ValueEstimators 列舉類使其易於使用其中一個估計器,該類包含指向所有已實現的價值估計器的指標。讓我們在此處定義預設價值函式。我們將採用最簡單的版本 (TD(0)),並在稍後展示如何更改它。
from torchrl.objectives.utils import ValueEstimators
default_value_estimator = ValueEstimators.TD0
我們還需要向 DDPG 提供一些關於如何根據使用者查詢構建價值估計器的說明。根據提供的估計器,我們將構建在訓練時要使用的相應模組
from torchrl.objectives.utils import default_value_kwargs
from torchrl.objectives.value import TD0Estimator, TD1Estimator, TDLambdaEstimator
def make_value_estimator(self, value_type: ValueEstimators, **hyperparams):
hp = dict(default_value_kwargs(value_type))
if hasattr(self, "gamma"):
hp["gamma"] = self.gamma
hp.update(hyperparams)
value_key = "state_action_value"
if value_type == ValueEstimators.TD1:
self._value_estimator = TD1Estimator(value_network=self.actor_critic, **hp)
elif value_type == ValueEstimators.TD0:
self._value_estimator = TD0Estimator(value_network=self.actor_critic, **hp)
elif value_type == ValueEstimators.GAE:
raise NotImplementedError(
f"Value type {value_type} it not implemented for loss {type(self)}."
)
elif value_type == ValueEstimators.TDLambda:
self._value_estimator = TDLambdaEstimator(value_network=self.actor_critic, **hp)
else:
raise NotImplementedError(f"Unknown value type {value_type}")
self._value_estimator.set_keys(value=value_key)
make_value_estimator 方法可以呼叫,但非必需:如果未呼叫,則 LossModule 將使用其預設估計器查詢此方法。
Actor 損失方法¶
強化學習演算法的核心部分是 actor 的訓練損失函式。在 DDPG 的情況下,此函式相當簡單:我們只需要計算使用策略計算的動作的價值,並最佳化 actor 權重以最大化此價值。
計算此價值時,我們必須確保將價值引數從計算圖中移除,否則 actor 和價值損失將混淆。為此,可以使用 hold_out_params() 函式。
def _loss_actor(
self,
tensordict,
) -> torch.Tensor:
td_copy = tensordict.select(*self.actor_in_keys)
# Get an action from the actor network: since we made it functional, we need to pass the params
with self.actor_network_params.to_module(self.actor_network):
td_copy = self.actor_network(td_copy)
# get the value associated with that action
with self.value_network_params.detach().to_module(self.value_network):
td_copy = self.value_network(td_copy)
return -td_copy.get("state_action_value")
價值損失方法¶
現在我們需要最佳化價值網路引數。為此,我們將依賴於類的價值估計器
from torchrl.objectives.utils import distance_loss
def _loss_value(
self,
tensordict,
):
td_copy = tensordict.clone()
# V(s, a)
with self.value_network_params.to_module(self.value_network):
self.value_network(td_copy)
pred_val = td_copy.get("state_action_value").squeeze(-1)
