⚠️ 注意:有限維護¶
本專案不再積極維護。現有版本仍然可用,但沒有計劃的更新、錯誤修復、新功能或安全補丁。使用者應注意,漏洞可能不會得到解決。
多圖生成 Streamlit 應用:使用 TorchServe、torch.compile 和 OpenVINO 串聯 Llama 和 Stable Diffusion¶
此多圖生成 Streamlit 應用旨在根據提供的文字提示生成多張影像。與直接使用 Stable Diffusion 不同,此應用透過串聯 Llama 和 Stable Diffusion 來增強影像生成過程。其工作原理如下:
該應用接收使用者提示,並使用 Meta-Llama-3.2 建立多個有趣且相關的提示。
然後將這些生成的提示傳送到帶有 latent-consistency/lcm-sdxl 模型的 Stable Diffusion,以生成影像。
為了最佳化效能,模型使用 採用 OpenVINO 後端的 torch.compile 進行編譯。
該應用利用 TorchServe 實現高效的模型服務和管理。
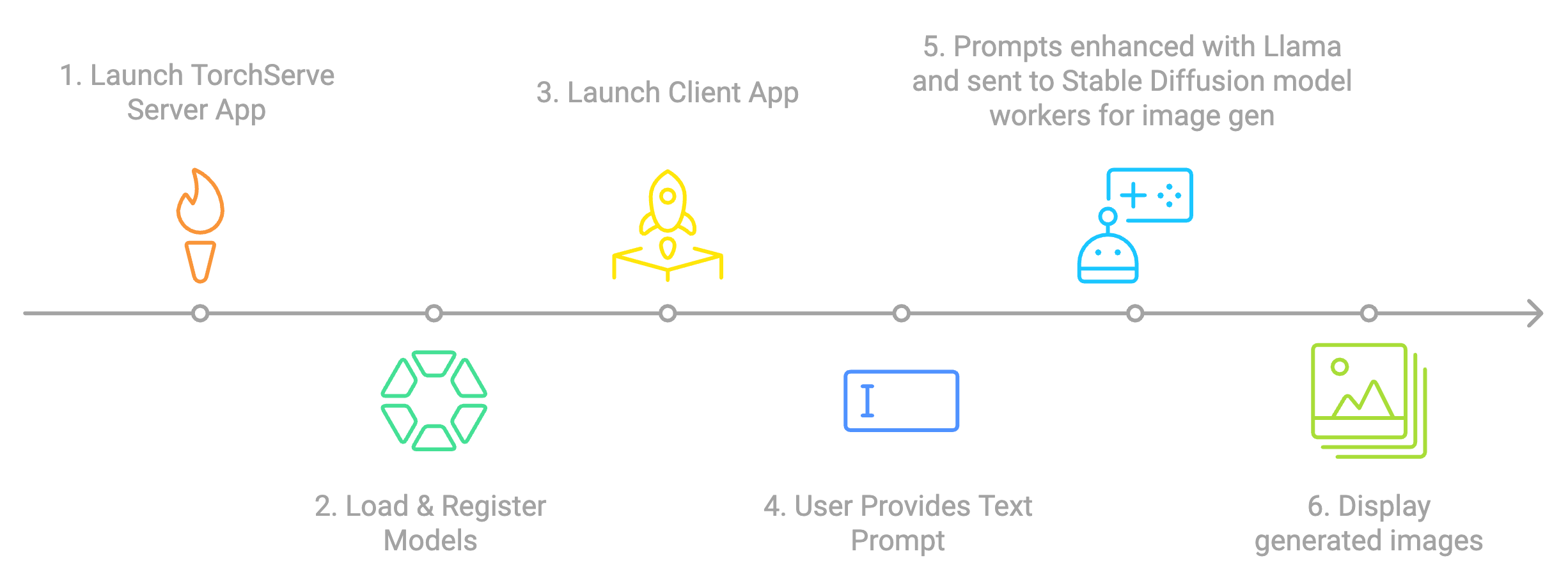
快速入門指南¶
先決條件:
您的系統上已安裝 Docker
Hugging Face 令牌:建立一個 Hugging Face 賬戶並獲取一個能夠訪問 meta-llama/Llama-3.2-3B-Instruct 模型的令牌。
要啟動多圖生成應用,請按照以下步驟操作:
# 1: Set HF Token as Env variable
export HUGGINGFACE_TOKEN=<HUGGINGFACE_TOKEN>
# 2: Build Docker image for this Multi-Image Generation App
git clone https://github.com/pytorch/serve.git
cd serve
./examples/usecases/llm_diffusion_serving_app/docker/build_image.sh
# 3: Launch the streamlit app for server & client
# After the Docker build is successful, you will see a "docker run" command printed to the console.
# Run that "docker run" command to launch the Streamlit app for both the server and client.
Docker 構建示例輸出:¶
ubuntu@ip-10-0-0-137:~/serve$ ./examples/usecases/llm_diffusion_serving_app/docker/build_image.sh
EXAMPLE_DIR: .//examples/usecases/llm_diffusion_serving_app/docker
ROOT_DIR: /home/ubuntu/serve
DOCKER_BUILDKIT=1 docker buildx build --platform=linux/amd64 --file .//examples/usecases/llm_diffusion_serving_app/docker/Dockerfile --build-arg BASE_IMAGE="pytorch/torchserve:latest-cpu" --build-arg EXAMPLE_DIR=".//examples/usecases/llm_diffusion_serving_app/docker" --build-arg HUGGINGFACE_TOKEN=hf_<token> --build-arg HTTP_PROXY= --build-arg HTTPS_PROXY= --build-arg NO_PROXY= -t "pytorch/torchserve:llm_diffusion_serving_app" .
[+] Building 1.4s (18/18) FINISHED docker:default
=> [internal] load .dockerignore 0.0s
.
.
.
=> => naming to docker.io/pytorch/torchserve:llm_diffusion_serving_app 0.0s
Docker Build Successful !
............................ Next Steps ............................
--------------------------------------------------------------------
[Optional] Run the following command to benchmark Stable Diffusion:
--------------------------------------------------------------------
docker run --rm --platform linux/amd64 \
--name llm_sd_app_bench \
-v /home/ubuntu/serve/model-store-local:/home/model-server/model-store \
--entrypoint python \
pytorch/torchserve:llm_diffusion_serving_app \
/home/model-server/llm_diffusion_serving_app/sd-benchmark.py -ni 3
-------------------------------------------------------------------
Run the following command to start the Multi-Image generation App:
-------------------------------------------------------------------
docker run --rm -it --platform linux/amd64 \
--name llm_sd_app \
-p 127.0.0.1:8080:8080 \
-p 127.0.0.1:8081:8081 \
-p 127.0.0.1:8082:8082 \
-p 127.0.0.1:8084:8084 \
-p 127.0.0.1:8085:8085 \
-v /home/ubuntu/serve/model-store-local:/home/model-server/model-store \
-e MODEL_NAME_LLM=meta-llama/Llama-3.2-3B-Instruct \
-e MODEL_NAME_SD=stabilityai/stable-diffusion-xl-base-1.0 \
pytorch/torchserve:llm_diffusion_serving_app
Note: You can replace the model identifiers (MODEL_NAME_LLM, MODEL_NAME_SD) as needed.
