torch.utils.tensorboard¶
在繼續之前,可以在 https://www.tensorflow.org/tensorboard/ 找到更多關於 TensorBoard 的詳細資訊
安裝 TensorBoard 後,這些工具函式允許您將 PyTorch 模型和指標記錄到目錄中,以便在 TensorBoard UI 中進行視覺化。支援 PyTorch 模型和張量以及 Caffe2 網路和 blob 的標量、影像、直方圖、圖表和嵌入視覺化。
SummaryWriter 類是您記錄資料供 TensorBoard 消費和視覺化的主要入口。例如
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
from torchvision import datasets, transforms
# Writer will output to ./runs/ directory by default
writer = SummaryWriter()
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
trainset = datasets.MNIST('mnist_train', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
model = torchvision.models.resnet50(False)
# Have ResNet model take in grayscale rather than RGB
model.conv1 = torch.nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False)
images, labels = next(iter(trainloader))
grid = torchvision.utils.make_grid(images)
writer.add_image('images', grid, 0)
writer.add_graph(model, images)
writer.close()
然後可以使用 TensorBoard 對其進行視覺化,TensorBoard 可以透過以下方式安裝和執行
pip install tensorboard
tensorboard --logdir=runs
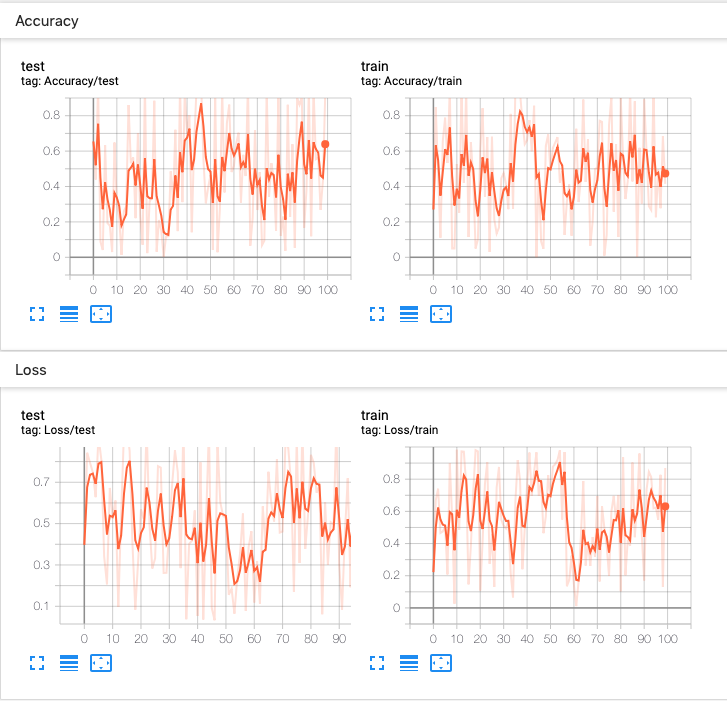
一個實驗可以記錄很多資訊。為了避免 UI 混亂並更好地對結果進行聚類,我們可以透過分層命名來對圖表進行分組。例如,“Loss/train” 和 “Loss/test” 將被分在一組,而 “Accuracy/train” 和 “Accuracy/test” 將在 TensorBoard 介面中單獨分組。
from torch.utils.tensorboard import SummaryWriter
import numpy as np
writer = SummaryWriter()
for n_iter in range(100):
writer.add_scalar('Loss/train', np.random.random(), n_iter)
writer.add_scalar('Loss/test', np.random.random(), n_iter)
writer.add_scalar('Accuracy/train', np.random.random(), n_iter)
writer.add_scalar('Accuracy/test', np.random.random(), n_iter)
預期結果
- class torch.utils.tensorboard.writer.SummaryWriter(log_dir=None, comment='', purge_step=None, max_queue=10, flush_secs=120, filename_suffix='')[source][source]¶
將條目直接寫入 log_dir 中的事件檔案,供 TensorBoard 消費。
SummaryWriter 類提供了一個高階 API,用於在給定目錄中建立事件檔案並向其中新增摘要和事件。該類非同步更新檔案內容。這使得訓練程式可以直接從訓練迴圈中呼叫方法向檔案新增資料,而不會減慢訓練速度。
- __init__(log_dir=None, comment='', purge_step=None, max_queue=10, flush_secs=120, filename_suffix='')[source][source]¶