# we manually reconstruct the parameters of the actor-critic, where the first
# set of parameters belongs to the actor and the second to the value function.
target_params = TensorDict(
{
"module": {
"0": self.target_actor_network_params,
"1": self.target_value_network_params,
}
},
batch_size=self.target_actor_network_params.batch_size,
device=self.target_actor_network_params.device,
)
with target_params.to_module(self.actor_critic):
target_value = self.value_estimator.value_estimate(tensordict).squeeze(-1)
# Computes the value loss: L2, L1 or smooth L1 depending on `self.loss_function`
loss_value = distance_loss(pred_val, target_value, loss_function=self.loss_function)
td_error = (pred_val - target_value).pow(2)
return loss_value, td_error, pred_val, target_value
在 forward 呼叫中將各部分組合起來¶
唯一缺少的部分是 forward 方法,它將價值損失和 actor 損失粘合在一起,收整合本值並將它們寫入提供給使用者的 TensorDict 中。
from tensordict import TensorDict, TensorDictBase
def _forward(self, input_tensordict: TensorDictBase) -> TensorDict:
loss_value, td_error, pred_val, target_value = self.loss_value(
input_tensordict,
)
td_error = td_error.detach()
td_error = td_error.unsqueeze(input_tensordict.ndimension())
if input_tensordict.device is not None:
td_error = td_error.to(input_tensordict.device)
input_tensordict.set(
"td_error",
td_error,
inplace=True,
)
loss_actor = self.loss_actor(input_tensordict)
return TensorDict(
source={
"loss_actor": loss_actor.mean(),
"loss_value": loss_value.mean(),
"pred_value": pred_val.mean().detach(),
"target_value": target_value.mean().detach(),
"pred_value_max": pred_val.max().detach(),
"target_value_max": target_value.max().detach(),
},
batch_size=[],
)
from torchrl.objectives import LossModule
class DDPGLoss(LossModule):
default_value_estimator = default_value_estimator
make_value_estimator = make_value_estimator
__init__ = _init
forward = _forward
loss_value = _loss_value
loss_actor = _loss_actor
現在我們有了損失函式,我們可以用它來訓練策略來解決控制任務。
環境¶
在大多數演算法中,首先需要處理的是環境的構建,因為它決定了訓練指令碼的其餘部分。
對於此示例,我們將使用 "cheetah" 任務。目標是讓一隻半機械豹儘可能快地奔跑。
在 TorchRL 中,可以透過依賴 dm_control 或 gym 建立此類任務
env = GymEnv("HalfCheetah-v4")
或
env = DMControlEnv("cheetah", "run")
預設情況下,這些環境停用渲染。從狀態進行訓練通常比從影像進行訓練更容易。為了簡單起見,我們只關注從狀態學習。要將畫素傳遞給 env.step() 收集的 tensordicts,只需將 from_pixels=True 引數傳遞給建構函式即可
env = GymEnv("HalfCheetah-v4", from_pixels=True, pixels_only=True)
我們編寫一個 make_env() 輔助函式,該函式將使用上面考慮的兩種後端之一(dm-control 或 gym)建立一個環境。
from torchrl.envs.libs.dm_control import DMControlEnv
from torchrl.envs.libs.gym import GymEnv
env_library = None
env_name = None
def make_env(from_pixels=False):
"""Create a base ``env``."""
global env_library
global env_name
if backend == "dm_control":
env_name = "cheetah"
env_task = "run"
env_args = (env_name, env_task)
env_library = DMControlEnv
elif backend == "gym":
env_name = "HalfCheetah-v4"
env_args = (env_name,)
env_library = GymEnv
else:
raise NotImplementedError
env_kwargs = {
"device": device,
"from_pixels": from_pixels,
"pixels_only": from_pixels,
"frame_skip": 2,
}
env = env_library(*env_args, **env_kwargs)
return env
Transforms¶
現在我們有了基本環境,我們可能希望修改其表示形式以使其對策略更友好。在 TorchRL 中,transforms 被附加到基本環境中,放在專門的 torchr.envs.TransformedEnv 類中。
在 DDPG 中,使用一些啟發式價值來重新縮放獎勵是很常見的。在此示例中,我們將獎勵乘以 5。
如果我們使用
dm_control,構建一個在模擬器(使用雙精度數字)與我們的指令碼(可能使用單精度數字)之間的介面也很重要。這種轉換是雙向的:呼叫env.step()時,我們的動作需要表示為雙精度,並且輸出需要轉換為單精度。DoubleToFloattransform 正好做了這件事:in_keys列表指的是需要從雙精度轉換為單精度的鍵,而in_keys_inv指的是在傳遞給環境之前需要轉換為雙精度的鍵。我們使用
CatTensorstransform 將狀態鍵連線在一起。最後,我們也保留了歸一化狀態的可能性:我們將稍後計算歸一化常數。
from torchrl.envs import (
CatTensors,
DoubleToFloat,
EnvCreator,
InitTracker,
ObservationNorm,
ParallelEnv,
RewardScaling,
StepCounter,
TransformedEnv,
)
def make_transformed_env(
env,
):
"""Apply transforms to the ``env`` (such as reward scaling and state normalization)."""