預期結果¶
在成功構建後,使用顯示的 docker run .. 命令啟動 Docker 容器後,您可以訪問兩個獨立的 Streamlit 應用:
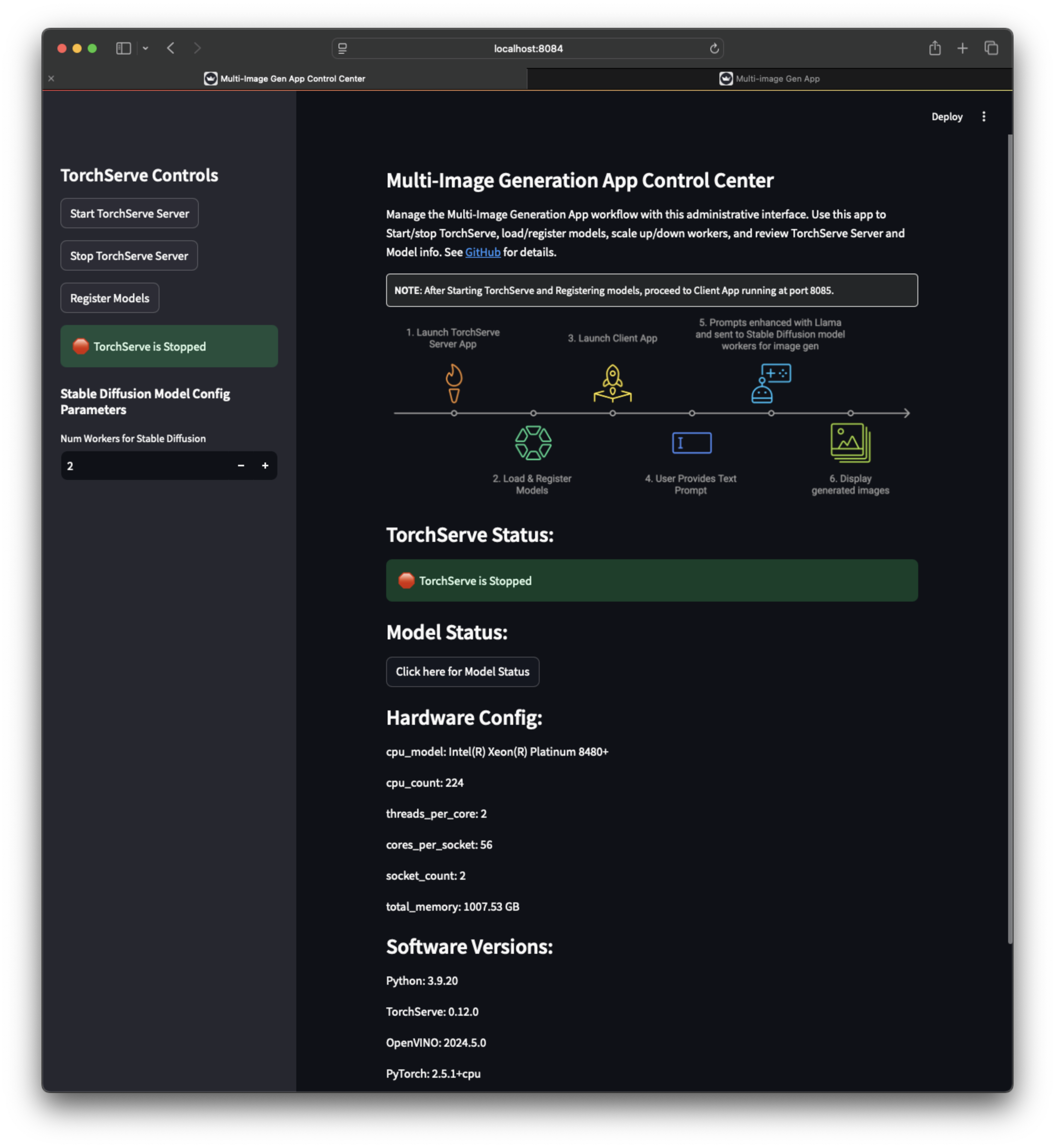
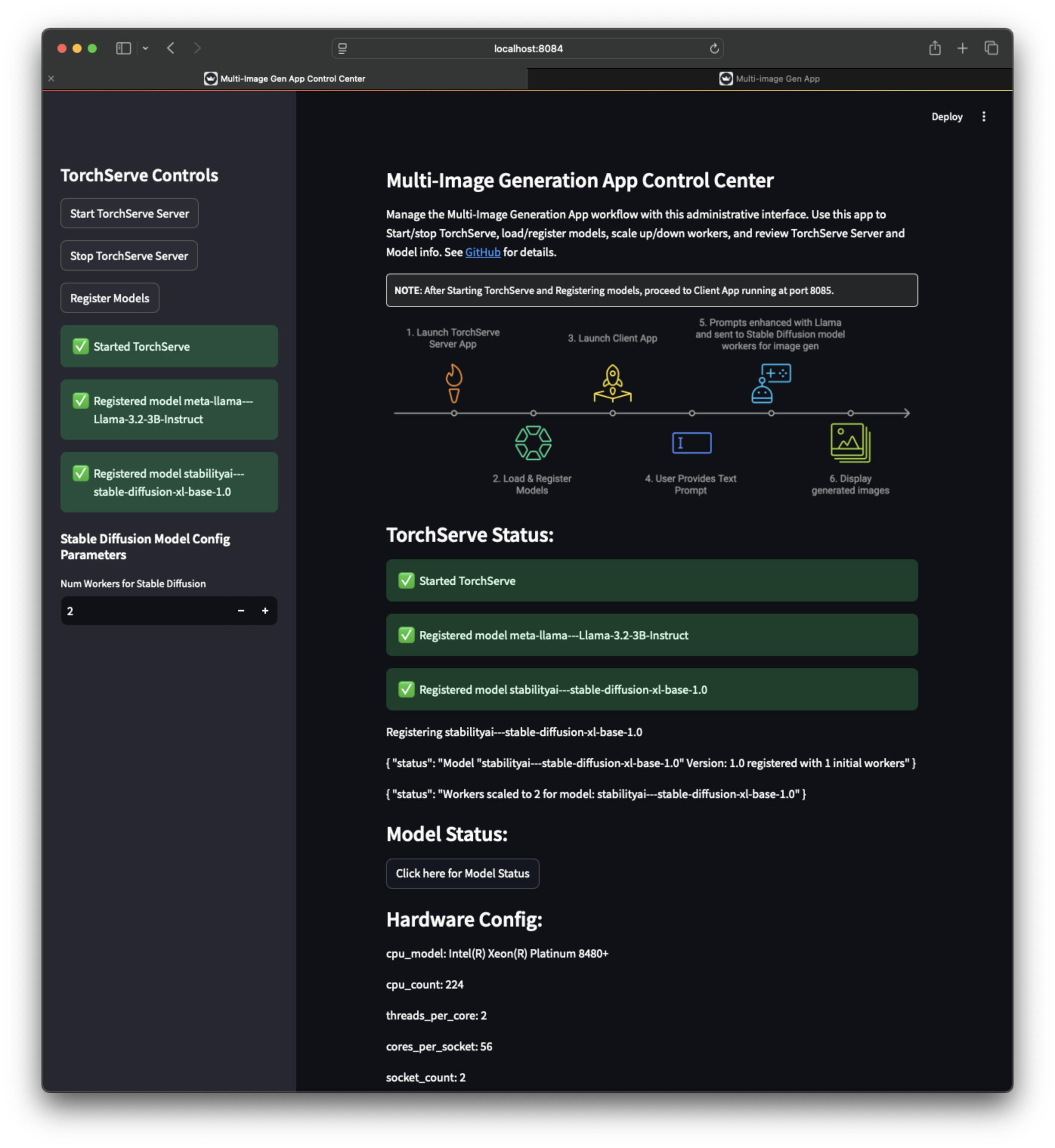
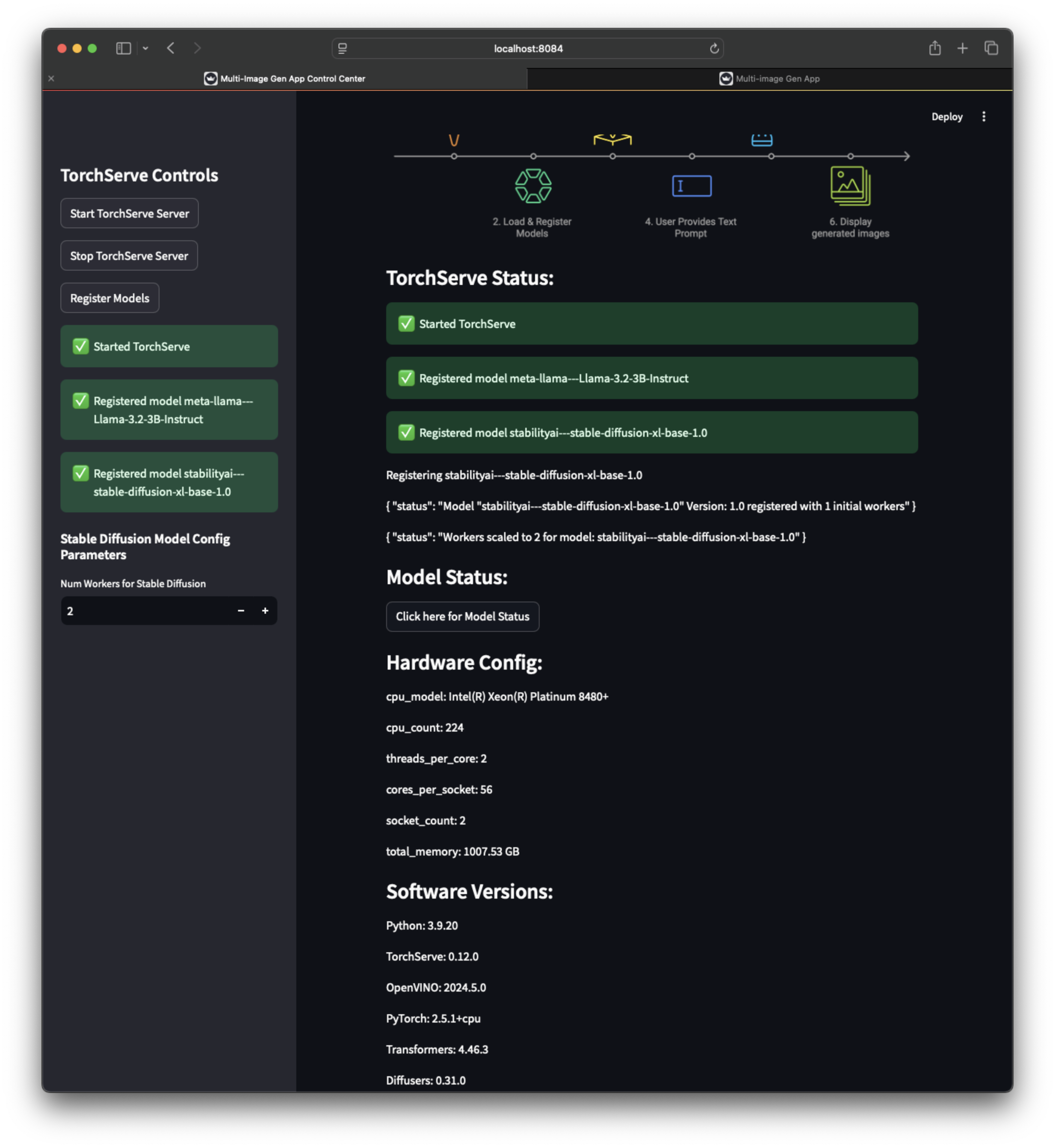
TorchServe 伺服器應用(執行在 https://:8084),用於啟動/停止 TorchServe、載入/註冊模型、擴充套件/縮減工作程序。
客戶端應用(執行在 https://:8085),您可以在其中輸入提示詞進行影像生成。
注意:您還可以執行一個快速基準測試,比較 Stable Diffusion 在 Eager 模式、使用 inductor 的 torch.compile 和 openvino 後端下的效能。請檢視成功構建後顯示的
docker run ..命令以進行基準測試。
啟動應用示例輸出:¶
ubuntu@ip-10-0-0-137:~/serve$ docker run --rm -it --platform linux/amd64 \
--name llm_sd_app \
-p 127.0.0.1:8080:8080 \
-p 127.0.0.1:8081:8081 \
-p 127.0.0.1:8082:8082 \
-p 127.0.0.1:8084:8084 \
-p 127.0.0.1:8085:8085 \
-v /home/ubuntu/serve/model-store-local:/home/model-server/model-store \
-e MODEL_NAME_LLM=meta-llama/Llama-3.2-3B-Instruct \
-e MODEL_NAME_SD=stabilityai/stable-diffusion-xl-base-1.0 \
pytorch/torchserve:llm_diffusion_serving_app
Preparing meta-llama/Llama-3.2-1B-Instruct
/home/model-server/llm_diffusion_serving_app/llm /home/model-server/llm_diffusion_serving_app
Model meta-llama---Llama-3.2-1B-Instruct already downloaded.