建立一個 SummaryWriter,它將事件和摘要寫入事件檔案。
- 引數
log_dir (str) – 儲存目錄位置。預設值為 runs/CURRENT_DATETIME_HOSTNAME,每次執行時都會更改。使用分層資料夾結構可以輕鬆比較不同執行。例如,對於每個新實驗,傳入 ‘runs/exp1’、‘runs/exp2’ 等以進行比較。
comment (str) – 註釋 log_dir 字尾,附加到預設的
log_dir。如果log_dir已指定,此引數無效。purge_step (int) – 當日志記錄在步驟 崩潰並在步驟 重啟時,任何 global_step 大於或等於 的事件都將被清除並隱藏在 TensorBoard 中。請注意,崩潰後恢復的實驗應具有相同的
log_dir。max_queue (int) – 待處理事件和摘要的佇列大小,在某個 'add' 呼叫強制重新整理到磁碟之前。預設是十項。
flush_secs (int) – 將待處理事件和摘要重新整理到磁碟的頻率,以秒為單位。預設是每兩分鐘。
filename_suffix (str) – 新增到 log_dir 目錄中所有事件檔名中的字尾。更多檔名構建細節參見 tensorboard.summary.writer.event_file_writer.EventFileWriter。
示例
from torch.utils.tensorboard import SummaryWriter # create a summary writer with automatically generated folder name. writer = SummaryWriter() # folder location: runs/May04_22-14-54_s-MacBook-Pro.local/ # create a summary writer using the specified folder name. writer = SummaryWriter("my_experiment") # folder location: my_experiment # create a summary writer with comment appended. writer = SummaryWriter(comment="LR_0.1_BATCH_16") # folder location: runs/May04_22-14-54_s-MacBook-Pro.localLR_0.1_BATCH_16/
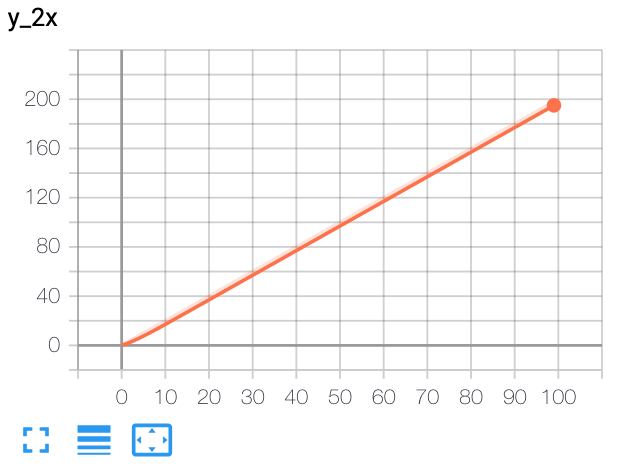
- add_scalar(tag, scalar_value, global_step=None, walltime=None, new_style=False, double_precision=False)[source][source]¶
向摘要新增標量資料。
- 引數
示例
from torch.utils.tensorboard import SummaryWriter writer = SummaryWriter() x = range(100) for i in x: writer.add_scalar('y=2x', i * 2, i) writer.close()
預期結果
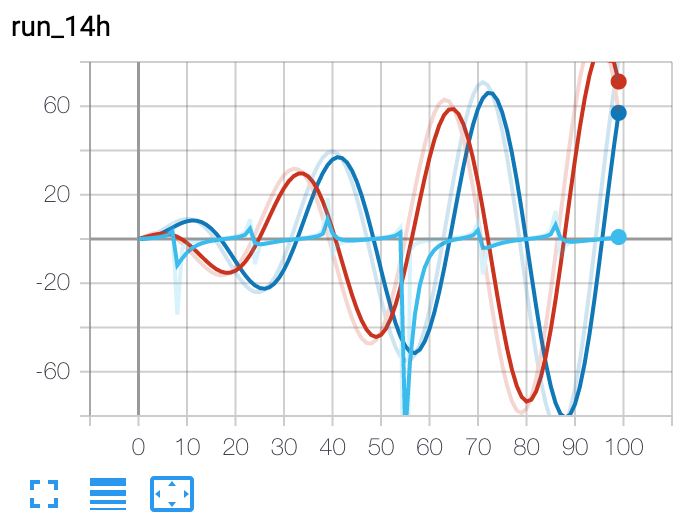
- add_scalars(main_tag, tag_scalar_dict, global_step=None, walltime=None)[source][source]¶
向摘要新增多個標量資料。
- 引數
示例
from torch.utils.tensorboard import SummaryWriter writer = SummaryWriter() r = 5 for i in range(100): writer.add_scalars('run_14h', {'xsinx':i*np.sin(i/r), 'xcosx':i*np.cos(i/r), 'tanx': np.tan(i/r)}, i) writer.close() # This call adds three values to the same scalar plot with the tag # 'run_14h' in TensorBoard's scalar section.