env = TransformedEnv(env)
# we append transforms one by one, although we might as well create the
# transformed environment using the `env = TransformedEnv(base_env, transforms)`
# syntax.
env.append_transform(RewardScaling(loc=0.0, scale=reward_scaling))
# We concatenate all states into a single "observation_vector"
# even if there is a single tensor, it'll be renamed in "observation_vector".
# This facilitates the downstream operations as we know the name of the
# output tensor.
# In some environments (not half-cheetah), there may be more than one
# observation vector: in this case this code snippet will concatenate them
# all.
selected_keys = list(env.observation_spec.keys())
out_key = "observation_vector"
env.append_transform(CatTensors(in_keys=selected_keys, out_key=out_key))
# we normalize the states, but for now let's just instantiate a stateless
# version of the transform
env.append_transform(ObservationNorm(in_keys=[out_key], standard_normal=True))
env.append_transform(DoubleToFloat())
env.append_transform(StepCounter(max_frames_per_traj))
# We need a marker for the start of trajectories for our Ornstein-Uhlenbeck (OU)
# exploration:
env.append_transform(InitTracker())
return env
並行執行¶
以下輔助函式允許我們並行執行環境。並行執行環境可以顯著加快收集吞吐量。使用 transformed 環境時,我們需要選擇是為每個環境單獨執行 transform,還是集中資料並以批處理方式轉換。這兩種方法都很容易編碼
env = ParallelEnv(
lambda: TransformedEnv(GymEnv("HalfCheetah-v4"), transforms),
num_workers=4
)
env = TransformedEnv(
ParallelEnv(lambda: GymEnv("HalfCheetah-v4"), num_workers=4),
transforms
)
為了利用 PyTorch 的向量化能力,我們採用第一種方法
def parallel_env_constructor(
env_per_collector,
transform_state_dict,
):
if env_per_collector == 1:
def make_t_env():
env = make_transformed_env(make_env())
env.transform[2].init_stats(3)
env.transform[2].loc.copy_(transform_state_dict["loc"])
env.transform[2].scale.copy_(transform_state_dict["scale"])
return env
env_creator = EnvCreator(make_t_env)
return env_creator
parallel_env = ParallelEnv(
num_workers=env_per_collector,
create_env_fn=EnvCreator(lambda: make_env()),
create_env_kwargs=None,
pin_memory=False,
)
env = make_transformed_env(parallel_env)
# we call `init_stats` for a limited number of steps, just to instantiate
# the lazy buffers.
env.transform[2].init_stats(3, cat_dim=1, reduce_dim=[0, 1])
env.transform[2].load_state_dict(transform_state_dict)
return env
# The backend can be ``gym`` or ``dm_control``
backend = "gym"
注意
frame_skip 將多個步驟與單個動作批處理在一起 如果 > 1,則其他幀計數(例如 frames_per_batch, total_frames)需要調整,以確保在不同實驗中收集到的總幀數一致。這一點很重要,因為提高 frame-skip 但保持總幀數不變可能看起來像作弊:相比之下,一個使用 frame-skip 2 收集的 10M 元素資料集和另一個使用 frame-skip 1 的資料集,其與環境互動的比率實際上是 2:1!簡而言之,在處理幀跳過時,應該謹慎對待訓練指令碼的幀計數,因為這可能導致訓練策略之間的比較產生偏差。
縮放獎勵有助於我們控制訊號幅度,從而實現更高效的學習。
reward_scaling = 5.0
我們還定義了軌跡何時會被截斷。一千步(如果 frame-skip = 2,則為 500)對於 cheetah 任務來說是個不錯的數值
max_frames_per_traj = 500
觀察值歸一化¶
為了計算歸一化統計資料,我們在環境中執行任意數量的隨機步驟,並計算收集到的觀察值的均值和標準差。ObservationNorm.init_stats() 方法可用於此目的。為了獲得彙總統計資料,我們建立一個 dummy 環境,執行特定數量的步驟,收集特定數量步驟的資料,並計算其彙總統計資料。
def get_env_stats():
"""Gets the stats of an environment."""
