torchrl.collectors 包¶
資料收集器與 pytorch 的資料載入器(dataloaders)有些類似,不同之處在於 (1) 它們從非靜態資料來源收集資料,(2) 資料是使用模型(很可能是正在訓練的模型的某個版本)收集的。
TorchRL 的資料收集器接受兩個主要引數:一個環境(或一個環境建構函式列表)和一個策略(policy)。它們將在預設的步數內迭代執行環境步進和策略查詢,然後將收集到的資料堆疊交付給使用者。環境在達到完成狀態時和/或經過預設的步數後會被重置。
由於資料收集是一個潛在的計算密集型過程,因此適當配置執行超引數至關重要。首先需要考慮的引數是資料收集應該與最佳化步驟序列發生還是並行發生。SyncDataCollector 類將在訓練工作程序上執行資料收集。MultiSyncDataCollector 將工作負載分配到多個工作程序並聚合結果,然後將結果交付給訓練工作程序。最後,MultiaSyncDataCollector 將在多個工作程序上執行資料收集,並交付其能收集到的第一個批次結果。這種執行方式將與網路的訓練持續並行進行:這意味著用於資料收集的策略權重可能略滯後於訓練工作程序上的策略配置。因此,儘管此類可能是收集資料最快的,但其代價是僅適用於可以非同步收集資料的場景(例如離策略強化學習或課程強化學習)。對於遠端執行的 rollout(MultiSyncDataCollector 或 MultiaSyncDataCollector),需要使用 collector.update_policy_weights_() 或在建構函式中設定 update_at_each_batch=True 來同步遠端策略權重與訓練工作程序上的權重。
需要考慮的第二個引數(在遠端設定中)是資料收集裝置以及環境和策略操作執行裝置。例如,在 CPU 上執行的策略可能比在 CUDA 上執行的策略慢。當多個推理工作程序同時執行時,將計算工作負載分配到可用裝置上可以加快收集速度或避免 OOM(記憶體不足)錯誤。最後,批次大小和傳遞裝置(即資料在等待傳遞給收集工作程序時儲存的裝置)的選擇也可能影響記憶體管理。關鍵控制引數是 devices,它控制執行裝置(即策略裝置),以及 storing_device,它控制 rollout 期間環境和資料儲存的裝置。一個好的啟發式方法通常是為儲存和計算使用相同的裝置,這是隻傳遞 devices 引數時的預設行為。
除了這些計算引數外,使用者還可以選擇配置以下引數
max_frames_per_traj: 觸發
env.reset()的幀數閾值frames_per_batch: 收集器每次迭代交付的幀數
init_random_frames: 隨機步數(呼叫
env.rand_step()的步數)reset_at_each_iter: 如果為
True,環境將在每次批次收集後重置split_trajs: 如果為
True,軌跡將被分割並以 padded tensordict 的形式交付,同時包含一個"mask"鍵,該鍵指向一個布林掩碼,表示有效值。exploration_type: 與策略一起使用的探索策略。
reset_when_done: 環境在達到完成狀態時是否應該重置。
收集器與批次大小¶
由於每個收集器組織其內部執行環境的方式不同,因此資料將根據收集器的具體特性而具有不同的批次大小。下表總結了資料收集時的預期結果
SyncDataCollector |
MultiSyncDataCollector (n=B) |
MultiaSyncDataCollector (n=B) |
|||
|---|---|---|---|---|---|
cat_results |
不適用 |
“stack” |
0 |
-1 |
不適用 |
單個環境 |
[T] |
[B, T] |
[B*(T//B) |
[B*(T//B)] |
[T] |
批次環境 (n=P) |
[P, T] |
[B, P, T] |
[B * P, T] |
[P, T * B] |
[P, T] |
在這些情況下,最後一個維度(T 表示 時間)會進行調整,使得批次大小等於傳遞給收集器的 frames_per_batch 引數值。
警告
MultiSyncDataCollector 不應與 cat_results=0 一起使用,因為對於批次環境,資料將沿批次維度堆疊,對於單個環境,資料將沿時間維度堆疊,這在相互切換時可能導致混淆。cat_results="stack" 是與環境互動的一種更好、更一致的方式,因為它會保持每個維度獨立,並在配置、收集器類和其他元件之間提供更好的互換性。