Model archive for meta-llama---Llama-3.2-1B-Instruct exists.
/home/model-server/llm_diffusion_serving_app
Preparing stabilityai/stable-diffusion-xl-base-1.0
/home/model-server/llm_diffusion_serving_app/sd /home/model-server/llm_diffusion_serving_app
Model stabilityai/stable-diffusion-xl-base-1.0 already downloaded
Model archive for stabilityai---stable-diffusion-xl-base-1.0 exists.
/home/model-server/llm_diffusion_serving_app
Collecting usage statistics. To deactivate, set browser.gatherUsageStats to false.
Collecting usage statistics. To deactivate, set browser.gatherUsageStats to false.
You can now view your Streamlit app in your browser.
Local URL: https://:8085
Network URL: http://123.11.0.2:8085
External URL: http://123.123.12.34:8085
You can now view your Streamlit app in your browser.
Local URL: https://:8084
Network URL: http://123.11.0.2:8084
External URL: http://123.123.12.34:8084
Stable Diffusion 基準測試示例輸出:¶
要執行 Stable Diffusion 基準測試,請使用 sd-benchmark.py。有關示例控制檯輸出的詳細資訊,請參閱下文。
ubuntu@ip-10-0-0-137:~/serve$ docker run --rm --platform linux/amd64 \
--name llm_sd_app_bench \
-v /home/ubuntu/serve/model-store-local:/home/model-server/model-store \
--entrypoint python \
pytorch/torchserve:llm_diffusion_serving_app \
/home/model-server/llm_diffusion_serving_app/sd-benchmark.py -ni 3
.
.
.
Hardware Info:
--------------------------------------------------------------------------------
cpu_model: Intel(R) Xeon(R) Platinum 8488C
cpu_count: 64
threads_per_core: 2
cores_per_socket: 32
socket_count: 1
total_memory: 247.71 GB
Software Versions:
--------------------------------------------------------------------------------
Python: 3.9.20
TorchServe: 0.12.0
OpenVINO: 2024.5.0
PyTorch: 2.5.1+cpu
Transformers: 4.46.3
Diffusers: 0.31.0
Benchmark Summary:
--------------------------------------------------------------------------------
+-------------+----------------+---------------------------+
| Run Mode | Warm-up Time | Average Time for 3 iter |
+=============+================+===========================+
| eager | 11.25 seconds | 10.13 +/- 0.02 seconds |
+-------------+----------------+---------------------------+
| tc_inductor | 85.40 seconds | 8.85 +/- 0.03 seconds |
+-------------+----------------+---------------------------+
| tc_openvino | 52.57 seconds | 2.58 +/- 0.04 seconds |
+-------------+----------------+---------------------------+
Results saved in directory: /home/model-server/model-store/benchmark_results_20241123_071103
Files in the /home/model-server/model-store/benchmark_results_20241123_071103 directory:
benchmark_results.json
image-eager-final.png
image-tc_inductor-final.png
image-tc_openvino-final.png
Results saved at /home/model-server/model-store/ which is a Docker container mount, corresponds to 'serve/model-store-local/' on the host machine.
帶效能分析的 Stable Diffusion 基準測試示例輸出:¶
要執行帶效能分析的 Stable Diffusion 基準測試,請使用 --run_profiling 或 -rp。有關示例控制檯輸出的詳細資訊,請參閱下文。示例效能分析基準測試輸出檔案可在 assets/benchmark_results_20241123_044407/ 中找到。
ubuntu@ip-10-0-0-137:~/serve$ docker run --rm --platform linux/amd64 \
--name llm_sd_app_bench \
-v /home/ubuntu/serve/model-store-local:/home/model-server/model-store \
--entrypoint python \
pytorch/torchserve:llm_diffusion_serving_app \
/home/model-server/llm_diffusion_serving_app/sd-benchmark.py -rp
.
.
.
Hardware Info:
--------------------------------------------------------------------------------
cpu_model: Intel(R) Xeon(R) Platinum 8488C
cpu_count: 64
threads_per_core: 2
cores_per_socket: 32
socket_count: 1
total_memory: 247.71 GB
Software Versions:
--------------------------------------------------------------------------------
Python: 3.9.20
TorchServe: 0.12.0
OpenVINO: 2024.5.0
PyTorch: 2.5.1+cpu
Transformers: 4.46.3
Diffusers: 0.31.0
Benchmark Summary:
--------------------------------------------------------------------------------
+-------------+----------------+---------------------------+
| Run Mode | Warm-up Time | Average Time for 1 iter |
+=============+================+===========================+
| eager | 9.33 seconds | 8.57 +/- 0.00 seconds |
+-------------+----------------+---------------------------+
| tc_inductor | 81.11 seconds | 7.20 +/- 0.00 seconds |
+-------------+----------------+---------------------------+
| tc_openvino | 50.76 seconds | 1.72 +/- 0.00 seconds |
+-------------+----------------+---------------------------+
Results saved in directory: /home/model-server/model-store/benchmark_results_20241123_071629
Files in the /home/model-server/model-store/benchmark_results_20241123_071629 directory:
benchmark_results.json
image-eager-final.png
image-tc_inductor-final.png
image-tc_openvino-final.png
profile-eager.txt
profile-tc_inductor.txt
profile-tc_openvino.txt
num_iter is set to 1 as run_profiling flag is enabled !
Results saved at /home/model-server/model-store/ which is a Docker container mount, corresponds to 'serve/model-store-local/' on the host machine.