proof_env = make_transformed_env(make_env())
t = proof_env.transform[2]
t.init_stats(init_env_steps)
transform_state_dict = t.state_dict()
proof_env.close()
return transform_state_dict
歸一化統計資料¶
使用 ObservationNorm 計算統計資料所使用的隨機步驟數
init_env_steps = 5000
transform_state_dict = get_env_stats()
每個資料收集器中的環境數量
env_per_collector = 4
我們將之前計算的統計資料傳遞給環境以歸一化其輸出
parallel_env = parallel_env_constructor(
env_per_collector=env_per_collector,
transform_state_dict=transform_state_dict,
)
from torchrl.data import Composite
構建模型¶
現在我們來設定模型。正如我們所見,DDPG 需要一個價值網路,用於估計狀態-動作對的價值,以及一個引數化 actor,用於學習如何選擇最大化此價值的動作。
回想一下,構建 TorchRL 模組需要兩個步驟
編寫將用作網路的
torch.nn.Module,將網路包裝到
tensordict.nn.TensorDictModule中,其中透過指定輸入和輸出鍵來處理資料流。
在更復雜的場景中,也可以使用 tensordict.nn.TensorDictSequential。
Q 值網路被包裝在一個 ValueOperator 中,該運算子會自動將 Q 值網路的 out_keys 設定為 "state_action_value,將其他價值網路的 out_keys 設定為 state_value。
TorchRL 提供了原論文中介紹的內建 DDPG 網路版本。可以在 DdpgMlpActor 和 DdpgMlpQNet 中找到它們。
由於我們使用 lazy 模組,因此必須在能夠將策略從一個裝置移動到另一個裝置以及執行其他操作之前例項化這些 lazy 模組。因此,使用少量資料樣本執行模組是良好的實踐。為此,我們根據環境規格生成假資料。
from torchrl.modules import (
ActorCriticWrapper,
DdpgMlpActor,
DdpgMlpQNet,
OrnsteinUhlenbeckProcessModule,
ProbabilisticActor,
TanhDelta,
ValueOperator,
)
def make_ddpg_actor(
transform_state_dict,
device="cpu",
):
proof_environment = make_transformed_env(make_env())
proof_environment.transform[2].init_stats(3)
proof_environment.transform[2].load_state_dict(transform_state_dict)
out_features = proof_environment.action_spec.shape[-1]
actor_net = DdpgMlpActor(
action_dim=out_features,
)
in_keys = ["observation_vector"]
out_keys = ["param"]
actor = TensorDictModule(
actor_net,
in_keys=in_keys,