預期結果
- add_histogram(tag, values, global_step=None, bins='tensorflow', walltime=None, max_bins=None)[source][source]¶
向摘要新增直方圖。
- 引數
tag (str) – 資料識別符號
values (torch.Tensor, numpy.ndarray, 或 string/blobname) – 構建直方圖的值
global_step (int) – 要記錄的全域性步驟值
bins (str) – {‘tensorflow’,’auto’, ‘fd’, …} 之一。這決定了如何建立 bin。您可以在以下連結中找到其他選項:https://docs.scipy.org/doc/numpy/reference/generated/numpy.histogram.html
walltime (float) – 可選地覆蓋預設 walltime (time.time()),使用事件的 epoch 後秒數
示例
from torch.utils.tensorboard import SummaryWriter import numpy as np writer = SummaryWriter() for i in range(10): x = np.random.random(1000) writer.add_histogram('distribution centers', x + i, i) writer.close()
預期結果
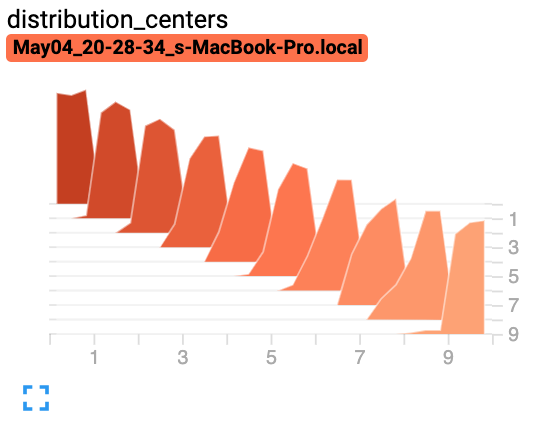
- add_image(tag, img_tensor, global_step=None, walltime=None, dataformats='CHW')[source][source]¶
向摘要新增影像資料。
請注意,這需要安裝
pillow包。- 引數
tag (str) – 資料識別符號
img_tensor (torch.Tensor, numpy.ndarray, 或 string/blobname) – 影像資料
global_step (int) – 要記錄的全域性步驟值
walltime (float) – 可選地覆蓋預設 walltime (time.time()),使用事件的 epoch 後秒數
dataformats (str) – 影像資料格式規範,形式為 CHW、HWC、HW、WH 等。
- 形狀
img_tensor: 預設形狀是 。您可以使用
torchvision.utils.make_grid()將批張量轉換為 3xHxW 格式,或呼叫add_images並讓我們來處理。形狀為 、、 的張量也適用,只要傳遞相應的dataformats引數即可,例如CHW、HWC、HW。
示例
from torch.utils.tensorboard import SummaryWriter import numpy as np img = np.zeros((3, 100, 100)) img[0] = np.arange(0, 10000).reshape(100, 100) / 10000 img[1] = 1 - np.arange(0, 10000).reshape(100, 100) / 10000 img_HWC = np.zeros((100, 100, 3)) img_HWC[:, :, 0] = np.arange(0, 10000).reshape(100, 100) / 10000 img_HWC[:, :, 1] = 1 - np.arange(0, 10000).reshape(100, 100) / 10000 writer = SummaryWriter() writer.add_image('my_image', img, 0) # If you have non-default dimension setting, set the dataformats argument. writer.add_image('my_image_HWC', img_HWC, 0, dataformats='HWC') writer.close()
預期結果
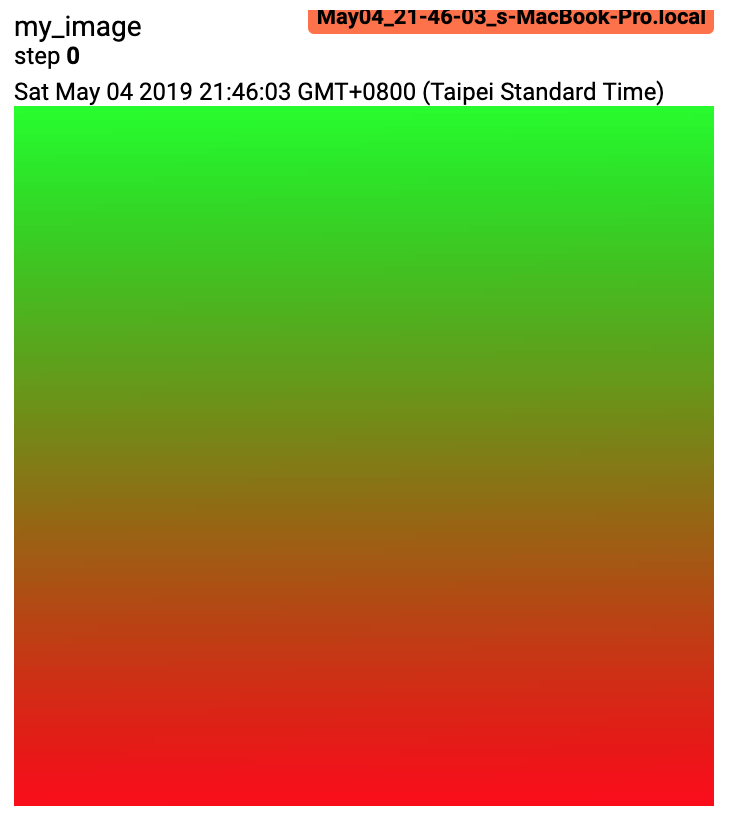
- add_images(tag, img_tensor, global_step=None, walltime=None, dataformats='NCHW')[source][source]¶
向摘要新增批影像資料。
請注意,這需要安裝
pillow包。- 引數
tag (str) – 資料識別符號