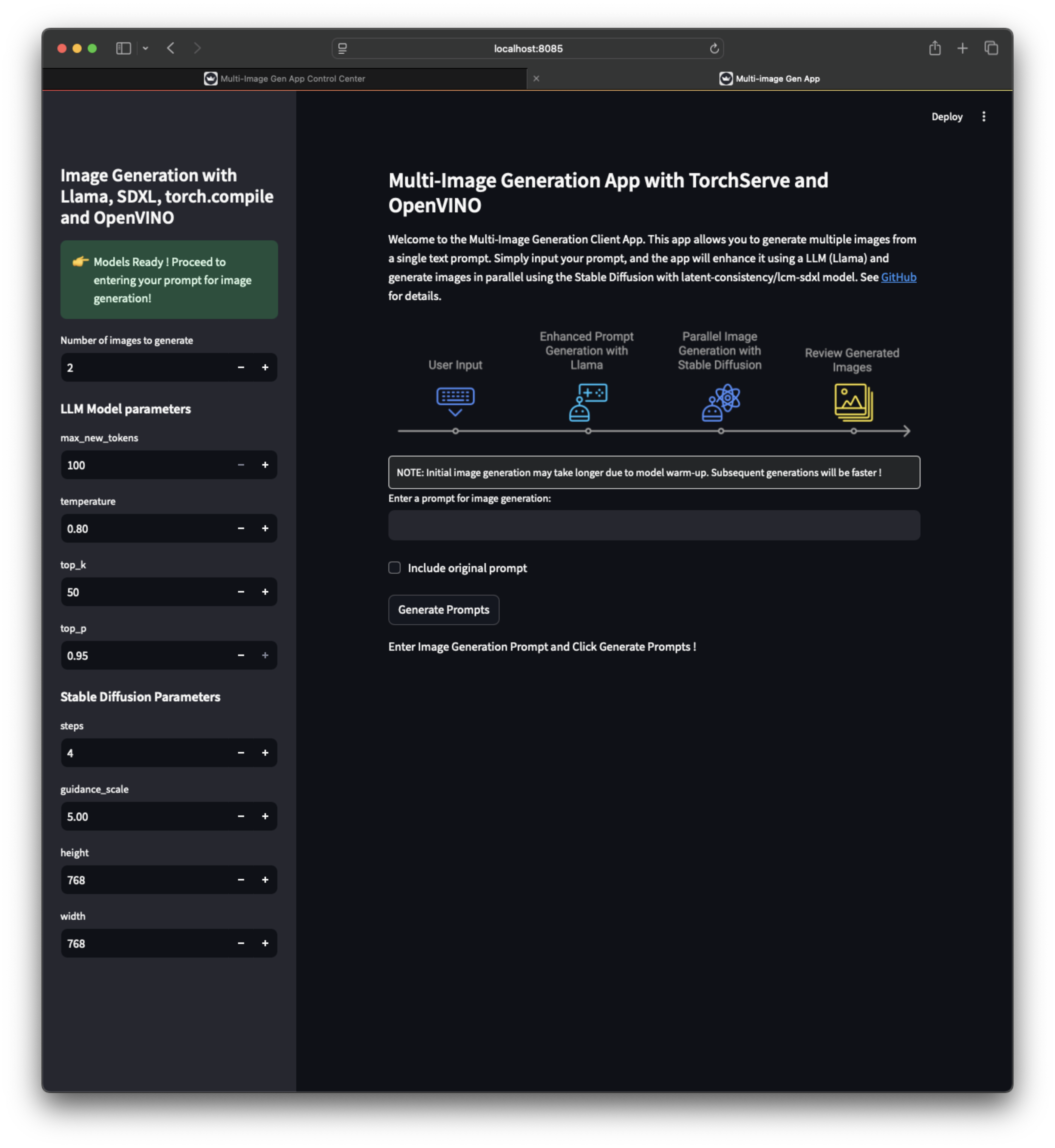
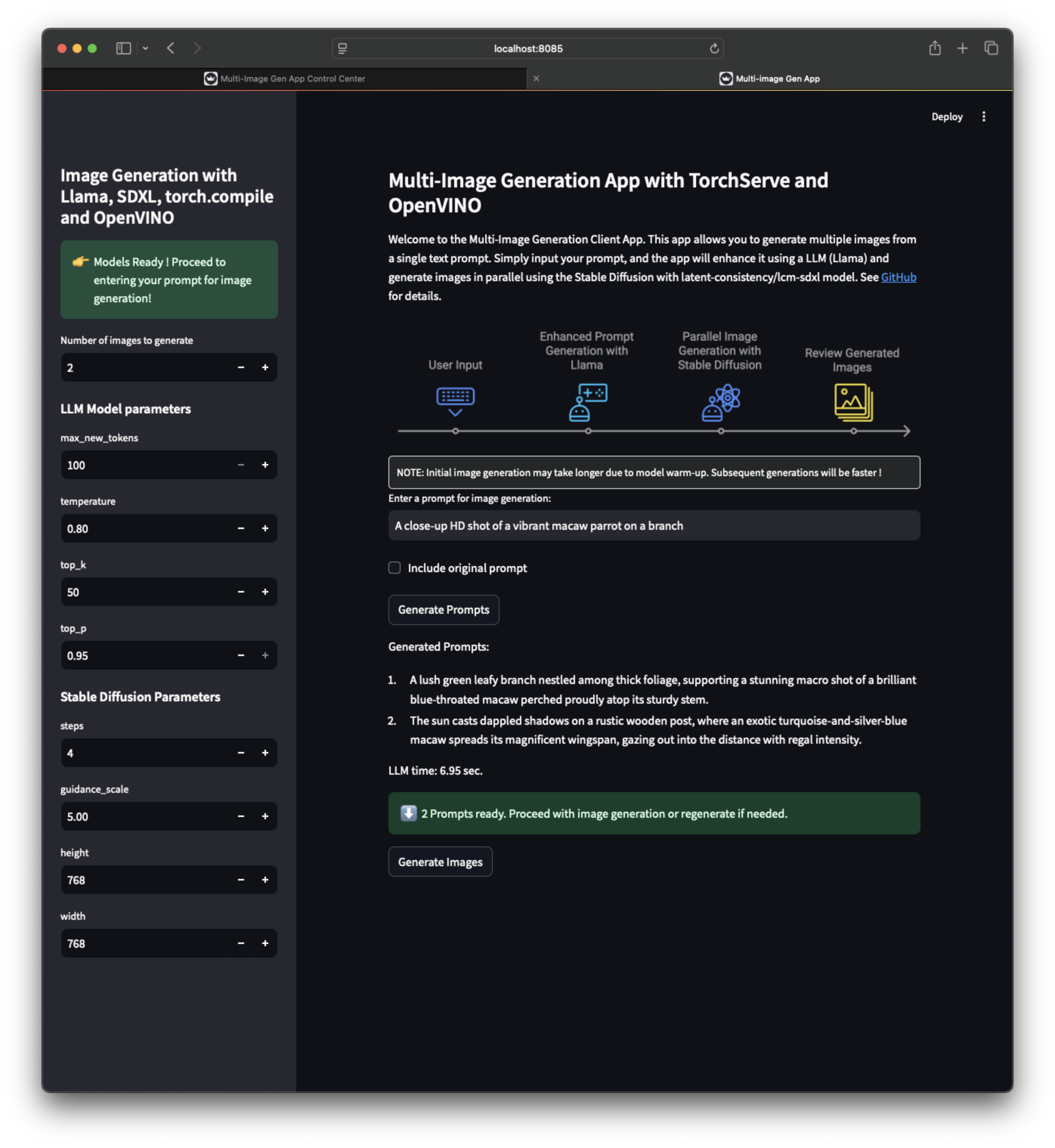
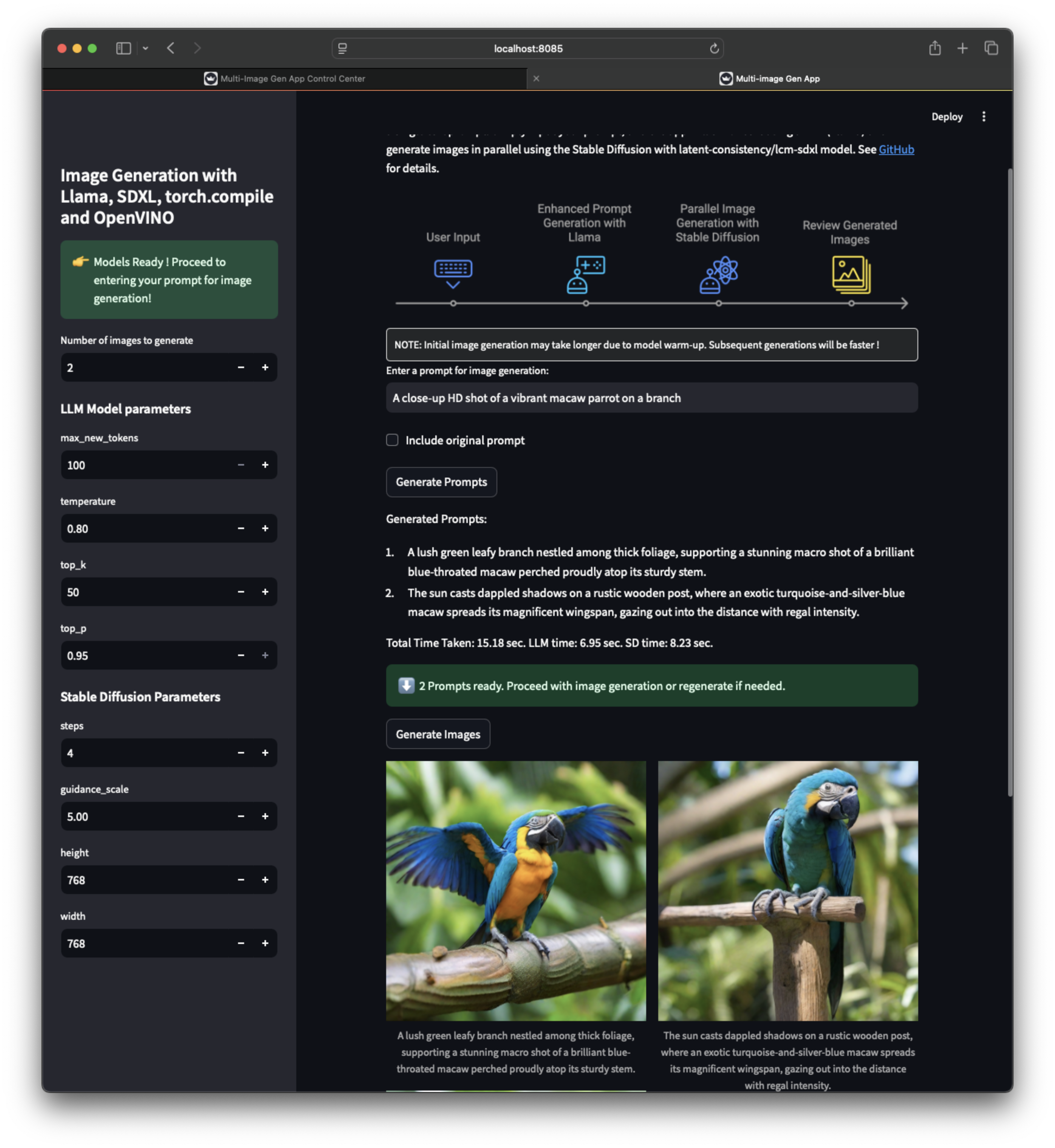