out_keys=out_keys,
)
actor = ProbabilisticActor(
actor,
distribution_class=TanhDelta,
in_keys=["param"],
spec=Composite(action=proof_environment.action_spec),
).to(device)
q_net = DdpgMlpQNet()
in_keys = in_keys + ["action"]
qnet = ValueOperator(
in_keys=in_keys,
module=q_net,
).to(device)
# initialize lazy modules
qnet(actor(proof_environment.reset().to(device)))
return actor, qnet
actor, qnet = make_ddpg_actor(
transform_state_dict=transform_state_dict,
device=device,
)
探索¶
策略被傳遞到一個 OrnsteinUhlenbeckProcessModule 探索模組中,正如原論文建議的那樣。讓我們定義 OU 噪聲達到最小值之前的幀數
annealing_frames = 1_000_000
actor_model_explore = TensorDictSequential(
actor,
OrnsteinUhlenbeckProcessModule(
spec=actor.spec.clone(),
annealing_num_steps=annealing_frames,
).to(device),
)
if device == torch.device("cpu"):
actor_model_explore.share_memory()
資料收集器¶
TorchRL 提供了專門的類,幫助你透過在環境中執行策略來收集資料。這些“資料收集器”會迭代計算給定時間要執行的動作,然後在環境中執行一個步驟,並在需要時重置環境。資料收集器旨在幫助開發者嚴格控制每批資料中的幀數、收集的同步/非同步性質以及分配給資料收集的資源(例如 GPU、worker 數量等)。
這裡我們將使用 SyncDataCollector,一個簡單的單程序資料收集器。TorchRL 還提供其他收集器,例如 MultiaSyncDataCollector,它以非同步方式執行 rollouts(例如,在策略最佳化時收集資料,從而解耦訓練和資料收集)。
需要指定的引數有
一個環境工廠或一個環境,
策略,
收集器被視為空之前的總幀數,
每條軌跡的最大幀數(對於非終止環境,例如
dm_control環境很有用)。注意
傳遞給收集器的
max_frames_per_traj引數將註冊一個新的StepCountertransform 到用於推理的環境中。我們也可以手動實現相同的結果,正如我們在指令碼中所做的那樣。
還應該傳遞
每個收集到的批次中的幀數,
獨立於策略執行的隨機步數,
用於策略執行的裝置
在資料傳遞給主程序之前用於儲存資料的裝置。
訓練期間使用的總幀數應在 1M 左右。
total_frames = 10_000 # 1_000_000
收集器在外部迴圈每次迭代中返回的幀數等於每個子軌跡的長度乘以每個收集器中並行執行的環境數量。
換句話說,我們期望收集器返回的批次具有 [env_per_collector, traj_len] 的形狀,其中 traj_len=frames_per_batch/env_per_collector
traj_len = 200
frames_per_batch = env_per_collector * traj_len
init_random_frames = 5000