img_tensor (torch.Tensor, numpy.ndarray, 或 string/blobname) – 影像資料
global_step (int) – 要記錄的全域性步驟值
walltime (float) – 可選地覆蓋預設 walltime (time.time()),使用事件的 epoch 後秒數
dataformats (str) – 影像資料格式規範,形式為 NCHW、NHWC、CHW、HWC、HW、WH 等。
- 形狀
img_tensor: 預設形狀是 。如果指定了
dataformats,其他形狀也將被接受。例如 NCHW 或 NHWC。
示例
from torch.utils.tensorboard import SummaryWriter import numpy as np img_batch = np.zeros((16, 3, 100, 100)) for i in range(16): img_batch[i, 0] = np.arange(0, 10000).reshape(100, 100) / 10000 / 16 * i img_batch[i, 1] = (1 - np.arange(0, 10000).reshape(100, 100) / 10000) / 16 * i writer = SummaryWriter() writer.add_images('my_image_batch', img_batch, 0) writer.close()
預期結果

- add_figure(tag, figure, global_step=None, close=True, walltime=None)[source][source]¶
將 matplotlib 圖形渲染為影像並將其新增到摘要中。
請注意,這需要安裝
matplotlib包。
- add_video(tag, vid_tensor, global_step=None, fps=4, walltime=None)[source][source]¶
向摘要新增影片資料。
請注意,這需要安裝
moviepy包。- 引數
- 形狀
vid_tensor: 。對於 uint8 型別,值應在 [0, 255] 範圍內;對於 float 型別,值應在 [0, 1] 範圍內。
- add_audio(tag, snd_tensor, global_step=None, sample_rate=44100, walltime=None)[source][source]¶
將音訊資料新增到摘要。
- 引數
tag (str) – 資料識別符號
snd_tensor (torch.Tensor) – 聲音資料
global_step (int) – 要記錄的全域性步驟值
sample_rate (int) – 取樣率,單位為 Hz
walltime (float) – 可選地覆蓋預設 walltime (time.time()),使用事件的 epoch 後秒數
- 形狀
snd_tensor: 。值應介於 [-1, 1] 之間。
- add_text(tag, text_string, global_step=None, walltime=None)[source][source]¶
將文字資料新增到摘要。
- 引數
示例
writer.add_text('lstm', 'This is an lstm', 0) writer.add_text('rnn', 'This is an rnn', 10)
- add_graph(model, input_to_model=None, verbose=False, use_strict_trace=True)[source][source]¶
將圖資料新增到摘要。
- 引數
model (torch.nn.Module) – 要繪製的模型。
input_to_model (torch.Tensor or list of torch.Tensor) – 要輸入的一個變數或一個變數元組。
verbose (bool) – 是否在控制檯中列印圖結構。
use_strict_trace (bool) – 是否將關鍵字引數 strict 傳遞給 torch.jit.trace。如果你希望追蹤器記錄你的可變容器型別(列表、字典),則傳遞 False
- add_embedding(mat, metadata=None, label_img=None, global_step=None, tag='default', metadata_header=None)[source][source]¶
將嵌入投影儀資料新增到摘要。
- 引數
mat (torch.Tensor or numpy.ndarray) – 一個矩陣,其每一行是資料點的特徵向量