多圖生成應用 UI¶
應用工作流¶
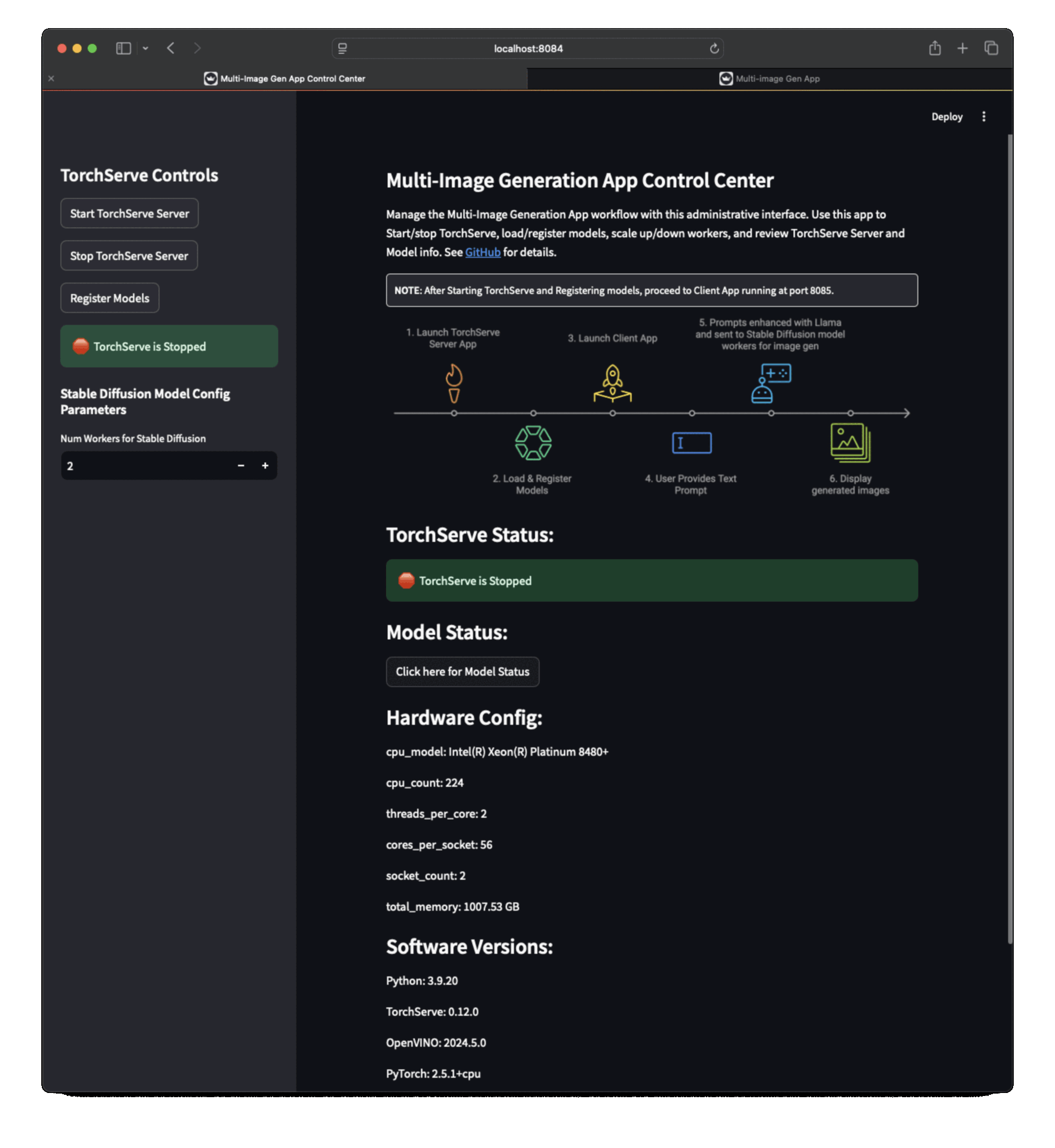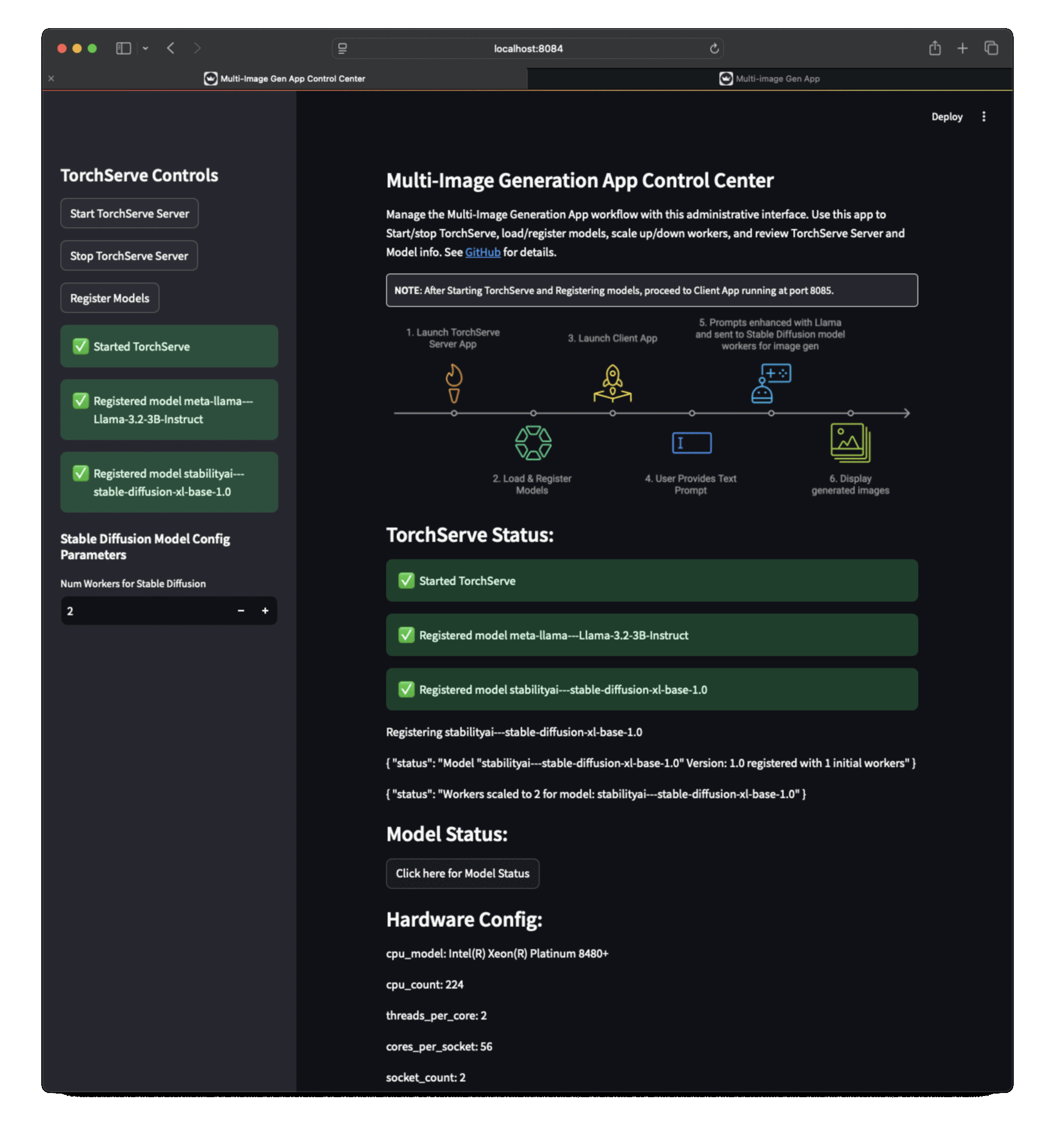