num_collectors = 2
from torchrl.collectors import SyncDataCollector
from torchrl.envs import ExplorationType
collector = SyncDataCollector(
parallel_env,
policy=actor_model_explore,
total_frames=total_frames,
frames_per_batch=frames_per_batch,
init_random_frames=init_random_frames,
reset_at_each_iter=False,
split_trajs=False,
device=collector_device,
exploration_type=ExplorationType.RANDOM,
)
評估器:構建你的記錄器物件¶
由於訓練資料是使用某種探索策略獲得的,因此演算法的真實效能需要在確定性模式下評估。我們使用一個專門的類 LogValidationReward 來實現此目的,它會以給定的頻率在環境中執行策略,並返回從這些模擬中獲得的統計資料。
以下輔助函式構建此物件
from torchrl.trainers import LogValidationReward
def make_recorder(actor_model_explore, transform_state_dict, record_interval):
base_env = make_env()
environment = make_transformed_env(base_env)
environment.transform[2].init_stats(
3
) # must be instantiated to load the state dict
environment.transform[2].load_state_dict(transform_state_dict)
recorder_obj = LogValidationReward(
record_frames=1000,
policy_exploration=actor_model_explore,
environment=environment,
exploration_type=ExplorationType.DETERMINISTIC,
record_interval=record_interval,
)
return recorder_obj
我們將每收集 10 個批次記錄一次效能
record_interval = 10
recorder = make_recorder(
actor_model_explore, transform_state_dict, record_interval=record_interval
)
from torchrl.data.replay_buffers import (
LazyMemmapStorage,
PrioritizedSampler,
RandomSampler,
TensorDictReplayBuffer,
)
經驗回放緩衝區¶
經驗回放緩衝區有兩種型別:優先回放(其中使用某種誤差訊號為某些項提供比其他項更高的取樣機率)和常規的迴圈經驗回放。
TorchRL 經驗回放緩衝區是可組合的:可以選擇儲存、取樣和寫入策略。也可以使用記憶體對映陣列將張量儲存在物理記憶體中。以下函式負責使用所需的超引數建立經驗回放緩衝區
from torchrl.envs import RandomCropTensorDict
def make_replay_buffer(buffer_size, batch_size, random_crop_len, prefetch=3, prb=False):