metadata (list) – 一個標籤列表,每個元素將被轉換為字串
label_img (torch.Tensor) – 對應每個資料點的影像
global_step (int) – 要記錄的全域性步驟值
tag (str) – 嵌入的名稱
metadata_header (list) – 多列元資料的標題列表。如果給定,每個元資料必須是一個列表,其中包含與標題對應的值。
- 形狀
mat: ,其中 N 是資料點數量,D 是特徵維度
label_img:
示例
import keyword import torch meta = [] while len(meta)<100: meta = meta+keyword.kwlist # get some strings meta = meta[:100] for i, v in enumerate(meta): meta[i] = v+str(i) label_img = torch.rand(100, 3, 10, 32) for i in range(100): label_img[i]*=i/100.0 writer.add_embedding(torch.randn(100, 5), metadata=meta, label_img=label_img) writer.add_embedding(torch.randn(100, 5), label_img=label_img) writer.add_embedding(torch.randn(100, 5), metadata=meta)
注意
分類(即非數字)元資料如果用於嵌入投影儀中的著色,則唯一值不能超過 50 個。
- add_pr_curve(tag, labels, predictions, global_step=None, num_thresholds=127, weights=None, walltime=None)[source][source]¶
新增精確率-召回率曲線。
繪製精確率-召回率曲線可以幫助您瞭解模型在不同閾值設定下的效能。使用此函式,您可以為每個目標提供真實標籤(真/假)和預測置信度(通常是模型的輸出)。TensorBoard UI 將允許您互動式地選擇閾值。
- 引數
tag (str) – 資料識別符號
labels (torch.Tensor, numpy.ndarray, or string/blobname) – 真實資料。每個元素的二元標籤。
predictions (torch.Tensor, numpy.ndarray, or string/blobname) – 元素被歸類為真的機率。值應在 [0, 1] 之間。
global_step (int) – 要記錄的全域性步驟值
num_thresholds (int) – 用於繪製曲線的閾值數量。
walltime (float) – 可選地覆蓋預設 walltime (time.time()),使用事件的 epoch 後秒數
示例
from torch.utils.tensorboard import SummaryWriter import numpy as np labels = np.random.randint(2, size=100) # binary label predictions = np.random.rand(100) writer = SummaryWriter() writer.add_pr_curve('pr_curve', labels, predictions, 0) writer.close()
- add_custom_scalars(layout)[source][source]¶
透過收集“標量”中的圖表標籤來建立特殊圖表。
注意:此函式對於每個 SummaryWriter() 物件只能呼叫一次。
由於此函式只向 TensorBoard 提供元資料,因此可以在訓練迴圈之前或之後呼叫。
- 引數
layout (dict) – {類別名稱: 圖表集},其中圖表集也是一個字典 {圖表名稱: 屬性列表}。屬性列表中的第一個元素是圖表型別(可以是 Multiline 或 Margin),第二個元素應是一個列表,包含您在 add_scalar 函式中使用的標籤,這些標籤將被收集到新圖表中。
示例
layout = {'Taiwan':{'twse':['Multiline',['twse/0050', 'twse/2330']]}, 'USA':{ 'dow':['Margin', ['dow/aaa', 'dow/bbb', 'dow/ccc']], 'nasdaq':['Margin', ['nasdaq/aaa', 'nasdaq/bbb', 'nasdaq/ccc']]}} writer.add_custom_scalars(layout)