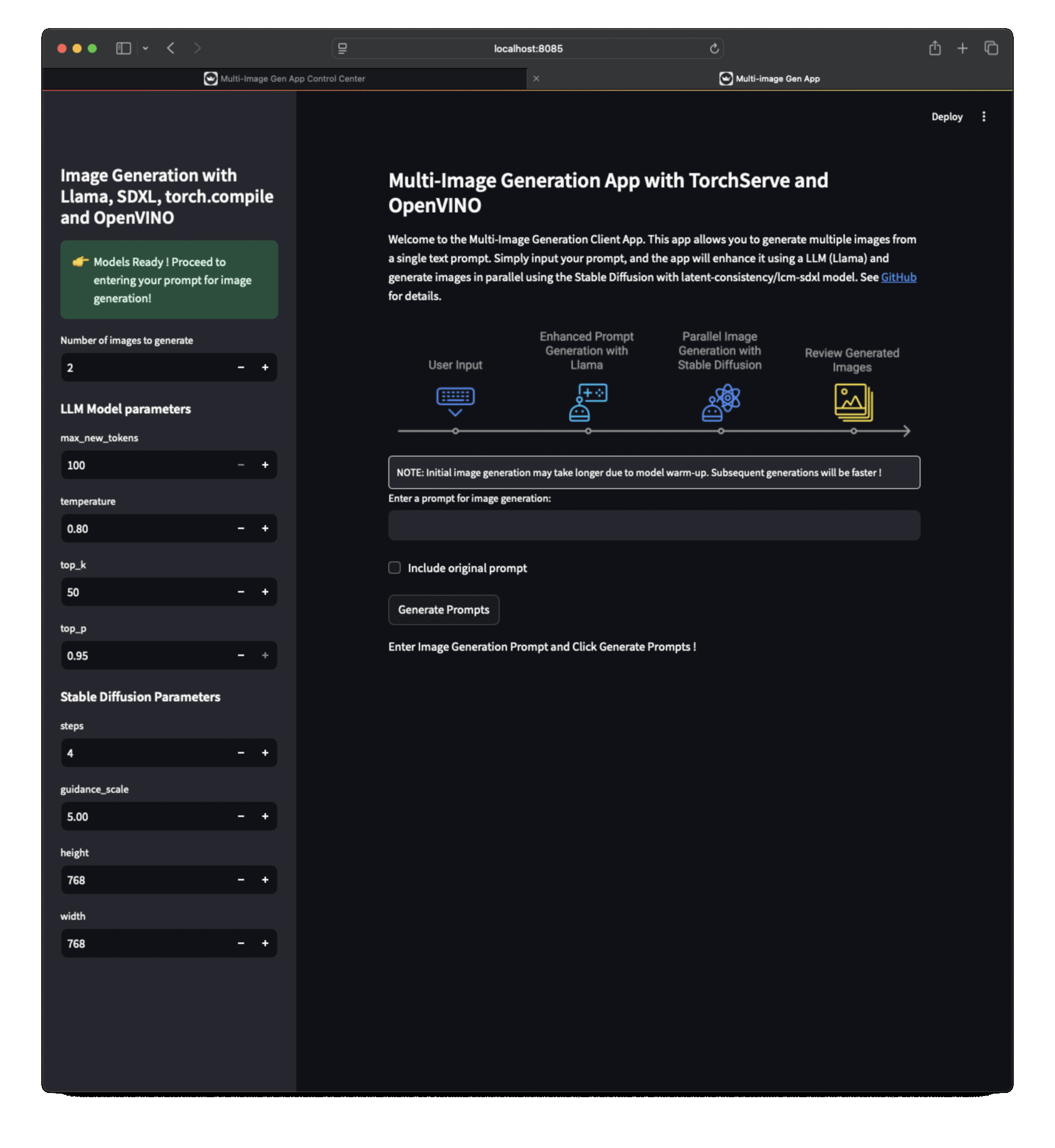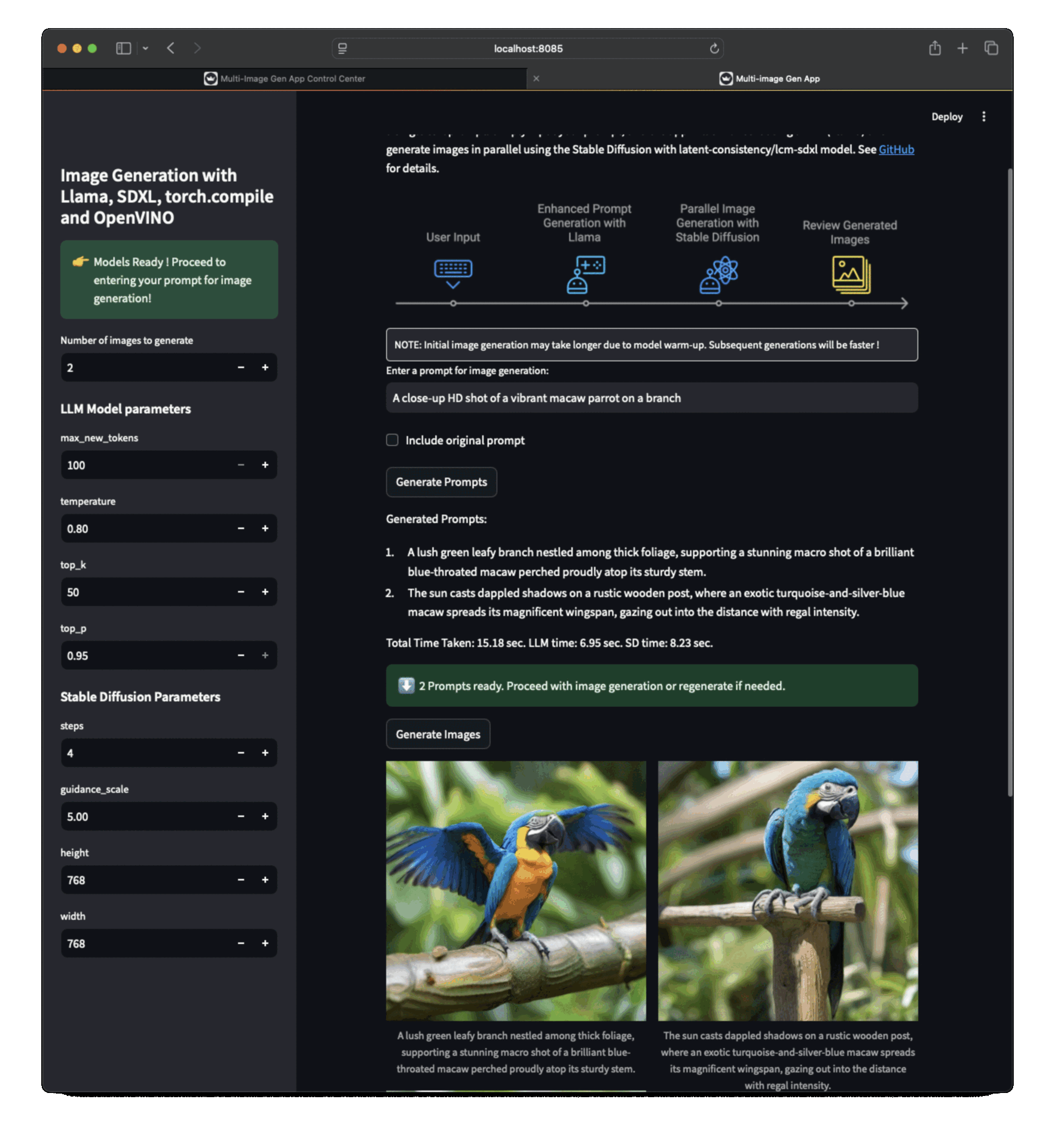
應用截圖¶
| 伺服器應用截圖 1 | 伺服器應用截圖 2 | 伺服器應用截圖 3 |
|---|---|---|
 |
 |
 |
| 客戶端應用截圖 1 | 客戶端應用截圖 2 | 客戶端應用截圖 3 |
|---|---|---|
 |
 |
 |