if prb:
sampler = PrioritizedSampler(
max_capacity=buffer_size,
alpha=0.7,
beta=0.5,
)
else:
sampler = RandomSampler()
replay_buffer = TensorDictReplayBuffer(
storage=LazyMemmapStorage(
buffer_size,
scratch_dir=buffer_scratch_dir,
),
batch_size=batch_size,
sampler=sampler,
pin_memory=False,
prefetch=prefetch,
transform=RandomCropTensorDict(random_crop_len, sample_dim=1),
)
return replay_buffer
我們將經驗回放緩衝區儲存在磁碟上的一個臨時目錄中
import tempfile
tmpdir = tempfile.TemporaryDirectory()
buffer_scratch_dir = tmpdir.name
經驗回放緩衝區儲存和批次大小¶
TorchRL 經驗回放緩衝區沿第一個維度計算元素數量。由於我們將軌跡饋送到緩衝區,因此需要將緩衝區大小除以資料收集器產生的子軌跡長度進行調整。關於批次大小,我們的取樣策略將包括取樣長度為 traj_len=200 的軌跡,然後選擇長度為 random_crop_len=25 的子軌跡,並在此子軌跡上計算損失。此策略平衡了儲存特定長度的完整軌跡與為損失提供足夠異構樣本的需求。下圖顯示了一個收集器的資料流,該收集器在每個批次中獲取 8 幀,並並行執行 2 個環境,將這些資料饋送到包含 1000 條軌跡的經驗回放緩衝區,並採樣每條長度為 2 個時間步的子軌跡。
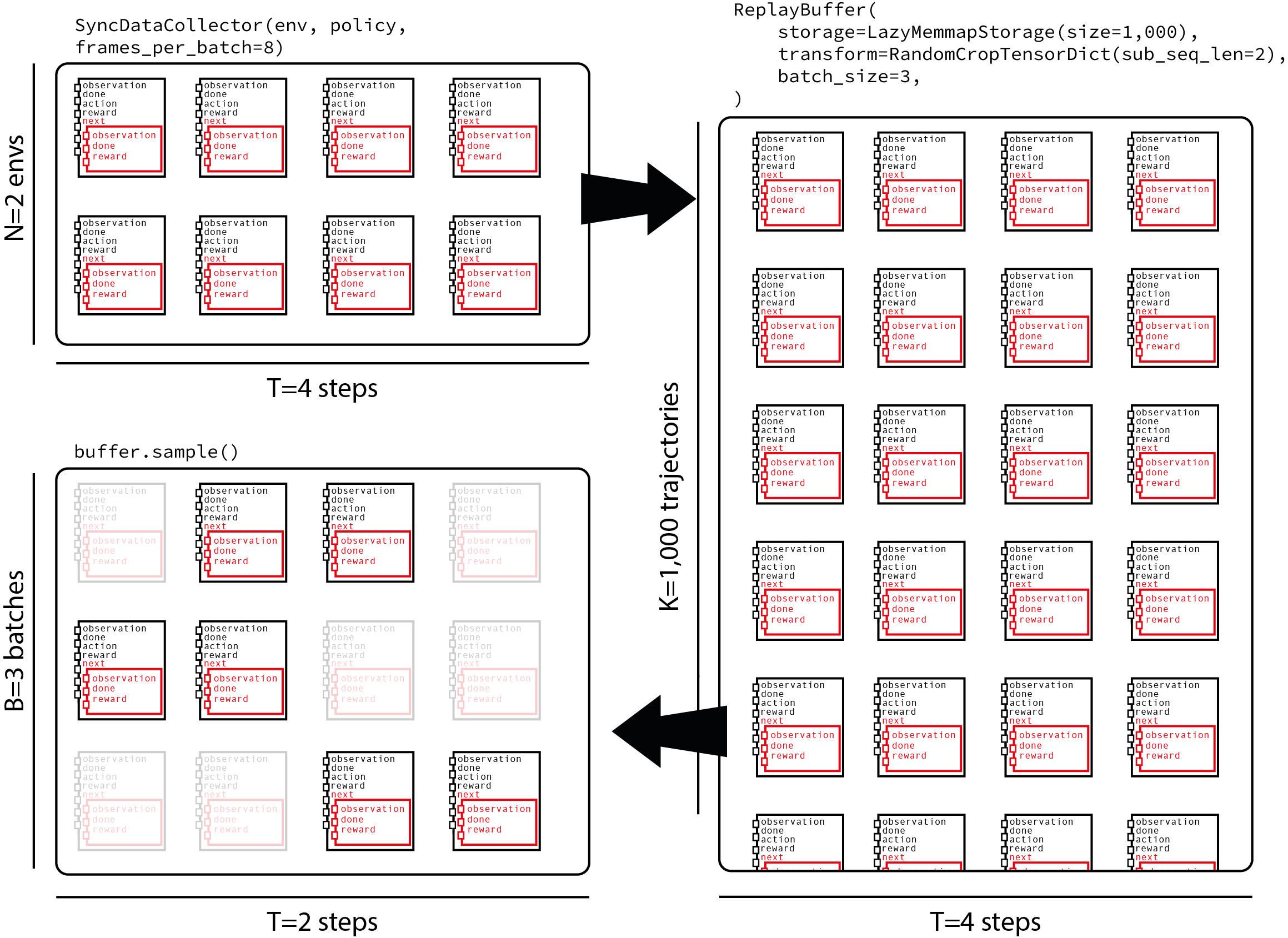
讓我們從儲存在緩衝區中的幀數開始
def ceil_div(x, y):
return -x // (-y)
buffer_size = 1_000_000
buffer_size = ceil_div(buffer_size, traj_len)
預設情況下停用優先回放緩衝區
prb = False
我們還需要定義每個收集到的資料批次要執行多少次更新。這被稱為更新-資料比率或 UTD 比率
update_to_data = 64
我們將使用長度為 25 的軌跡來訓練損失函式
random_crop_len = 25
在原論文中,作者為收集到的每一幀執行一次批次大小為 64 的更新。在這裡,我們重複相同的比率,但在每次收集批次時執行多次更新。我們調整批次大小以達到相同的每幀更新次數比率
batch_size = ceil_div(64 * frames_per_batch, update_to_data * random_crop_len)
replay_buffer = make_replay_buffer(
buffer_size=buffer_size,
batch_size=batch_size,
random_crop_len=random_crop_len,
prefetch=3,
prb=prb,
)
損失模組構建¶
我們使用剛剛建立的 actor 和 qnet 構建我們的損失模組。因為我們有目標引數需要更新,所以必須建立一個目標網路更新器。
gamma = 0.99
lmbda = 0.9
tau = 0.001 # Decay factor for the target network
loss_module = DDPGLoss(actor, qnet)
讓我們使用 TD(lambda) 估計器!