- add_mesh(tag, vertices, colors=None, faces=None, config_dict=None, global_step=None, walltime=None)[source][source]¶
將網格或 3D 點雲新增到 TensorBoard。
視覺化基於 Three.js,因此允許使用者與渲染的物件進行互動。除了頂點、面等基本定義外,使用者還可以提供相機引數、光照條件等。請檢視 https://threejs.org/docs/index.html#manual/en/introduction/Creating-a-scene 獲取高階用法。
- 引數
tag (str) – 資料識別符號
vertices (torch.Tensor) – 頂點的 3D 座標列表。
colors (torch.Tensor) – 每個頂點的顏色
faces (torch.Tensor) – 每個三角形內頂點的索引。(可選)
config_dict – 包含 ThreeJS 類名和配置的字典。
global_step (int) – 要記錄的全域性步驟值
walltime (float) – 可選地覆蓋預設 walltime (time.time()),使用事件的 epoch 後秒數
- 形狀
vertices: 。(批次大小,頂點數量,通道)
colors: 。對於 uint8 型別,值應在 [0, 255] 之間;對於 float 型別,值應在 [0, 1] 之間。
faces: 。對於 uint8 型別,值應在 [0, number_of_vertices] 之間。
示例
from torch.utils.tensorboard import SummaryWriter vertices_tensor = torch.as_tensor([ [1, 1, 1], [-1, -1, 1], [1, -1, -1], [-1, 1, -1], ], dtype=torch.float).unsqueeze(0) colors_tensor = torch.as_tensor([ [255, 0, 0], [0, 255, 0], [0, 0, 255], [255, 0, 255], ], dtype=torch.int).unsqueeze(0) faces_tensor = torch.as_tensor([ [0, 2, 3], [0, 3, 1], [0, 1, 2], [1, 3, 2], ], dtype=torch.int).unsqueeze(0) writer = SummaryWriter() writer.add_mesh('my_mesh', vertices=vertices_tensor, colors=colors_tensor, faces=faces_tensor) writer.close()
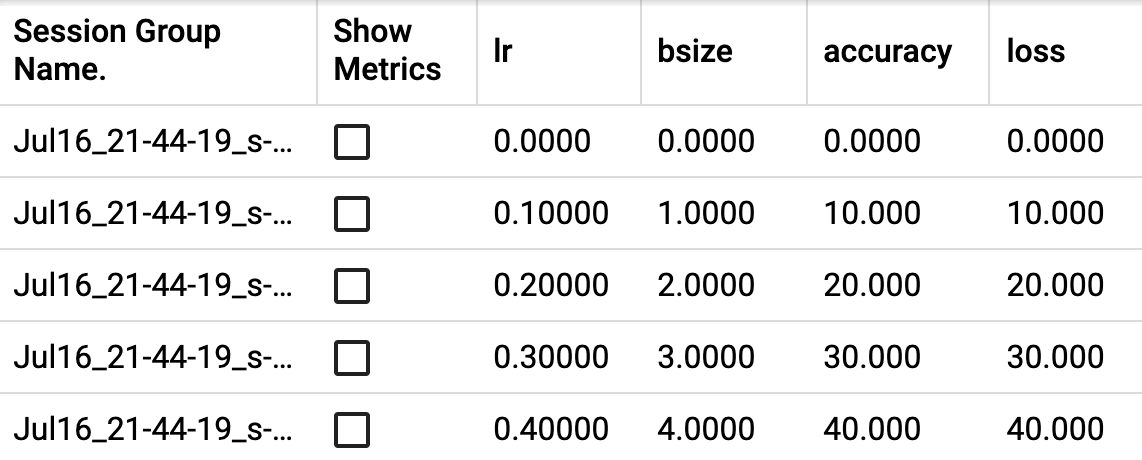
- add_hparams(hparam_dict, metric_dict, hparam_domain_discrete=None, run_name=None, global_step=None)[source][source]¶
將一組超引數新增到 TensorBoard 中進行比較。
- 引數
hparam_dict (dict) – 字典中的每個鍵值對是超引數的名稱及其對應的值。值的型別可以是 bool、string、float、int 或 None 之一。
metric_dict (dict) – 字典中的每個鍵值對是度量的名稱及其對應的值。請注意,此處使用的鍵在 TensorBoard 記錄中應是唯一的。否則,您透過
add_scalar新增的值將顯示在 hparam 外掛中。在大多數情況下,這是不希望的。hparam_domain_discrete – (Optional[Dict[str, List[Any]]]) 一個字典,包含超引數的名稱及其可以持有的所有離散值
run_name (str) – 執行的名稱,將包含在 logdir 中。如果未指定,將使用當前時間戳。
global_step (int) – 要記錄的全域性步驟值
示例
from torch.utils.tensorboard import SummaryWriter with SummaryWriter() as w: for i in range(5): w.add_hparams({'lr': 0.1*i, 'bsize': i}, {'hparam/accuracy': 10*i, 'hparam/loss': 10*i})
預期結果