考慮到 MultiaSyncDataCollector 以先到先得的方式交付資料批次,而 MultiSyncDataCollector 在交付資料之前會從每個子收集器收集資料,這一點很容易理解。MultiSyncDataCollector 包含一個對應於執行的子收集器數量 (B) 的維度,而 MultiaSyncDataCollector 則沒有。
收集器與策略副本¶
將策略傳遞給收集器時,我們可以選擇執行該策略的裝置。這可以用來將策略的訓練版本儲存在一個裝置上,而推理版本儲存在另一個裝置上。例如,如果您有兩個 CUDA 裝置,明智的做法可能是在一個裝置上進行訓練,並在另一個裝置上執行策略進行推理。如果是這種情況,可以使用 update_policy_weights_() 將引數從一個裝置複製到另一個裝置(如果不需要複製,此方法無效)。
由於目標是避免顯式呼叫 policy.to(policy_device),收集器將在必要時對策略結構進行深複製,並在例項化期間將引數複製到新裝置上。由於並非所有策略都支援深複製(例如,使用 CUDA 圖或依賴第三方庫的策略),我們嘗試限制執行深複製的情況。下圖顯示了何時會發生這種情況。
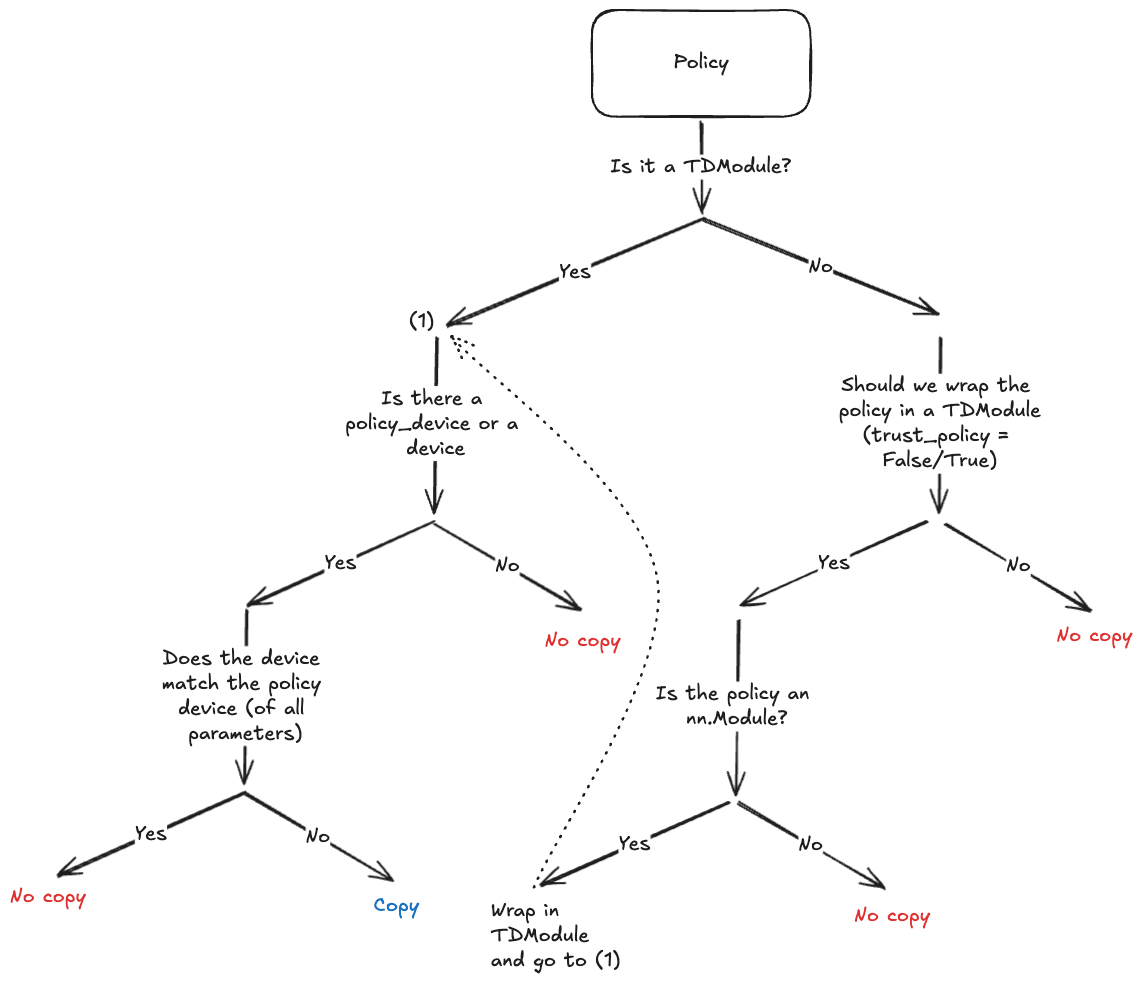
收集器中的策略複製決策樹。¶
收集器與經驗回放緩衝區互操作性¶
在需要從經驗回放緩衝區中取樣單個轉換(transitions)的最簡單場景中,無需過多關注收集器的構建方式。收集後將資料展平是填充儲存之前一個足夠的預處理步驟。
>>> memory = ReplayBuffer(
... storage=LazyTensorStorage(N),
... transform=lambda data: data.reshape(-1))
>>> for data in collector:
... memory.extend(data)
如果需要收集軌跡切片(slices),推薦的方法是建立一個多維緩衝區並使用 SliceSampler 取樣器類進行取樣。必須確保傳遞給緩衝區的資料形狀正確,並且 時間 和 批次 維度清晰分離。實踐中,以下配置將生效:
>>> # Single environment: no need for a multi-dimensional buffer
>>> memory = ReplayBuffer(
... storage=LazyTensorStorage(N),
... sampler=SliceSampler(num_slices=4, trajectory_key=("collector", "traj_ids"))
... )
>>> collector = SyncDataCollector(env, policy, frames_per_batch=N, total_frames=-1)
>>> for data in collector:
... memory.extend(data)
>>> # Batched environments: a multi-dim buffer is required
>>> memory = ReplayBuffer(
... storage=LazyTensorStorage(N, ndim=2),
... sampler=SliceSampler(num_slices=4, trajectory_key=("collector", "traj_ids"))
... )
>>> env = ParallelEnv(4, make_env)
>>> collector = SyncDataCollector(env, policy, frames_per_batch=N, total_frames=-1)
>>> for data in collector:
... memory.extend(data)
>>> # MultiSyncDataCollector + regular env: behaves like a ParallelEnv if cat_results="stack"
>>> memory = ReplayBuffer(