loss_module.make_value_estimator(ValueEstimators.TDLambda, gamma=gamma, lmbda=lmbda)
注意
離策略通常需要一個 TD(0) 估計器。在這裡,我們使用 TD(\(\lambda\)) 估計器,這會引入一些偏差,因為某個狀態後的軌跡是使用過時的策略收集的。這個技巧,就像資料收集期間可以使用的多步技巧一樣,是“駭客技巧”的另一種版本,我們通常發現在實踐中它們效果很好,儘管它們在回報估計中引入了一些偏差。
目標網路更新器¶
目標網路是離策略強化學習演算法的關鍵部分。得益於 HardUpdate 和 SoftUpdate 類,更新目標網路引數變得容易。它們以損失模組作為引數構建,更新透過在訓練迴圈的適當位置呼叫 updater.step() 來實現。
from torchrl.objectives.utils import SoftUpdate
target_net_updater = SoftUpdate(loss_module, eps=1 - tau)
最佳化器¶
最後,我們將對策略網路和價值網路使用 Adam 最佳化器
from torch import optim
optimizer_actor = optim.Adam(
loss_module.actor_network_params.values(True, True), lr=1e-4, weight_decay=0.0
)
optimizer_value = optim.Adam(
loss_module.value_network_params.values(True, True), lr=1e-3, weight_decay=1e-2
)
total_collection_steps = total_frames // frames_per_batch
訓練策略的時間¶
現在我們已經構建了所有需要的模組,訓練迴圈變得相當簡單。
rewards = []
rewards_eval = []
# Main loop
collected_frames = 0
pbar = tqdm.tqdm(total=total_frames)
r0 = None
for i, tensordict in enumerate(collector):
# update weights of the inference policy
collector.update_policy_weights_()
if r0 is None:
r0 = tensordict["next", "reward"].mean().item()
pbar.update(tensordict.numel())
# extend the replay buffer with the new data
current_frames = tensordict.numel()
collected_frames += current_frames
replay_buffer.extend(tensordict.cpu())
# optimization steps
if collected_frames >= init_random_frames:
for _ in range(update_to_data):
# sample from replay buffer
sampled_tensordict = replay_buffer.sample().to(device)
# Compute loss
loss_dict = loss_module(sampled_tensordict)
# optimize
loss_dict["loss_actor"].backward()
gn1 = torch.nn.utils.clip_grad_norm_(
loss_module.actor_network_params.values(True, True), 10.0
)
optimizer_actor.step()
optimizer_actor.zero_grad()
loss_dict["loss_value"].backward()
gn2 = torch.nn.utils.clip_grad_norm_(
loss_module.value_network_params.values(True, True), 10.0
)
optimizer_value.step()
optimizer_value.zero_grad()
gn = (gn1**2 + gn2**2) ** 0.5
# update priority
if prb:
replay_buffer.update_tensordict_priority(sampled_tensordict)
# update target network
target_net_updater.step()
rewards.append(
(
i,
tensordict["next", "reward"].mean().item(),
)
)
td_record = recorder(None)
if td_record is not None:
rewards_eval.append((i, td_record["r_evaluation"].item()))
if len(rewards_eval) and collected_frames >= init_random_frames:
target_value = loss_dict["target_value"].item()
loss_value = loss_dict["loss_value"].item()
loss_actor = loss_dict["loss_actor"].item()
rn = sampled_tensordict["next", "reward"].mean().item()
rs = sampled_tensordict["next", "reward"].std().item()
pbar.set_description(
f"reward: {rewards[-1][1]: 4.2f} (r0 = {r0: 4.2f}), "
f"reward eval: reward: {rewards_eval[-1][1]: 4.2f}, "
f"reward normalized={rn :4.2f}/{rs :4.2f}, "
f"grad norm={gn: 4.2f}, "
f"loss_value={loss_value: 4.2f}, "
f"loss_actor={loss_actor: 4.2f}, "
f"target value: {target_value: 4.2f}"
)
# update the exploration strategy
actor_model_explore[1].step(current_frames)
collector.shutdown()
del collector
try:
parallel_env.close()
del parallel_env
except Exception:
pass
實驗結果¶
我們繪製了一個簡單的訓練期間平均獎勵圖。我們可以觀察到,我們的策略很好地學會了解決任務。
注意
如上所述,為了獲得更合理的效能,請為 total_frames 使用更大的值,例如 1M。
from matplotlib import pyplot as plt
plt.figure()
plt.plot(*zip(*rewards), label="training")
plt.plot(*zip(*rewards_eval), label="eval")
plt.legend()
plt.xlabel("iter")
plt.ylabel("reward")
plt.tight_layout()
結論¶
在本教程中,我們學習瞭如何使用具體的 DDPG 示例在 TorchRL 中編寫損失模組的程式碼。
主要要點是
如何使用
LossModule類來編寫新的損失元件的程式碼;如何使用(或不使用)目標網路,以及如何更新其引數;
如何建立與損失模組關聯的最佳化器。
下一步¶
為了進一步迭代此損失模組,我們可以考慮
使用 @dispatch(參見 [Feature] Distpatch IQL loss module。)
允許靈活的 TensorDict 鍵。