... storage=LazyTensorStorage(N, ndim=2),
... sampler=SliceSampler(num_slices=4, trajectory_key=("collector", "traj_ids"))
... )
>>> collector = MultiSyncDataCollector([make_env] * 4,
... policy,
... frames_per_batch=N,
... total_frames=-1,
... cat_results="stack")
>>> for data in collector:
... memory.extend(data)
>>> # MultiSyncDataCollector + parallel env: the ndim must be adapted accordingly
>>> memory = ReplayBuffer(
... storage=LazyTensorStorage(N, ndim=3),
... sampler=SliceSampler(num_slices=4, trajectory_key=("collector", "traj_ids"))
... )
>>> collector = MultiSyncDataCollector([ParallelEnv(2, make_env)] * 4,
... policy,
... frames_per_batch=N,
... total_frames=-1,
... cat_results="stack")
>>> for data in collector:
... memory.extend(data)
目前使用 MultiSyncDataCollector 取樣軌跡的經驗回放緩衝區尚未完全支援,因為資料批次可能來自任何工作程序,並且在大多數情況下,寫入緩衝區中的連續批次不會來自同一來源(從而中斷軌跡)。
單節點資料收集器¶
資料收集器的基類。 |
|
|
用於強化學習問題的通用資料收集器。 |
|
在獨立的程序上同步執行指定數量的資料收集器。 |
|
在獨立的程序上非同步執行指定數量的資料收集器。 |
|
在獨立的程序上執行單個數據收集器。 |
分散式資料收集器¶
TorchRL 提供了一組分散式資料收集器。這些工具支援多種後端(使用 DistributedDataCollector 的 'gloo'、'nccl'、'mpi',或使用 RPCDataCollector 的 PyTorch RPC)和啟動器('ray'、submitit 或 torch.multiprocessing)。它們可以在同步或非同步模式下高效使用,無論是單節點還是跨多個節點。
資源:在專用資料夾中查詢這些收集器的示例。
注意
選擇子收集器:所有分散式收集器都支援各種單機收集器。您可能想知道為什麼不使用 MultiSyncDataCollector 或 ParallelEnv。一般來說,多程序收集器比需要每一步通訊的並行環境具有更低的 IO 開銷。然而,模型規格的作用方向相反,因為使用並行環境會使策略(和/或 transforms)的執行速度更快,因為這些操作是向量化的。
注意
選擇收集器(或並行環境)的裝置:程序之間的資料共享是透過共享記憶體緩衝區實現的,對於在 CPU 上執行的並行環境和多程序環境。根據所使用機器的能力,這可能比在 GPU 上共享資料慢得多,GPU 資料共享由 cuda 驅動程式原生支援。實踐中,這意味著在構建並行環境或收集器時使用 device="cpu" 關鍵字引數,可能導致比在可用時使用 device="cuda" 更慢的資料收集。
注意
考慮到庫的許多可選依賴項(例如 Gym、Gymnasium 等),在多程序/分散式設定中警告可能會很快變得非常煩人。預設情況下,TorchRL 會在子程序中過濾掉這些警告。如果仍然希望看到這些警告,可以透過設定 torchrl.filter_warnings_subprocess=False 來顯示它們。
|
使用 torch.distributed 後端的分散式資料收集器。 |
|
基於 RPC 的分散式資料收集器。 |
|
使用 torch.distributed 後端的分散式同步資料收集器。 |
|
submitit 的延遲啟動器。 |
|
使用 Ray 後端的分散式資料收集器。 |
輔助函式¶
|
一個用於軌跡分割的實用函式。 |
